Esercitazione: Creare cluster Apache Hadoop on demand in HDInsight con Azure Data Factory
Questa esercitazione illustra come creare un cluster Apache Hadoop su richiesta in Azure HDInsight con Azure Data Factory. Si useranno quindi le pipeline di dati in Azure Data Factory per eseguire i processi Hive ed eliminare il cluster. Al termine di questa esercitazione, si apprenderà come operationalize l'esecuzione di un processo Big Data in cui la creazione del cluster, l'esecuzione del processo e l'eliminazione del cluster vengono eseguite in base a una pianificazione.
Questa esercitazione illustra le attività seguenti:
- Creare un account di archiviazione di Azure
- Comprendere l'attività di Azure Data Factory
- Creare una data factory con il portale di Azure
- Creare servizi collegati
- Creare una pipeline
- Attivare una pipeline
- Monitorare una pipeline
- Verificare l'output
Se non si ha una sottoscrizione di Azure, creare un account gratuito prima di iniziare.
Prerequisiti
Il modulo Az di PowerShell installato.
Un'entità servizio Microsoft Entra. Dopo aver creato l'entità servizio, assicurarsi di recuperare l'ID dell'applicazione e la chiave di autenticazione seguendo le istruzioni nell'articolo collegato. Più avanti in questa esercitazione saranno necessari questi valori. Assicurarsi anche che l'entità servizio sia un membro del ruolo Collaboratore della sottoscrizione o del gruppo di risorse in cui viene creato il cluster. Per istruzioni su come recuperare i valori necessari e assegnare i ruoli corretti, vedere Creare un'entità servizio Microsoft Entra.
Creare oggetti di Azure preliminari
In questa sezione si creeranno diversi oggetti che verranno usati per il cluster HDInsight creato su richiesta. L'account di archiviazione creato conterrà lo script HiveQL di esempio, partitionweblogs.hql, che consente di simulare un processo Apache Hive di esempio eseguito nel cluster.
In questa sezione viene usato uno script Azure PowerShell per creare l'account di archiviazione e copiare i file necessari al suo interno. Lo script di esempio di Azure PowerShell di questa sezione consente di eseguire queste operazioni:
- Accedere ad Azure.
- Crea un gruppo di risorse di Azure.
- Creare un account di Archiviazione di Azure.
- Creare un contenitore BLOB nell'account di archiviazione
- Copiare lo script HiveQL di esempio (partitionweblogs.hql) nel contenitore BLOB. Lo script di esempio è già disponibile in un altro contenitore BLOB pubblico. Questo script di PowerShell esegue una copia di questi file nell'account di archiviazione di Azure creato.
Creare l'account di archiviazione e copiare i file
Importante
Specificare i nomi del gruppo di risorse di Azure e dell'account di archiviazione di Azure che verranno creati dallo script. Prendere nota del nome del gruppo di risorse, del nome dell'account di archiviazione e della chiave dell'account di archiviazione restituiti dallo script. Sono necessari nella sezione successiva.
$resourceGroupName = "<Azure Resource Group Name>"
$storageAccountName = "<Azure Storage Account Name>"
$location = "East US"
$sourceStorageAccountName = "hditutorialdata"
$sourceContainerName = "adfv2hiveactivity"
$destStorageAccountName = $storageAccountName
$destContainerName = "adfgetstarted" # don't change this value.
####################################
# Connect to Azure
####################################
#region - Connect to Azure subscription
Write-Host "`nConnecting to your Azure subscription ..." -ForegroundColor Green
$sub = Get-AzSubscription -ErrorAction SilentlyContinue
if(-not($sub))
{
Connect-AzAccount
}
# If you have multiple subscriptions, set the one to use
# Select-AzSubscription -SubscriptionId "<SUBSCRIPTIONID>"
#endregion
####################################
# Create a resource group, storage, and container
####################################
#region - create Azure resources
Write-Host "`nCreating resource group, storage account and blob container ..." -ForegroundColor Green
New-AzResourceGroup `
-Name $resourceGroupName `
-Location $location
New-AzStorageAccount `
-ResourceGroupName $resourceGroupName `
-Name $destStorageAccountName `
-Kind StorageV2 `
-Location $location `
-SkuName Standard_LRS `
-EnableHttpsTrafficOnly 1
$destStorageAccountKey = (Get-AzStorageAccountKey `
-ResourceGroupName $resourceGroupName `
-Name $destStorageAccountName)[0].Value
$sourceContext = New-AzStorageContext `
-StorageAccountName $sourceStorageAccountName `
-Anonymous
$destContext = New-AzStorageContext `
-StorageAccountName $destStorageAccountName `
-StorageAccountKey $destStorageAccountKey
New-AzStorageContainer `
-Name $destContainerName `
-Context $destContext
#endregion
####################################
# Copy files
####################################
#region - copy files
Write-Host "`nCopying files ..." -ForegroundColor Green
$blobs = Get-AzStorageBlob `
-Context $sourceContext `
-Container $sourceContainerName `
-Blob "hivescripts\hivescript.hql"
$blobs|Start-AzStorageBlobCopy `
-DestContext $destContext `
-DestContainer $destContainerName `
-DestBlob "hivescripts\partitionweblogs.hql"
Write-Host "`nCopied files ..." -ForegroundColor Green
Get-AzStorageBlob `
-Context $destContext `
-Container $destContainerName
#endregion
Write-host "`nYou will use the following values:" -ForegroundColor Green
write-host "`nResource group name: $resourceGroupName"
Write-host "Storage Account Name: $destStorageAccountName"
write-host "Storage Account Key: $destStorageAccountKey"
Write-host "`nScript completed" -ForegroundColor Green
Verificare l'account di archiviazione
- Accedere al portale di Azure.
- Da sinistra passare a Tutti i servizi>Generale>Gruppi di risorse.
- Selezionare il nome del gruppo di risorse creato con lo script di PowerShell. Se sono presenti troppi gruppi di risorse elencati, usare il filtro.
- Nella visualizzazione Panoramica è visibile una sola risorsa, a meno che il gruppo di risorse non sia condiviso con altri progetti. Tale risorsa è l'account di archiviazione con il nome specificato in precedenza. Selezionare il nome dell'account di archiviazione.
- Selezionare il riquadro Contenitori.
- Fare clic sul contenitore adfgetstarted. Viene visualizzata una cartella denominata
hivescripts. - Aprire la cartella e assicurarsi che contenga il file di script di esempio partitionweblogs.hql.
Comprendere l'attività di Azure Data Factory
Azure Data Factory orchestra e automatizza lo spostamento e la trasformazione dei dati. Azure Data Factory può creare un cluster Hadoop di HDInsight JIT per elaborare una sezione dati di input ed eliminare il cluster al termine dell'elaborazione.
In Azure Data Factory, una data factory può includere una o più pipeline di dati. Una pipeline di dati include una o più attività. Sono disponibili due tipi di attività:
- Attività di spostamento dati. Le attività di spostamento dati consentono di spostare dati da un archivio dati di origine a un archivio dati di destinazione.
- Attività di trasformazione dei dati. Le attività di trasformazione dei dati vengono usate per trasformare/elaborare i dati. L'attività Hive di HDInsight è una delle attività di trasformazione supportate da Data Factory. L'attività di trasformazione Hive verrà usata in questa esercitazione.
In questo articolo viene configurata l'attività Hive per la creazione di un cluster Hadoop di HDInsight on demand. Ecco cosa accade quando l'attività viene eseguita per elaborare i dati:
Viene creato automaticamente un cluster Hadoop di HDInsight JIT per elaborare la sezione.
I dati di input vengono elaborati eseguendo uno script HiveQL nel cluster. In questa esercitazione, lo script HiveQL associato all'attività Hive esegue queste azioni:
- Usa la tabella esistente (hivesampletable) per creare un'altra tabella HiveSampleOut.
- Popola la tabella HiveSampleOut solo con colonne specifiche dalla tabella hivesampletable originale.
Il cluster Hadoop di HDInsight viene eliminato al termine dell'elaborazione ed è inattivo per l'intervallo di tempo configurato (impostazione timeToLive). Se la sezione dati successiva è disponibile per l'elaborazione entro il tempo di inattività di timeToLive, per l'elaborazione della sezione viene usato lo stesso cluster.
Creare una data factory
Accedere al portale di Azure.
Dal menu a sinistra passare a
+ Create a resource>Analytics>Data Factory.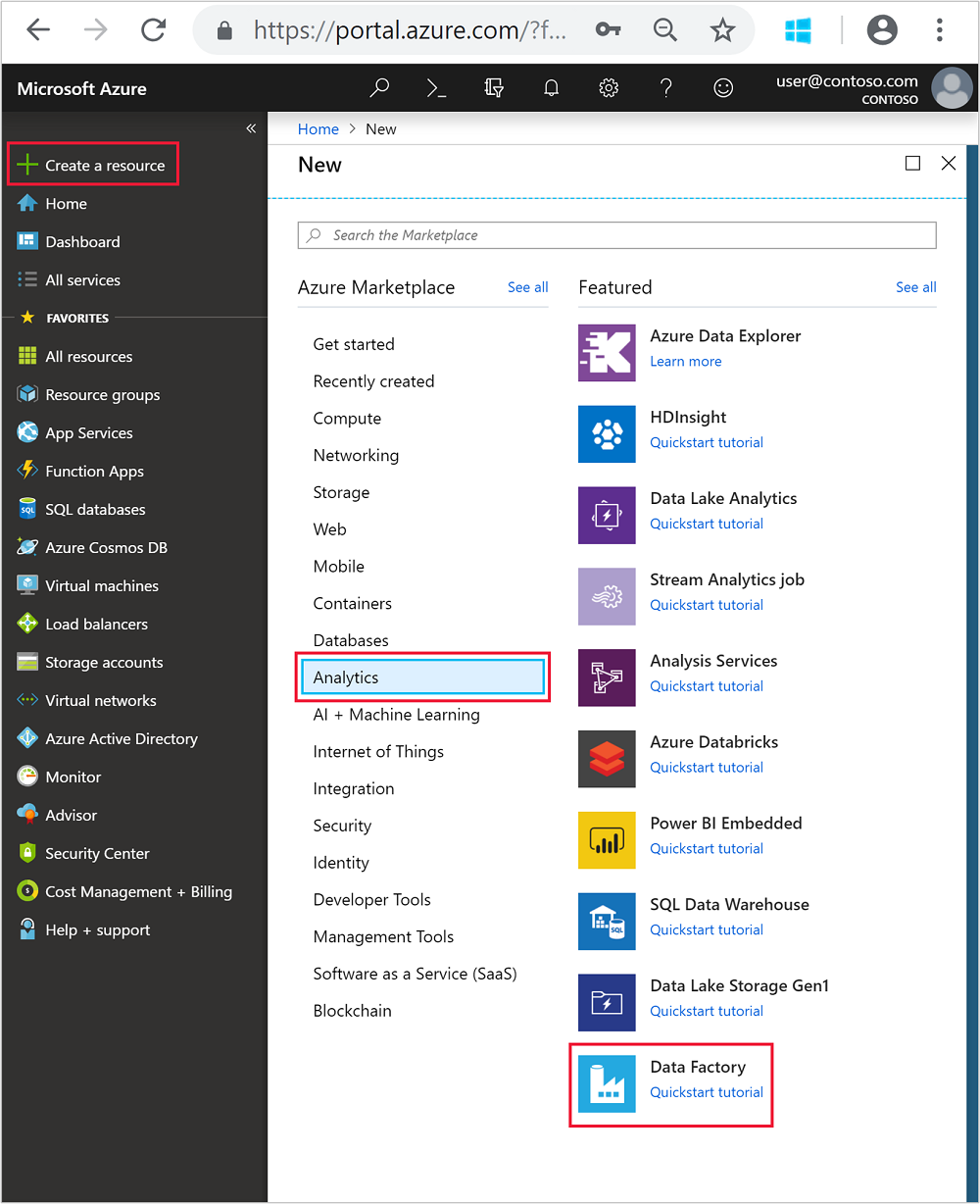
Immettere o selezionare i valori seguenti per il riquadro Nuova data factory:
Proprietà valore Nome Immettere un nome per la data factory. Il nome deve essere univoco a livello globale. Versione Lasciare V2. Abbonamento Seleziona la tua sottoscrizione di Azure. Gruppo di risorse Selezionare il gruppo di risorse creato con lo script di PowerShell. Ufficio Il percorso viene automaticamente impostato sulla posizione specificata durante la creazione del gruppo di risorse precedente. Per questa esercitazione la posizione è impostata su Stati Uniti orientali. Abilitare GIT Deselezionare questa casella. 
Seleziona Crea. La creazione di una data factory potrebbe richiedere tra 2 e 4 minuti.
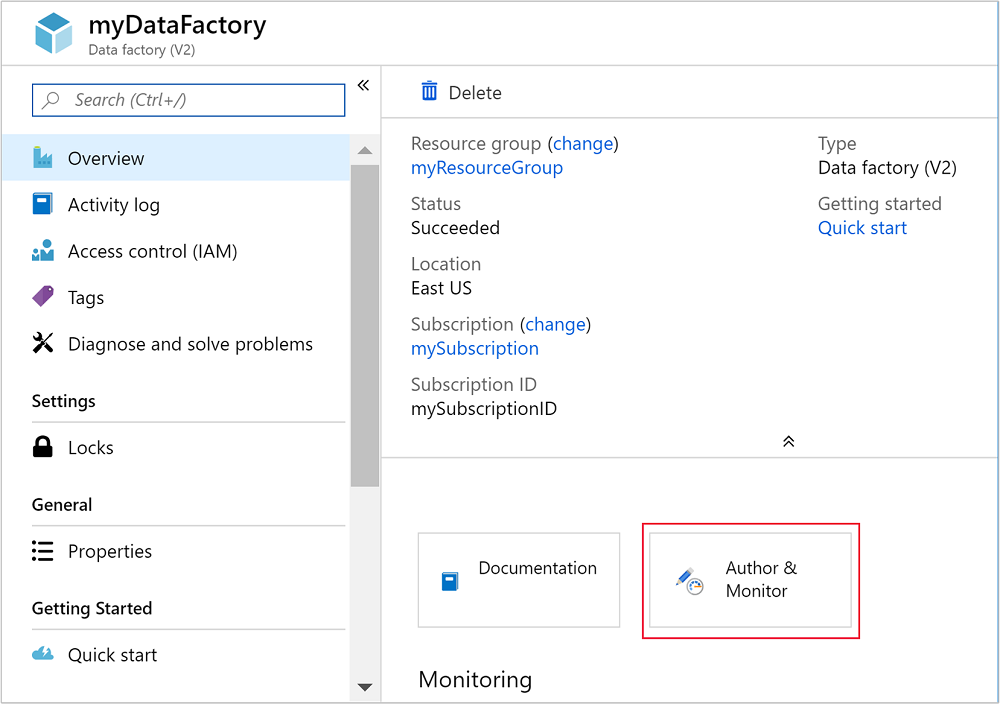
Dopo aver creato la data factory, si riceverà la notifica La distribuzione è riuscita con il pulsante Vai alla risorsa. Selezionare Vai alla risorsa per aprire la visualizzazione predefinita di Data Factory.
Selezionare Crea e monitora per avviare il portale di creazione e monitoraggio di Azure Data Factory.
Creare servizi collegati
In questa sezione si creano due servizi collegati nella data factory.
- Un servizio collegato Archiviazione di Azure che collega un account di archiviazione di Azure alla data factory. Questo archivio viene usato dal cluster HDInsight su richiesta. Include anche lo script Hive che è in esecuzione nel cluster.
- Un servizio collegato HDInsight su richiesta. Azure Data Factory crea automaticamente un cluster HDInsight ed esegue lo script Hive. Elimina quindi il cluster HDInsight dopo un tempo di inattività preconfigurato.
Creare un servizio collegato Archiviazione di Azure
Nel riquadro a sinistra nella pagina Attività iniziali selezionare l'icona Autore.

Selezionare Connessioni nell'angolo inferiore sinistro della finestra e quindi + Nuovo.
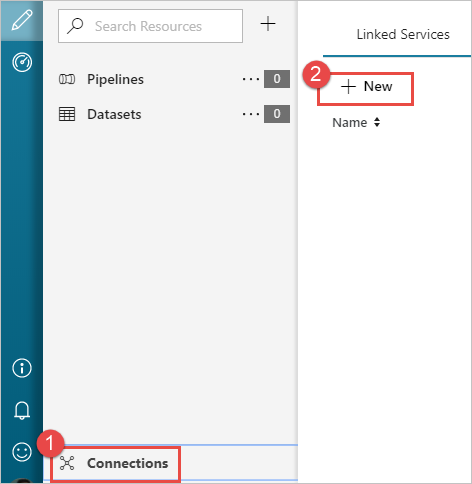
Nella finestra di dialogo New Linked Service (Nuovo servizio collegato) selezionare Archiviazione BLOB di Azure e quindi Continua.
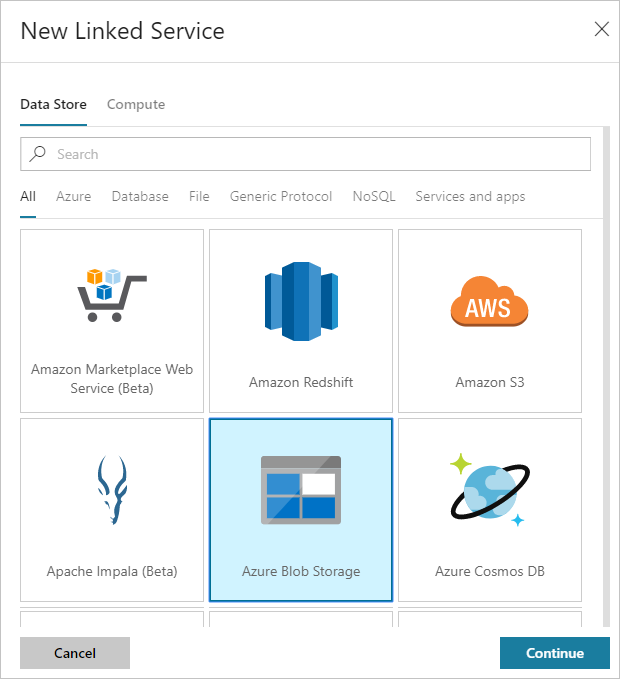
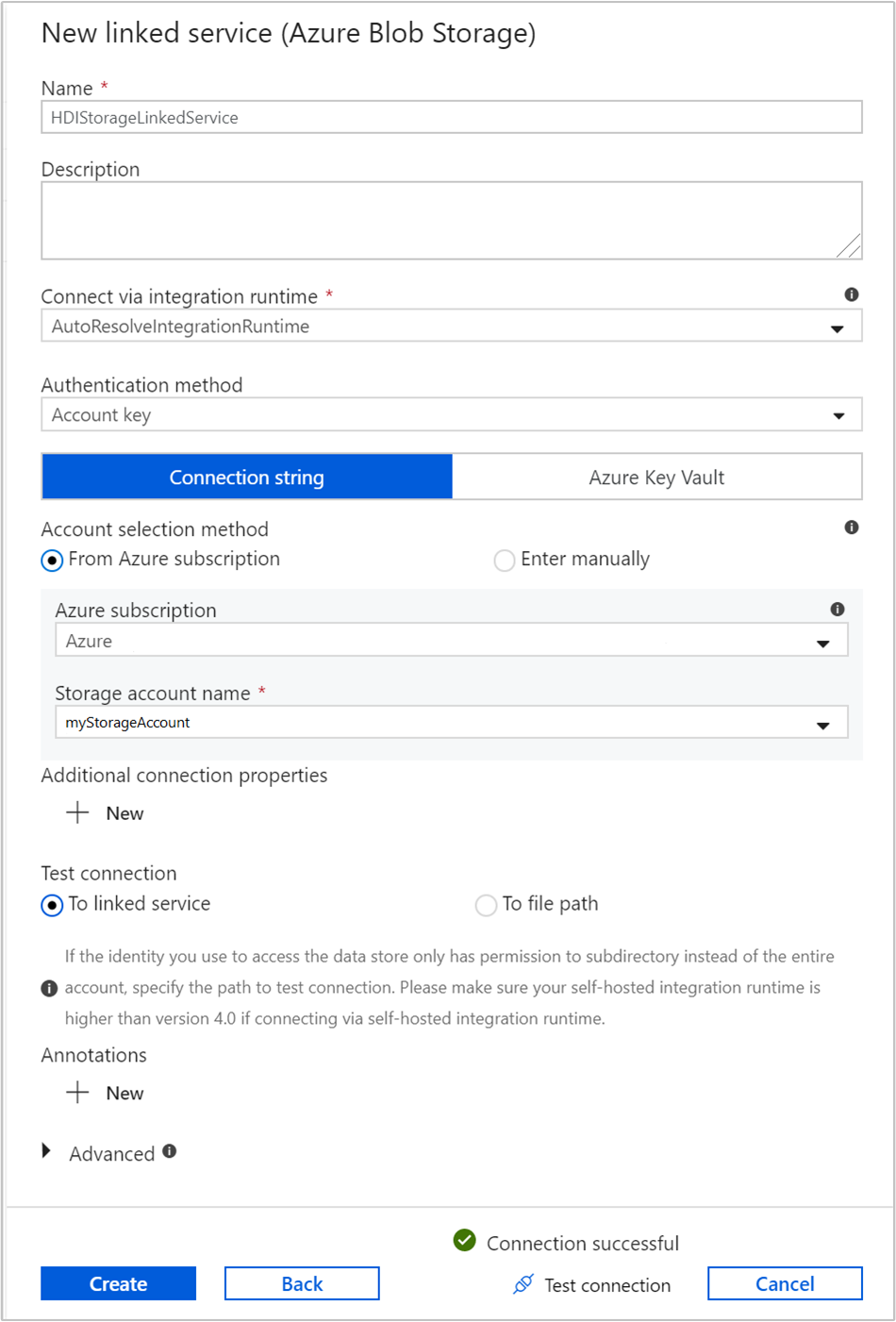
Specificare i valori seguenti per il servizio collegato di archiviazione:
Proprietà valore Nome Immetti HDIStorageLinkedService.Sottoscrizione di Azure Selezionare la sottoscrizione dall'elenco a discesa. Nome account di archiviazione Selezionare l'account di Archiviazione di Azure creato con lo script di PowerShell. Selezionare Test connessione e se l'operazione riesce selezionare Crea.
Creare un servizio collegato HDInsight su richiesta
Selezionare il pulsante + Nuovo per creare un altro servizio collegato.
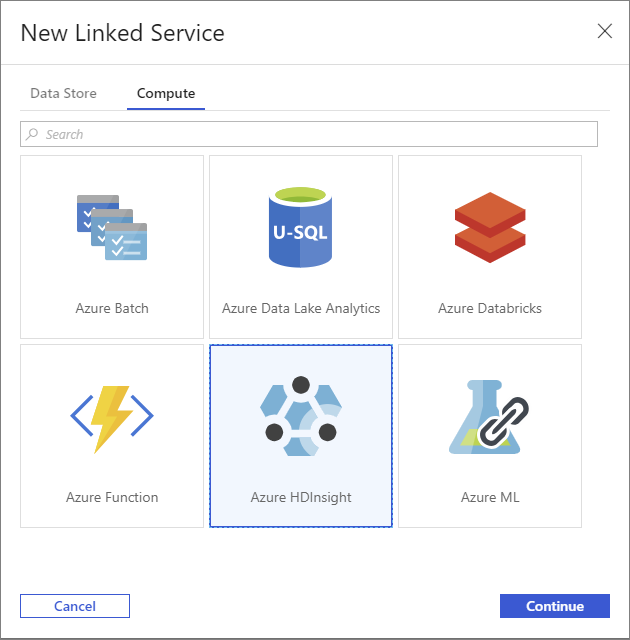
Nella finestra Nuovo Servizio collegato selezionare la scheda Calcolo.
Selezionare Azure HDInsight e quindi selezionare Continua.
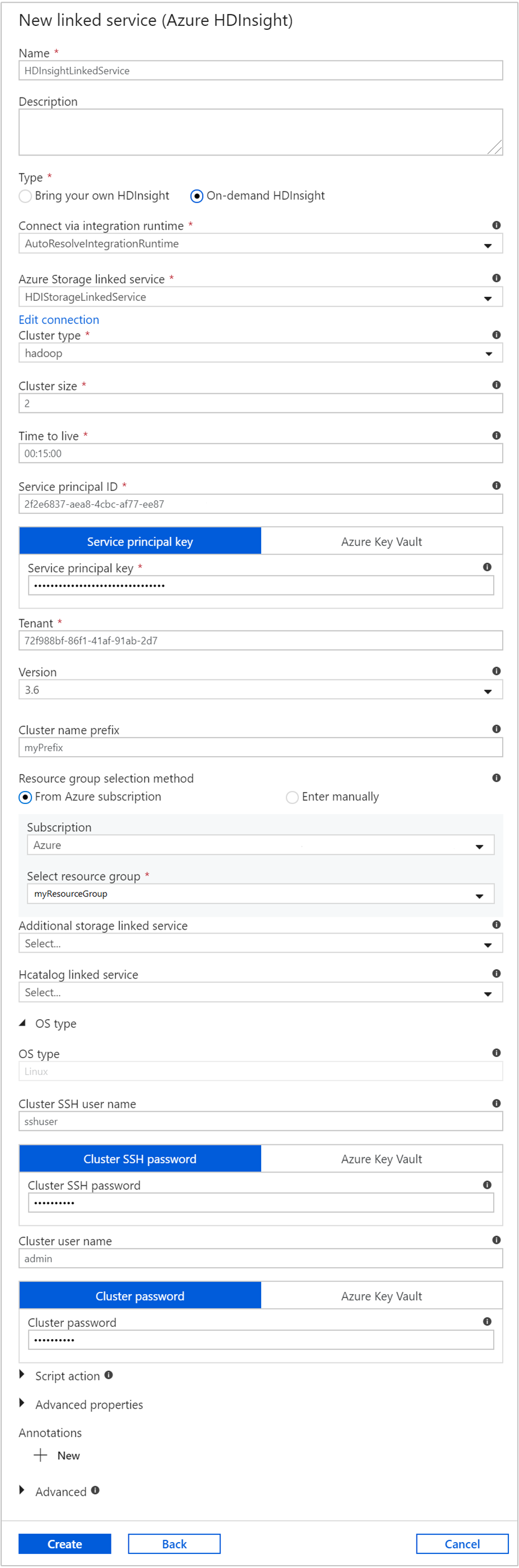
Nella finestra Nuovo Servizio collegato immettere i valori seguenti e lasciare le altre impostazioni sui valori predefiniti:
Proprietà valore Nome Immetti HDInsightLinkedService.Type Selezionare On-demand HDInsight (HDInsight su richiesta). Servizio collegato Archiviazione di Azure Selezionare HDIStorageLinkedService.Tipo di cluster Selezionare hadoop Durata (TTL) Specificare il periodo per cui si desidera che il cluster HDInsight sia disponibile prima di essere eliminato automaticamente. ID entità servizio Specificare l'ID applicazione dell'entità servizio Microsoft Entra creata come parte dei prerequisiti. Chiave entità servizio Specificare la chiave di autenticazione per l'entità servizio Microsoft Entra. Prefisso nome cluster Specificare il valore che verrà usato come prefisso per tutti i tipi di cluster creati dalla data factory. Abbonamento Selezionare la sottoscrizione dall'elenco a discesa. Seleziona gruppo di risorse Selezionare il gruppo di risorse creato dallo script PowerShell usato in precedenza. Nome utente SSH tipo sistema operativo/cluster Immettere un nome utente SSH, in genere sshuser.Password SSH tipo sistema operativo/cluster Fornire una password per l'utente SSH Nome utente tipo sistema operativo/cluster Immettere un nome utente cluster, in genere admin.Password tipo sistema operativo/cluster Specificare una password per l'utente del cluster. Selezionare Crea.
Creare una pipeline
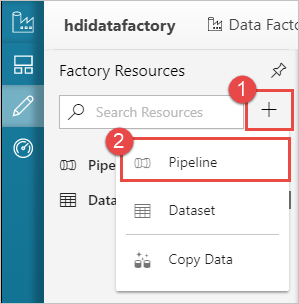
Selezionare il pulsante + (segno più) e quindi selezionare Pipeline.
Nella casella degli strumenti Attività espandere HDInsight e trascinare l'attività Hive nell'area di progettazione della pipeline. Nella scheda Generale specificare un nome per l'attività.
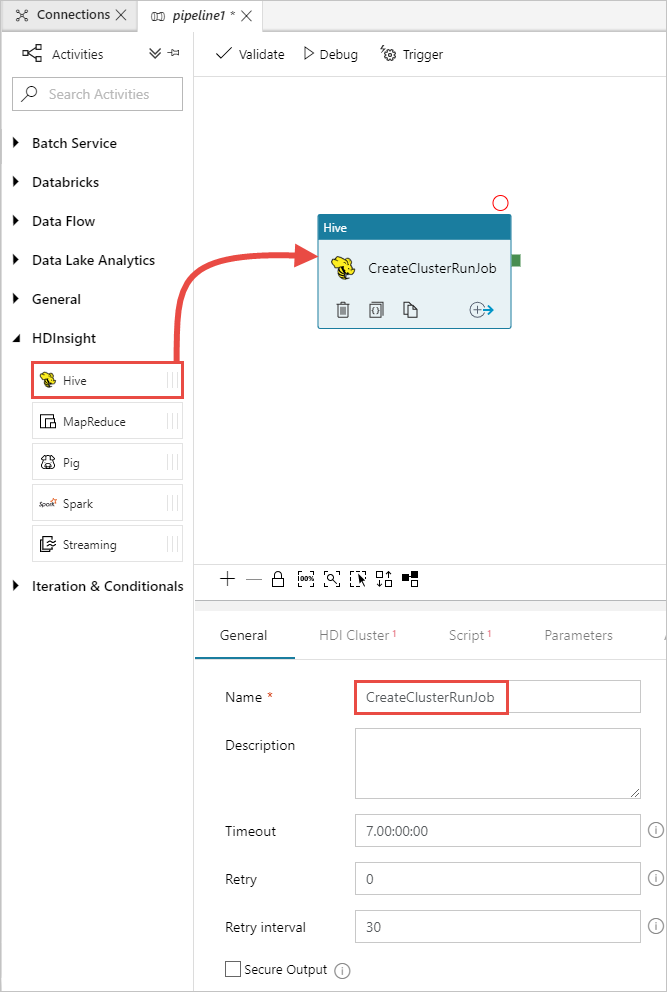
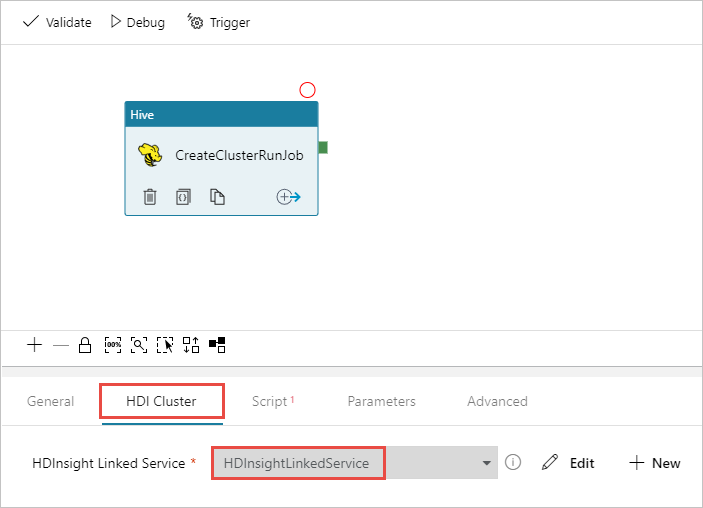
Assicurarsi di avere selezionato l'attività Hive, selezionare la scheda Cluster HDI. Nell'elenco a discesa Servizio collegato HDInsight selezionare il servizio collegato creato in precedenza, HDInsightLinkedService, per HDInsight.
Selezionare la scheda Script e completare questa procedura:
Per Servizio script collegato selezionare HDIStorageLinkedService dall'elenco a discesa. Questo è il valore del servizio di archiviazione collegato creato in precedenza.
Per Percorso file, selezionare Sfoglia risorsa di archiviazione e passare alla posizione in cui si trova lo script Hive di esempio. Se in precedenza è stato eseguito lo script di PowerShell, il percorso dovrebbe essere
adfgetstarted/hivescripts/partitionweblogs.hql.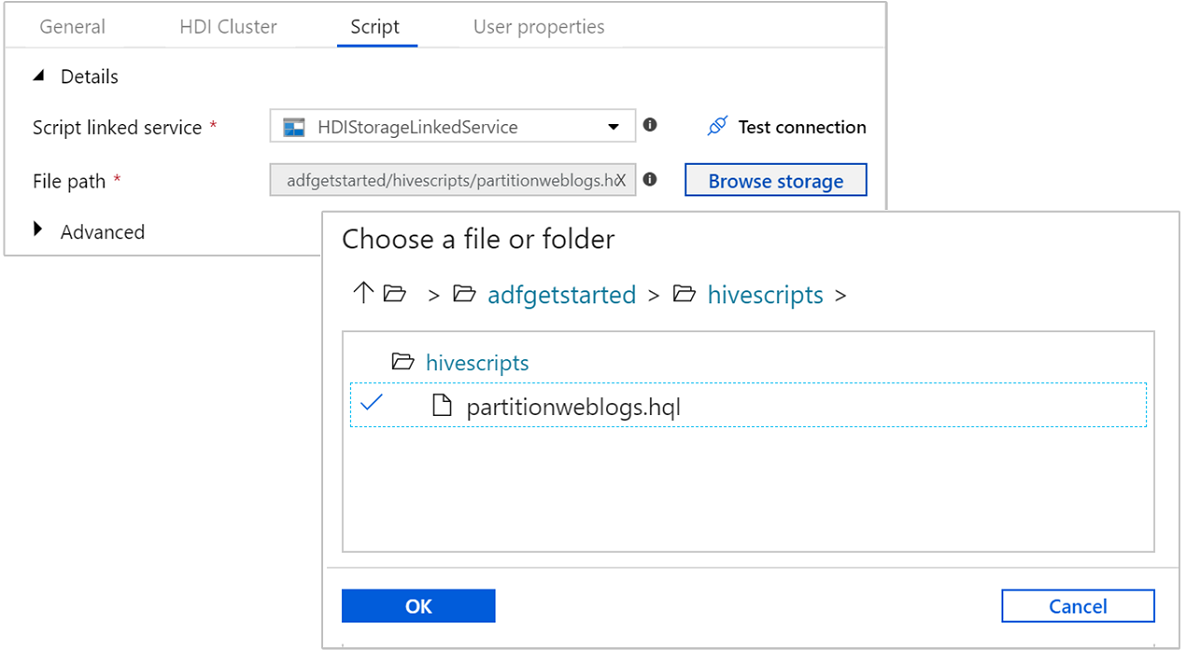
In Advanced>Parameters (Avanzate > Parametri) selezionare
Auto-fill from script. Questa opzione ricerca tutti i parametri nello script Hive che richiedono valori in fase di esecuzione.Nella casella di testo Valore aggiungere la cartella esistente nel formato
wasbs://adfgetstarted@<StorageAccount>.blob.core.windows.net/outputfolder/. Per il percorso viene applicata la distinzione tra maiuscole e minuscole. Questo è il percorso in cui verrà archiviato l'output dello script. Lo schemawasbsè necessario perché per gli account di archiviazione è ora abilitato il trasferimento sicuro necessario per impostazione predefinita.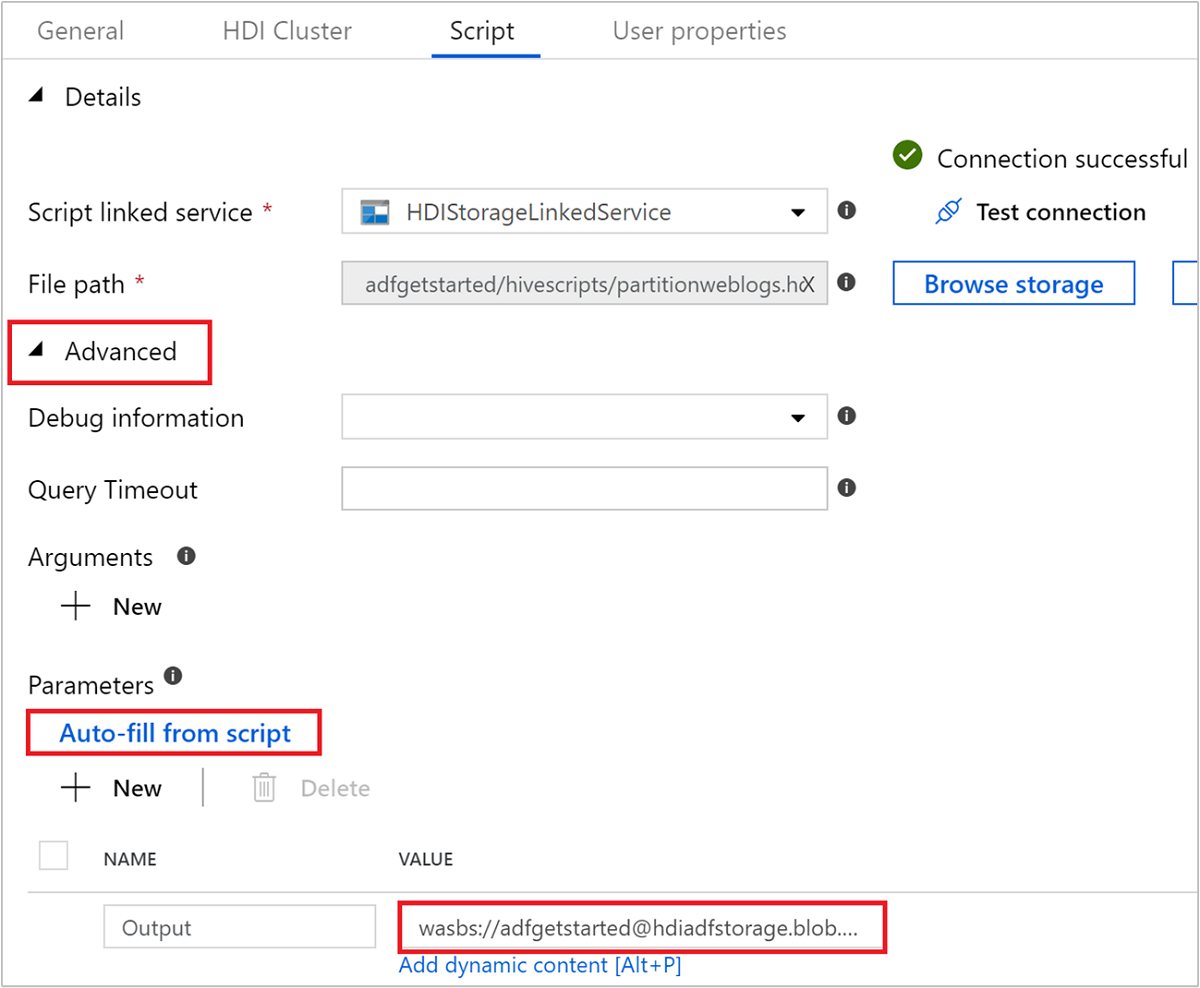
Per convalidare la pipeline, selezionare Convalida. Selezionare il pulsante >> (freccia destra) per chiudere la finestra di convalida.
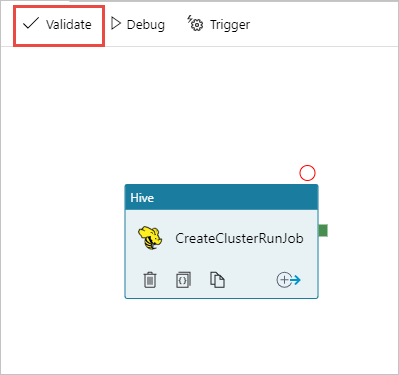
Infine, selezionare Publish All (Pubblica tutti) per pubblicare gli artefatti in Azure Data Factory.
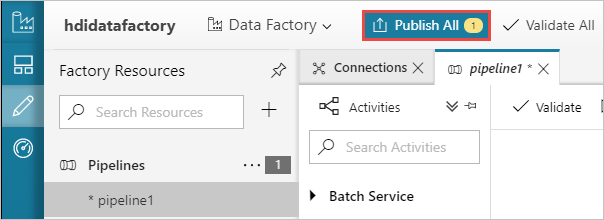
Attivare una pipeline
Sulla barra degli strumenti della finestra di progettazione selezionare Aggiungi trigger>Trigger now (Attiva ora).
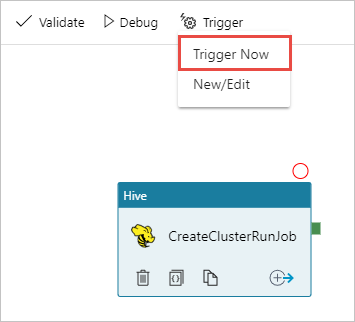
Selezionare OK nella barra laterale popup.
Monitorare una pipeline
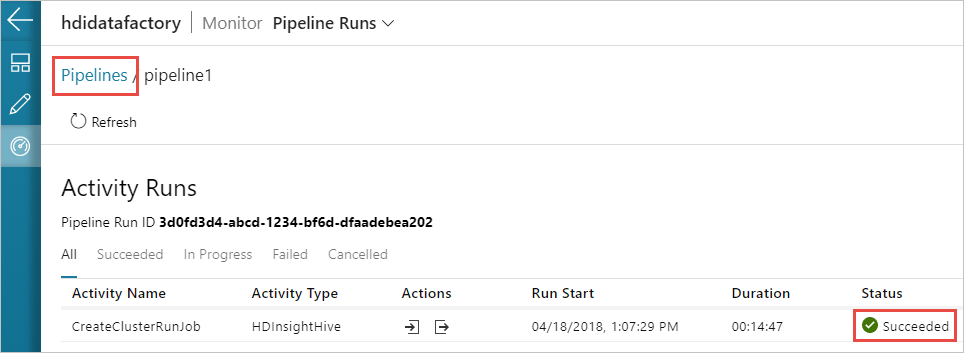
Passare alla scheda Monitoraggio a sinistra. Nell'elenco Pipeline Runs (Esecuzioni di pipeline) verrà visualizzata un'esecuzione della pipeline. Si noti lo stato di esecuzione nella colonna Stato.
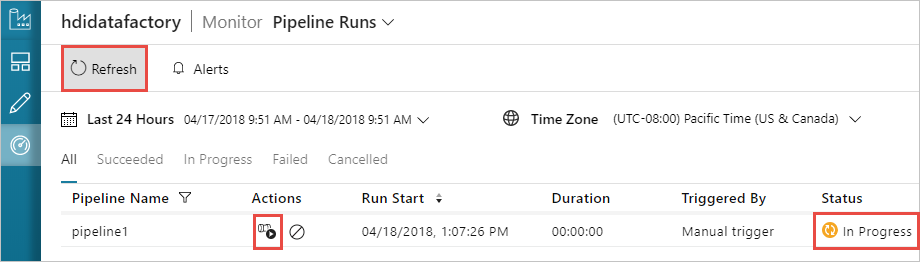
Selezionare Aggiorna per aggiornare lo stato.
È anche possibile selezionare l'icona View Activity Runs (Visualizza le esecuzioni di attività) per visualizzare le esecuzioni di attività associate alla pipeline. Nello screenshot qui di seguito viene visualizzata una sola esecuzione di attività perché la pipeline creata contiene una sola attività. Per tornare alla visualizzazione precedente, selezionare Pipeline nella parte superiore della pagina.
Verificare l'output
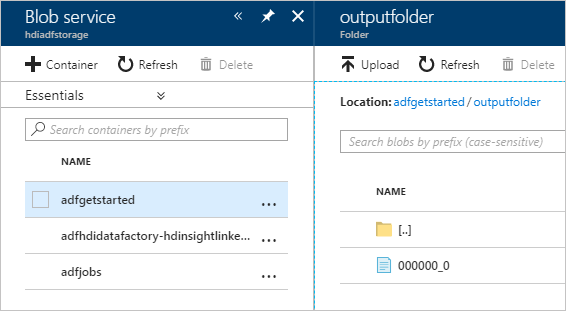
Per verificare l'output, nel portale di Azure passare all'account di archiviazione usato per questa esercitazione. Verranno visualizzate le cartelle o i contenitori seguenti:
Viene visualizzato adfgerstarted/outputfolder che contiene l'output dello script Hive che è stato eseguito come parte della pipeline.
Viene visualizzato un contenitore adfhdidatafactory-linked-service-name-timestamp<<>>. Questo contenitore è il percorso di archiviazione predefinito del cluster HDInsight che è stato creato come parte dell'esecuzione della pipeline.
Viene visualizzato un contenitore adfjobs che include i log del processo di Azure Data Factory.
Pulire le risorse
Con la creazione del cluster HDInsight su richiesta non è necessario eliminare in modo esplicito il cluster HDInsight. Il cluster verrà eliminato in base alla configurazione fornita durante la creazione della pipeline. Anche dopo l'eliminazione del cluster, gli account di archiviazione a esso associati continuano a esistere. Questo comportamento è previsto da progettazione per mantenere intatti i dati. Tuttavia, se non si intende rendere persistenti i dati, è possibile eliminare l'account di archiviazione creato.
In alternativa, è possibile eliminare l'intero gruppo di risorse creato per questa esercitazione. Ciò consente di eliminare l'account di archiviazione e Azure Data Factory creati.
Eliminare il gruppo di risorse
Accedere al portale di Azure.
Selezionare Gruppi di risorse nel riquadro di sinistra.
Selezionare il nome del gruppo di risorse creato con lo script di PowerShell. Se sono presenti troppi gruppi di risorse elencati, usare il filtro. Si apre il pannello del gruppo di risorse.
Nel riquadro Risorse dovrebbe essere indicato l'account di archiviazione predefinito e l'istanza Data Factory, a meno che il gruppo di risorse non sia condiviso con altri progetti.
Selezionare Elimina gruppo di risorse. In questo modo si eliminano l'account di archiviazione e i dati in esso archiviati.
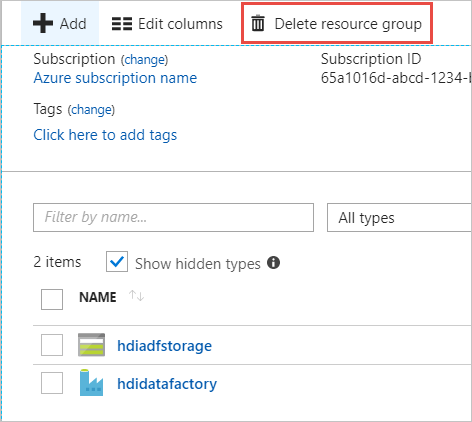
Immettere il nome del gruppo di risorse per confermare l'eliminazione e quindi fare clic su Elimina.
Passaggi successivi
Questo articolo descrive come usare Azure Data Factory per creare il cluster HDInsight on demand per l'elaborazione dei processi Apache Hive. Passare al prossimo articolo per apprendere come creare cluster HDInsight con una configurazione personalizzata.