Modelli di progettazione per applicazioni SaaS multi-tenant e Ricerca di intelligenza artificiale di Azure
Un'applicazione multi-tenant è una che fornisce gli stessi servizi e funzionalità a un numero qualsiasi di tenant che non possono visualizzare o condividere i dati di qualsiasi altro tenant. Questo articolo illustra le strategie di isolamento dei tenant per le applicazioni multi-tenant create con Ricerca di intelligenza artificiale di Azure.
Concetti di Ricerca intelligenza artificiale di Azure
Come soluzione di ricerca distribuita come servizio, Ricerca intelligenza artificiale di Azure consente agli sviluppatori di aggiungere esperienze di ricerca avanzate alle applicazioni senza gestire alcuna infrastruttura o diventare un esperto nel recupero delle informazioni. I dati vengano caricati nel servizio e quindi archiviati nel cloud. Usando richieste semplici all'API ricerca di intelligenza artificiale di Azure, i dati possono quindi essere modificati e cercati.
Servizi di ricerca, indici, campi e documenti
Prima di discutere dei modelli di progettazione, è importante comprendere alcuni concetti di base.
Quando si usa Ricerca intelligenza artificiale di Azure, si sottoscrive un servizio di ricerca. Quando i dati vengono caricati in Ricerca di intelligenza artificiale di Azure, vengono archiviati in un indice all'interno del servizio di ricerca. In un solo servizio possono essere presenti molti indici. Facendo riferimento ai familiari concetti relativi ai database, il servizio di ricerca può essere paragonato a un database, mentre gli indici all'interno di un servizio possono essere paragonati alle tabelle di un database.
Ogni indice all'interno di un servizio di ricerca ha un proprio schema, definito da un certo numero di campipersonalizzabili. I dati vengono aggiunti a un indice di Ricerca di intelligenza artificiale di Azure sotto forma di singoli documenti. Ogni documento deve essere caricato in un indice specifico e deve adattarsi allo schema di tale indice. Durante la ricerca dei dati con Ricerca di intelligenza artificiale di Azure, le query di ricerca full-text vengono eseguite su un determinato indice. Facendo riferimento ai database, i campi possono essere paragonati alle colonne e i documenti alle righe di una tabella del database.
Scalabilità
Qualsiasi servizio di ricerca di intelligenza artificiale di Azure nel piano tariffario Standard può essere ridimensionato in due dimensioni: archiviazione e disponibilità.
- partizioni per aumentare lo spazio di archiviazione di un servizio di ricerca.
- repliche a un servizio per aumentare la velocità effettiva delle richieste che un servizio di ricerca può gestire.
Aggiungendo e rimuovendo partizioni e repliche si consentirà alla capacità del servizio di ricerca di crescere in base alla quantità di dati e al traffico richiesti dall'applicazione. Affinché un servizio di ricerca rispetti un contratto di serviziodi lettura, sono necessarie due repliche. Affinché un servizio rispetti un contratto di serviziodi lettura-scrittura, sono necessarie tre repliche.
Limiti dei servizi e degli indici in Ricerca di intelligenza artificiale di Azure
Esistono alcuni piani tariffari diversi in Ricerca di intelligenza artificiale di Azure, ognuno dei livelli ha limiti e quote diversi. Alcuni di questi limiti sono a livello di servizio, altri sono a livello di indice e altri ancora a livello di partizione.
| Di base | Standard1 | Standard2 | Standard3 | Standard3 HD | |
|---|---|---|---|---|---|
| Numero massimo di repliche per servizio | 3 | 12 | 12 | 12 | 12 |
| Numero massimo di partizioni per servizio | 1 | 12 | 12 | 12 | 3 |
| Numero massimo di unità di ricerca (repliche*partizioni) per servizio | 3 | 36 | 36 | 36 | 36 (max 3 partizioni) |
| Numero massimo di Archiviazione per servizio | 2 GB | 300 GB | 1,2 TB | 2,4 TB | 600 GB |
| Numero massimo di Archiviazione per partizione | 2 GB | 25 GB | 100 GB | 200 GB | 200 GB |
| Numero massimo di indici per servizio | 5 | 50 | 200 | 200 | 3000 (max 1000 indici/partizione) |
S3 ad alta densità
Nel piano tariffario S3 di Ricerca intelligenza artificiale di Azure è disponibile un'opzione per la modalità HD (High Density) progettata in modo specifico per scenari multi-tenant. In molti casi, è necessario supportare un numero elevato di tenant più piccoli in un singolo servizio per ottenere i vantaggi della semplicità e dell'efficienza dei costi.
S3 HD consente di comprimere numerosi indici di piccole dimensioni, che vengono quindi gestiti da un singolo servizio di ricerca, sacrificando la possibilità di aumentare il numero di indici che usano le partizioni in cambio dell'hosting di un maggior numero di indici in un singolo servizio.
Un servizio S3 è progettato per ospitare un numero fisso di indici (massimo 200) e consentire a ogni indice di ridimensionare le dimensioni orizzontalmente man mano che vengono aggiunte nuove partizioni al servizio. L'aggiunta di partizioni ai servizi S3 HD aumenta il numero massimo di indici che il servizio può ospitare. La dimensione massima ideale per un singolo indice S3HD è di circa 50 - 80 GB, anche se non esiste alcun limite di dimensioni rigide per ogni indice imposto dal sistema.
Considerazioni per le applicazioni multi-tenant
Le applicazioni multi-tenant devono distribuire in modo efficace le risorse tra i tenant mantenendo al tempo stesso un certo livello di privacy tra i vari tenant. Quando si progetta l'architettura di un'applicazione di questo tipo, ci sono alcuni aspetti da considerare:
Isolamento del tenant: gli sviluppatori di applicazioni devono adottare misure appropriate per assicurarsi che nessun tenant non autorizzato o indesiderato acceda ai dati di altri tenant. Oltre alla questione della privacy dei dati, le strategie di isolamento tenant richiedono una gestione efficace delle risorse condivise e la protezione da vicini fastidiosi.
Costi delle risorse del cloud: come con qualsiasi altra applicazione, le soluzioni software devono rimanere competitive quando sono componenti di un'applicazione multi-tenant.
Semplicità delle operazioni: quando si sviluppa un'architettura multi-tenant, l'impatto sulle operazioni e la complessità dell'applicazione è un fattore importante. Ricerca di intelligenza artificiale di Azure ha un contratto di servizio del 99,9%.
Footprint globale: le applicazioni multi-tenant devono spesso servire i tenant distribuiti in tutto il mondo.
Scalabilità: gli sviluppatori di applicazioni devono mantenere le applicazioni a un livello di complessità sufficientemente ridotto e allo stesso tempo progettarle in maniera che siano scalabili in base al numero di tenant e alla dimensione dei dati e del carico di lavoro dei tenant.
Ricerca di intelligenza artificiale di Azure offre alcuni limiti che possono essere usati per isolare i dati e il carico di lavoro dei tenant.
Modellazione di più tenancy con Ricerca di intelligenza artificiale di Azure
Nel caso di uno scenario multi-tenant, lo sviluppatore di applicazioni usa uno o più servizi di ricerca e divide i tenant tra servizi, indici o entrambi. Ricerca di intelligenza artificiale di Azure presenta alcuni modelli comuni durante la modellazione di uno scenario multi-tenant:
Un indice per tenant: ogni tenant ha un proprio indice all'interno di un servizio di ricerca condiviso con altri tenant.
Un servizio per tenant: ogni tenant ha un proprio servizio di ricerca di intelligenza artificiale di Azure dedicato, offrendo il massimo livello di separazione dei dati e dei carichi di lavoro.
Combinazione di entrambi: ai tenant più grandi e attivi vengono assegnati servizi dedicati mentre ai tenant più piccoli vengono assegnati singoli indici all'interno di servizi condivisi.
Modello 1: un indice per tenant
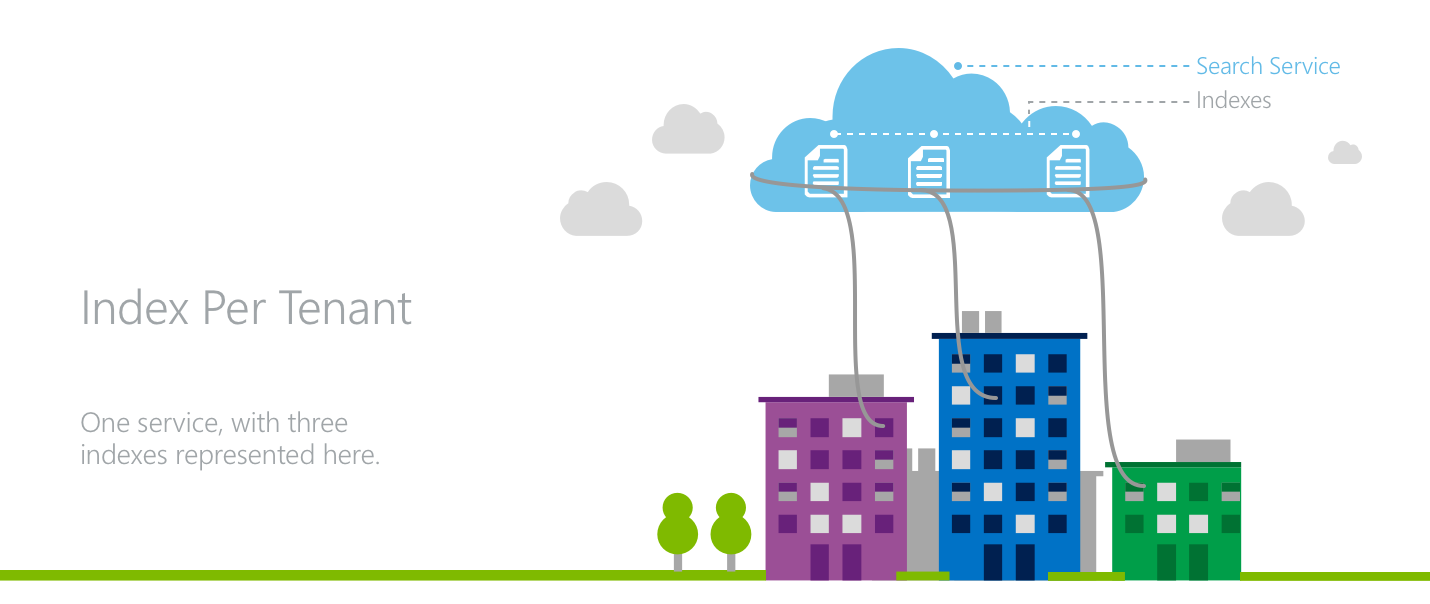
In un modello di indice per tenant, più tenant occupano un singolo servizio di ricerca di intelligenza artificiale di Azure in cui ogni tenant ha un proprio indice.
I tenant ottengono l'isolamento dei dati perché tutte le richieste di ricerca e le operazioni sui documenti vengono eseguite a livello di indice in Ricerca di intelligenza artificiale di Azure. Nel livello dell'applicazione esiste la necessità di indirizzare il traffico dei vari tenant agli indici appropriati, gestendo al tempo stesso le risorse a livello di servizio in tutti i tenant.
Una caratteristica importante del modello "indice per tenant" è la possibilità per lo sviluppatore di applicazioni di eseguire l'oversubscription della capacità di un servizio di ricerca tra i tenant dell'applicazione. Se la distribuzione del carico di lavoro fra i tenant non è uniforme, è possibile distribuire una combinazione ottimale di tenant tra gli indici di un servizio di ricerca in modo da sistemare un certo numero di tenant molto attivi e che richiedono molte risorse, servendo al tempo stesso una lunga coda di tenant meno attivi. Lo svantaggio del modello è la sua incapacità di gestire le situazioni in cui tutti i tenant sono simultaneamente molto attivi.
Il modello index-per-tenant fornisce la base per un modello di costo variabile, in cui un intero servizio di ricerca di intelligenza artificiale di Azure viene acquistato in anticipo e quindi riempito con tenant. In questo modo la capacità inutilizzata può essere destinata ad account di prova e gratuiti.
Per le applicazioni con footprint globale, il modello index-per-tenant potrebbe non essere il più efficiente. Se i tenant di un'applicazione vengono distribuiti in tutto il mondo, un servizio separato può essere necessario per ogni area, duplicando i costi in ognuno di essi.
Ricerca di intelligenza artificiale di Azure consente di aumentare sia la scalabilità dei singoli indici che il numero totale di indici. Se viene scelto un piano tariffario appropriato, possono essere aggiunte partizioni e repliche all'intero servizio di ricerca quando un singolo indice all'interno del servizio diventa troppo grande in termini di archiviazione o traffico.
Se il numero totale di indici diventa troppo grande per un singolo servizio, è necessario eseguire il provisioning di un altro servizio per accogliere i nuovi tenant. Se gli indici devono essere spostati tra i servizi di ricerca man mano che vengono aggiunti nuovi servizi, i dati dell'indice devono essere copiati manualmente da un indice all'altro perché Ricerca di intelligenza artificiale di Azure non consente lo spostamento di un indice.
Modello 2: un servizio per tenant

In un'architettura "servizio per tenant" ogni tenant dispone di un proprio servizio di ricerca.
In questo modello l'applicazione ottiene il massimo livello di isolamento per i suoi tenant. Ogni servizio ha risorse di archiviazione e velocità effettiva dedicate per la gestione delle richieste di ricerca. Ogni tenant ha la proprietà individuale delle chiavi API.
Per le applicazioni in cui ogni tenant ha un footprint elevato o il carico di lavoro ha poca variabilità dal tenant al tenant, il modello di servizio per tenant è una scelta efficace perché le risorse non vengono condivise tra i vari carichi di lavoro dei tenant.
Un modello "servizio per tenant" offre inoltre il vantaggio della stimabilità dei costi fissi. Non è previsto alcun investimento iniziale in un intero servizio di ricerca fino a quando non è disponibile un tenant per riempirlo, ma il costo per tenant è superiore a un modello index-per-tenant.
Il modello "servizio per tenant" è una scelta efficiente per le applicazioni con una presenza globale. Con i tenant distribuiti geograficamente, è facile avere il servizio di ogni tenant nell'area appropriata.
Problematiche di scalabilità di questo modello si verificano quando i singoli tenant diventano troppo grandi per il servizio. Ricerca di intelligenza artificiale di Azure attualmente non supporta l'aggiornamento del piano tariffario di un servizio di ricerca, quindi tutti i dati devono essere copiati manualmente in un nuovo servizio.
Modello 3: Ibrido
Un'altra possibilità per la modellazione multi-tenancy consiste nell'unione delle due strategie "indice per tenant" e "servizio per tenant".
Combinando i due modelli, i tenant più grandi di un'applicazione possono occupare servizi dedicati mentre la lunga coda di tenant più piccoli e meno attivi può occupare gli indici in un servizio condiviso. Questo modello garantisce ai tenant più grandi di ottenere prestazioni elevate e coerenti dal servizio, contribuendo al tempo stesso a proteggere i tenant più piccoli da eventuali vicini fastidiosi.
Tuttavia, l'implementazione di questa strategia si basa su foresight per prevedere quali tenant richiederanno un servizio dedicato rispetto a un indice in un servizio condiviso. La complessità dell'applicazione aumenta con la necessità di gestire entrambi questi modelli multi-tenancy.
Raggiungimento di una granularità ancora maggiore
I modelli di progettazione precedenti per modellare scenari multi-tenant in Ricerca di intelligenza artificiale di Azure presuppongono un ambito uniforme in cui ogni tenant è un'intera istanza di un'applicazione. Le applicazioni tuttavia possono gestire a volte numerosi ambiti più piccoli.
Se i modelli service-per-tenant e index-per-tenant non sono sufficientemente piccoli, è possibile modellare un indice per ottenere un livello di granularità ancora più fine.
Per fare in modo che un singolo indice si comporti in modo diverso per endpoint client diversi, è possibile aggiungere un campo a un indice, che definisce un determinato valore per ogni client possibile. Ogni volta che un client chiama Ricerca di intelligenza artificiale di Azure per eseguire query o modificare un indice, il codice dell'applicazione client specifica il valore appropriato per tale campo usando la funzionalità di filtro di Ricerca di intelligenza artificiale di Azure in fase di query.
Questo metodo può essere usato per ottenere funzionalità di account utente diversi, livelli di autorizzazione diversi e persino applicazioni completamente diverse.
Nota
L'uso dell'approccio descritto sopra per configurare un singolo indice per più tenant influisce sulla pertinenza dei risultati della ricerca. I punteggi di pertinenza della ricerca vengono calcolati a livello di indice, non a livello di tenant, quindi tutti i dati dei tenant vengono incorporati nelle statistiche dei punteggi di pertinenza, ad esempio la frequenza del termine.
Passaggi successivi
Ricerca di intelligenza artificiale di Azure è una scelta interessante per molte applicazioni. Quando si valutano i vari modelli di progettazione per le applicazioni multi-tenant, prendere in considerazione i vari piani tariffari e i rispettivi limiti del servizio per adattare al meglio Ricerca di intelligenza artificiale di Azure per adattare i carichi di lavoro e le architetture delle applicazioni di tutte le dimensioni.