Federazione multisito e multiarea
Molte soluzioni sofisticate richiedono che gli stessi flussi di eventi siano resi disponibili per l'utilizzo in più posizioni oppure richiedono che i flussi di eventi vengano raccolti in più posizioni e quindi consolidati in una posizione specifica per l'utilizzo. Spesso è anche necessario arricchire o ridurre i flussi di eventi o eseguire conversioni di formato eventi, anche per all'interno di una singola area e soluzione.
In pratica, ciò significa che la soluzione manterrà più hub eventi, spesso in aree diverse e spazi dei nomi di Hub eventi e quindi replica gli eventi tra di essi. È anche possibile scambiare eventi con origini e destinazioni come bus di servizio di Azure, hub IoT di Azure o Apache Kafka.
La gestione di più hub eventi attivi in aree diverse consente anche ai client di scegliere e passare da un'area all'altra se il relativo contenuto viene unito, in modo che il sistema complessivo sia più resiliente rispetto ai problemi di disponibilità a livello di area.
Questo capitolo "Federazione" illustra i modelli di federazione e come realizzare questi modelli usando Analisi di flusso di Azure serverless o i runtime di Funzioni di Azure, con la possibilità di avere il proprio codice di trasformazione o arricchimento direttamente nel percorso del flusso di eventi.
Modelli di federazione
Esistono molte possibili motivazioni per il motivo per cui è possibile spostare eventi tra hub eventi diversi o altre origini e destinazioni ed enumerare i modelli più importanti in questa sezione e anche collegare indicazioni più dettagliate per il rispettivo modello.
- Resilienza rispetto a eventi di disponibilità a livello di area
- Ottimizzazione della latenza
- Convalida, riduzione e arricchimento
- Integrazione con i servizi di analisi
- Consolidamento e normalizzazione dei flussi di eventi
- Suddivisione e routing dei flussi di eventi
- Proiezioni di log
Resilienza rispetto a eventi di disponibilità a livello di area
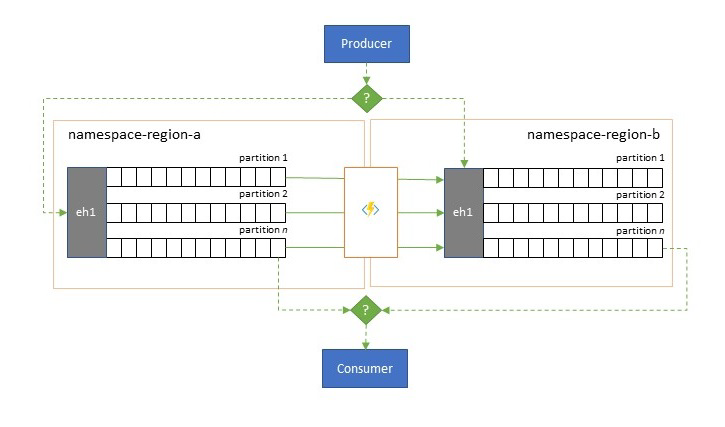
Sebbene la disponibilità e l'affidabilità massime siano le principali priorità operative per Hub eventi, esistono tuttavia molti modi in cui un producer o un consumer potrebbe non comunicare con hub eventi "primario" assegnato a causa di problemi di rete o risoluzione dei nomi o in cui un hub eventi potrebbe effettivamente non rispondere o restituire errori.
Tali condizioni non sono "disastrose" in modo da voler abbandonare completamente la distribuzione a livello di area, in quanto in una situazione di ripristino di emergenza, ma lo scenario aziendale di alcune applicazioni potrebbe essere già interessato da eventi di disponibilità che durano non più di pochi minuti o addirittura secondi.
Esistono due modelli fondamentali per affrontare questi scenari:
- Il modello di replica riguarda la replica del contenuto di un hub eventi primario in un hub eventi secondario, in cui hub eventi primario viene in genere usato dall'applicazione per produrre e utilizzare eventi e il database secondario funge da opzione di fallback nel caso in cui Hub eventi primario non sia più disponibile. Poiché la replica è unidirezionale, dal database primario al secondario, il passaggio da producer e consumer da un primario non disponibile al database secondario causerà che il database primario precedente non riceva più nuovi eventi e pertanto non sarà più corrente. La replica pura è quindi adatta solo per scenari di failover unidirezionale. Dopo aver eseguito il failover, il database primario precedente viene abbandonato e deve essere creato un nuovo hub eventi secondario in un'area di destinazione diversa.
- Il modello di unione estende il modello di replica eseguendo un'unione continua del contenuto di due o più Hub eventi. Ogni evento originariamente prodotto in uno degli Hub eventi inclusi nello schema viene replicato negli altri Hub eventi. Man mano che gli eventi vengono replicati, vengono annotati in modo che vengano successivamente ignorati dal processo di replica della destinazione di replica. I risultati dell'uso del modello di unione sono due o più hub eventi che conterranno lo stesso set di eventi in modo coerente.
In entrambi i casi, il contenuto di Hub eventi non sarà identico. Gli eventi di un producer e raggruppati in base alla stessa chiave di partizione verranno visualizzati nello stesso ordine relativo dell'invio originale, ma l'ordine assoluto degli eventi può differire. Questo vale soprattutto per gli scenari in cui il numero di partizioni di Hub eventi di origine e di destinazione differisce, che è auspicabile per diversi modelli estesi descritti qui. Una suddivisione o un router può ottenere una sezione di Hub eventi molto più grande con centinaia di partizioni e imbuto in un hub eventi più piccolo con solo una manciata di partizioni, più adatto per gestire il subset con risorse di elaborazione limitate. Al contrario, un consolidamento può incanalare i dati di più piccoli Hub eventi in un singolo hub eventi di dimensioni maggiori con più partizioni per far fronte alle esigenze di elaborazione e velocità effettiva consolidate.
Il criterio per mantenere insieme gli eventi è la chiave di partizione e non l'ID partizione originale. Altre considerazioni sull'ordine relativo e su come eseguire un failover da un hub eventi a quello successivo senza basarsi sullo stesso ambito degli offset di flusso viene illustrato nella descrizione del modello di replica .
Materiale sussidiario:
Ottimizzazione della latenza
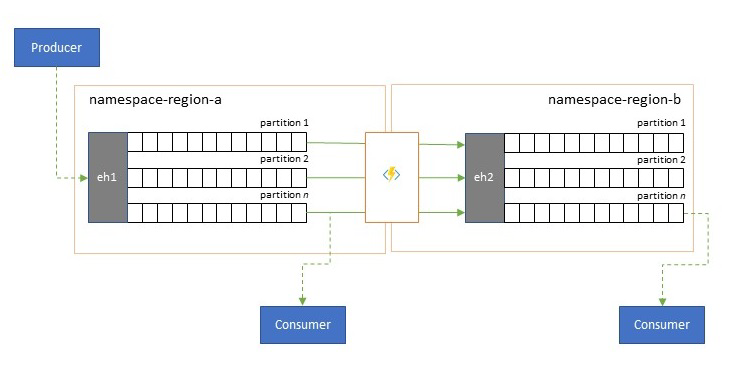
I flussi di eventi vengono scritti una sola volta dai producer, ma possono essere letti un numero qualsiasi di volte dai consumer di eventi. Per gli scenari in cui un flusso di eventi in un'area è condiviso da più consumer ed è necessario accedervi ripetutamente durante l'elaborazione di analisi che si trova in un'area diversa o con tutte le richieste che causano un'interruzione dei consumer simultanei, può essere utile inserire una copia del flusso di eventi vicino al processore di analisi per ridurre la latenza di round trip.
Esempi validi per i casi in cui la replica deve essere preferita rispetto all'utilizzo di eventi in remoto da più aree sono soprattutto quelle in cui le aree sono estremamente distanti, ad esempio l'Europa e l'Australia sono quasi antipodi, le latenze geografiche e di rete possono facilmente superare i 250 ms per qualsiasi round trip. Non è possibile accelerare la velocità della luce, ma è possibile ridurre il numero di round trip ad alta latenza per interagire con i dati.
Materiale sussidiario:
Convalida, riduzione e arricchimento
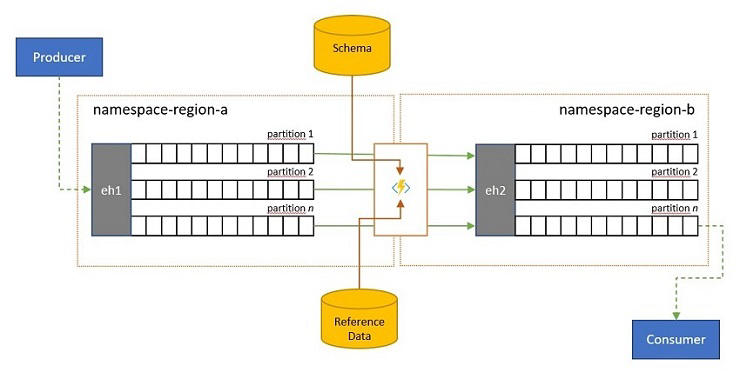
I flussi di eventi possono essere inviati a un hub eventi da parte dei client esterni alla propria soluzione. Tali flussi di eventi possono richiedere che gli eventi inviati esternamente siano controllati per la conformità a uno schema specifico e che gli eventi non conformi vengano eliminati.
Negli scenari in cui i client sono estremamente vincolati alla larghezza di banda, così come accade in molti scenari "Internet delle cose" con larghezza di banda a consumo o in cui gli eventi vengono originariamente inviati su reti non IP con dimensioni di pacchetti vincolati, gli eventi possono essere arricchiti con dati di riferimento per aggiungere ulteriore contesto per essere utilizzabili dai processori di eventi downstream.
In altri casi, in particolare quando i flussi vengono consolidati, i dati dell'evento possono essere ridotti in complessità o con dimensioni più elevate o omettendo alcuni dettagli.
Una di queste operazioni può verificarsi come parte dei flussi di replica, consolidamento o unione.
Materiale sussidiario:
Integrazione con i servizi di analisi
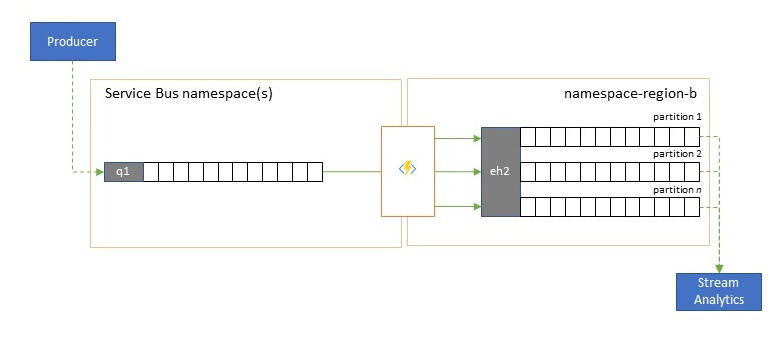
Diversi servizi di analisi nativa del cloud di Azure, ad esempio Analisi di flusso di Azure o Azure Synapse funzionano meglio con i dati in streaming o pre-batch forniti da Hub eventi di Azure e Hub eventi di Azure consente anche l'integrazione con diversi pacchetti di analisi open source, ad esempio Apache Samza, Apache Flink, Apache Spark e Apache Storm.
Se la soluzione usa principalmente il bus di servizio o Griglia di eventi, è possibile rendere questi eventi facilmente accessibili a tali sistemi di analisi e anche per l'archiviazione con l'acquisizione di Hub eventi se li si incanala in Hub eventi. Griglia di eventi può farlo in modo nativo con l'integrazione di Hub eventi, per il bus di servizio si seguono le linee guida per la replica del bus di servizio.
Analisi di flusso di Azure si integra direttamente con Hub eventi.
Materiale sussidiario:
Consolidamento e normalizzazione dei flussi di eventi
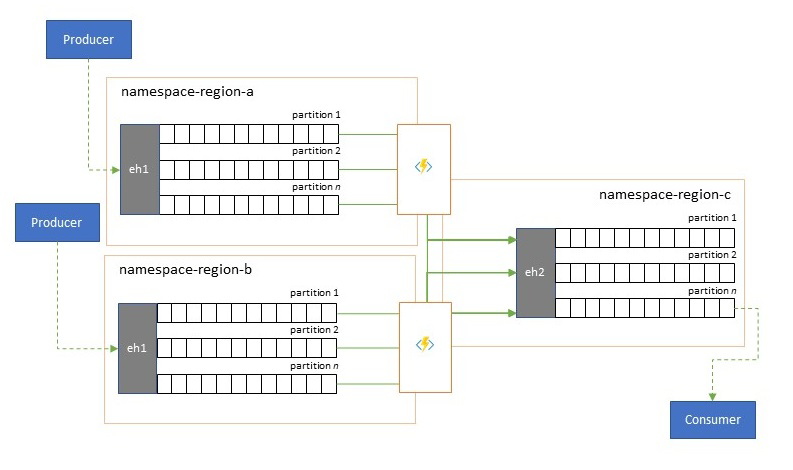
Le soluzioni globali sono spesso costituite da footprint regionali che sono in gran parte indipendenti, tra cui avere le proprie capacità di analisi, ma le prospettive di analisi sovra-regionali e globali richiederanno una prospettiva integrata ed è per questo che un consolidamento centrale degli stessi flussi di eventi valutati nei rispettivi footprint regionali per la prospettiva locale.
La normalizzazione è una versione dello scenario di consolidamento, in cui due o più flussi di eventi in ingresso portano lo stesso tipo di eventi, ma con strutture diverse o codifiche diverse e gli eventi più transcodificati o trasformati prima che possano essere utilizzati.
La normalizzazione può includere anche operazioni di crittografia, ad esempio la decrittografia di payload crittografati end-to-end e la ricrittografia con chiavi e algoritmi diversi per il gruppo di destinatari del consumer downstream.
Materiale sussidiario:
Suddivisione e routing dei flussi di eventi
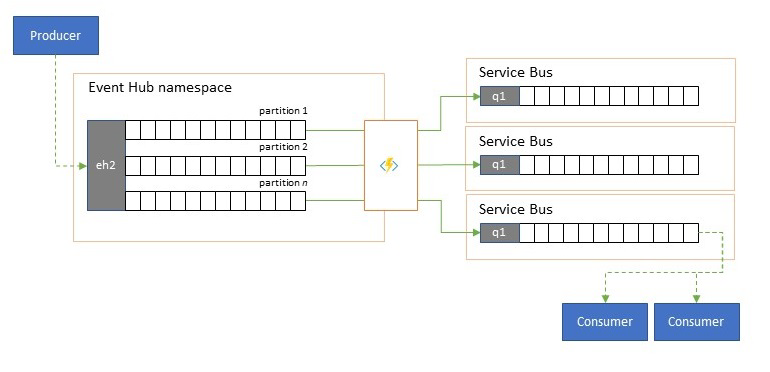
Hub eventi di Azure viene usato occasionalmente in scenari di stile "publish-subscribe" in cui un torrente in ingresso di eventi inseriti supera di gran lunga la capacità di bus di servizio di Azure o Griglia di eventi di Azure, entrambi con funzionalità di filtro di pubblicazione-sottoscrizione e distribuzione native e sono preferibili per questo modello.
Anche se una vera funzionalità "publish-subscribe" lascia ai sottoscrittori di selezionare gli eventi desiderati, il modello di suddivisione include gli eventi di mapping dei producer alle partizioni in base a un modello di distribuzione predeterminato e i consumer designati e quindi eseguono il pull esclusivo dalla partizione "their". Con l'hub eventi che memorizza nel buffer il traffico complessivo, il contenuto di una determinata partizione, che rappresenta una frazione del volume di velocità effettiva originale, può quindi essere replicato in una coda per un consumo consumer affidabile, transazionale e concorrente.
Molti scenari in cui Hub eventi viene usato principalmente per lo spostamento di eventi all'interno di un'applicazione all'interno di un'area hanno alcuni casi in cui gli eventi selezionati, forse solo da una singola partizione, devono essere resi disponibili altrove. Questo scenario è simile allo scenario di suddivisione, ma può usare un router scalabile che considera tutti i messaggi in arrivo in hub eventi e solo pochi per il routing in avanti e potrebbe distinguere le destinazioni di routing in base ai metadati o al contenuto dell'evento.
Materiale sussidiario:
Proiezioni di log
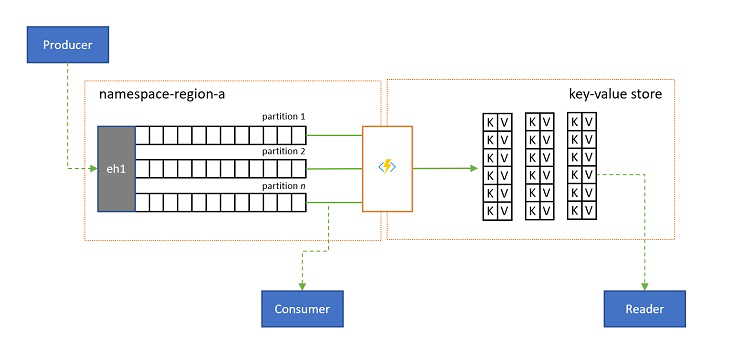
In alcuni scenari è necessario avere accesso al valore più recente inviato per qualsiasi sottostream di un evento e comunemente distinto dalla chiave di partizione. In Apache Kafka questa operazione viene spesso ottenuta abilitando la "compattazione dei log" in un argomento, che rimuove tutti gli eventi, ma l'evento più recente etichettato con qualsiasi chiave univoca. L'approccio di compattazione dei log presenta tre svantaggi composti:
- La compattazione richiede una riorganizzazione continua del log, ovvero un'operazione eccessivamente costosa per un broker ottimizzato per carichi di lavoro di sola accodamento.
- La compattazione è distruttiva e non consente una prospettiva compattata e non compattata dello stesso flusso.
- Un flusso compattato ha ancora un modello di accesso sequenziale, ovvero la ricerca del valore desiderato nel log richiede la lettura dell'intero log nel peggiore dei casi, che in genere comporta ottimizzazioni che implementano il modello esatto presentato qui: proiettando il contenuto del log in un database o in una cache.
In definitiva, un log compattato è un archivio chiave-valore e, di conseguenza, è l'opzione di implementazione peggiore possibile per tale archivio. È molto più efficiente per le ricerche e per le query creare e usare una proiezione permanente del log in un archivio chiave-valore appropriato o in un altro database.
Poiché gli eventi non sono modificabili e l'ordine viene sempre mantenuto in un log, qualsiasi proiezione di un log in un archivio chiave-valore sarà sempre identica per lo stesso intervallo di eventi, ovvero una proiezione che si mantiene aggiornata fornisce sempre una visualizzazione autorevole e non c'è mai alcun motivo valido per ricompilarlo dal contenuto del log dopo la compilazione.
Materiale sussidiario:
Tecnologie dell'applicazione di replica
L'implementazione dei modelli precedenti richiede un ambiente di esecuzione scalabile e affidabile per le attività di replica da configurare ed eseguire. In Azure, gli ambienti di runtime più adatti per tali attività sono attività senza stato sono Analisi di flusso di Azure per attività di replica di flusso con stato e Funzioni di Azure per le attività di replica senza stato.
Applicazioni di replica con stato in Analisi di flusso di Azure
Per le applicazioni di replica con stato che devono prendere in considerazione le relazioni tra eventi, creare eventi compositi, arricchire eventi o ridurre eventi, creare aggregazioni di dati e trasformare payload di eventi, Analisi di flusso di Azure è l'opzione di implementazione migliore.
In Analisi di flusso di Azure si creano processi che integrano input e output e si integrano i dati dagli input tramite query che producono un risultato che viene quindi reso disponibile negli output.
Le query sono basate sul linguaggio di query SQL e possono essere usate per filtrare, ordinare, aggregare e unire facilmente i dati di streaming in un periodo di tempo. È anche possibile estendere questo linguaggio SQL con funzioni Definite dall'utenteJavaScript e C#. È possibile modificare facilmente le opzioni di ordinamento degli eventi e la durata delle finestre temporali durante l'esecuzione di operazioni di aggregazione tramite semplici costrutti di linguaggio e/o configurazioni.
Ogni processo include uno o più output dei dati trasformati ed è possibile controllare cosa avviene in risposta alle informazioni analizzate. Ad esempio, è possibile:
- Inviare dati a servizi quali Funzioni di Azure, argomenti del bus di servizio o code per attivare comunicazioni o flussi di lavoro personalizzati a valle.
- Inviare dati a un dashboard di Power BI per la visualizzazione nel dashboard in tempo reale.
- Archiviare i dati in altri servizi di archiviazione di Azure ,ad esempio Azure Data Lake, Azure Synapse Analytics e così via, per eseguire analisi batch o eseguire il training di modelli di Machine Learning basati su pool di dati cronologici molto grandi e indicizzati.
- Archiviare le proiezioni (dette anche "viste materializzate") nei database (database SQL, Azure Cosmos DB).
Applicazioni di replica senza stato in Funzioni di Azure
Per le attività di replica senza stato in cui si desidera inoltrare gli eventi senza considerare i payload o elaborarli in modo automatico senza dover considerare le relazioni degli eventi (ad eccezione del relativo ordine), è possibile usare Funzioni di Azure, che offre enorme flessibilità.
Funzioni di Azure include trigger predefiniti, trigger scalabili e associazioni di output per Hub eventi di Azure, hub IoT di Azure, bus di servizio di Azure, Griglia di eventi di Azure, e Archiviazione code di Azure, nonché estensioni personalizzate per RabbitMQ e Apache Kafka. La maggior parte dei trigger si adatterà dinamicamente alle esigenze di velocità effettiva ridimensionando il numero di istanze in esecuzione simultanea in base alle metriche documentate.
Per la creazione di proiezioni di log, Funzioni di Azure supporta le associazioni di output per Azure Cosmos DB e Archiviazione tabelle di Azure.
Funzioni di Azure può essere eseguito con un'identità gestita di Azure e con questo può contenere i valori di configurazione per le credenziali in una risorsa di archiviazione strettamente controllata dall'accesso all'interno di Azure Key Vault.
Funzioni di Azure consente inoltre alle attività di replica di integrarsi direttamente con le reti virtuali di Azure e gli endpoint di servizio per tutti i servizi di messaggistica di Azure ed è facilmente integrato con Monitoraggio di Azure.
Con il piano a consumo Funzioni di Azure, i trigger predefiniti possono anche ridurre fino a zero mentre non sono disponibili messaggi per la replica, il che significa che non si comportano costi per mantenere la configurazione pronta per il backup. Il lato negativo dell'uso del piano a consumo è che la latenza per le attività di replica "riattiva" da questo stato è significativamente superiore rispetto ai piani di hosting in cui l'infrastruttura viene mantenuta in esecuzione.
A differenza di tutto questo, i motori di replica più comuni per la messaggistica e l'evento, ad esempio MirrorMaker di Apache Kafka, richiedono di fornire un ambiente di hosting e ridimensionare manualmente il motore di replica. Ciò include la configurazione e l'integrazione delle funzionalità di sicurezza e di rete e la facilitazione del flusso dei dati di monitoraggio e quindi non è ancora possibile inserire attività di replica personalizzate nel flusso.
Scelta tra Funzioni di Azure e Analisi di flusso di Azure
Analisi di flusso di Azure è l'opzione migliore ogni volta che è necessario elaborare il payload degli eventi durante la replica. AsA può copiare gli eventi uno per uno o può creare aggregazioni che condensano le informazioni dei flussi di eventi prima di inoltrarlo. Può essere facilmente in grado di integrare i dati di riferimento contenuti in Archiviazione BLOB di Azure o Azure SQL Database senza dover importare tali dati in un flusso.
Con ASA è possibile creare facilmente viste persistenti materializzate dei flussi nei database con ipersaltamento. Si tratta di un approccio molto superiore al modello di "compattazione log" di Apache Kafka e delle proiezioni di tabelle sul lato client volatili di Kafka Streams.
AsA può elaborare facilmente gli eventi con payload codificati nei formati CSV, JSON e Apache Avro ed è possibile collegare deserializzatori personalizzati per qualsiasi altro formato.
Per tutte le attività di replica in cui si desidera copiare i flussi di eventi "così com'è" e senza toccare i payload oppure se è necessario implementare un router, eseguire operazioni di crittografia, modificare la codifica dei payload o se in caso contrario è necessario il controllo completo sul contenuto del flusso di dati, Funzioni di Azure è l'opzione migliore.
Passaggi successivi
In questo articolo è stata esaminata una serie di modelli di federazione ed è stato illustrato il ruolo di Funzioni di Azure come runtime di replica di eventi e messaggistica in Azure.
Successivamente, è possibile leggere come configurare un'applicazione di replicatore con Analisi di flusso di Azure o Funzioni di Azure e quindi come replicare i flussi di eventi tra Hub eventi e vari altri sistemi di eventi e messaggistica: