Esercitazione: Soluzione end-to-end con Azure Machine Learning e IoT Edge
Si applica![]() IoT Edge 1.1
IoT Edge 1.1
Importante
IoT Edge 1,1 data di fine del supporto è stata il 13 dicembre 2022. Controlla il ciclo di vita dei prodotti Microsoft per ottenere informazioni sul modo in cui viene supportato questo prodotto, servizio, tecnologia o API. Per altre informazioni sull'aggiornamento alla versione più recente di IoT Edge, vedere Aggiornare IoT Edge.
Le applicazioni IoT spesso vogliono usufruire del cloud intelligente e della rete perimetrale intelligente. In questa esercitazione viene illustrato come eseguire il training di un modello di Machine Learning con i dati raccolti dai dispositivi IoT nel cloud, distribuendo tale modello a IoT Edge, e quindi come sottoporre il modello a manutenzione e come perfezionarlo periodicamente.
Nota
I concetti di questo set di esercitazioni si applicano a tutte le versioni di IoT Edge, ma il dispositivo di esempio creato per provare lo scenario viene eseguito IoT Edge versione 1.1.
L'obiettivo principale di questa esercitazione è introdurre l'elaborazione dei dati IoT con Machine Learning, più specificamente nella rete perimetrale. Anche se vengono trattati molti aspetti di un flusso di lavoro generico di Machine Learning, l'esercitazione non ha lo scopo di fornire un'introduzione approfondita a tale funzionalità. In questo caso, non si tenta di creare un modello altamente ottimizzato per il caso d'uso, ma è sufficiente illustrare il processo di creazione e l'uso di un modello valida per l'elaborazione dei dati IoT.
Questa sezione dell'esercitazione esamina quanto segue:
- Prerequisiti per completare le parti successive dell'esercitazione.
- Destinatari dell'esercitazione.
- Il caso d'uso simulato dall'esercitazione.
- Il processo generale seguito dall'esercitazione per soddisfare il caso d'uso.
Se non si ha una sottoscrizione di Azure, creare un account gratuito prima di iniziare.
Prerequisiti
Per completare l'esercitazione, è necessario avere accesso a una sottoscrizione di Azure che conferisca i diritti per creare risorse. Per diversi servizi usati in questa esercitazione verranno addebitati i costi di Azure. Se ancora non si dispone di una sottoscrizione di Azure, è possibile provare a iniziare con un account Azure gratuito.
È inoltre necessario un computer in cui sia installato PowerShell dove poter eseguire gli script per configurare una macchina virtuale di Azure come computer di sviluppo.
In questo documento vengono usati gli strumenti seguenti:
Un hub IoT di Azure per l'acquisizione dei dati.
Azure Notebooks come front-end principale per la preparazione dei dati e la sperimentazione con Machine Learning. L'esecuzione del codice Python in un notebook in un subset dei dati di esempio è un ottimo modo per ottenere un turno iterativo e interattivo rapido durante la preparazione dei dati. È anche possibile usare notebook Jupyter per preparare gli script da eseguire su larga scala in un back-end di calcolo.
Azure Machine Learning come back-end per Machine Learning su larga scala e per la generazione delle immagini di Machine Learning. Tale back-end viene controllato tramite script preparati e testati in notebook Jupyter.
Azure IoT Edge per l'applicazione fuori dal cloud di un'immagine di Machine Learning.
Sono ovviamente disponibili altre opzioni. In alcuni scenari, ad esempio, è possibile usare IoT Central come alternativa senza codice per acquisire i dati di training iniziali dai dispositivi IoT.
Destinatari e ruoli
Questa serie di articoli si rivolge agli sviluppatori senza precedenti esperienze nello sviluppo IoT o in Machine Learning. Per distribuire Machine Learning nella rete perimetrale, è necessario sapere come connettere un'ampia gamma di tecnologie. Questa esercitazione illustra pertanto un intero scenario end-to-end per mostrare uno dei modi in cui è possibile combinare tali tecnologie per una soluzione IoT. In un ambiente reale queste attività potrebbero essere distribuite tra più persone con specializzazioni diverse. Ad esempio, gli sviluppatori potrebbero occuparsi del codice del dispositivo o del cloud dopo che i data scientist hanno progettato i modelli di analisi. Per consentire a un singolo sviluppatore di completare correttamente questa esercitazione, è stato fornito materiale supplementare con informazioni dettagliate e collegamenti ad altre informazioni presumibilmente sufficienti per comprendere le operazioni da eseguire e i motivi per cui eseguirle.
In alternativa, è possibile seguire l'esercitazione insieme a colleghi con ruoli diversi, in modo che ognuno porti la propria esperienza e l'intero team comprenda il funzionamento e l'interazione tra le diverse funzionalità.
In entrambi i casi, per orientare meglio i lettori, ogni articolo di questa esercitazione indica il ruolo dell'utente. Tali ruoli includono:
- Sviluppo per il cloud (compreso uno sviluppatore per il cloud che sappia usare DevOps)
- Analisi dei dati
Caso d'uso: Manutenzione predittiva
Questo scenario è basato su un caso d'uso presentato alla Conference on Prognostics and Health Management (PHM08) nel 2008. L'obiettivo è quello di prevedere la vita utile rimanente di un gruppo di motori di aerei con turboventole. Questi dati sono stati generati usando C-MAPSS, la versione commerciale del software MAPSS (Modular Aero-Propulsion System Simulation). Tale software fornisce un ambiente flessibile per la simulazione di motori con turboventole che consente di simulare in modo pratico i parametri relativi allo stato, ai controlli e ai motori.
I dati usati nell'esercitazione sono tratti dal set di dati di simulazione della riduzione delle prestazioni dei motori con turboventole.
Dal file leggimi:
Scenario sperimentale
I set di dati sono costituiti da più serie temporali multivariate. Ogni set di dati è ulteriormente suddiviso in sottoinsiemi di training e di test. Ogni serie temporale proviene da un motore diverso, ovvero i dati possono essere considerati da una flotta di motori dello stesso tipo. Ogni motore parte con gradi diversi di usura iniziale e alcune variazioni di produzione non note all'utente. Tale usura e tali variazioni vengono considerate normali e non come una condizione di errore. Sulle prestazioni dei motori incidono in modo significativo tre impostazioni operative. Anche queste impostazioni sono incluse nei dati, I dati sono contaminati con il rumore del sensore.
Il motore funziona normalmente all'inizio di ogni serie temporale e a un certo punto, durante la serie, presenta un problema. Nel set di training il problema man mano peggiora fino a provocare il guasto del sistema. Nel set di test la serie temporale termina prima del guasto del sistema. L'obiettivo della sfida è prevedere il numero di cicli operativi rimanenti prima del guasto nel set di test, ovvero per quanti cicli operativi il motore continuerà a funzionare dopo l'ultimo ciclo. Viene fornito anche un vettore di reali valori di vita utile rimanente per i dati di test.
Poiché i dati sono stati pubblicati per una sfida, sono stati pubblicati in modo indipendente diversi approcci per derivare i modelli di Machine Learning. Si è scoperto che studiare gli esempi è utile per comprendere il processo e il ragionamento alla base della creazione di un modello di Machine Learning specifico. Ad esempio, vedere:
Aircraft engine failure prediction model (Modello di previsione dei guasti dei motori degli aerei) dell'utente di GitHub jancervenka.
Turbofan engine degradation (Riduzione delle prestazioni dei motori con turboventole) dell'utente di GitHub hankroark.
Process
La figura sotto riportata illustra approssimativamente i passaggi da eseguire in questa esercitazione:
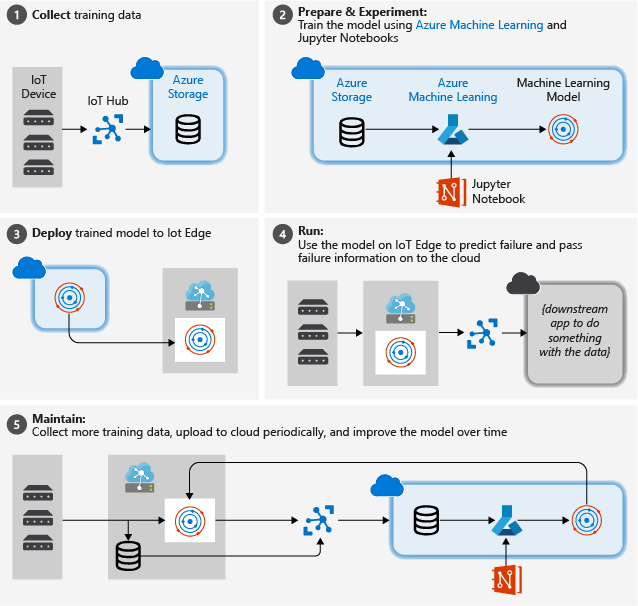
Raccogliere i dati di training: il processo inizia con la raccolta dei dati di training. In alcuni casi i dati sono già stati raccolti e sono disponibili in un database o sotto forma di file di dati. In altri casi, soprattutto per gli scenari IoT, è necessario raccogliere i dati dai dispositivi IoT e dai sensori e archiviarli nel cloud.
Si presuppone che chi esegue l'esercitazione non disponga di una raccolta di motori con turboventole, pertanto i file di progetto includono un semplice simulatore di dispositivo che invia i dati dei dispositivi NASA al cloud.
Preparare i dati. Nella maggior parte dei casi i dati non elaborati raccolti dai dispositivi e dai sensori devono essere preparati per Machine Learning. Questo passaggio può comportare la pulizia, la riformattazione o la rielaborazione dei dati per l'inserimento di informazioni aggiuntive che Machine Learning può usare come base di partenza.
Nel caso dei motori degli aerei di questo esempio, la preparazione dei dati comporta il calcolo del tempo esplicito necessario per giungere al guasto per ogni punto dati nel campione in base alle osservazioni effettive sui dati. Queste informazioni consentono all'algoritmo di Machine Learning di trovare le correlazioni tra i modelli di dati effettivi dei sensori e la vita rimanente prevista del motore. Questo passaggio è molto specifico del settore in questione.
Creare un modello di Machine Learning. Sulla base dei dati preparati, è ora possibile provare con diversi algoritmi e parametrizzazioni di Machine Learning per eseguire il training dei modelli e confrontare tra loro i risultati.
In questo caso, ai fini del testing, il risultato previsto calcolato dal modello viene confrontato con il risultato reale osservato su un gruppo di motori. In Azure Machine Learning è possibile gestire le diverse iterazioni dei modelli creati in un apposito registro.
Distribuire il modello. Dopo aver ottenuto un modello in grado di soddisfare i criteri di riuscita, è possibile passare alla distribuzione. Questo passaggio comporta il wrapping del modello in un'app di servizio Web che può ricevere dati tramite chiamate REST e restituire i risultati dell'analisi. L'app di servizio Web viene quindi compressa in un contenitore docker che a sua volta può essere distribuito nel cloud o come modulo IoT Edge. Questo esempio verterà sulla distribuzione a IoT Edge.
Eseguire la manutenzione e perfezionare il modello. Dopo la distribuzione del modello, il lavoro non è ancora finito. In molti casi è possibile continuare a raccogliere dati e caricare periodicamente tali dati nel cloud. È quindi possibile usare questi dati per ripetere il training e perfezionare il modello, che potrà essere successivamente ridistribuito a IoT Edge.
Pulire le risorse
Questa esercitazione fa parte di un set in cui ogni articolo si basa sul lavoro svolto nei precedenti. Prima di pulire le risorse attendere il completamento dell'esercitazione finale.
Passaggi successivi
Questa esercitazione è suddivisa nelle sezioni seguenti:
- Configurare il computer di sviluppo e i servizi di Azure.
- Generare i dati di training per il modulo di Machine Learning.
- Eseguire il training e distribuire il modello di Machine Learning.
- Configurare un dispositivo IoT Edge come gateway trasparente.
- Creare e distribuire i moduli IoT Edge.
- Inviare i dati al dispositivo IoT Edge.
Proseguire con l'articolo che segue per configurare un computer di sviluppo ed effettuare il provisioning delle risorse di Azure.