Ottimizzare le query Apache Hive in Azure HDInsight
Questo articolo descrive alcune delle ottimizzazioni delle prestazioni più comuni che è possibile usare per migliorare le prestazioni delle query Apache Hive.
Selezione del tipo di cluster
In Azure HDInsight è possibile eseguire query Apache Hive in diversi tipi di cluster.
Scegliere il tipo di cluster appropriato per ottimizzare le prestazioni per le esigenze del carico di lavoro:
- Scegliere Il tipo di cluster Interactive Query per ottimizzare per
ad hocle query interattive. - Scegliere il tipo di cluster Apache Hadoop per ottimizzare le query Hive usate come processo batch.
- I tipi di cluster Spark e HBase possono anche eseguire query Hive e potrebbero essere appropriate se si eseguono tali carichi di lavoro.
Per altre informazioni sull'esecuzione di query Hive in vari tipi di cluster HDInsight, vedere What is Apache Hive and HiveQL on Azure HDInsight? (Che cosa sono Apache Hive e HiveQL in Azure HDInsight?).
Scalabilità orizzontale dei nodi di lavoro
L'aumento del numero di nodi di lavoro in un cluster HDInsight consente di usare più mapper e riduttori da eseguire in parallelo. Esistono due modi per aumentare la scalabilità orizzontale in HDInsight:
Quando si crea un cluster, è possibile specificare il numero di nodi di lavoro usando il portale di Azure, Azure PowerShell o l'interfaccia della riga di comando. Per altre informazioni, vedere Creare cluster Hadoop in HDInsight. La schermata seguente mostra la configurazione dei nodi del ruolo di lavoro nel portale di Azure:
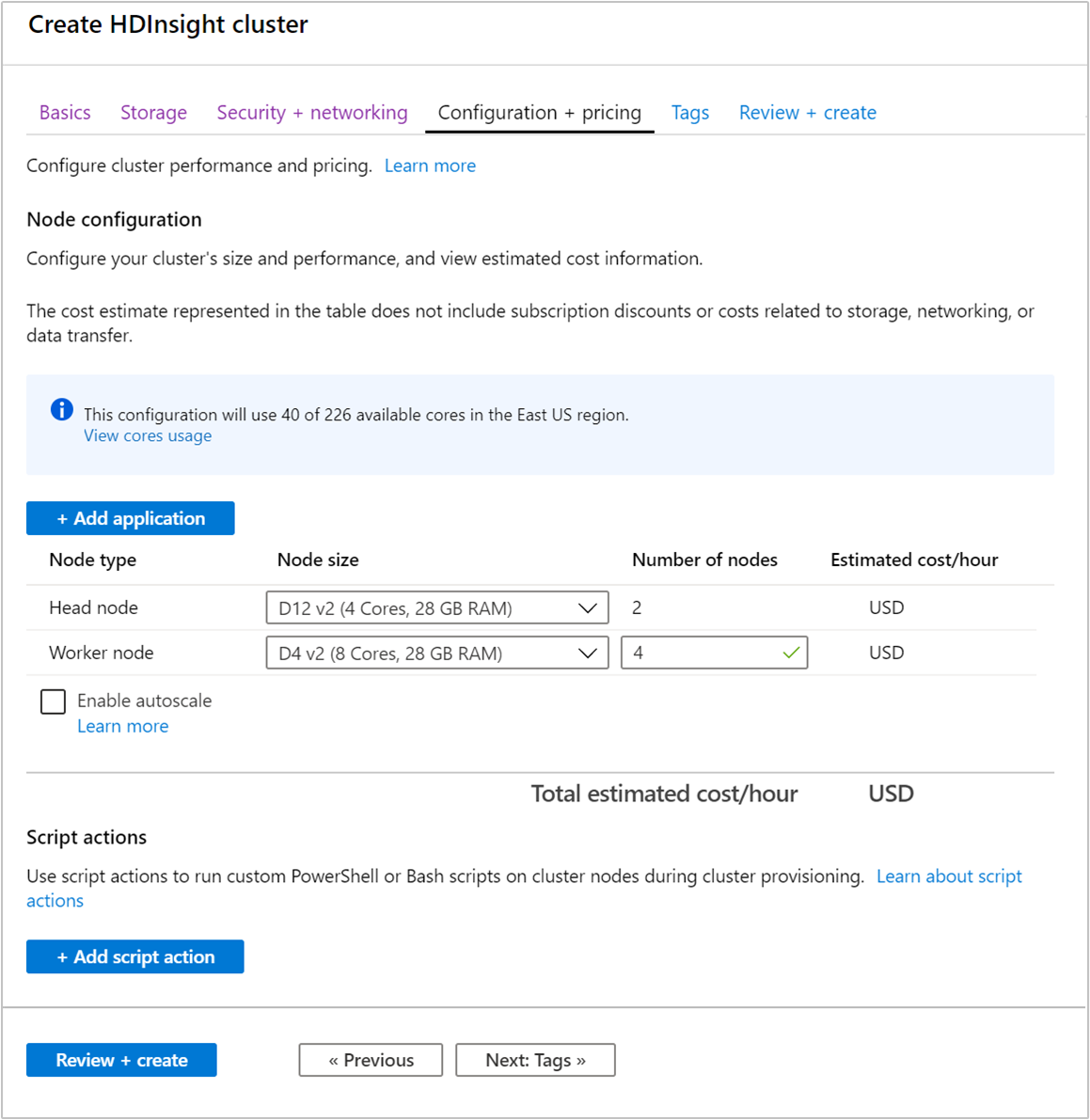
Dopo avere creato il cluster, è possibile anche modificare il numero di nodi del ruolo di lavoro per aumentare il numero di istanze per il cluster senza ricrearne uno:
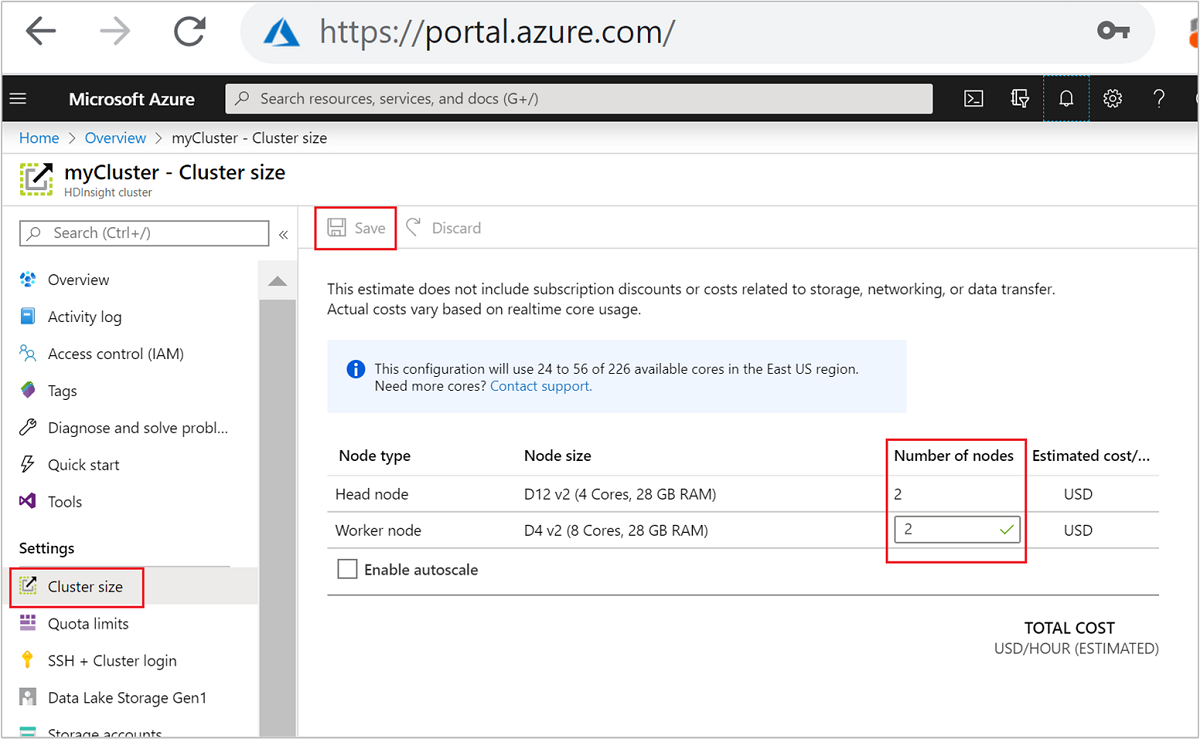
Per altre informazioni sulla scalabilità di HDInsight, vedere Scale HDInsight clusters (Scalare i cluster HDInsight)
Uso di Apache Tez al posto di MapReduce
Apache Tez è un motore di esecuzione alternativo al motore di MapReduce. I cluster HDInsight basati su Linux hanno Tez abilitato per impostazione predefinita.
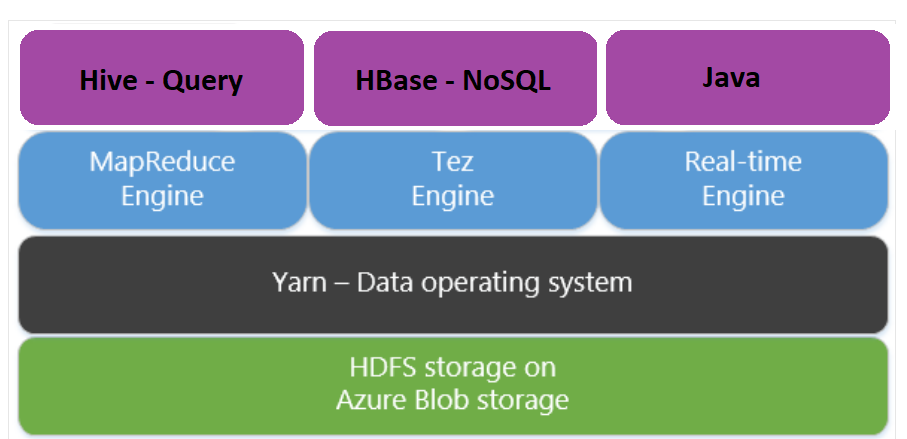
Tez è più veloce perché:
- Esegue un grafo aciclico diretto (DAG) come un singolo processo nel motore di MapReduce. Il DAG richiede che ogni set di mapper sia seguito da un set di reducer. tale requisito determina più processi MapReduce da eseguire per ciascuna query Hive. Tez non presenta questo vincolo e può elaborare DAG complessi con un unico processo, riducendo così il sovraccarico di avvio del processo.
- Evita scritture non necessarie. Nel motore di MapReduce vengono usati più processi per elaborare la stessa query Hive. L'output di ogni processo di MapReduce viene scritto in Hadoop Distributed File System (HDFS) per quanto riguarda i dati intermedi. Poiché Tez riduce il numero di processi per ciascuna query Hive è in grado di evitare scritture non necessarie.
- Riduce al minimo i ritardi di avvio. Tez è in grado di ridurre al minimo il ritardo di avvio limitando il numero di mapper da avviare e migliorando anche l'ottimizzazione complessiva.
- Riusa i contenitori. Quando possibile, Tez è in grado di riusare i contenitori per assicurare che la latenza dovuta all'avvio dei contenitori venga ridotta.
- Usa tecniche di ottimizzazione continua. In genere l'ottimizzazione viene eseguita durante la fase di compilazione. Tuttavia, sono disponibili ulteriori informazioni sugli input che consentono una migliore ottimizzazione durante il runtime. Tez usa tecniche di ottimizzazione continua che consentono di ottimizzare ulteriormente il piano nella fase di runtime.
Per altre informazioni su questi concetti, vedere Apache TEZ.
È possibile eseguire qualsiasi query Hive per cui Tez è abilitato anteponendovi il comando set seguente:
set hive.execution.engine=tez;
Partizionamento Hive
Le operazioni di I/O rappresentano il principale collo di bottiglia nelle prestazioni per l'esecuzione di query Hive. Le prestazioni possono essere migliorate se è possibile ridurre la quantità di dati da leggere. Per impostazione predefinita, le query Hive analizzano intere tabelle Hive. ma per le query che devono analizzare solo una piccola quantità di dati, ad esempio le query con filtro, viene creato un sovraccarico non necessario. Il partizionamento Hive consente alle query Hive di accedere solo alla quantità di dati presente nelle tabelle Hive necessaria.
Il partizionamento Hive viene implementato riorganizzando i dati non elaborati in nuove directory. Ogni partizione ha una propria directory di file L'utente definisce il partizionamento. Il diagramma seguente illustra il partizionamento di una tabella Hive mediante la colonna Anno. Viene creata una nuova directory per ogni anno.
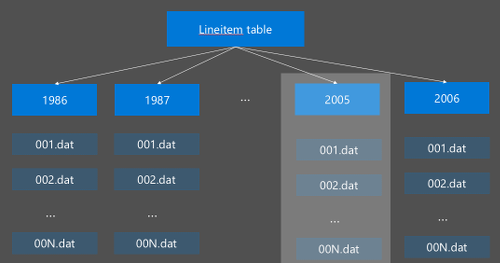
Alcune considerazioni sul partizionamento:
- Non eseguire la partizione : il partizionamento delle colonne con solo alcuni valori può causare poche partizioni. Ad esempio, il partizionamento sul sesso crea solo due partizioni da creare (maschio e femmina), quindi ridurre la latenza di un massimo di metà.
- Non eseguire la partizione : nell'altro estremo, la creazione di una partizione in una colonna con un valore univoco (ad esempio userid) causa più partizioni. generando un sovraccarico nel nodo dei nomi del cluster, che dovrà gestire una grande quantità di directory.
- Evitare lo sfasamento di dati : scegliere la chiave di partizionamento con attenzione, in modo che tutte le partizioni siano di dimensioni pari. Il partizionamento nella colonna Stato ad esempio potrebbe rendere asimmetrica la distribuzione dei dati. Poiché lo stato della California ha una popolazione di quasi 30 volte quella del Vermont, la dimensione della partizione è potenzialmente asimmetrica e le prestazioni possono variare enormemente.
Per creare una tabella di partizione, usare la clausola Partizionato da :
CREATE TABLE lineitem_part
(L_ORDERKEY INT, L_PARTKEY INT, L_SUPPKEY INT,L_LINENUMBER INT,
L_QUANTITY DOUBLE, L_EXTENDEDPRICE DOUBLE, L_DISCOUNT DOUBLE,
L_TAX DOUBLE, L_RETURNFLAG STRING, L_LINESTATUS STRING,
L_SHIPDATE_PS STRING, L_COMMITDATE STRING, L_RECEIPTDATE STRING,
L_SHIPINSTRUCT STRING, L_SHIPMODE STRING, L_COMMENT STRING)
PARTITIONED BY(L_SHIPDATE STRING)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
STORED AS TEXTFILE;
Una volta creata la tabella partizionata, è possibile creare il partizionamento statico o il partizionamento dinamico.
Il partizionamento statico indica che sono già presenti dati partizionati nelle directory appropriate. Con le partizioni statiche, si aggiungono partizioni Hive manualmente in base al percorso di directory. Il frammento di codice seguente rappresenta un esempio.
INSERT OVERWRITE TABLE lineitem_part PARTITION (L_SHIPDATE = '5/23/1996 12:00:00 AM') SELECT * FROM lineitem WHERE lineitem.L_SHIPDATE = '5/23/1996 12:00:00 AM' ALTER TABLE lineitem_part ADD PARTITION (L_SHIPDATE = '5/23/1996 12:00:00 AM') LOCATION 'wasb://sampledata@ignitedemo.blob.core.windows.net/partitions/5_23_1996/'Partizionamento dinamico indica che si desidera che Hive crei le partizioni automaticamente per l'utente. Poiché la tabella di partizionamento è già stata creata dalla tabella di staging, è sufficiente inserire i dati nella tabella partizionata:
SET hive.exec.dynamic.partition = true; SET hive.exec.dynamic.partition.mode = nonstrict; INSERT INTO TABLE lineitem_part PARTITION (L_SHIPDATE) SELECT L_ORDERKEY as L_ORDERKEY, L_PARTKEY as L_PARTKEY, L_SUPPKEY as L_SUPPKEY, L_LINENUMBER as L_LINENUMBER, L_QUANTITY as L_QUANTITY, L_EXTENDEDPRICE as L_EXTENDEDPRICE, L_DISCOUNT as L_DISCOUNT, L_TAX as L_TAX, L_RETURNFLAG as L_RETURNFLAG, L_LINESTATUS as L_LINESTATUS, L_SHIPDATE as L_SHIPDATE_PS, L_COMMITDATE as L_COMMITDATE, L_RECEIPTDATE as L_RECEIPTDATE, L_SHIPINSTRUCT as L_SHIPINSTRUCT, L_SHIPMODE as L_SHIPMODE, L_COMMENT as L_COMMENT, L_SHIPDATE as L_SHIPDATE FROM lineitem;
Per altre informazioni, vedere Partitioned Tables (Tabelle partizionate).
Utilizzare il formato ORCFile
Hive supporta diversi formati di file. Ad esempio:
- Testo: è il formato di file predefinito e funziona con la maggior parte degli scenari.
- Avro: funziona bene per scenari di interoperabilità.
- ORC/Parquet: particolarmente indicato per le prestazioni.
Il formato ORC (Optimized Row Columnar) è un modo particolarmente efficace per archiviare i dati Hive. Rispetto ad altri formati, ORC offre i vantaggi seguenti:
- supporto per tipi complessi, inclusi i tipi complessi e semi-strutturati e DateTime.
- fino al 70% di compressione.
- indici ogni 10.000 righe, che consentono di ignorare le righe.
- una significativa riduzione in fase di esecuzione.
Per abilitare il formato ORC, creare innanzitutto una tabella con la clausola Archiviato come ORC:
CREATE TABLE lineitem_orc_part
(L_ORDERKEY INT, L_PARTKEY INT,L_SUPPKEY INT, L_LINENUMBER INT,
L_QUANTITY DOUBLE, L_EXTENDEDPRICE DOUBLE, L_DISCOUNT DOUBLE,
L_TAX DOUBLE, L_RETURNFLAG STRING, L_LINESTATUS STRING,
L_SHIPDATE_PS STRING, L_COMMITDATE STRING, L_RECEIPTDATE STRING,
L_SHIPINSTRUCT STRING, L_SHIPMODE STRING, L_COMMENT STRING)
PARTITIONED BY(L_SHIPDATE STRING)
STORED AS ORC;
Inserire quindi i dati nella tabella ORC dalla tabella di gestione temporanea. Ad esempio:
INSERT INTO TABLE lineitem_orc
SELECT L_ORDERKEY as L_ORDERKEY,
L_PARTKEY as L_PARTKEY ,
L_SUPPKEY as L_SUPPKEY,
L_LINENUMBER as L_LINENUMBER,
L_QUANTITY as L_QUANTITY,
L_EXTENDEDPRICE as L_EXTENDEDPRICE,
L_DISCOUNT as L_DISCOUNT,
L_TAX as L_TAX,
L_RETURNFLAG as L_RETURNFLAG,
L_LINESTATUS as L_LINESTATUS,
L_SHIPDATE as L_SHIPDATE,
L_COMMITDATE as L_COMMITDATE,
L_RECEIPTDATE as L_RECEIPTDATE,
L_SHIPINSTRUCT as L_SHIPINSTRUCT,
L_SHIPMODE as L_SHIPMODE,
L_COMMENT as L_COMMENT
FROM lineitem;
Altre informazioni sul formato ORC sono disponibili nel manuale del linguaggio Apache Hive.
Vettorizzazione
La vettorizzazione consente ad Hive di elaborare un batch di 1024 righe insieme invece di elaborare una riga alla volta. Ciò significa che le operazioni semplici vengono eseguite più rapidamente poiché è necessario eseguire una quantità inferiore di codice interno.
Per abilitare la vettorizzazione, anteporre alla query Hive la seguente impostazione:
set hive.vectorized.execution.enabled = true;
Per altre informazioni, vedere Esecuzione di query vettorizzate.
Altri metodi di ottimizzazione
Esistono altri metodi di ottimizzazione che è possibile considerare, ad esempio:
- Hive bucket: una tecnica che consente di raggruppare o segmentare grandi set di dati per ottimizzare le prestazioni delle query.
- Ottimizzazione join: ottimizzazione dell'esecuzione di query Hive pianificata per migliorare l'efficienza di join e ridurre la necessità di suggerimenti dell'utente. Per altre informazioni, vedere Ottimizzazione join.
- Aumento dei reducer.
Passaggi successivi
In questo articolo sono stati illustrati vari metodi di ottimizzazione delle query comuni di Hive. Per ulteriori informazioni, vedere gli articoli seguenti: