Pianificazione della capacità per le applicazioni Service Fabric
Questo documento illustra come stimare la quantità di risorse (CPU, RAM e spazio di archiviazione su disco) necessaria per eseguire le applicazioni di Azure Service Fabric. I requisiti delle risorse tendono a cambiare nel tempo. In genere sono necessarie poche risorse durante lo sviluppo e il test del servizio e un numero maggiore nella fase di produzione e di aumento della popolarità dell'applicazione. Quando si progetta un'applicazione, occorre prendere in considerazione i requisiti di lungo termine e adottare subito i provvedimenti necessari affinché il servizio possa essere ridimensionato per soddisfare le richieste elevate dei clienti.
Quando si crea un cluster di Service Fabric si definiscono i tipi di macchine virtuali (VM) che costituiscono il cluster. Ogni VM è dotata di una quantità limitata di risorse sotto forma di CPU (core e velocità), larghezza di banda di rete, RAM e spazio di archiviazione su disco. Con la crescita del servizio nel tempo, è possibile aggiornare le VM affinché offrano un numero maggiore di risorse e/o aggiungere VM al cluster. Per farlo è necessario progettare il servizio in modo che possa sfruttare i vantaggi offerti dall'aggiunta di nuove VM al cluster in modo dinamico.
Alcuni servizi gestiscono pochi dati o addirittura nessun dato nelle VM. La pianificazione della capacità per questi servizi deve pertanto riguardare principalmente le prestazioni, ovvero è necessario scegliere le CPU appropriate (memorie centrali e velocità) per le VM. È consigliabile valutare anche la larghezza di banda della rete, compresa la frequenza con cui si verificano trasferimenti di rete nonché la quantità dei dati trasferiti. Se il servizio deve mantenere un buon livello di prestazioni con l'aumento dell'utilizzo, è possibile aggiungere altre VM al cluster e bilanciare il carico delle richieste di rete in tutte le VM.
Per i servizi che gestiscono una grande quantità di dati nelle VM la pianificazione della capacità deve concentrarsi soprattutto sulla dimensione. È necessario pertanto valutare attentamente la capacità della RAM e dello spazio di archiviazione su disco della VM. Per il codice dell'applicazione il sistema di gestione della memoria virtuale di Windows rende lo spazio di archiviazione su disco analogo alla RAM. Inoltre il runtime di Service Fabric fornisce il paging intelligente mantenendo in memoria solo i dati attivi e spostando sul disco i dati inattivi. Le applicazioni possono così usare più memoria di quella fisicamente disponibile nella VM. Una maggiore disponibilità di RAM consente di aumentare le prestazioni, in quanto la VM può sfruttare più spazio di archiviazione su disco nella RAM. La VM selezionata deve disporre di un disco sufficiente per archiviare i dati desiderati nella VM. Allo stesso modo la VM deve disporre di RAM sufficiente per fornire le prestazioni desiderate. Se i dati del servizio aumentano nel tempo, è possibile aggiungere altre VM al cluster e partizionare i dati in tutte le VM.
Determinare il numero di nodi necessari
Il servizio di partizionamento consente di aumentare i dati del servizio. Per altre informazioni sul partizionamento, vedere l'articolo sul partizionamento di Service Fabric. Ogni partizione deve essere contenuta in una singola VM, ma è possibile posizionare più partizioni (di piccole dimensioni) in una singola VM. La presenza di un maggior numero di partizioni piccole offre maggiore flessibilità rispetto alla presenza di poche partizioni grandi. Lo svantaggio è rappresentato dal fatto che la presenza di numerose partizioni aumenta il sovraccarico di Service Fabric impedendo l'esecuzione di operazioni transazionali tra le partizioni. È inoltre disponibile un maggiore traffico di rete potenziale, se il codice del servizio deve accedere spesso a porzioni di dati che si trovano in partizioni diverse. Quando si progetta il servizio, è opportuno valutare attentamente questi vantaggi e svantaggi per adottare un'efficace strategia di partizionamento.
Si supponga che l'applicazione abbia un singolo servizio con stato con una dimensione di archiviazione che si prevede raggiunga i GB della dimensione del database in un anno. Si è disposti ad aggiungere altre applicazioni e partizioni, man mano che le dimensioni aumenteranno dopo tale anno. Il fattore di replica, che determina il numero di repliche per il servizio, influisce sul DB_Size totale. Il DB_Size totale in tutte le repliche è il fattore di replica moltiplicato per DB_Size. Node_Size rappresenta lo spazio di archiviazione su disco o RAM per ogni nodo che si vuole usare per il servizio. Per prestazioni ottimali il valore DB_Size deve essere contenuto nella memoria in tutto il cluster ed è necessario scegliere un Node_Size simile alla RAM della VM. Impostare un Node_Size maggiore della capacità di RAM, significa fare affidamento sul paging fornito dal runtime di Service Fabric. Di conseguenza le prestazioni potrebbero non essere ottimali se tutti i dati vengono considerati attivi (perché in questro caso verrebbe eseguito un paging dei dati in/out). È però più conveniente per molti servizi in cui solo una frazione dei dati è attiva.
Il numero di nodi necessari per ottenere le massime prestazioni può essere calcolato come segue:
Number of Nodes = (DB_Size * RF)/Node_Size
Account per l'espansione
Si consiglia di calcolare il numero dei nodi in base al DB_Size che si prevede di raggiungere e al DB_Size da cui si parte. Aumentare quindi il numero di nodi man mano che il servizio cresce, in modo da evitare l'overprovisioning del numero di nodi. Il numero di partizioni si deve tuttavia basare sul numero di nodi necessari quando si esegue il servizio al livello massimo di espansione.
È buona norma disporre di alcune macchine aggiuntive in ogni momento, in modo da poter gestire eventuali picchi imprevisti o errori (ad esempio se alcune VM subiscono un arresto anomalo). La capacità extra deve essere determinata sulla base dei picchi previsti, ma un buon punto di partenza è riservare alcune VM aggiuntive (5-10%).
Quanto detto sopra presuppone l'esistenza di un singolo servizio con stato. Se si dispone di più di un servizio con stato, è necessario aggiungere all'equazione i DB_Size associati con gli altri servizi. In alternativa è possibile calcolare il numero di nodi separatamente per ogni servizio con stato. Il servizio può includere repliche o partizioni non bilanciate. Si tenga presente che alcune partizioni potrebbero includere più dati di altre. Per altre informazioni sul partizionamento, vedere l' articolo sulle procedure consigliate relative al partizionamento. L'equazione sopra non tiene conto tuttavia delle partizioni e delle repliche, poiché Service Fabric garantisce che le repliche siano distribuite tra i nodi in modalità ottimizzata.
Usare un foglio di calcolo per il calcolo dei costi
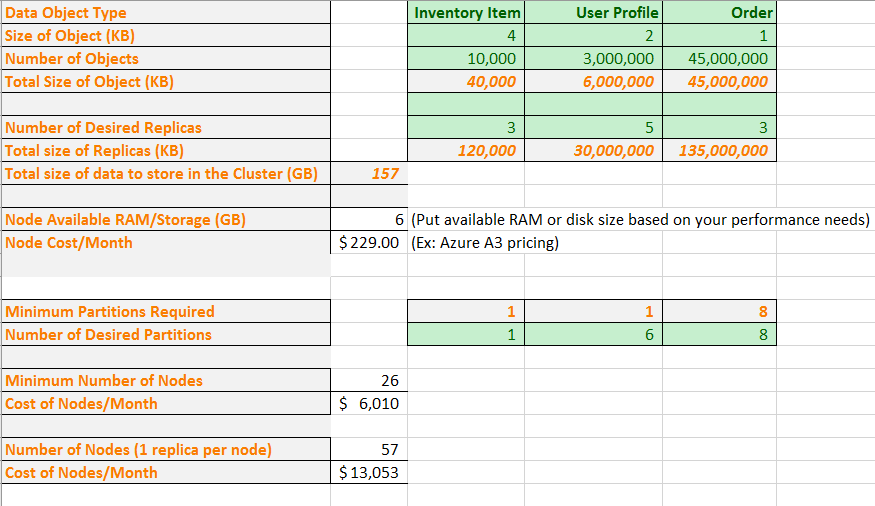
È ora opportuno inserire alcuni dati reali nella formula. Un foglio di calcolo di esempio illustra come pianificare la capacità di un'applicazione contenente tre tipi di oggetti dati. Per ogni oggetto sono stati definiti in modo approssimativo la dimensione e il numero di oggetti che dovrebbe contenere. Viene anche definito il numero di repliche per ogni tipo di oggetto. Il foglio di calcolo consente di calcolare la quantità totale di memoria da archiviare nel cluster.
Viene quindi immessa una dimensione di VM e il costo mensile. In base alla dimensione della VM, il foglio di calcolo indica il numero minimo di partizioni da usare per suddividere i dati affinché possano fisicamente adattarsi ai nodi. È possibile che si desideri un numero maggiore di partizioni per soddisfare le esigenze di calcolo specifiche dell'applicazione e del traffico di rete. Il foglio di calcolo illustra che il numero di partizioni che gestiscono gli oggetti del profilo utente è aumentato da 1 a 6.
A questo punto, in base a tali informazioni, il foglio di calcolo mostra che è possibile contenere tutti i dati con le partizioni e le repliche desiderate in un cluster a 26 nodi. Tale cluster risulta tuttavia compresso e possono essere necessari alcuni nodi aggiuntivi per gestire gli aggiornamenti e gli errori del nodo. Il foglio di calcolo mostra inoltre che la disponibilità di più di 57 nodi non offre alcun valore aggiuntivo in quanto alcuni nodi possono rimanere vuoti. Anche in questo caso, può essere comunque necessario superare i 57 nodi per gestire gli aggiornamenti e gli errori del nodo. È possibile apportare modifiche al foglio di calcolo in modo che corrisponda alle esigenze specifiche dell'applicazione.
Passaggi successivi
Per altre informazioni sul partizionamento del servizio, consultare Partizionamento dei servizi di Service Fabric.