Usare MirrorMaker per replicare gli argomenti di Apache Kafka con Kafka in HDInsight
Informazioni su come usare la funzionalità di mirroring di Apache Kafka per replicare gli argomenti in un cluster secondario. È possibile eseguire il mirroring come processo continuo o intermittente per eseguire la migrazione dei dati da un cluster a un altro.
In questo articolo si userà il mirroring per replicare gli argomenti tra due cluster HDInsight. Questi cluster si trovano in reti virtuali diverse in data center diversi.
Avviso
Non usare il mirroring come mezzo per ottenere la tolleranza di errore. L'offset agli elementi all'interno di un argomento è diverso tra i cluster primario e secondario, quindi i client non possono usare i due in modo intercambiabile. Per preservare la tolleranza di errore è necessario impostare la replica per gli argomenti all'interno del cluster. Per altre informazioni, vedere Introduzione ad Apache Kafka in HDInsight.
Funzionamento del mirroring di Apache Kafka
Il mirroring funziona usando lo strumento MirrorMaker , che fa parte di Apache Kafka. MirrorMaker usa i record degli argomenti nel cluster primario e quindi crea una copia locale nel cluster secondario. MirrorMaker usa uno o più consumer che leggono dal cluster primario e un producer che scrive nel cluster locale (secondario).
La configurazione del mirroring più utile per il ripristino di emergenza usa cluster Kafka in aree di Azure diverse. A tale scopo, le reti virtuali in cui risiedono i cluster vengono sottoposte a peering.
Il diagramma seguente illustra il processo di mirroring e il flusso di comunicazione tra i cluster:
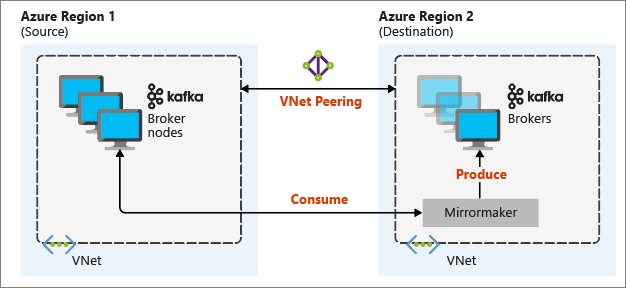
I cluster primari e secondari possono differire per numero di nodi e partizioni. Anche gli offset negli argomenti differiscono. Il mirroring mantiene il valore della chiave usato per il partizionamento, quindi l'ordine dei record viene conservato in base alla chiave.
Mirroring tra i limiti di rete
Se è necessario eseguire il mirroring di cluster Kafka in reti diverse, si notino le seguenti considerazioni aggiuntive:
Gateway: le reti devono poter comunicare a livello di TCP/IP.
Indirizzamento del server: è possibile scegliere di indirizzare i nodi del cluster usando gli indirizzi IP o i nomi di dominio completi.
Indirizzi IP: se si configurano i cluster Kafka per l'uso della pubblicità degli indirizzi IP, è possibile procedere con la configurazione del mirroring usando gli indirizzi IP dei nodi broker e dei nodi ZooKeeper.
Nomi di dominio: se non si configurano i cluster Kafka per la pubblicità degli indirizzi IP, i cluster devono essere in grado di connettersi tra loro usando nomi di dominio completi (FQDN). Ciò richiede un server DNS (Domain Name System) in ogni rete configurata per inoltrare le richieste alle altre reti. Quando si crea una rete virtuale di Azure, anziché usare il DNS automatico fornito con la rete, è necessario specificare un server DNS personalizzato e l'indirizzo IP per il server. Dopo aver creato la rete virtuale, è necessario creare una macchina virtuale di Azure che usa tale indirizzo IP. Installare e configurare quindi il software DNS.
Importante
Creare e configurare il server DNS personalizzato prima di installare HDInsight nella rete virtuale. Non è necessaria alcuna configurazione aggiuntiva per HDInsight per l'uso del server DNS configurato per la rete virtuale.
Per altre informazioni sulla connessione di due reti virtuali di Azure, vedere Configurare una connessione.
Architettura del mirroring
Questa architettura include due cluster in diversi gruppi di risorse e reti virtuali: un database primario e un database secondario.
Passaggi di creazione
Creare due nuovi gruppi di risorse:
Resource group Location kafka-primary-rg Stati Uniti centrali kafka-secondary-rg Stati Uniti centro-settentrionali Creare una nuova rete virtuale kafka-primary-vnet in kafka-primary-rg. Lasciare le impostazioni predefinite.
Creare una nuova rete virtuale kafka-secondary-vnet in kafka-secondary-rg, anche con le impostazioni predefinite.
Creare due nuovi cluster Kafka:
Nome cluster Resource group Rete virtuale Account di archiviazione kafka-primary-cluster kafka-primary-rg kafka-primary-vnet kafkaprimarystorage kafka-secondary-cluster kafka-secondary-rg kafka-secondary-vnet kafkasecondarystorage Creare peering di rete virtuale. Questo passaggio creerà due peering: uno da kafka-primary-vnet a kafka-secondary-vnet e uno da kafka-secondary-vnet a kafka-primary-vnet.
Selezionare la rete virtuale kafka-primary-vnet .
In Impostazioni selezionare Peer.
Selezionare Aggiungi.
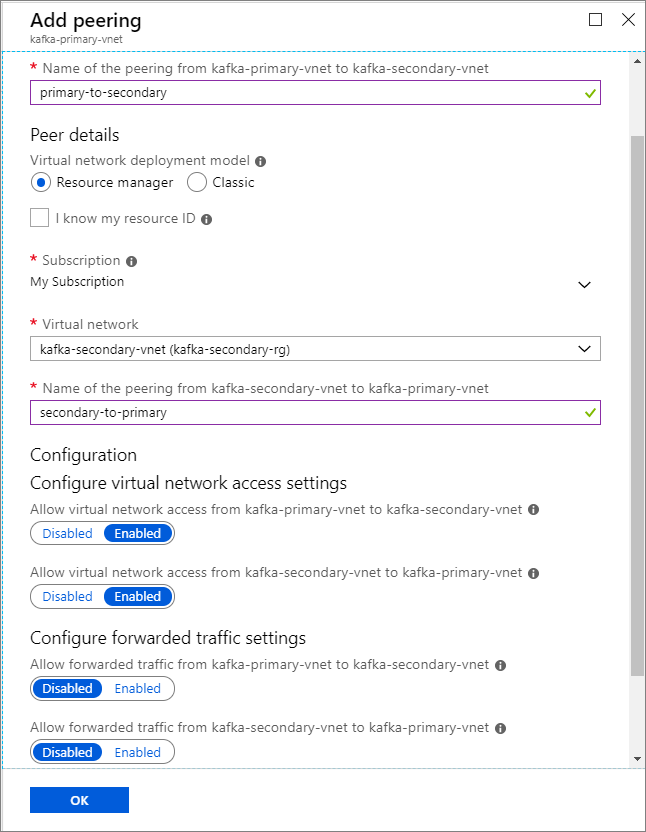
Nella schermata Aggiungi peering immettere i dettagli, come illustrato nello screenshot seguente.
Configurare la pubblicità IP
Configurare la pubblicità IP per consentire a un client di connettersi usando indirizzi IP broker anziché nomi di dominio.
Passare al dashboard di Ambari per il cluster primario:
https://PRIMARYCLUSTERNAME.azurehdinsight.net.Selezionare Servizi>Kafka. Selezionare la scheda Configurazioni .
Aggiungere le righe di configurazione seguenti alla sezione del modello kafka-env inferiore. Selezionare Salva.
# Configure Kafka to advertise IP addresses instead of FQDN IP_ADDRESS=$(hostname -i) echo advertised.listeners=$IP_ADDRESS sed -i.bak -e '/advertised/{/advertised@/!d;}' /usr/hdp/current/kafka-broker/conf/server.properties echo "advertised.listeners=PLAINTEXT://$IP_ADDRESS:9092" >> /usr/hdp/current/kafka-broker/conf/server.propertiesImmettere una nota nella schermata Salva configurazione e selezionare Salva.
Se viene visualizzato un avviso di configurazione, selezionare Continua comunque.
In Salva modifiche di configurazione selezionare OK.
Nella notifica Riavvia obbligatorio selezionare Riavvia riavvia>tutto interessato. Selezionare quindi Conferma riavvia tutto.
Configurare Kafka per l'ascolto su tutte le interfacce di rete
- Restare nella scheda Configurazioni in Servizi>Kafka. Nella sezione Broker Kafka impostare la proprietà listener su
PLAINTEXT://0.0.0.0:9092. - Selezionare Salva.
- Selezionare Riavvia>Conferma riavvia tutto.
Indirizzi IP del broker di record e indirizzi ZooKeeper per il cluster primario
Selezionare Host nel dashboard di Ambari.
Prendere nota degli indirizzi IP per i broker e ZooKeepers. I nodi broker hanno generato come prime due lettere del nome host e i nodi ZooKeeper hanno zk come prime due lettere del nome host.

Ripetere i tre passaggi precedenti per il secondo cluster , kafka-secondary-cluster: configurare annunci IP, impostare listener e prendere nota degli indirizzi IP broker e ZooKeeper.
Creare argomenti
Connettersi al cluster primario usando SSH:
ssh sshuser@PRIMARYCLUSTER-ssh.azurehdinsight.netSostituire
sshusercon il nome utente SSH usato durante la creazione del cluster. SostituirePRIMARYCLUSTERcon il nome di base usato durante la creazione del cluster.Per altre informazioni, vedere Usare SSH con HDInsight.
Usare il comando seguente per creare due variabili di ambiente con gli host Apache ZooKeeper e gli host broker per il cluster primario. Sostituire stringhe come
ZOOKEEPER_IP_ADDRESS1con gli indirizzi IP effettivi registrati in precedenza, ad esempio10.23.0.11e10.23.0.7. Lo stesso vale perBROKER_IP_ADDRESS1. Se si usa la risoluzione FQDN con un server DNS personalizzato, seguire questa procedura per ottenere nomi broker e ZooKeeper.# get the ZooKeeper hosts for the primary cluster export PRIMARY_ZKHOSTS='ZOOKEEPER_IP_ADDRESS1:2181, ZOOKEEPER_IP_ADDRESS2:2181, ZOOKEEPER_IP_ADDRESS3:2181' # get the broker hosts for the primary cluster export PRIMARY_BROKERHOSTS='BROKER_IP_ADDRESS1:9092,BROKER_IP_ADDRESS2:9092,BROKER_IP_ADDRESS2:9092'Per creare un argomento denominato
testtopic, usare il comando seguente:/usr/hdp/current/kafka-broker/bin/kafka-topics.sh --create --replication-factor 2 --partitions 8 --topic testtopic --zookeeper $PRIMARY_ZKHOSTSUsare il comando seguente per verificare che l'argomento sia stato creato:
/usr/hdp/current/kafka-broker/bin/kafka-topics.sh --list --zookeeper $PRIMARY_ZKHOSTSLa risposta contiene
testtopic.Usare quanto segue per visualizzare le informazioni sull'host broker per questo cluster (primario):
echo $PRIMARY_BROKERHOSTSVerranno restituite informazioni simili al testo seguente:
10.23.0.11:9092,10.23.0.7:9092,10.23.0.9:9092Salvare queste informazioni. Viene usato nella sezione successiva.
Configurare il mirroring
Connettersi al cluster secondario usando una sessione SSH diversa:
ssh sshuser@SECONDARYCLUSTER-ssh.azurehdinsight.netSostituire
sshusercon il nome utente SSH usato durante la creazione del cluster. SostituireSECONDARYCLUSTERcon il nome usato durante la creazione del cluster.Per altre informazioni, vedere Usare SSH con HDInsight.
Usare un
consumer.propertiesfile per configurare la comunicazione con il cluster primario. Per creare il file, usare il comando seguente:nano consumer.propertiesUsare il testo seguente come contenuto del file
consumer.properties:bootstrap.servers=PRIMARY_BROKERHOSTS group.id=mirrorgroupSostituire
PRIMARY_BROKERHOSTScon gli indirizzi IP dell'host broker dal cluster primario.Questo file descrive le informazioni sul consumer da usare durante la lettura dal cluster Kafka primario. Per altre informazioni, vedere Consumer Configs all'indirizzo
kafka.apache.org.Per salvare il file, premere CTRL+X, premere Y e quindi premere INVIO.
Prima di configurare il producer che comunica con il cluster secondario, configurare una variabile per gli indirizzi IP broker del cluster secondario. Usare i comandi seguenti per creare questa variabile:
export SECONDARY_BROKERHOSTS='BROKER_IP_ADDRESS1:9092,BROKER_IP_ADDRESS2:9092,BROKER_IP_ADDRESS2:9092'Il comando
echo $SECONDARY_BROKERHOSTSdeve restituire informazioni simili al testo seguente:10.23.0.14:9092,10.23.0.4:9092,10.23.0.12:9092Usare un
producer.propertiesfile per comunicare il cluster secondario. Per creare il file, usare il comando seguente:nano producer.propertiesUsare il testo seguente come contenuto del file
producer.properties:bootstrap.servers=SECONDARY_BROKERHOSTS compression.type=noneSostituire
SECONDARY_BROKERHOSTScon gli indirizzi IP del broker usati nel passaggio precedente.Per altre informazioni, vedere Configurazioni producer all'indirizzo
kafka.apache.org.Usare i comandi seguenti per creare una variabile di ambiente con gli indirizzi IP degli host ZooKeeper per il cluster secondario:
# get the ZooKeeper hosts for the secondary cluster export SECONDARY_ZKHOSTS='ZOOKEEPER_IP_ADDRESS1:2181,ZOOKEEPER_IP_ADDRESS2:2181,ZOOKEEPER_IP_ADDRESS3:2181'La configurazione predefinita per Kafka in HDInsight non consente la creazione automatica di argomenti. Prima di avviare il processo di mirroring, è necessario usare una delle opzioni seguenti:
Creare gli argomenti nel cluster secondario: questa opzione consente anche di impostare il numero di partizioni e il fattore di replica.
È possibile creare argomenti in anticipo usando il comando seguente:
/usr/hdp/current/kafka-broker/bin/kafka-topics.sh --create --replication-factor 2 --partitions 8 --topic testtopic --zookeeper $SECONDARY_ZKHOSTSSostituire
testtopiccon il nome dell'argomento da creare.Configurare il cluster per la creazione automatica degli argomenti: questa opzione consente a MirrorMaker di creare automaticamente gli argomenti. Si noti che potrebbe crearli con un numero diverso di partizioni o un fattore di replica diverso rispetto all'argomento primario.
Per configurare il cluster secondario per creare automaticamente gli argomenti, seguire questa procedura:
- Passare al dashboard di Ambari per il cluster secondario:
https://SECONDARYCLUSTERNAME.azurehdinsight.net. - Selezionare Servizi>Kafka. Selezionare quindi la scheda Configurazioni .
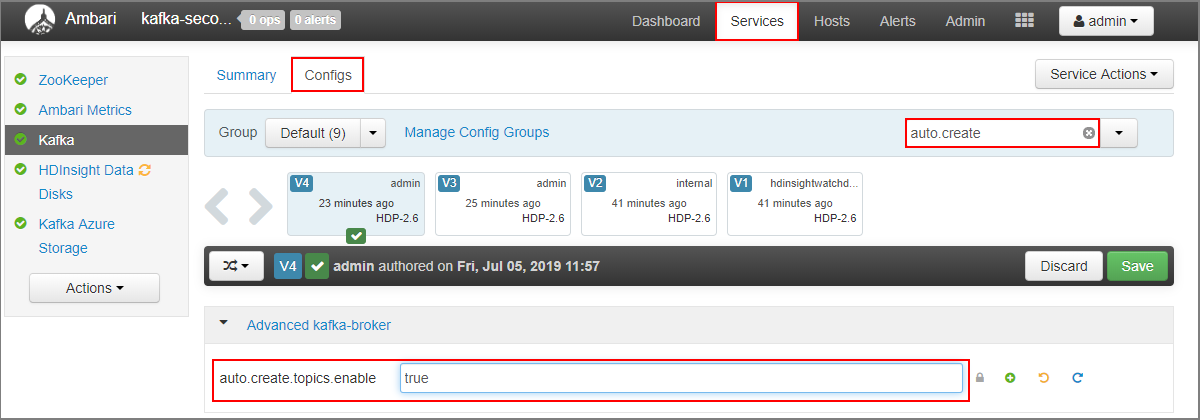
- Nel campo Filtro immettere il valore
auto.create. In questo modo, l'elenco di proprietà verrà filtrato e verrà visualizzata l'impostazioneauto.create.topics.enable. - Modificare il valore di
auto.create.topics.enableintruee quindi selezionare Salva. Aggiungere una nota e quindi selezionare di nuovo Salva . - Selezionare il servizio Kafka , selezionare Riavvia e quindi selezionare Riavvia tutto interessato. Quando richiesto, selezionare Conferma riavvio tutto.
- Passare al dashboard di Ambari per il cluster secondario:
Avviare MirrorMaker
Nota
Questo articolo contiene riferimenti a un termine che Microsoft non usa più. Quando il termine verrà rimosso dal software, verrà rimosso anche dall'articolo.
Dalla connessione SSH al cluster secondario usare il comando seguente per avviare il processo MirrorMaker:
/usr/hdp/current/kafka-broker/bin/kafka-run-class.sh kafka.tools.MirrorMaker --consumer.config consumer.properties --producer.config producer.properties --whitelist testtopic --num.streams 4I parametri usati in questo esempio sono i seguenti:
Parametro Descrizione --consumer.configspecifica il file che contiene le proprietà del consumer. Queste proprietà vengono usate per creare un consumer che legge dal cluster Kafka primario. --producer.configspecifica il file che contiene le proprietà del producer. Queste proprietà vengono usate per creare un producer che scrive nel cluster Kafka secondario. --whitelistElenco di argomenti replicati da MirrorMaker dal cluster primario al database secondario. --num.streamsnumero di thread consumer da creare. Il consumer nel nodo secondario è ora in attesa di ricevere messaggi.
Dalla connessione SSH al cluster primario, usare il comando seguente per avviare un producer e inviare messaggi all'argomento:
/usr/hdp/current/kafka-broker/bin/kafka-console-producer.sh --broker-list $PRIMARY_BROKERHOSTS --topic testtopicQuando si arriva a una riga vuota con un cursore, digitare alcuni messaggi di testo. I messaggi vengono inviati all'argomento nel cluster primario. Al termine, premere CTRL+C per terminare il processo producer.
Dalla connessione SSH al cluster secondario premere CTRL+C per terminare il processo mirrormaker. Potrebbero essere necessari alcuni secondi per terminare il processo. Per verificare che i messaggi siano stati replicati nel database secondario, usare il comando seguente:
/usr/hdp/current/kafka-broker/bin/kafka-console-consumer.sh --bootstrap-server $SECONDARY_BROKERHOSTS --topic testtopic --from-beginningL'elenco degli argomenti include
testtopicora , che viene creato quando MirrorMaster esegue il mirroring dell'argomento dal cluster primario al database secondario. I messaggi recuperati dall'argomento sono uguali a quelli immessi nel cluster primario.
Eliminare il cluster
Avviso
La fatturazione dei cluster HDInsight viene calcolata al minuto, indipendentemente dal fatto che siano usati o meno. Assicurarsi di eliminare il cluster dopo aver finito di usarlo. Vedere Come eliminare un cluster HDInsight.
La procedura descritta in questo articolo ha creato cluster in gruppi di risorse di Azure diversi. Per eliminare tutte le risorse create, è possibile eliminare i due gruppi di risorse creati: kafka-primary-rg e kafka-secondary-rg. L'eliminazione dei gruppi di risorse rimuove tutte le risorse create seguendo questo articolo, inclusi cluster, reti virtuali e account di archiviazione.
Passaggi successivi
In questo articolo si è appreso come usare MirrorMaker per creare una replica di un cluster Apache Kafka . Per trovare altri modi per lavorare con Kafka, vedere i collegamenti seguenti: