Il processo di data science per i team (TDSP) è una metodologia di data science agile e iterativa che è possibile usare per offrire in modo efficiente soluzioni di analisi predittiva e applicazioni di intelligenza artificiale. TDSP aiuta a migliorare la collaborazione e l'apprendimento dei team suggerendo il modo in cui i ruoli del team interagiscono meglio. Il TDSP include procedure consigliate e strutture di Microsoft e altri leader del settore per aiutare il team a implementare correttamente le iniziative di data science e realizzare appieno i vantaggi del programma di analisi.
Questo articolo riporta una panoramica del TDSP e dei suoi componenti principali. Vengono fornite indicazioni su come implementare il TDSP usando gli strumenti e l'infrastruttura Microsoft. È possibile trovare risorse più dettagliate in tutto l'articolo.
Componenti principali del TDSP
Il TDSP include i componenti chiave seguenti:
- Una definizione del ciclo di vita del data science
- Una struttura di progetto standardizzata
- Infrastruttura e risorse consigliate per i progetti di data science
- Strumenti e utilità consigliati per l'esecuzione dei progetti
Ciclo di vita del data science
Il TDSP fornisce un ciclo di vita che è possibile usare per strutturare lo sviluppo dei progetti di data science. Il ciclo di vita descrive tutti i passaggi da seguire per la riuscita dei progetti.
È possibile combinare il TDSP basato su attività con altri cicli di vita di data science, ad esempio il processo standard tra i settori per il data mining (CRISP-DM), il processo di individuazione delle informazioni nei database (KDD) o un altro processo personalizzato. In generale queste diverse metodologie hanno molto in comune.
È consigliabile usare questo ciclo di vita se si dispone di un progetto di data science che fa parte di un'applicazione intelligente. Le applicazioni intelligenti distribuiscono modelli di Machine Learning o intelligenza artificiale per l'analisi predittiva. È anche possibile usare questo processo per progetti esplorativi di data science e progetti di analisi improvvisati.
Il ciclo di vita del TDSP è costituito da cinque fasi principali eseguite dal team in modo iterativo. Queste fasi includono:
- Comprensione del business
- Acquisizione e comprensione dei dati
- Modellazione
- Distribuzione
- Accettazione del cliente
Ecco una rappresentazione visiva del ciclo di vita di TDSP:
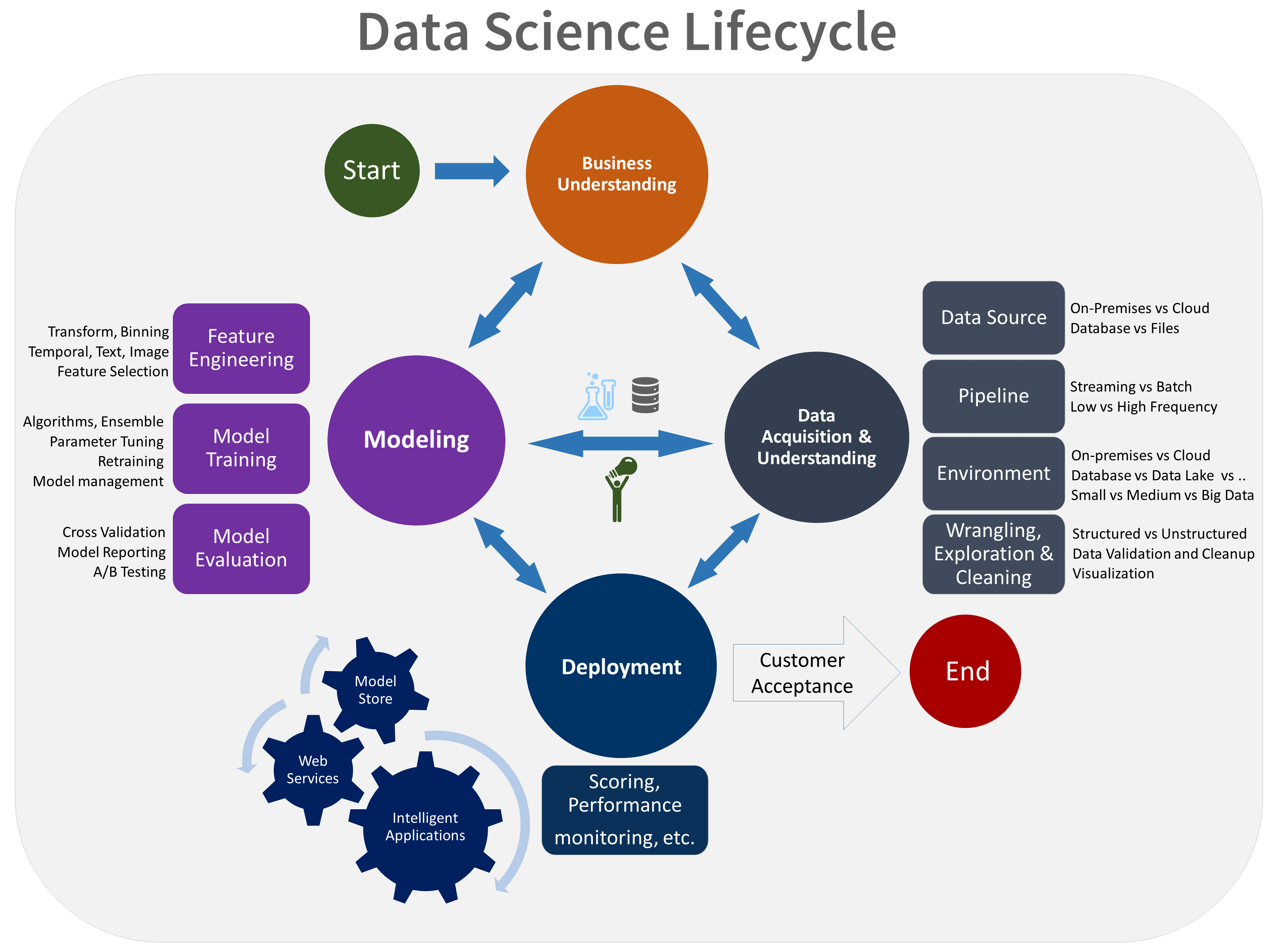
Per informazioni sugli obiettivi, le attività e gli artefatti della documentazione per ogni fase, vedere Ciclo di vita del processo di data science per i team.
Queste attività e elementi sono associati ai ruoli del progetto, ad esempio:
- Progettista di soluzioni.
- Responsabile di progetto.
- Data engineer.
- Data scientist.
- Sviluppatore di applicazioni.
- Responsabile del progetto.
Il diagramma seguente mostra le attività (in blu) e gli artefatti (in verde) associati a ogni fase del ciclo di vita (sull'asse orizzontale) per questi ruoli (sull'asse verticale).

Struttura di progetto standardizzata
Il team può usare l'infrastruttura di Azure per organizzare gli asset di data science.
Azure Machine Learning supporta MLflow open source. È consigliabile usare MLflow per la gestione dei progetti di data science e intelligenza artificiale. MLflow è progettato per gestire il ciclo di vita completo di Machine Learning. Esegue il training e gestisce modelli su piattaforme diverse, in modo da poter usare un set coerente di strumenti indipendentemente dalla posizione in cui vengono eseguiti gli esperimenti. È possibile usare MLflow localmente nel computer, in una destinazione di calcolo remota, in una macchina virtuale o in un'istanza di calcolo di Machine Learning.
MLflow è costituito da diverse funzionalità chiave:
Tenere traccia degli esperimenti: con MLflow è possibile tenere traccia degli esperimenti, inclusi parametri, versioni del codice, metriche e file di output. Questa funzionalità consente di confrontare esecuzioni diverse e di gestire in modo efficiente il processo di sperimentazione.
Codice del pacchetto: offre un formato standardizzato per la creazione di pacchetti di codice di Machine Learning, che include dipendenze e configurazioni. Questo pacchetto semplifica la riproduzione delle esecuzioni e la condivisione del codice con altri utenti.
Gestire i modelli: MLflow offre funzionalità per la gestione e il controllo delle versioni dei modelli. Supporta diversi framework di Machine Learning, in modo da poter archiviare, versione e gestire i modelli.
Gestire e distribuire modelli: MLflow integra funzionalità di distribuzione e gestione dei modelli, in modo da poter distribuire facilmente i modelli in ambienti diversi.
Registrare i modelli: è possibile gestire il ciclo di vita di un modello, inclusi il controllo delle versioni, le transizioni di fase e le annotazioni. MLflow è utile per gestire un archivio modelli centralizzato in un ambiente collaborativo.
Usare un'API e un'interfaccia utente: all'interno di Azure, MLflow è incluso nell'API di Machine Learning versione 2, in modo da poter interagire con il sistema a livello di codice. È possibile usare il portale di Azure per interagire con un'interfaccia utente.
MLflow mira a semplificare e standardizzare il processo di sviluppo di Machine Learning, dalla sperimentazione alla distribuzione.
Machine Learning si integra con i repository Git, quindi è possibile usare servizi compatibili con Git: GitHub, GitLab, Bitbucket, Azure DevOps o un altro servizio compatibile con Git. Oltre agli asset già registrati in Machine Learning, il team può sviluppare la propria tassonomia all'interno del servizio compatibile con Git per archiviare altre informazioni sul progetto, ad esempio:
- Documentazione
- Progetto, ad esempio il report finale del progetto
- Report dei dati, ad esempio il dizionario dati o i report sulla qualità dei dati
- Modello, ad esempio report modello
- Codice
- Preparazione dei dati
- Sviluppo del modello
- Operazionalizzazione, tra cui sicurezza e conformità
Infrastruttura e risorse
Il TDSP offre raccomandazioni per la gestione di analisi condivise e dell'infrastruttura di archiviazione, ad esempio:
- File system cloud per l'archiviazione di set di dati
- Database
- Cluster Big Data, ad esempio SQL o Spark
- Machine Learning Services
È possibile posizionare l'infrastruttura di analisi e archiviazione, in cui vengono archiviati set di dati non elaborati e non elaborati, nel cloud o in locale. Questa infrastruttura consente di eseguire analisi riproducibili. Impedisce inoltre la duplicazione, che può causare incoerenze e costi di infrastruttura non necessari. L'infrastruttura include strumenti per effettuare il provisioning delle risorse condivise, monitorarle e consentire a ogni membro del team di connettersi in modo sicuro a tali risorse. È anche consigliabile fare in modo che i membri del progetto creino un ambiente di calcolo coerente. I vari membri del team possono quindi replicare e convalidare gli esperimenti.
Ecco un esempio di team che lavora su più progetti e condivide vari componenti dell'infrastruttura di analisi cloud:

Strumenti e utilità
Nella maggior parte delle organizzazioni è difficile introdurre processi. L'infrastruttura fornisce strumenti per implementare il TDSP e il ciclo di vita aiutano a ridurre le barriere e aumentare la coerenza dell'adozione.
Con Machine Learning, i data scientist possono applicare strumenti open source come parte della pipeline di data science o del flusso di lavoro. All'interno di Machine Learning, Microsoft promuove gli strumenti di intelligenza artificiale responsabili, che consentono di ottenere lo standard di intelligenza artificiale responsabile di Microsoft.
Citazioni con peer reviewing
TDSP è una metodologia ben consolidata usata per gli impegni Microsoft e pertanto è stata documentata e studiata nella letteratura con revisione peer. Queste citazioni offrono l'opportunità di esaminare le funzionalità e le applicazioni TDSP. Per un elenco di citazioni, vedere la pagina di panoramica del ciclo di vita.