Diagnostica di Load Balancer Standard con metriche, avvisi e integrità delle risorse
Azure Load Balancer espone le seguenti funzionalità di diagnostica:
Metriche e avvisi multidimensionali: fornisce funzionalità di diagnostica multidimensionali tramite Monitoraggio di Azure per le configurazioni standard del servizio di bilanciamento del carico. Così è possibile monitorare, gestire e risolvere i problemi delle risorse di bilanciamento del carico standard.
Integrità delle risorse: lo stato Integrità risorse del servizio di bilanciamento del carico è disponibile nella pagina Integrità delle risorse in Monitoraggio. Questo controllo automatico indica la disponibilità attuale della risorsa del servizio di bilanciamento del carico.
Questo articolo offre una breve panoramica di queste funzionalità e illustra come usarle per bilanciamento del carico standard.
Metriche multidimensionali
Azure Load Balancer fornisce le metriche multidimensionali tramite la funzionalità Metriche di Azure nel portale di Azure e consente di ottenere informazioni dettagliate di diagnostica in tempo reale sulle risorse di Load Balancer.
Le varie configurazioni del bilanciamento del carico forniscono le seguenti metriche:
| Metric | Tipo di risorsa | Descrizione | Aggregazione consigliata |
|---|---|---|---|
| Disponibilità del percorso dati | Servizio di bilanciamento del carico interno e pubblico | Un servizio di bilanciamento del carico standard usa continuamente il percorso dati dall'interno di un'area al front-end del servizio di bilanciamento del carico, alla rete che supporta la macchina virtuale. Finché sono presenti istanze integre, la misurazione segue lo stesso percorso del traffico con bilanciamento del carico dell'applicazione. Il percorso dati in uso viene convalidato. La misurazione è invisibile all'applicazione e non interferisce con altre operazioni. | Media |
| Stato del probe di integrità | Servizio di bilanciamento del carico interno e pubblico | Un Load Balancer Standard usa un servizio di probe dell'integrità distribuito che monitora l'integrità dell'endpoint dell'applicazione in base alle impostazioni di configurazione. Questa metrica offre una visualizzazione filtrata, aggregata o per endpoint di ogni endpoint dell'istanza nel pool di Load Balancer. In questo modo è possibile visualizzare l'integrità dell'applicazione rilevata da bilanciamento del carico, in base alla configurazione del probe di integrità. | Media |
| Conteggio SYN (sincronizzazione) | Servizio di bilanciamento del carico interno e pubblico | Un servizio di bilanciamento del carico standard non termina le connessioni TCP (Transmission Control Protocol) o interagisce con i flussi TCP o UDP (User Data-gram Packet). I flussi e i relativi handshake sono sempre tra l'origine e l'istanza VM. Per risolvere meglio i problemi degli scenari del protocollo TCP, è possibile usare contatori di pacchetti SYN per determinare quanti tentativi di connessione TCP vengono eseguiti. La metrica indica il numero di pacchetti SYN TCP ricevuti. | Sum |
| Numero di connessioni SNAT (Source Network Address Translation) | Servizio di bilanciamento del carico pubblico | Il bilanciamento del carico standard segnala il numero di flussi in uscita mascherati per il front-end dell'indirizzo IP pubblico. Le porte SNAT sono una risorsa esauribile. Questa metrica può indicare l'uso che l'applicazione fa di SNAT per i flussi originati in uscita. Vengono segnalati i contatori per i flussi SNAT in uscita riusciti e non riusciti. I contatori possono essere usati per risolvere i problemi e comprendere l'integrità dei flussi in uscita. | Sum |
| Porte SNAT allocate | Servizio di bilanciamento del carico pubblico | Un servizio di bilanciamento del carico standard segnala il numero di porte SNAT allocate per ogni istanza back-end | Media. |
| Porte SNAT usate | Servizio di bilanciamento del carico pubblico | Un servizio di bilanciamento del carico standard segnala il numero di porte SNAT utilizzate per ogni istanza back-end. | Media |
| Conteggio byte | Servizio di bilanciamento del carico interno e pubblico | Bilanciamento del carico standard restituisce i dati elaborati per ogni front-end. È possibile notare che i byte non sono distribuiti equamente tra le istanze back-end. Si tratta di un comportamento previsto, in quanto l'algoritmo di Load Balancer di Azure è basato sui flussi | Sum |
| Numero di pacchetti | Servizio di bilanciamento del carico interno e pubblico | Bilanciamento del carico standard restituisce i pacchetti elaborati per ogni front-end. | Sum |
Nota
Le metriche correlate alla larghezza di banda, ad esempio il pacchetto SYN, il numero di byte e il numero di pacchetti, non acquisiranno traffico verso un servizio di bilanciamento del carico interno tramite una UDR (ad esempio, da una NVA o da un firewall).
Le aggregazioni massime e minime non sono disponibili per il conteggio SYN, il numero di pacchetti, il numero di connessioni SNAT e le metriche del conteggio dei byte. L'aggregazione conteggio non è consigliata per la disponibilità del percorso dati e lo stato del probe di integrità. Usare invece la media per i dati di integrità meglio rappresentati.
Consente di visualizzare le metriche di Load Balancer nel portale di Azure
Il portale di Azure espone le metriche del servizio di bilanciamento del carico tramite la pagina Metriche. Questa pagina è disponibile sia nella pagina delle risorse del servizio di bilanciamento del carico per una determinata risorsa che nella pagina Monitoraggio di Azure.
Nota
Azure Load Balancer non invia probe di integrità alle macchine virtuali deallocate. Quando le macchine virtuali vengono deallocate, il servizio di bilanciamento del carico interromperà la segnalazione delle metriche per tale istanza. Le metriche non disponibili verranno visualizzate come linea tratteggiata nel portale o visualizzano un messaggio di errore che indica che le metriche non possono essere recuperate.
Per visualizzare le metriche delle risorse di bilanciamento del carico standard:
Accedere alla pagina Metriche ed eseguire una di queste attività:
Nella pagina delle risorse di bilanciamento del carico, selezionare il tipo di metrica nell'elenco a discesa.
Nella pagina Monitoraggio di Azure, selezionare la risorsa di Load Balancer.
Impostare il tipo di aggregazione delle metriche appropriato.
Facoltativamente, configurare il filtro e il raggruppamento necessari.
Facoltativamente, configurare l'intervallo di tempo e l'aggregazione. Per impostazione predefinita, l'ora viene visualizzata in formato UTC.
Nota
L'aggregazione temporale è importante quando si interpretano determinate metriche come dati campionati una volta al minuto. Se l'aggregazione temporale è impostata su cinque minuti e il tipo di aggregazione delle metriche Sum viene usato per le metriche, ad esempio l'allocazione SNAT, il grafico visualizzerà cinque volte le porte SNAT allocate totali.
Raccomandazione: quando si analizza il tipo di aggregazione delle metriche Somma e Conteggio, è consigliabile usare un valore di aggregazione temporale maggiore di un minuto.
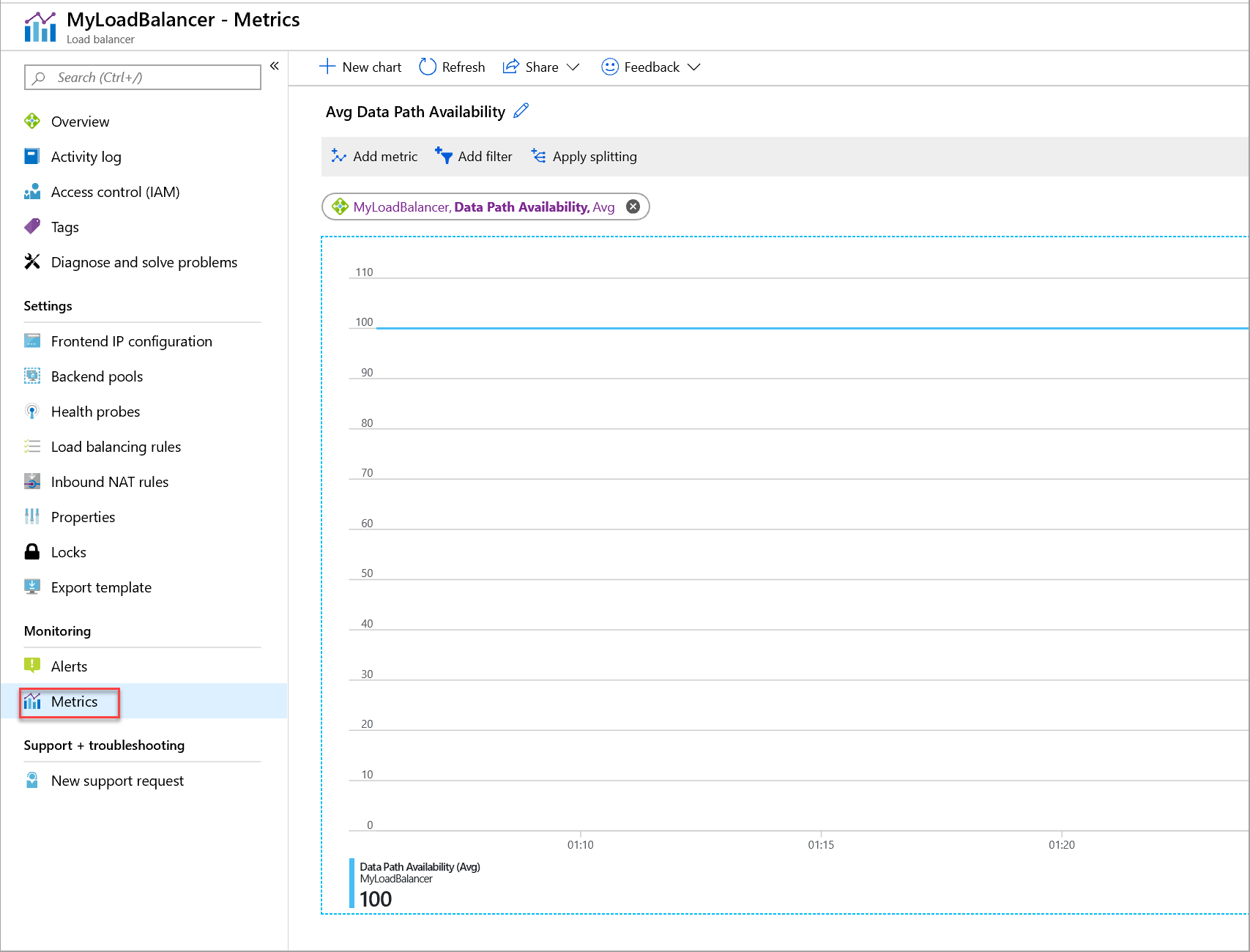
Figura - Metrica per la disponibilità del percorso dati per un servizio di bilanciamento del carico standard
Recuperare le metriche multidimensionali a livello di codice tramite le API
Per informazioni sull'API per il recupero dei valori e delle definizioni delle metriche multidimensionali, vedere la Procedura dettagliata di API REST di Azure Monitoring. Queste metriche possono essere scritte in un account di archiviazione aggiungendo un'impostazione di diagnostica per la categoria "Tutte le metriche".
Scenari di diagnostica comuni e visualizzazioni consigliate
Il percorso dei dati è disponibile per il front-end del servizio di bilanciamento del carico?
Espandi
La metrica per la disponibilità del percorso dati descrive l'integrità all'interno dell'area del percorso dati dell'host di calcolo in cui si trovano le macchine virtuali. La metrica riflette lo stato di integrità delle infrastrutture di Azure. La metrica può essere utilizzata per:
Monitorare la disponibilità esterna del servizio.
Esaminare la piattaforma in cui viene distribuito il servizio e stabilire se è integro. Stabilire se il sistema operativo guest o l'istanza dell'applicazione sono integri.
Isolare se un evento è correlato al servizio o al piano dati sottostante. Non confondere questa metrica con lo stato del probe di integrità ("Disponibilità dell'istanza back-end").
Ottenere la disponibilità del percorso dati per le risorse del servizio di bilanciamento del carico standard:
Assicurarsi che sia selezionata la risorsa di Load Balancer corretta.
Nell'elenco a discesa Metrica selezionare Disponibilità del percorso dati.
Nell’elenco a discesa Aggregazione, selezionare Media.
Aggiungere inoltre un filtro sull'indirizzo IP front-end o sulla porta front-end come dimensione con l'indirizzo IP front-end o la porta front-end richiesta. Raggrupparli quindi in base alla dimensione selezionata.
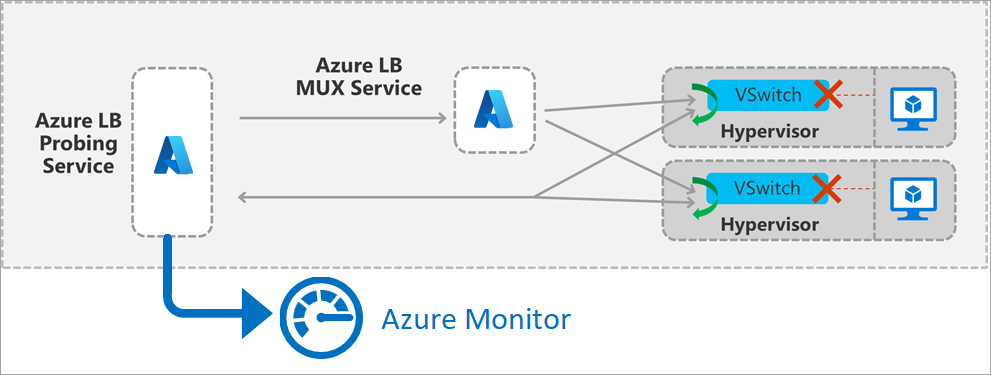
Figura - Dettagli del probe front-end del servizio di bilanciamento del carico
La metrica viene generata da una misura attiva in banda. Un servizio di esecuzione del probe all'interno della regione genera traffico per la misura. Il servizio viene attivato non appena si crea una distribuzione con un front end pubblico e continua fino a quando non viene rimosso.
Viene generato periodicamente un pacchetto corrispondente alla regola e al front-end di distribuzione che attraversa l'area dall'origine all'host in cui si trova una macchina virtuale nel pool back-end. L'infrastruttura di Load Balancer esegue le stesse operazioni di traslazione e bilanciamento del carico che vengono effettuate per tutto il resto del traffico. Questo probe è in banda nell'endpoint con carico bilanciato. Dopo che il probe arriva nell'host di calcolo in cui si trova una macchina virtuale integra nel pool back-end, l'host di calcolo genera una risposta al servizio di esecuzione del probe. La macchina virtuale non visualizza questo traffico.
La disponibilità del percorso dati avrà esito negativo per le ragioni seguenti:
La distribuzione non ha macchine virtuali integre rimanenti nel pool back-end.
Si è verificata un'interruzione dell'infrastruttura.
Per scopi diagnostici è possibile usare la metrica per la disponibilità del percorso dati insieme allo stato del probe di integrità.
Usare Media come aggregazione per la maggior parte degli scenari.
Le istanze back-end per il servizio di bilanciamento del carico rispondono ai probe?
Espandi
La metrica relativa allo stato del probe di integrità descrive l'integrità della distribuzione dell'applicazione come configurato dall'utente quando si configura il probe di integrità di Load Balancer. Load Balancer usa lo stato del probe di integrità per determinare dove inviare nuovi flussi. I probe di integrità hanno origine da un indirizzo dell'infrastruttura di Azure e sono visibili all'interno del sistema operativo guest della macchina virtuale.
Ottenere lo stato del probe di integrità per le risorse del servizio di bilanciamento del carico standard:
Selezionare la metrica Health Probe Status (Stato probe di integrità) con il Avg aggregation type (Tipo di aggregazione media).
Applicare un filtro sulla porta o sull'indirizzo IP front-end richiesto (o entrambi).
I probe di integrità hanno esito negativo per le ragioni seguenti:
Se si configura un probe di integrità per una porta che non è in ascolto, che non risponde o che non utilizza il protocollo corretto. Se il servizio usa regole IP mobili o restituite dal server diretto, verificare che il servizio sia in ascolto sull'indirizzo IP della configurazione IP della scheda di interfaccia di rete e sul loopback configurato con l'indirizzo IP front-end.
Il gruppo di sicurezza di rete, il firewall del sistema operativo guest della macchina virtuale o i filtri del livello applicazione non consentono il traffico del probe di integrità.
Usare Media come aggregazione per la maggior parte degli scenari.
Come è possibile controllare le statistiche di connessione in uscita?
Espandi
La metrica relativa alle connessioni SNAT descrive il volume di quelle con esito positivo e con esito negativo (connessioni per i flussi in uscita).
Un volume di connessioni non riuscite maggiore di zero indica l'esaurimento delle porte SNAT. È necessario effettuare un'analisi approfondita per determinare che cosa potrebbe causare questi errori. L'esaurimento delle porte SNAT si manifesta sotto forma di errore durante la definizione di un flusso in uscita. Fare riferimento all'articolo sulle connessioni in uscita per comprendere gli scenari e i meccanismi coinvolti e scoprire come ridurre ed evitare l'esaurimento delle porte SNAT in fase di progettazione.
Per ottenere statistiche sulle connessioni SNAT:
Selezionare il tipo di metrica Connessioni SNAT e Somma come aggregazione.
Procedere al raggruppamento per Stato connessione per il conteggio delle connessioni SNAT riuscite e non riuscite rappresentate da righe differenti.
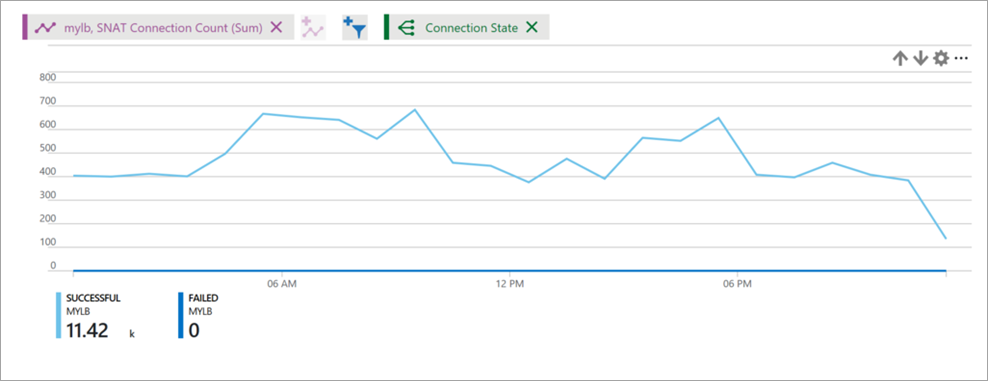
Figura - Conteggio delle connessioni SNAT per bilanciamento del carico
Come è possibile controllare l'utilizzo e l'allocazione delle porte SNAT?
Espandi
La metrica delle porte SNAT usate tiene traccia del numero di porte SNAT utilizzate per gestire i flussi in uscita. Questa metrica indica il numero di flussi univoci stabiliti tra un'origine Internet e una macchina virtuale back-end o un set di scalabilità di macchine virtuali dietro un servizio di bilanciamento del carico e non ha un indirizzo IP pubblico. Confrontando il numero di porte SNAT in uso con la metrica Porte SNAT allocate, è possibile determinare se il servizio riscontra o a rischio di esaurimento SNAT e conseguente errore del flusso in uscita.
Se le metriche indicano il rischio di errore del flusso in uscita, fare riferimento all'articolo ed eseguire le operazioni necessarie per attenuare questo problema per garantire l'integrità dei servizi.
Visualizzare l'utilizzo e l'allocazione delle porte SNAT:
Impostare l'aggregazione temporale del grafico su 1 minuto per assicurarsi che vengano visualizzati i dati desiderati.
Selezionare Porte SNAT usate e/o porte SNAT allocate come tipo di metrica e Media come aggregazione.
Per impostazione predefinita, queste metriche rappresentano il numero medio di porte SNAT allocate o usate da ogni macchina virtuale back-end o set di scalabilità di macchine virtuali. Corrispondono a tutti gli indirizzi IP pubblici front-end mappati al servizio di bilanciamento del carico, aggregati su TCP e UDP.
Per visualizzare le porte SNAT totali usate o allocate per il servizio di bilanciamento del carico, usare l'aggregazione delle metriche Somma.
Filtrare in base a un tipo di protocollo specifico, un set di Indirizzi IP back-end e/o Indirizzi IP front-end.
Per monitorare l'integrità per ogni istanza back-end o front-end, applicare la suddivisione.
- La suddivisione delle note consente solo la visualizzazione di una singola metrica alla volta.
Ad esempio, per monitorare l'utilizzo SNAT per i flussi TCP per computer, aggregare per Media, diviso per Indirizzo IP back-end e filtrare in base al tipo di protocollo.
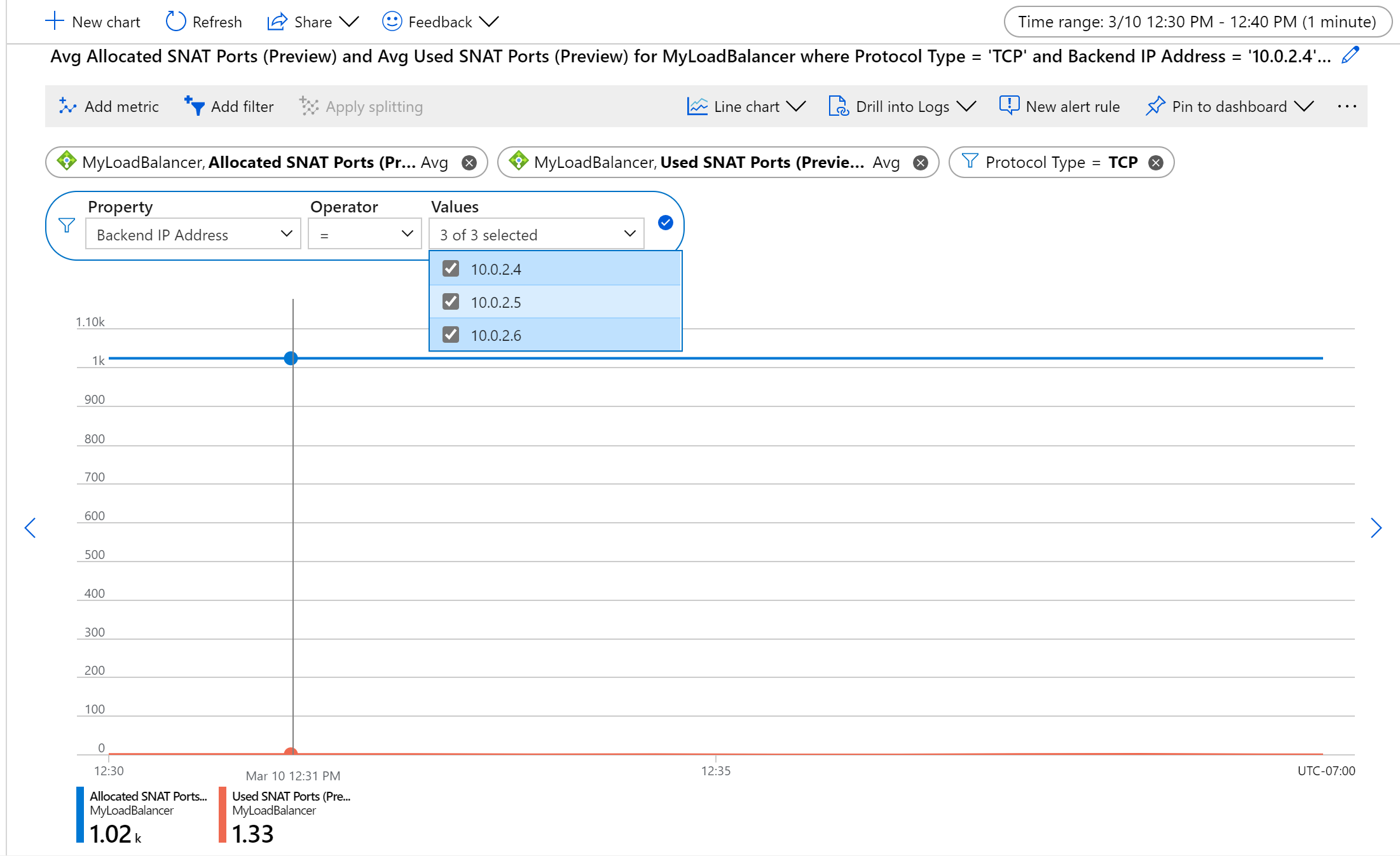
Figura - Allocazione e utilizzo medio delle porte SNAT TCP per un set di macchine virtuali back-end
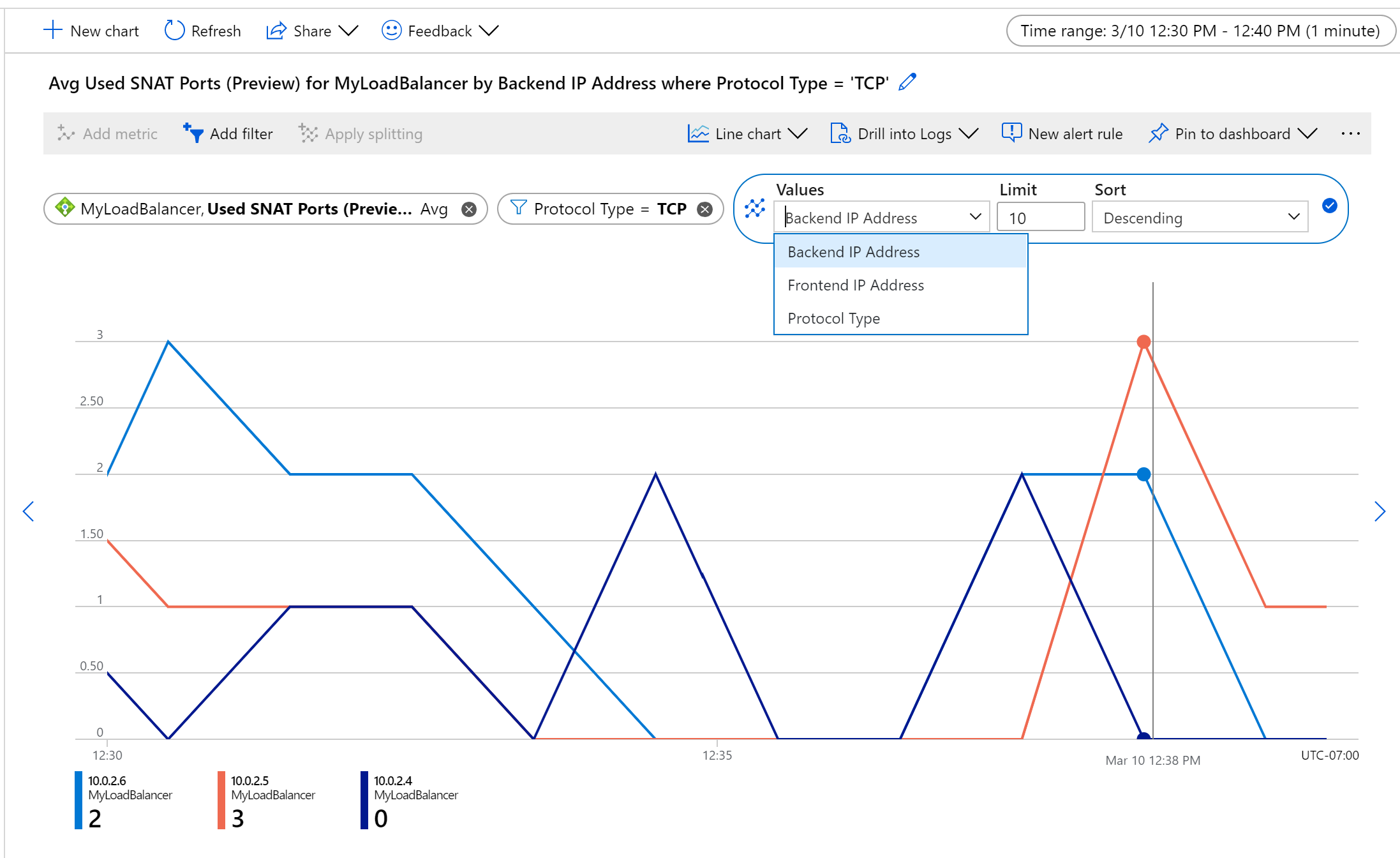
Figura - Utilizzo delle porte SNAT TCP per ogni istanza back-end
Come è possibile verificare i tentativi di connessione in ingresso/uscita per il servizio?
Espandere
La metrica relativa a un pacchetto SYN descrive il volume di pacchetti SYN TCP arrivati o inviati per i flussi in uscita che sono associati a uno specifico front-end. Questa metrica può essere usata per comprendere i tentativi di connessione TCP al servizio.Per ulteriori informazioni sulle connessioni in uscita, consultare Uso di SNAT (Source Network Address Translation) per le connessioni in uscita
Usare la Somma come aggregazione per la maggior parte degli scenari.
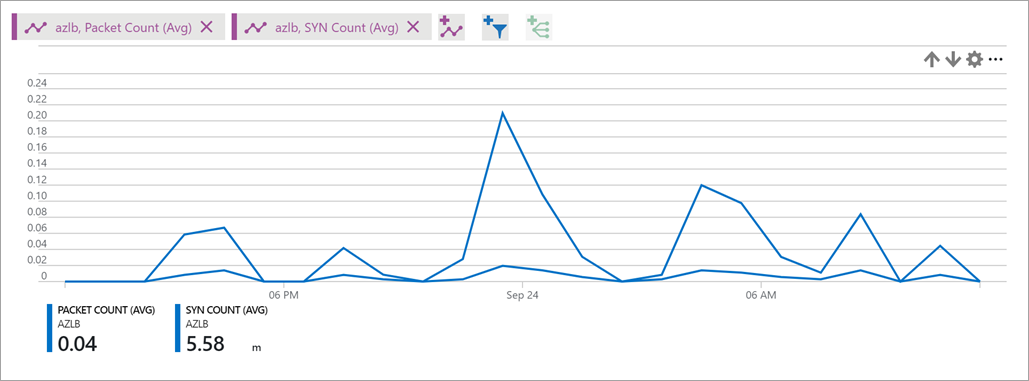
Figura - Conteggio SYN per il bilanciamento del carico
Come è possibile verificare il consumo di larghezza di banda di rete?
Espandi
La metrica relativa ai contatori di byte e pacchetti descrive il volume di byte e pacchetti che vengono inviati o ricevuti dal servizio per ogni front-end.
Usare la Somma come aggregazione per la maggior parte degli scenari.
Per ottenere statistiche relative al conteggio di byte o pacchetti:
Selezionare il tipo di metrica Conteggio byte e/o Conteggio pacchetti con Somma come aggregazione.
Effettuare una delle operazioni riportate di seguito:
Applicare un filtro a un indirizzo IP front-end, una porta front-end, un indirizzo IP back-end o una porta back-end specifica.
È possibile ottenere statistiche generali per la risorsa di Load Balancer senza applicare filtri.
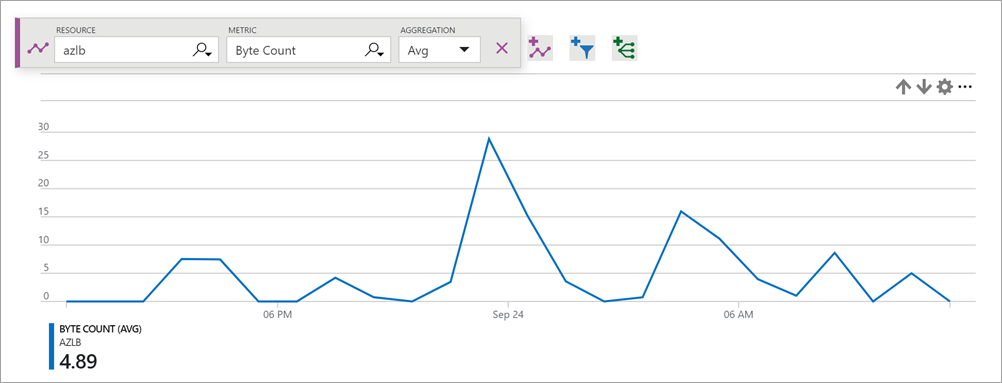
Figura - Conteggio byte per bilanciamento del carico
Come è possibile diagnosticare la distribuzione di Load Balancer?
Espandi
La combinazione del percorso dei dati e delle metriche di stato del probe di integrità su un singolo grafico consente di identificare dove si verificano e si possono risolvere i problemi. È possibile assicurarsi che Azure funzioni correttamente e usare questa conoscenza per determinare definitivamente che la configurazione o l'applicazione costituisca la causa radice.
È possibile usare le metriche relative ai probe di integrità per comprendere in che modo Azure visualizza lo stato della distribuzione in base alla configurazione specificata. L'analisi dei probe di integrità costituisce sempre una valida opzione per iniziare a monitorare o determinare una causa.
È possibile eseguire un ulteriore passaggio e usare le metriche relative alla disponibilità del percorso dati per ottenere informazioni approfondite sul modo in cui Azure visualizza l'integrità del piano dati sottostante che è responsabile per la specifica distribuzione. Quando si combinano entrambe le metriche, è possibile isolare il punto in cui potrebbe verificarsi l'errore come illustrato in questo esempio:
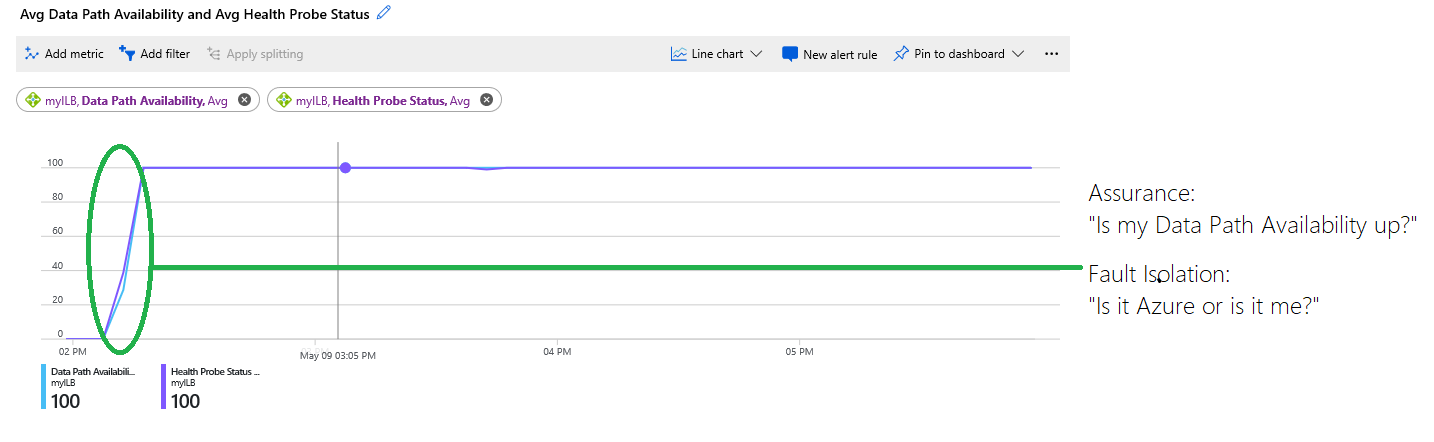
Figura - Combinazione delle metriche di stato del probe di integrità e disponibilità del percorso dei dati
In questo grafico vengono visualizzate le informazioni seguenti:
L'infrastruttura che ospita le macchine virtuali non era disponibile e al 0% all'inizio del grafico. Successivamente, l'infrastruttura risultava integra e le macchine virtuali erano raggiungibili e più macchine virtuali venivano posizionate nel back-end. Queste informazioni sono indicate dalla traccia blu per la disponibilità del percorso dati, successivamente al 100%.
Lo stato del probe di integrità, indicato dalla traccia viola, è pari allo 0% all'inizio del grafico. L'area cerchiata in rosso evidenzia il punto in cui lo stato probe di integrità è diventato integro e in quale punto la distribuzione del cliente è stata in grado di accettare nuovi flussi.
Il grafico consente al cliente di risolvere i problemi della distribuzione in modo autonomo senza dover fare supposizioni o contattare il supporto per sapere se si stanno verificando altri problemi. Il servizio non era disponibile perché i probe di integrità hanno avuto esito negativo a causa di una configurazione errata o di un'applicazione non riuscita.
Configurare gli avvisi per le metriche multidimensionali
Azure Load Balancer supporta avvisi facilmente configurabili per le metriche multidimensionali. Configurare soglie personalizzate per metriche specifiche per attivare avvisi con diversi livelli di gravità per offrire un'esperienza di monitoraggio delle risorse senza tocco.
Per configurare gli avvisi:
Passare alla pagina di avviso per il servizio di bilanciamento del carico
Creare una nuova regola di avviso
Configurare la condizione di avviso (nota: per evitare avvisi rumorosi, è consigliabile configurare gli avvisi con il tipo di aggregazione impostato su Media, esaminando una finestra di cinque minuti di dati e con una soglia del 95%)
(Facoltativo) Aggiungere un gruppo di azioni per il ripristino automatizzato
Assegnare gravità, nome e descrizione dell'avviso che consente una reazione intuitiva
Avvisi di disponibilità in ingresso
Nota
Se i pool back-end del servizio di bilanciamento del carico sono vuoti, il servizio di bilanciamento del carico non avrà percorsi di dati validi da testare. Di conseguenza, non sarà disponibile la metrica di disponibilità del percorso dati e non verranno attivati gli avvisi di Azure configurati nella metrica di disponibilità del percorso dati.
Per ricevere avvisi per la disponibilità in ingresso, è possibile creare due avvisi separati usando le metriche di disponibilità del percorso dati e stato del probe di integrità. I clienti possono avere scenari diversi che richiedono una logica di avviso specifica, ma gli esempi seguenti sono utili per la maggior parte delle configurazioni.
Usando la disponibilità del percorso dati, è possibile generare avvisi ogni volta che una regola di bilanciamento del carico specifica diventa non disponibile. È possibile configurare questo avviso impostando una condizione di avviso per la disponibilità del percorso dati e dividendo per tutti i valori correnti e i valori futuri per la porta front-end e l'indirizzo IP front-end. Se si imposta la logica di avviso su un valore minore o pari a 0, questo avviso verrà attivato ogni volta che una regola di bilanciamento del carico non risponde. Impostare la granularità dell'aggregazione e la frequenza di valutazione in base alla valutazione desiderata.
Con lo stato del probe di integrità, è possibile avvisare quando una determinata istanza back-end non risponde al probe di integrità per parecchio tempo. Configurare la condizione di avviso per usare la metrica relativa allo stato del probe di integrità e suddividerla per indirizzo IP back-end e porta back-end. In questo modo è possibile inviare avvisi separatamente per la capacità di ogni singola istanza back-end per gestire il traffico su una porta specifica. Usare il tipo di aggregazione Media e impostare il valore soglia in base alla frequenza con cui viene eseguita il probe dell'istanza back-end e alla soglia considerata integra.
Inoltre, è possibile generare un avviso a livello di pool back-end senza suddividere le dimensioni in base alle dimensioni e usando il tipo di aggregazione Media. In questo modo si possono configurare regole di avviso come l'avviso quando il 50% dei membri del pool back-end non è integro.
Creazione di avvisi sulla disponibilità in uscita
Per la disponibilità in uscita, è possibile configurare due avvisi separati usando il numero di connessioni SNAT e le metriche delle porte SNAT usate.
Per rilevare gli errori di connessione in uscita, configurare un avviso usando il numero di connessioni SNAT e il filtro per Stato connessione = Non riuscito. Usare l'aggregazione Totale. Pertanto è possibile suddividerlo in base all'indirizzo IP back-end impostato su tutti i valori attuali e futuri per avvisare separatamente per ogni istanza back-end che riscontra connessioni non riuscite. Impostare la soglia su superiore a zero o un numero superiore se si prevede di visualizzare alcuni errori di connessione in uscita.
Con le porte SNAT usate, è possibile segnalare un rischio maggiore di esaurimento SNAT e di errore della connessione in uscita. Assicurarsi di suddividere in base all'indirizzo IP e al protocollo back-end quando si usa questo avviso. Usare l'aggregazione Media. Impostare la soglia in modo che sia maggiore di una percentuale del numero di porte allocate per ogni istanza che non risulta sicura. Ad esempio, configurare un avviso di gravità bassa quando un'istanza back-end usa il 75% delle porte allocate. Configurare un avviso di gravità elevata quando usa il 90% o il 100% delle porte allocate.
Stato di integrità delle risorse
Lo stato di integrità per le risorse di bilanciamento del carico standard viene esposto tramite Integrità risorse in Monitoraggio > Integrità dei servizi. Viene valutato ogni due minuti misurando la disponibilità del percorso dati che determina se gli endpoint di bilanciamento del carico front-end sono disponibili.
| Stato di integrità delle risorse | Descrizione |
|---|---|
| Disponibile | La risorsa di bilanciamento del carico standard è integra e disponibile. |
| Degraded | Il servizio di bilanciamento del carico standard ha eventi avviati dalla piattaforma o dall'utente che influiscono sulle prestazioni. La metrica di disponibilità del percorso dati ha restituito un valore di integrità inferiore al 90% ma maggiore del 25% per almeno due minuti. Con questo stato, si verifica un effetto moderato e grave sulle prestazioni. Seguire la guida alla risoluzione dei problemi di RHC per stabilire se sono presenti eventi avviati dall'utente che influiscono sulla disponibilità. |
| Non disponibile | La risorsa del servizio di bilanciamento del carico standard non è integra. La metrica per la disponibilità del percorso dati ha segnalato un integrità al di sotto del 25% per almeno due minuti. Con questo stato si avranno effetti significativi sulle prestazioni o mancanza di disponibilità per la connettività in ingresso. Potrebbero verificarsi eventi utente o piattaforma che causano un'indisponibilità. Seguire la guida alla risoluzione dei problemi di RHC per stabilire se sono presenti eventi avviati dall'utente che influiscono sulla disponibilità. |
| Sconosciuto | Lo stato di integrità per la risorsa del servizio di bilanciamento del carico non è stato aggiornato o non ha ricevuto informazioni sulla disponibilità del percorso dati negli ultimi 10 minuti. Questo stato deve essere temporaneo e rifletterà lo stato corretto non appena vengono ricevuti i dati. |
Per visualizzare l'integrità delle risorse della configurazione pubblica di bilanciamento del carico standard:
Selezionare Monitor>Integrità dei servizi.
Figura - Collegamento a Integrità dei servizi in Monitoraggio di Azure
Selezionare Integrità risorse e assicurarsi che ID di sottoscrizione e Tipo di risorsa = bilanciamento del carico siano selezionati.
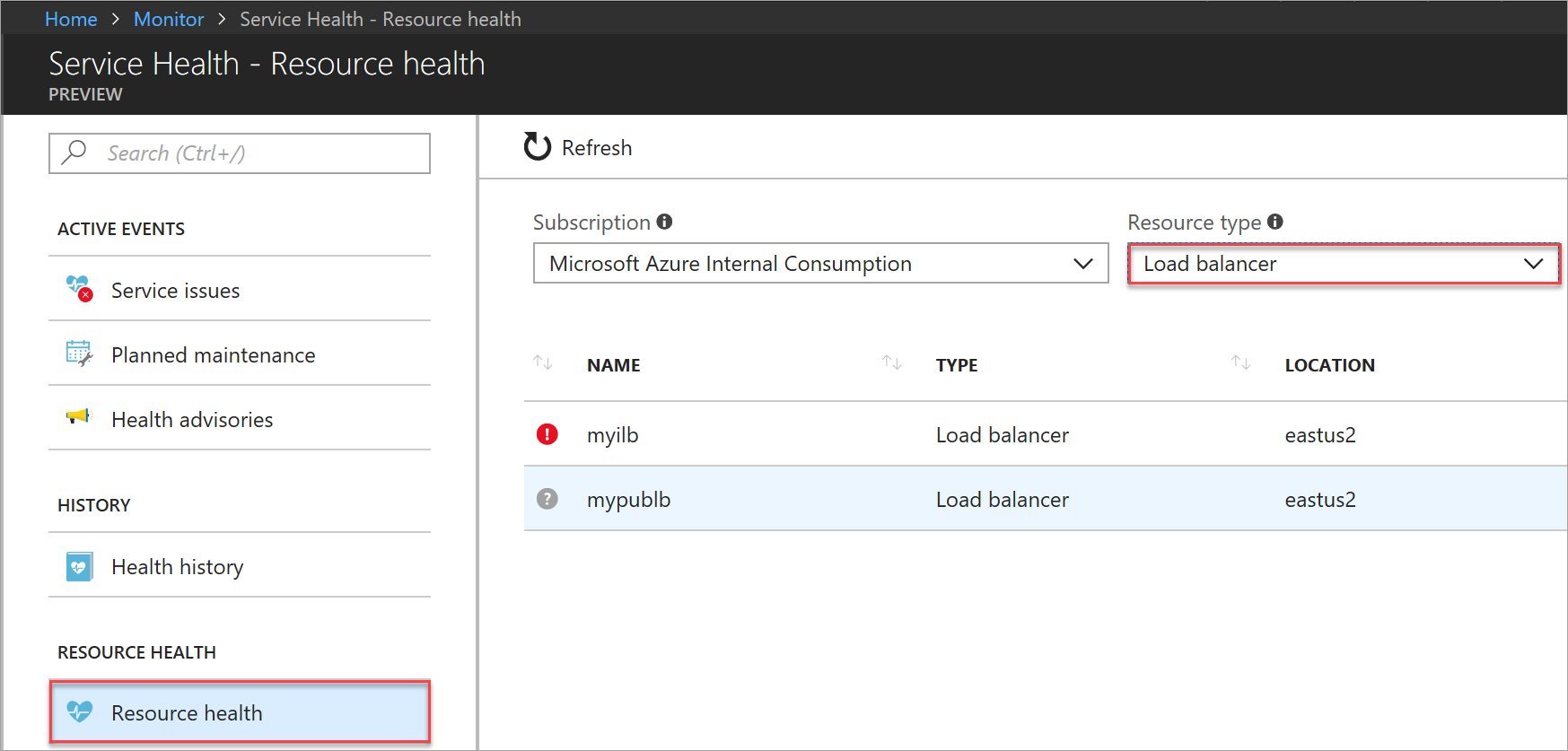
Figura: Selezionare la risorsa per la visualizzazione dell'integrità
Selezionare la risorsa di bilanciamento del carico dall'elenco per visualizzare il relativo stato di integrità cronologico.
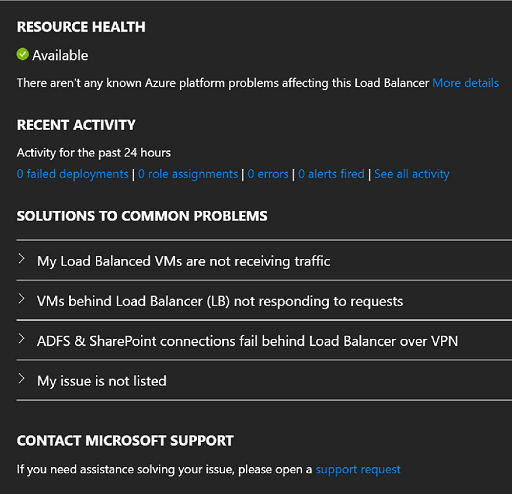
Figura - Stato di integrità delle risorse
Una descrizione generica dello stato di integrità delle risorse è disponibile nella documentazione sull'integrità delle risorse.
Avvisi sull'integrità delle risorse
Gli avvisi di Integrità risorse di Azure possono inviare notifiche quasi in tempo reale quando cambia lo stato di integrità della risorsa del servizio di bilanciamento del carico. È consigliabile impostare gli avvisi di integrità delle risorse per ricevere una notifica quando la risorsa di bilanciamento del carico è in stato danneggiato o non disponibile.
Quando si creano avvisi di integrità delle risorse di Azure per Il servizio di bilanciamento del carico, Azure invia notifiche sull'integrità delle risorse alla sottoscrizione di Azure. È possibile creare e personalizzare gli avvisi in base alle seguenti opzioni:
- La sottoscrizione interessata
- Gruppo di risorse interessato
- Tipo di risorsa interessato (bilanciamento del carico)
- Risorsa specifica (qualsiasi risorsa del servizio di bilanciamento del carico scelta per la configurazione di un avviso)
- Stato dell'evento della risorsa del servizio di bilanciamento del carico interessato
- Stato attuale della risorsa del servizio di bilanciamento del carico interessato
- Stato precedente della risorsa del servizio di bilanciamento del carico interessato
- Tipo di motivo della risorsa del servizio di bilanciamento del carico interessato
È anche possibile configurare l'utente a cui deve essere inviato l'avviso:
- Un nuovo gruppo di azione (che può essere usato per avvisi futuri)
- Un gruppo di azioni esistente
Per ulteriori informazioni su come configurare questi avvisi di integrità delle risorse, consultare:
- Avvisi di integrità delle risorse tramite il portale di Azure
- Avvisi di integrità risorse di Azure tramite modelli di Resource Manager
Passaggi successivi
- Informazioni su Analisi di rete.
- Informazioni sull'uso di Dati analitici per visualizzare queste metriche preconfigurate per il servizio di bilanciamento del carico.
- Ulteriori informazioni sul Servizio di bilanciamento del carico Standard.