Esercitazione REST: Usare set di competenze per generare contenuto ricercabile in Ricerca di intelligenza artificiale di Azure
Questa esercitazione illustra come chiamare le API REST che creano una pipeline di arricchimento tramite intelligenza artificiale per l'estrazione e le trasformazioni del contenuto durante l'indicizzazione.
I set di competenze aggiungono l'elaborazione di intelligenza artificiale al contenuto non elaborato, rendendo il contenuto più uniforme e ricercabile. Una volta appreso il funzionamento dei set di competenze, è possibile supportare un'ampia gamma di trasformazioni: dall'analisi delle immagini all'elaborazione del linguaggio naturale, all'elaborazione personalizzata fornita esternamente.
Questa esercitazione illustra come:
- Definire gli oggetti in una pipeline di arricchimento.
- Creare un set di competenze. Richiamare OCR, rilevamento della lingua, riconoscimento delle entità ed estrazione di frasi chiave.
- Eseguire la pipeline. Creare e caricare un indice di ricerca.
- Controllare i risultati usando la ricerca full-text.
Se non si ha una sottoscrizione di Azure, aprire un account gratuito prima di iniziare.
Panoramica
Questa esercitazione usa un client REST e le API REST di Ricerca intelligenza artificiale di Azure per creare un'origine dati, un indice, un indicizzatore e un set di competenze.
L'indicizzatore guida ogni passaggio della pipeline, a partire dall'estrazione del contenuto di dati di esempio (testo e immagini non strutturati) in un contenitore BLOB in Archiviazione di Azure.
Una volta estratto il contenuto, il set di competenze esegue competenze predefinite da Microsoft per trovare ed estrarre informazioni. Queste competenze includono il riconoscimento ottico dei caratteri (OCR) sulle immagini, il rilevamento della lingua sul testo, l'estrazione di frasi chiave e il riconoscimento delle entità (organizzazioni). Le nuove informazioni create dal set di competenze vengono inviate ai campi in un indice. Dopo aver popolato l'indice, è possibile usare i campi nelle query, nei facet e nei filtri.
Prerequisiti
Nota
Per questa esercitazione è possibile usare un servizio di ricerca gratuito. Il livello gratuito limita tre indici, tre indicizzatori e tre origini dati. Questa esercitazione crea un elemento per ogni tipo. Prima di iniziare, assicurarsi che lo spazio nel servizio sia sufficiente per accettare le nuove risorse.
Scaricare i file
Scaricare un file ZIP del repository di dati di esempio ed estrarre il contenuto. Informazioni.
Caricare dati di esempio in Archiviazione di Azure
In Archiviazione di Azure creare un nuovo contenitore e denominarlo cog-search-demo.
Caricare i file di dati di esempio.
Ottenere un stringa di connessione di archiviazione in modo da poter formulare una connessione in Ricerca di intelligenza artificiale di Azure.
A sinistra selezionare Chiavi di accesso.
Copiare il stringa di connessione per la chiave uno o due. L'stringa di connessione è simile all'esempio seguente:
DefaultEndpointsProtocol=https;AccountName=<your account name>;AccountKey=<your account key>;EndpointSuffix=core.windows.net
Servizi di Azure AI
L'arricchimento integrato tramite intelligenza artificiale è supportato dai servizi di intelligenza artificiale di Azure, tra cui il servizio di linguaggio e Visione artificiale di Azure per l'elaborazione di linguaggio naturale e immagini. Per carichi di lavoro di piccole dimensioni come questa esercitazione, è possibile usare l'allocazione gratuita di venti transazioni per indicizzatore. Per carichi di lavoro di dimensioni maggiori, collegare una risorsa multiarea di Servizi di intelligenza artificiale di Azure a un set di competenze per i prezzi con pagamento in base al consumo.
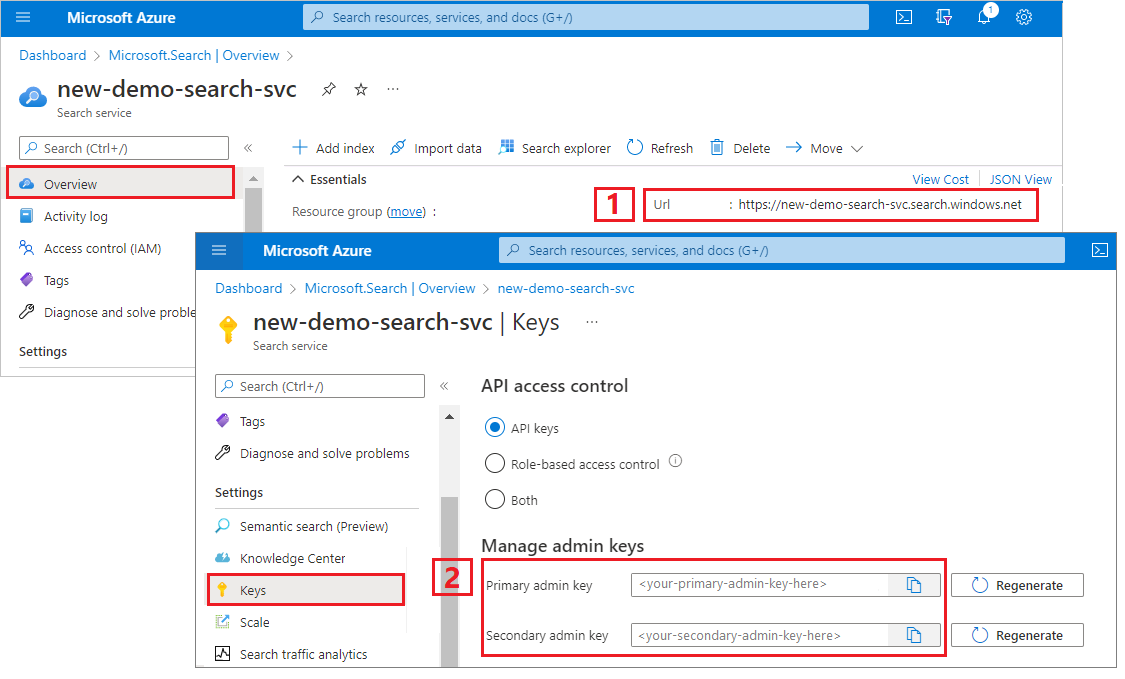
Copiare un URL del servizio di ricerca e una chiave API
Per questa esercitazione, le connessioni a Ricerca intelligenza artificiale di Azure richiedono un endpoint e una chiave API. È possibile ottenere questi valori dalla portale di Azure.
Accedere al portale di Azure, passare alla pagina Panoramica del servizio di ricerca e copiare l'URL. Un endpoint di esempio potrebbe essere simile a
https://mydemo.search.windows.net.In Impostazioni> Chiavi copiare una chiave di amministratore. Amministrazione chiavi vengono usate per aggiungere, modificare ed eliminare oggetti. Sono disponibili due chiavi di amministrazione intercambiabili. Copiarne uno.
Configurare il file REST
Avviare Visual Studio Code e aprire il file skillset-tutorial.rest . Per assistenza con il client REST, vedere Guida introduttiva: Ricerca di testo con REST .
Specificare i valori per le variabili: l'endpoint del servizio di ricerca, la chiave API dell'amministratore del servizio di ricerca, un nome di indice, un stringa di connessione all'account Archiviazione di Azure e il nome del contenitore BLOB.
Creare la pipeline
L'arricchimento tramite intelligenza artificiale è basato sull'indicizzatore. In questa parte della procedura dettagliata vengono creati quattro oggetti: origine dati, definizione dell'indice, set di competenze e indicizzatore.
Passaggio 1: Creare un'origine dati
Chiamare Create Data Source (Crea origine dati) per impostare il stringa di connessione sul contenitore BLOB contenente i file di dati di esempio.
### Create a data source
POST {{baseUrl}}/datasources?api-version=2023-11-01 HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
{
"name": "cog-search-demo-ds",
"description": null,
"type": "azureblob",
"subtype": null,
"credentials": {
"connectionString": "{{storageConnectionString}}"
},
"container": {
"name": "{{blobContainer}}",
"query": null
},
"dataChangeDetectionPolicy": null,
"dataDeletionDetectionPolicy": null
}
Passaggio 2: Creare un set di competenze
Chiama Create Skillset (Crea set di competenze) per specificare quali passaggi di arricchimento vengono applicati al contenuto. Le competenze sono eseguite in parallelo, a meno che non esista una dipendenza.
### Create a skillset
POST {{baseUrl}}/skillsets?api-version=2023-11-01 HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
{
"name": "cog-search-demo-ss",
"description": "Apply OCR, detect language, extract entities, and extract key-phrases.",
"cognitiveServices": null,
"skills":
[
{
"@odata.type": "#Microsoft.Skills.Vision.OcrSkill",
"context": "/document/normalized_images/*",
"defaultLanguageCode": "en",
"detectOrientation": true,
"inputs": [
{
"name": "image",
"source": "/document/normalized_images/*"
}
],
"outputs": [
{
"name": "text"
}
]
},
{
"@odata.type": "#Microsoft.Skills.Text.MergeSkill",
"description": "Create merged_text, which includes all the textual representation of each image inserted at the right location in the content field. This is useful for PDF and other file formats that supported embedded images.",
"context": "/document",
"insertPreTag": " ",
"insertPostTag": " ",
"inputs": [
{
"name":"text",
"source": "/document/content"
},
{
"name": "itemsToInsert",
"source": "/document/normalized_images/*/text"
},
{
"name":"offsets",
"source": "/document/normalized_images/*/contentOffset"
}
],
"outputs": [
{
"name": "mergedText",
"targetName" : "merged_text"
}
]
},
{
"@odata.type": "#Microsoft.Skills.Text.SplitSkill",
"textSplitMode": "pages",
"maximumPageLength": 4000,
"defaultLanguageCode": "en",
"context": "/document",
"inputs": [
{
"name": "text",
"source": "/document/merged_text"
}
],
"outputs": [
{
"name": "textItems",
"targetName": "pages"
}
]
},
{
"@odata.type": "#Microsoft.Skills.Text.LanguageDetectionSkill",
"description": "If you have multilingual content, adding a language code is useful for filtering",
"context": "/document",
"inputs": [
{
"name": "text",
"source": "/document/merged_text"
}
],
"outputs": [
{
"name": "languageName",
"targetName": "language"
}
]
},
{
"@odata.type": "#Microsoft.Skills.Text.KeyPhraseExtractionSkill",
"context": "/document/pages/*",
"inputs": [
{
"name": "text",
"source": "/document/pages/*"
}
],
"outputs": [
{
"name": "keyPhrases",
"targetName": "keyPhrases"
}
]
},
{
"@odata.type": "#Microsoft.Skills.Text.V3.EntityRecognitionSkill",
"categories": ["Organization"],
"context": "/document",
"inputs": [
{
"name": "text",
"source": "/document/merged_text"
}
],
"outputs": [
{
"name": "organizations",
"targetName": "organizations"
}
]
},
{
"@odata.type": "#Microsoft.Skills.Text.V3.EntityRecognitionSkill",
"categories": ["Location"],
"context": "/document",
"inputs": [
{
"name": "text",
"source": "/document/merged_text"
}
],
"outputs": [
{
"name": "locations",
"targetName": "locations"
}
]
},
{
"@odata.type": "#Microsoft.Skills.Text.V3.EntityRecognitionSkill",
"categories": ["Person"],
"context": "/document",
"inputs": [
{
"name": "text",
"source": "/document/merged_text"
}
],
"outputs": [
{
"name": "persons",
"targetName": "persons"
}
]
}
]
}
Punti principali:
Il corpo della richiesta specifica le competenze predefinite seguenti:
Competenza Descrizione Riconoscimento ottico dei caratteri Riconosce il testo e i numeri nei file di immagine. Unione testo Crea "contenuto unito" che ricombina il contenuto separato in precedenza, utile per i documenti con immagini incorporate (PDF, DOCX e così via). Le immagini e il testo vengono separati durante la fase di cracking del documento. La competenza di merge li ricombina inserendo qualsiasi testo riconosciuto, immagine didascalia o tag creati durante l'arricchimento nella stessa posizione in cui l'immagine è stata estratta dal documento. Quando si lavora con il contenuto unito in un set di competenze, questo nodo è inclusivo di tutto il testo del documento, inclusi i documenti solo testo che non vengono mai sottoposti a OCR o analisi delle immagini. Rilevamento lingua Rileva la lingua e restituisce un nome di lingua o un codice. Nei set di dati multilingue, un campo lingua può essere utile per i filtri. Riconoscimento delle entità Estrae i nomi di persone, organizzazioni e posizioni dal contenuto unito. Suddivisione del testo Suddivide il contenuto unito di grandi dimensioni in blocchi più piccoli prima di chiamare la competenza di estrazione frasi chiave. L'estrazione delle frasi chiave accetta input di al massimo 50.000 caratteri. Alcuni dei file di esempio devono essere suddivisi per rispettare questo limite. Estrazione frasi chiave Estrae le frasi chiave principali. Ogni competenza viene eseguita sul contenuto del documento. Durante l'elaborazione, Ricerca intelligenza artificiale di Azure esegue il cracking di ogni documento per leggere il contenuto da formati di file diversi. Il testo trovato con origine nel file di origine viene inserito in un campo
contentgenerato, uno per ogni documento. L'input diventa quindi"/document/content".Dal momento che per l'estrazione di frasi chiave si usa la competenza di suddivisione del testo per suddividere file più grandi in pagine, il contesto per la competenza di estrazione delle frasi chiave è
"document/pages/*"(per ogni pagina del documento) invece di"/document/content".
Nota
Gli output possono essere mappati a un indice, usati come input per una competenza a valle, o entrambi, come nel caso del codice di lingua. Nell'indice, un codice di lingua è utile per le operazioni di filtro. Per altre informazioni sui concetti di base dei set di competenze, vedere How to create a skillset (Come creare un set di competenze).
Passaggio 3: Creare un indice
Chiamare Create Index per fornire lo schema usato per creare indici invertiti e altri costrutti in Ricerca di intelligenza artificiale di Azure.
Il componente più grande di un indice è la raccolta di campi, in cui il tipo di dati e gli attributi determinano il contenuto e il comportamento in Ricerca di intelligenza artificiale di Azure. Assicurarsi di avere campi per l'output appena generato.
### Create an index
POST {{baseUrl}}/indexes?api-version=2023-11-01 HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
{
"name": "cog-search-demo-idx",
"defaultScoringProfile": "",
"fields": [
{
"name": "content",
"type": "Edm.String",
"searchable": true,
"sortable": false,
"filterable": false,
"facetable": false
},
{
"name": "text",
"type": "Collection(Edm.String)",
"facetable": false,
"filterable": true,
"searchable": true,
"sortable": false
},
{
"name": "language",
"type": "Edm.String",
"searchable": false,
"sortable": true,
"filterable": true,
"facetable": false
},
{
"name": "keyPhrases",
"type": "Collection(Edm.String)",
"searchable": true,
"sortable": false,
"filterable": true,
"facetable": true
},
{
"name": "organizations",
"type": "Collection(Edm.String)",
"searchable": true,
"sortable": false,
"filterable": true,
"facetable": true
},
{
"name": "persons",
"type": "Collection(Edm.String)",
"searchable": true,
"sortable": false,
"filterable": true,
"facetable": true
},
{
"name": "locations",
"type": "Collection(Edm.String)",
"searchable": true,
"sortable": false,
"filterable": true,
"facetable": true
},
{
"name": "metadata_storage_path",
"type": "Edm.String",
"key": true,
"searchable": true,
"sortable": false,
"filterable": false,
"facetable": false
},
{
"name": "metadata_storage_name",
"type": "Edm.String",
"searchable": true,
"sortable": false,
"filterable": false,
"facetable": false
}
]
}
Passaggio 4: Creare ed eseguire un indicizzatore
Chiamare Create Indexer (Crea indicizzatore ) per guidare la pipeline. I tre componenti creati finora (origine dati, set di competenze, indice) costituiscono i valori di input di un indicizzatore. La creazione dell'indicizzatore in Ricerca di intelligenza artificiale di Azure è l'evento che attiva l'intera pipeline.
Il completamento di questa operazione può richiedere alcuni minuti. Anche se il set di dati è piccolo, le competenze analitiche prevedono un utilizzo elevato delle risorse di calcolo.
### Create and run an indexer
POST {{baseUrl}}/indexers?api-version=2023-11-01 HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
{
"name": "cog-search-demo-idxr",
"description": "",
"dataSourceName" : "cog-search-demo-ds",
"targetIndexName" : "cog-search-demo-idx",
"skillsetName" : "cog-search-demo-ss",
"fieldMappings" : [
{
"sourceFieldName" : "metadata_storage_path",
"targetFieldName" : "metadata_storage_path",
"mappingFunction" : { "name" : "base64Encode" }
},
{
"sourceFieldName": "metadata_storage_name",
"targetFieldName": "metadata_storage_name"
}
],
"outputFieldMappings" :
[
{
"sourceFieldName": "/document/merged_text",
"targetFieldName": "content"
},
{
"sourceFieldName" : "/document/normalized_images/*/text",
"targetFieldName" : "text"
},
{
"sourceFieldName" : "/document/organizations",
"targetFieldName" : "organizations"
},
{
"sourceFieldName": "/document/language",
"targetFieldName": "language"
},
{
"sourceFieldName" : "/document/persons",
"targetFieldName" : "persons"
},
{
"sourceFieldName" : "/document/locations",
"targetFieldName" : "locations"
},
{
"sourceFieldName" : "/document/pages/*/keyPhrases/*",
"targetFieldName" : "keyPhrases"
}
],
"parameters":
{
"batchSize": 1,
"maxFailedItems":-1,
"maxFailedItemsPerBatch":-1,
"configuration":
{
"dataToExtract": "contentAndMetadata",
"imageAction": "generateNormalizedImages"
}
}
}
Punti principali:
Il corpo della richiesta include riferimenti agli oggetti precedenti, alle proprietà di configurazione necessarie per l'elaborazione delle immagini e a due tipi di mapping dei campi.
"fieldMappings"vengono elaborati prima del set di competenze, inviando contenuto dall'origine dati ai campi di destinazione in un indice. I mapping dei campi vengono usati per inviare contenuto esistente non modificato all'indice. Se i nomi e i tipi di campo sono uguali alle due estremità, non è necessario alcun mapping."outputFieldMappings"sono per i campi creati dalle competenze, dopo l'esecuzione del set di competenze. I riferimenti asourceFieldNameinoutputFieldMappingsnon esistono fino a quando non vengono creati dal cracking o dall'arricchimento di documenti. L'oggettotargetFieldNameè un campo in un indice, definito nello schema dell'indice.Il
"maxFailedItems"parametro è impostato su -1, che indica al motore di indicizzazione di ignorare gli errori durante l'importazione dei dati. Questo comportamento è accettabile perché nell'origine dati demo sono presenti pochissimi documenti. Per un'origine dati più grande sarebbe necessario impostare un valore maggiore di 0.L'istruzione
"dataToExtract":"contentAndMetadata"indica all'indicizzatore di estrarre automaticamente i valori dalla proprietà del contenuto del BLOB e dai metadati di ogni oggetto.Il
imageActionparametro indica all'indicizzatore di estrarre testo dalle immagini trovate nell'origine dati. La configurazione"imageAction":"generateNormalizedImages", unita alla competenza OCR e alla competenza di unione del testo, indica all'indicizzatore di estrarre il testo dalle immagini (ad esempio, la parola "stop" da un segnale stradale di stop) e incorporarlo come parte del campo del contenuto. Questo comportamento si applica sia alle immagini incorporate (si pensi a un'immagine all'interno di un PDF) sia ai file di immagine autonomi, ad esempio a un file JPG.
Nota
La creazione di un indicizzatore richiama la pipeline. Eventuali problemi a raggiungere i dati, per il mapping di input e output o nell'ordine delle operazioni vengono visualizzati in questa fase. Per eseguire di nuovo la pipeline con modifiche per codice o script, potrebbe essere necessario eliminare prima gli oggetti. Per altre informazioni, vedere Reimpostare ed eseguire di nuovo.
Monitorare l'indicizzazione
L'indicizzazione e l'arricchimento iniziano non appena si invia la richiesta Crea l'indicizzatore. A seconda della complessità e delle operazioni del set di competenze, l'indicizzazione può richiedere del tempo.
Per verificare se l'indicizzatore è ancora in esecuzione, chiamare Get Indexer Status (Ottieni stato indicizzatore) per controllare lo stato dell'indicizzatore.
### Get Indexer Status (wait several minutes for the indexer to complete)
GET {{baseUrl}}/indexers/cog-search-demo-idxr/status?api-version=2023-11-01 HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
Punti principali:
Gli avvisi sono comuni in alcuni scenari e non sempre indicano un problema. Ad esempio, se un contenitore BLOB include file di immagine e la pipeline non gestisce le immagini, viene visualizzato un avviso che informa che le immagini non sono state elaborate.
In questo esempio è presente un file PNG che non contiene testo. Tutte e cinque le competenze basate sul testo (rilevamento della lingua, riconoscimento delle entità di posizioni, organizzazioni, persone ed estrazione di frasi chiave) non vengono eseguite in questo file. La notifica risultante viene visualizzata nella cronologia di esecuzione.
Controllare i risultati
Dopo aver creato un indice contenente contenuto generato dall'intelligenza artificiale, chiamare Documenti di ricerca per eseguire alcune query per visualizzare i risultati.
### Query the index\
POST {{baseUrl}}/indexes/cog-search-demo-idx/docs/search?api-version=2023-11-01 HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
{
"search": "*",
"select": "metadata_storage_name,language,organizations",
"count": true
}
I filtri consentono di restringere i risultati agli elementi di interesse:
### Filter by organization
POST {{baseUrl}}/indexes/cog-search-demo-idx/docs/search?api-version=2023-11-01 HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
{
"search": "*",
"filter": "organizations/any(organizations: organizations eq 'Microsoft')",
"select": "metadata_storage_name,organizations",
"count": true
}
Queste query illustrano alcuni dei modi in cui è possibile usare la sintassi delle query e i filtri sui nuovi campi creati da Ricerca di intelligenza artificiale di Azure. Per altri esempi di query, vedere Esempi nell'API REST di ricerca documenti, Esempi di sintassi di query semplice ed Esempi di sintassi di query Lucene completa.
Reimpostare ed eseguire di nuovo
Durante le prime fasi di sviluppo, l'iterazione sulla progettazione è comune. La reimpostazione e la riesecuzione aiutano con l'iterazione.
Risultati
Questa esercitazione illustra i passaggi di base per l'uso delle API REST per creare una pipeline di arricchimento tramite intelligenza artificiale: un'origine dati, un set di competenze, un indice e un indicizzatore.
Sono state introdotte competenze predefinite, insieme alla definizione del set di competenze che mostra i meccanismi di concatenamento delle competenze tramite input e output. Si è anche appreso che outputFieldMappings nella definizione dell'indicizzatore è necessario il routing di valori arricchiti dalla pipeline in un indice ricercabile in un servizio di ricerca di intelligenza artificiale di Azure.
Infine, è stato descritto come testare i risultati e reimpostare il sistema per ulteriori iterazioni. Si è appreso che l'esecuzione di query sull'indice consente di restituire l'output creato dalla pipeline di indicizzazione arricchita.
Pulire le risorse
Quando si lavora nella propria sottoscrizione, alla fine di un progetto è opportuno rimuovere le risorse che non sono più necessarie. Le risorse che rimangono in esecuzione hanno un costo. È possibile eliminare risorse singole oppure gruppi di risorse per eliminare l'intero set di risorse.
Per trovare e gestire le risorse nel portale, usare il collegamento Tutte le risorse o Gruppi di risorse nel riquadro di spostamento a sinistra.
Passaggi successivi
Ora che si ha familiarità con tutti gli oggetti in una pipeline di arricchimento tramite intelligenza artificiale, esaminare più in dettaglio le definizioni del set di competenze e le singole competenze.