Trasmettere i dati dal BLOB del servizio di archiviazione di Azure a Data Lake Storage Gen1 usando Analisi di flusso di Azure
In questo articolo viene illustrato come usare Azure Data Lake Storage Gen1 come output per un processo di Azure Stream Analytics. Questo articolo illustra uno scenario semplice in cui i dati vengono letti da un BLOB del servizio di archiviazione di Azure (input) e scritti in Data Lake Storage Gen1 (output).
Prerequisiti
Prima di iniziare questa esercitazione, è necessario disporre di quanto segue:
Una sottoscrizione di Azure. Vedere Ottenere una versione di prova gratuita di Azure.
Account di archiviazione di Azure. Per l'input dei dati per un processo di Analisi di flusso viene usato un contenitore BLOB da questo account. Per questa esercitazione, si supponga di disporre di un account di archiviazione storageforasa e di un contenitore incluso nell'account denominato storageforasacontainer. Dopo aver creato il contenitore, caricare un file di dati di esempio.
Un account Data Lake Storage Gen1. Seguire le istruzioni fornite in Introduzione ad Azure Data Lake Storage Gen1 con il portale di Azure. Si supponga di avere un account Data Lake Storage Gen1 denominato myadlsg1.
Creare un processo di Analisi di flusso
Iniziare creando un processo di Analisi di flusso che include un'origine di input e una destinazione di output. Per questa esercitazione, l'origine è un contenitore BLOB di Azure e la destinazione è Data Lake Storage Gen1.
Accedere al portale di Azure.
Nel riquadro sinistro, fare clic su Processi di Analisi di flusso, quindi fare clic su Aggiungi.
 analisi
analisi Nota
Assicurarsi di creare il processo nella stessa area dell'account di archiviazione per non incorrere in costi aggiuntivi per lo spostamento dei dati tra le aree.
Creare un input BLOB per il processo
Aprire la pagina per il processo di Analisi di flusso, nel riquadro sinistro fare clic sulla scheda Input e quindi fare clic su Aggiungi.

Nel pannello Nuovo input specificare i valori seguenti.

In Alias dell'input inserire un nome univoco per l'input del processo.
Per Tipo di origine selezionare Flusso dati.
Per Origine selezionare Archiviazione BLOB.
Per Sottoscrizione selezionare Usa l'archiviazione BLOB della sottoscrizione corrente.
Per Account di archiviazione selezionare l'account di archiviazione creato come parte dei prerequisiti.
Per Contenitore selezionare il contenitore creato nell'account di archiviazione selezionato.
In Formato di serializzazione eventi scegliere CSV.
Per Delimitatore selezionare scheda.
Per Codifica selezionare UTF-8.
Fare clic su Crea. Il portale ora aggiunge l'input e verifica la connessione allo stesso.
Creare un output di Data Lake Storage Gen1 per il processo
Aprire la pagina per il processo di Analisi di flusso, fare clic sulla scheda Output, quindi su Aggiungi e selezionare Data Lake Storage Gen1.

Nel pannello Nuovo output specificare i valori seguenti.

- In Alias dell'output inserire un nome univoco per l'output del processo. È un nome descrittivo usato nelle query per indirizzare l'output delle query all'account Data Lake Storage Gen1.
- Verrà richiesto di autorizzare l'accesso all'account Data Lake Storage Gen1. Fare clic su Autorizza.
Nel pannello Nuovo output continuare a specificare i valori seguenti.

Per Nome account selezionare l'account Data Lake Storage Gen1 già creato a cui si vuole inviare l'output del processo.
In Schema prefisso percorso immettere un percorso di file usato per scrivere i file nell'account Data Lake Storage Gen1 specificato.
Per Formato data, se nel percorso di prefisso viene usato un token di data, è possibile selezionare il formato della data in cui sono organizzati i file.
Per Formato ora, se nel percorso di prefisso viene usato un token di ora, specificare il formato dell'ora in cui sono organizzati i file.
In Formato di serializzazione eventi scegliere CSV.
Per Delimitatore selezionare scheda.
Per Codifica selezionare UTF-8.
Fare clic su Crea. Il portale ora aggiunge l'output e verifica la connessione allo stesso.
Eseguire il processo di Analisi di flusso
Per eseguire un processo Stream Analytics, è necessario eseguire una query dalla scheda Query. Per questa esercitazione è possibile eseguire la query di esempio sostituendo i segnaposto con gli alias di input e output del processo, come illustrato nell'acquisizione dello schermo seguente.

Fare clic su Salva nella parte superiore dello schermo, quindi sulla scheda Panoramica e su Avvia. Nella finestra di dialogo selezionare Ora personalizzata, quindi selezionare la data e l'ora correnti.
 del
del Fare clic su Avvia per avviare il processo. L'avvio del processo può richiedere un paio di minuti.
Per attivare la raccolta dei dati dal BLOB da parte del processo, copiare un file dati campione nel contenitore BLOB. È possibile ottenere un file di dati di esempio dal repository Git di Azure Data Lake. Per questa esercitazione verrà copiato il file vehicle1_09142014.csv. È possibile usare vari tipi di client, ad esempio Azure Storage Explorer, per caricare i dati in un contenitore BLOB.
Nella scheda Panoramica, in Monitoraggio è possibile visualizzare come sono stati elaborati i dati.
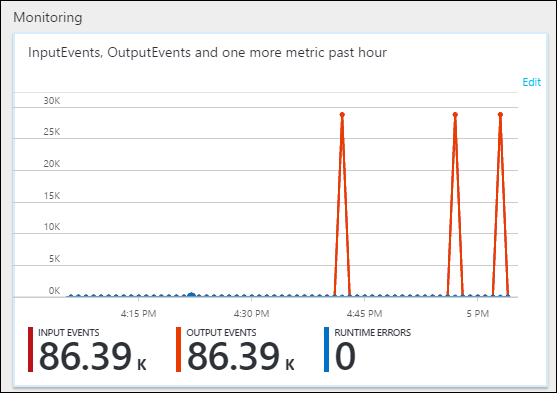
Infine, è possibile verificare la disponibilità dei dati di output del processo nell'account Data Lake Storage Gen1.

Nel riquadro Esplora dati l'output viene scritto in un percorso di cartella come specificato nelle impostazioni di output di Data Lake Storage Gen1 (
streamanalytics/job/output/{date}/{time}).