Apache Phoenix in Azure HDInsight
Apache Phoenix è un livello di database relazionale open source altamente parallelo basato su Apache HBase. Phoenix consente di usare query in stile SQL su HBase. Phoenix usa i driver JDBC sottostanti per consentire agli utenti di creare, eliminare e modificare tabelle, indici, viste e sequenze, nonché righe upsert SQL singolarmente e in blocco. Phoenix usa la compilazione nativa NoSQL anziché MapReduce per compilare query, consentendo la creazione di applicazioni a bassa latenza basate su HBase. Phoenix aggiunge coprocessori per supportare l'esecuzione del codice fornito dal client nello spazio degli indirizzi del server, eseguendo il codice che si trova nello stesso percorso dei dati. Questo approccio consente di ridurre al minimo il trasferimento di dati client/server.
Apache Phoenix consente agli utenti non sviluppatori di gestire query per Big Data usando una sintassi simile a SQL invece della programmazione. A differenza di altri strumenti, ad esempio Apache Hive e Apache Spark SQL, Phoenix è altamente ottimizzato per HBase. Il vantaggio per gli sviluppatori è la possibilità di scrivere query ad alte prestazioni con una quantità di codice molto minore.
Quando si invia una query SQL, Phoenix compila la query in chiamate native di HBase ed esegue l'analisi (o il piano) in parallelo per l'ottimizzazione. Questo livello di astrazione consente allo sviluppatore di evitare la scrittura di processi MapReduce e di concentrarsi invece sulla logica di business e sul flusso di lavoro dell'applicazione correlati all'archiviazione di Big Data con Phoenix.
Ottimizzazione delle prestazioni delle query e altre funzionalità
Apache Phoenix aggiunge diversi miglioramenti e funzionalità per le prestazioni per le query HBase.
Indici secondari
HBase usa un singolo indice con ordinamento lessicografico in base alla chiave di riga primaria. Tali record sono accessibili solo tramite la chiave di riga. Per l'accesso ai record tramite qualsiasi colonna diversa dalla chiave di riga, è necessario eseguire l'analisi di tutti i dati applicando il filtro appropriato. In un indice secondario, le colonne o espressioni indicizzate formano una chiave di riga alternativa, che consente le ricerche e le analisi di intervalli su tale indice.
Creare un indice secondario con il comando CREATE INDEX:
CREATE INDEX ix_purchasetype on SALTEDWEBLOGS (purchasetype, transactiondate) INCLUDE (bookname, quantity);
Questo approccio può produrre un aumento significativo delle prestazioni rispetto all'esecuzione di query con singola indicizzazione. Questo tipo di indice secondario è un indice di copertura, contenente tutte le colonne incluse nella query. Di conseguenza, la ricerca della tabella non è necessaria e l'indice soddisfa l'intera query.
Visualizzazioni
Le viste Phoenix consentono di superare un limite di HBase, a causa del quale le prestazioni iniziano a diminuire quando si creano più di circa 100 tabelle fisiche. Le viste Phoenix consentono a più tabelle virtuali di condividere una sola tabella HBase fisica sottostante.
La creazione di una vista Phoenix è simile all'uso della sintassi standard SQL per le viste. Una differenza è la possibilità di definire le colonne per la vista, oltre alle colonne ereditate dalla relativa tabella di base. È anche possibile aggiungere nuove colonne KeyValue.
Ad esempio, ecco una tabella fisica denominata product_metrics con la definizione seguente:
CREATE TABLE product_metrics (
metric_type CHAR(1) NOT NULL,
created_by VARCHAR,
created_date DATE NOT NULL,
metric_id INTEGER NOT NULL
CONSTRAINT pk PRIMARY KEY (metric_type, created_by, created_date, metric_id));
Definire una vista su questa tabella con colonne aggiuntive:
CREATE VIEW mobile_product_metrics (carrier VARCHAR, dropped_calls BIGINT) AS
SELECT * FROM product_metrics
WHERE metric_type = 'm';
Per aggiungere più colonne in un secondo momento, usare l'istruzione ALTER VIEW.
Analisi con salto
L'analisi con salto usa una o più colonne di un indice composto per trovare valori distinti. Diversamente da un'analisi di intervalli, l'analisi con salto viene implementata tra le righe offrendo prestazioni migliori. Durante l'analisi, il primo valore corrispondente viene ignorato insieme all'indice fino a quando non viene trovato il valore successivo.
Un'analisi con salto usa l'enumerazione SEEK_NEXT_USING_HINT del filtro HBase. Tramite SEEK_NEXT_USING_HINT, l'analisi con salto tiene traccia del set di chiavi o degli intervalli di chiavi di cui viene eseguita la ricerca in ogni colonna. L'analisi skip accetta quindi una chiave passata durante la valutazione del filtro e determina se si tratta di una delle combinazioni. In caso contrario, l'analisi con salto procede con la chiave più alta successiva a cui passare.
Transazioni
Mentre HBase offre transazioni a livello di riga, Phoenix si integra con Tephra per aggiungere il supporto delle transazioni tra righe e tra tabelle con semantica completa ACID.
Come per le transazioni SQL tradizionali, le transazioni implementate tramite il gestore delle transazioni Phoenix consentono di assicurare il corretto upsert dell'unità atomica dei dati, con rollback della transazione se l'operazione upsert ha esito negativo per qualsiasi tabella abilitata per le transazioni.
Per abilitare le transazioni Phoenix, vedere la documentazione sulle transazioni di Apache Phoenix.
Per creare una nuova tabella con transazioni abilitate, impostare la proprietà TRANSACTIONAL su true in un'istruzione CREATE:
CREATE TABLE my_table (k BIGINT PRIMARY KEY, v VARCHAR) TRANSACTIONAL=true;
Per modificare una tabella esistente per renderla transazionale, usare la stessa proprietà in un'istruzione ALTER:
ALTER TABLE my_other_table SET TRANSACTIONAL=true;
Nota
Non è possibile tornare indietro, ovvero trasformare una tabella transazionale in non transazionale.
Tabelle con salting
L'hotspot dei server di area può verificarsi durante la scrittura di record con chiavi sequenziali in HBase. Anche se il cluster include più server di area, tutte le scritture vengono eseguite in uno solo. Questa concentrazione crea il problema di hotspot, ovvero la condizione nella quale il carico di lavoro di scrittura viene gestito da un solo server di area invece di essere distribuito su tutti i server di area disponibili. Poiché ogni area ha una dimensione massima predefinita, quando un'area raggiunge tale limite di dimensioni, viene suddivisa in due aree di piccole dimensioni. In questo caso, una di queste nuove aree accetta tutti i nuovi record, diventando il nuovo hotspot.
Per attenuare questo problema e ottenere prestazioni migliori, usare tabelle pre-suddivise in modo che tutti i server di area vengano usati uniformemente. Phoenix supporta tabelle con salting, aggiungendo in modo trasparente il byte di salt alla chiave di riga per una determinata tabella. La tabella viene pre-suddivisa in base ai limiti del byte di salt per garantire una distribuzione del carico uniforme tra i server di area durante la fase iniziale della tabella. Questo approccio consente di distribuire il carico di lavoro di scrittura su tutti i server di area disponibili, con conseguente miglioramento delle prestazioni di scrittura e di lettura. Per applicare il salting a una tabella, specificare la proprietà di tabella SALT_BUCKETS al momento della creazione della tabella:
CREATE TABLE Saltedweblogs (
transactionid varchar(500) Primary Key,
transactiondate Date NULL,
customerid varchar(50) NULL,
bookid varchar(50) NULL,
purchasetype varchar(50) NULL,
orderid varchar(50) NULL,
bookname varchar(50) NULL,
categoryname varchar(50) NULL,
invoicenumber varchar(50) NULL,
invoicestatus varchar(50) NULL,
city varchar(50) NULL,
state varchar(50) NULL,
paymentamount DOUBLE NULL,
quantity INTEGER NULL,
shippingamount DOUBLE NULL) SALT_BUCKETS=4;
Abilitare e ottimizzare Phoenix con Apache Ambari
Un cluster HBase di HDInsight include l'interfaccia utente di Ambari per apportare modifiche di configurazione.
Per abilitare o disabilitare Phoenix e per controllare le impostazioni di timeout delle query di Phoenix, accedere all'interfaccia utente Web di Ambari (
https://YOUR_CLUSTER_NAME.azurehdinsight.net) usando le credenziali utente di Hadoop.Selezionare HBase nell'elenco dei servizi nel menu a sinistra, quindi selezionare la scheda Configs (Configurazioni).
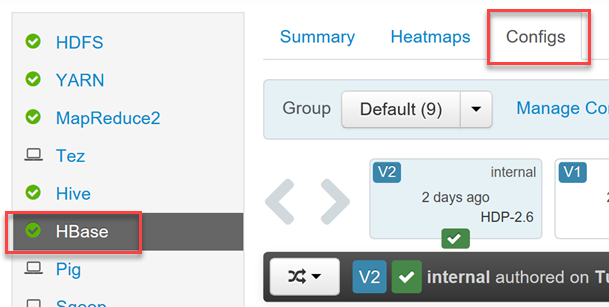
Trovare la sezione di configurazione Phoenix SQL per abilitare o disabilitare Phoenix e impostare il timeout per le query.