Scalabilità in Service Fabric
Azure Service Fabric semplifica la creazione di applicazioni scalabili gestendo i servizi, le partizioni e le repliche nei nodi di un cluster. L'esecuzione di molti carichi di lavoro sullo stesso hardware determina il massimo utilizzo delle risorse, ma offre anche la flessibilità in termini di scelta di come scalare i carichi di lavoro. Questo video di Channel 9 descrive come compilare applicazioni di microservizi scalabili:
Esistono vari modi per impostare la scalabilità in Service Fabric:
- Implementazione della scalabilità tramite creazione o rimozione di istanze del servizio senza stato
- Implementazione della scalabilità tramite creazione o rimozione di nuovi servizi denominati
- Implementazione della scalabilità tramite creazione o rimozione di nuove istanze dell'applicazione denominate
- Implementazione della scalabilità tramite utilizzo di servizi partizionati
- Implementazione della scalabilità tramite aggiunta e rimozione di nodi dal cluster
- Implementazione della scalabilità tramite metriche di Gestione risorse cluster
Implementazione della scalabilità tramite creazione o rimozione di istanze del servizio senza stato
Uno dei modi più semplici per scalare all'interno di Service Fabric usa i servizi senza stato. Quando si crea un servizio senza stato, è possibile definire un oggetto InstanceCount. L'oggetto InstanceCount definisce il numero di copie in esecuzione del codice del servizio che viene creato all'avvio del servizio. Si supponga, ad esempio, che il cluster contenga 100 nodi. Si supponga anche che venga creato un servizio con un oggetto InstanceCount impostato su 10. Durante il runtime, queste 10 copie in esecuzione del codice potrebbero diventare tutte troppo occupate oppure non esserlo a sufficienza. Un modo per scalare il carico di lavoro consiste nel modificare il numero di istanze. Alcuni frammenti di codice di monitoraggio o di gestione potrebbero, ad esempio, modificare il numero esistente di istanze in 50, o in 5, a seconda che il carico di lavoro debba essere scalato orizzontale o verticalmente in base al carico.
C#:
StatelessServiceUpdateDescription updateDescription = new StatelessServiceUpdateDescription();
updateDescription.InstanceCount = 50;
await fabricClient.ServiceManager.UpdateServiceAsync(new Uri("fabric:/app/service"), updateDescription);
PowerShell:
Update-ServiceFabricService -Stateless -ServiceName $serviceName -InstanceCount 50
Utilizzo del numero delle istanze dinamico
In particolare per i servizi senza stato, Service Fabric offre un modo automatico per modificare il numero delle istanze. Il servizio può così scalare dinamicamente con il numero di nodi disponibili. Per applicare questo comportamento, si imposta il numero delle istanze su -1. InstanceCount = -1 è un'istruzione di Service Fabric che indica che "Eseguire questo servizio senza stato in ogni nodo". Se il numero di nodi cambia, Service Fabric modifica automaticamente il numero di istanze in modo che corrisponda, assicurandosi che il servizio sia in esecuzione in tutti i nodi validi.
C#:
StatelessServiceDescription serviceDescription = new StatelessServiceDescription();
//Set other service properties necessary for creation....
serviceDescription.InstanceCount = -1;
await fc.ServiceManager.CreateServiceAsync(serviceDescription);
PowerShell:
New-ServiceFabricService -ApplicationName $applicationName -ServiceName $serviceName -ServiceTypeName $serviceTypeName -Stateless -PartitionSchemeSingleton -InstanceCount "-1"
Implementazione della scalabilità tramite creazione o rimozione di nuovi servizi denominati
Un'istanza del servizio denominata è un'istanza specifica di un tipo di servizio (vedere l'articolo Ciclo di vita dell'applicazione Service Fabric) all'interno di un'istanza dell'applicazione denominata nel cluster.
È possibile creare o rimuovere nuove istanze del servizio denominate man mano che aumenta o diminuisce l'utilizzo dei servizi. In questo modo le richieste possono essere distribuite tra più istanze del servizio, con conseguente riduzione del carico sui servizi esistenti. Quando si creano i servizi, Gestione risorse cluster di Service Fabric li inserisce nel cluster secondo una modalità distribuita. Le decisioni precise vengono gestite dalle metriche nel cluster e da altre regole di posizionamento. Esistono vari modi per creare i servizi, ma i più comuni prevedono azioni amministrative, ad esempio un utente che chiama l'oggetto New-ServiceFabricService o la chiamata di codice CreateServiceAsync. L'oggetto CreateServiceAsync può persino essere chiamato all'interno di altri servizi in esecuzione nel cluster.
La creazione dinamica dei servizi può essere usata in tutti i tipi di scenari ed è un criterio di uso comune. Si consideri ad esempio un servizio con stato che rappresenta uno specifico flusso di lavoro. Le chiamate che rappresentano il lavoro vengono presentate al servizio e questo esegue i passaggi per tale flusso di lavoro e ne registra lo stato.
In che modo si potrebbe scalare questo servizio specifico? Il servizio potrebbe essere multi-tenant in qualche forma e accettare le chiamate nonché avviare i passaggi per varie istanze dello stesso flusso di lavoro in una sola volta. Con questa soluzione, tuttavia, il codice diventa più complesso, poiché ora deve occuparsi di molte istanze diverse dello stesso flusso di lavoro, tutte in fasi diverse e derivanti da clienti diversi. La gestione di più flussi di lavoro alla volta, inoltre, non risolve il problema della scalabilità. Il servizio arriverà infatti ad un certo punto in cui consumerà troppe risorse per un computer specifico. Molti servizi che non sono creati fin dall'inizio con questo criterio sono inoltre soggetti a problemi legati ad alcuni colli di bottiglia intrinseci o a rallentamento del codice. Questi tipi di problemi impediscono anche la corretta esecuzione del servizio quando il numero dei flussi di lavoro simultanei controllati dal servizio aumenta.
Una soluzione consiste nel creare un'istanza di questo servizio per ogni istanza diversa del flusso di lavoro che si vuole tenere traccia. Si tratta di un modello ottimale e funziona se il servizio è senza stato o con stato. Perché questo criterio funzioni, di solito è presente un altro servizio che agisce da "servizio gestione dei carichi di lavoro". Il compito di questo servizio è ricevere le richieste e indirizzarle ad altri servizi. Il servizio gestione può creare dinamicamente un'istanza del servizio del carico di lavoro quando riceve il messaggio e successivamente passare le richieste al servizio. Il servizio gestione può anche ricevere i callback quando un determinato servizio del flusso di lavoro completa il processo. Quando il servizio gestione riceve questi callback, può eliminare l'istanza del servizio del flusso di lavoro o conservarla se prevede altre chiamate.
Nelle sue versioni avanzate, questo tipo di servizio gestione può addirittura creare pool dei servizi che gestisce. Il pool aiuta ad assicurare che una nuova richiesta in arrivo non debba attendere l'avvio da parte del servizio. Il servizio gestione, invece, può semplicemente selezionare un servizio del flusso di lavoro che non è attualmente occupato dal pool o instradare in modo casuale. La disponibilità continua di un pool di servizi velocizza la gestione di nuove richieste, in quanto si riducono le probabilità che la richiesta debba attendere l'avvio di un nuovo servizio. La creazione di nuovi servizi è rapida, ma non è libera o immediata. Il pool aiuta a ridurre al minimo la quantità di tempo che la richiesta deve attendere prima di essere elaborata dal servizio. Questo modello basato sul servizio gestione e sul pool viene usato spesso quando i tempi di risposta sono un aspetto molto importante. L'accodamento della richiesta e la creazione del servizio in background e quindi il relativo passaggio rappresentano un altro criterio di gestione di uso comune, come pure la creazione e l'eliminazione di servizi basati su alcune verifiche della quantità di lavoro che il servizio ha attualmente in sospeso.
Implementazione della scalabilità tramite creazione o rimozione di nuove istanze dell'applicazione denominate
La creazione e l'eliminazione di intere istanze dell'applicazione è simile al criterio di creazione ed eliminazione di servizi. Questo criterio si basa sull'esistenza di un servizio gestione che prende le decisioni in base alle richieste che vede e alle informazioni che riceve dagli altri servizi nel cluster.
Quando è preferibile usare la creazione di una nuova istanza dell'applicazione denominata al posto della creazione di una nuova istanza del servizio denominata in un'applicazione già esistente? Esistono alcuni casi in cui questa soluzione è preferibile:
- La nuova istanza dell'applicazione è adatta a un cliente che necessita che il codice venga eseguito con alcune specifiche impostazioni di sicurezza e di identità.
- Service Fabric consente di definire pacchetti di codice diversi da eseguire con identità specifiche. Per avviare lo stesso pacchetto di codice con identità diverse, è necessario che le attivazioni si verifichino in istanze dell'applicazione diverse. Si consideri il caso in cui sono presenti carichi di lavoro distribuiti di un cliente esistente. È possibile eseguire questi carichi con un'identità specifica in modo da poterne monitorare e controllare l'accesso ad altre risorse, ad esempio database remoti o altri sistemi. In questo caso, quando un nuovo cliente si iscrive, è probabile che non si desideri attivare il codice nello stesso contesto (spazio del processo). Sebbene possibile, questo rende più difficile al codice operare all'interno del contesto di una specifica identità. È necessario in genere disporre di ulteriore codice per la gestione della sicurezza, dell'isolamento e delle identità. Invece di usare istanze del servizio denominate diverse nella stessa istanza dell'applicazione e pertanto nello stesso spazio di processo, è possibile usare istanze dell'applicazione Service Fabric denominate diverse. In questo modo diventa più semplice definire contesti di identità diversi.
- La nuova istanza dell'applicazione funge da mezzo di configurazione
- Per impostazione predefinita, tutte le istanze del servizio denominate di un tipo di servizio specifico all'interno di un'istanza dell'applicazione vengono eseguite nello stesso processo in un determinato nodo. Ciò significa che, sebbene sia possibile configurare ogni istanza del servizio in modo diverso, si tratta di un approccio complicato. I servizi devono disporre di un token da usare per cercare la propria configurazione all'interno di un pacchetto di configurazioni. Il token è in genere semplicemente il nome del servizio. Questo approccio va bene, ma associa la configurazione ai nomi delle singole istanze del servizio denominate all'interno di tale istanza dell'applicazione. Questa situazione può generare confusione e risultare difficile da gestire perché la configurazione è normalmente un artefatto della fase di progettazione con valori specifici dell'istanza dell'applicazione. La creazione di più servizi prevede sempre vari aggiornamenti dell'applicazione per modificare le informazioni all'interno dei pacchetti di configurazione o per distribuirne di nuovi, in modo che i nuovi servizi possano cercare le informazioni specifiche che li riguardano. È spesso più facile creare un'istanza dell'applicazione denominata completamente nuova e quindi usare i parametri dell'applicazione per impostare la configurazione necessaria per i servizi. In questo modo tutti i servizi che vengono creati all'interno dell'istanza dell'applicazione denominata possono ereditare le impostazioni della configurazione specifica. Invece di avere, ad esempio, un unico file di configurazione con le impostazioni e le personalizzazioni per ogni cliente, ad esempio segreti o limiti di risorse per cliente, si dispone di un'istanza dell'applicazione diversa per ogni cliente in cui queste impostazioni sono ignorate.
- La nuova applicazione funge da limite per l'aggiornamento
- All'interno di Service Fabric le diverse istanze dell'applicazione denominate fungono da limiti per l'aggiornamento. Un aggiornamento di un'istanza dell'applicazione denominata non influirà sul codice in esecuzione in un'altra istanza dell'applicazione denominata. Le diverse applicazioni finiranno con l'eseguire versioni diverse dello stesso codice negli stessi nodi. Questo può essere un fattore da considerare quando occorre prendere una decisione sull'implementazione della scalabilità perché è possibile scegliere se il nuovo codice deve seguire o meno gli stessi aggiornamenti di un altro servizio. Si supponga, ad esempio, che arrivi una chiamata al servizio gestione che deve scalare i carichi di lavoro di un determinato cliente tramite la creazione e l'eliminazione dinamiche dei servizi. In questo caso, tuttavia, la chiamata riguarda un carico di lavoro associato a un nuovo cliente. La maggior parte dei clienti preferisce essere isolata dagli altri clienti non solo per i motivi di sicurezza e di configurazione spiegati in precedenza, ma perché l'isolamento offre maggiore flessibilità in termini di esecuzione di versioni specifiche del software e di scelta del periodo ideale per l'aggiornamento. È anche possibile creare una nuova istanza dell'applicazione e crearvi il servizio semplicemente per partizionare ulteriormente la quantità di servizi che saranno interessati da ogni aggiornamento. L'uso di istanze dell'applicazione separate offre maggiore granularità quando si eseguono gli aggiornamenti dell'applicazione e consente di usare i test A/B e le distribuzioni Blue/Green.
- L'istanza dell'applicazione esistente è completa
- In Service Fabric la capacità dell'applicazione è un concetto che può essere usato per controllare la quantità di risorse disponibili per istanze dell'applicazione specifiche. Si può ad esempio decidere che, per scalare un determinato servizio, si debba creare un'altra istanza. Questa istanza dell'applicazione è tuttavia fuori dalla capacità di una determinata metrica. Se a questo cliente o carico di lavoro specifico devono essere concesse ancora altre risorse, è possibile aumentare la capacità esistente per l'applicazione o creare una nuova applicazione.
Implementazione della scalabilità a livello di partizione
Service Fabric supporta il partizionamento. Il partizionamento suddivide un servizio in più sezioni logiche e fisiche, ognuna delle quali opera in modo indipendente. Ciò è utile con i servizi con stato, poiché nessun set di repliche deve gestire tutte le chiamate e manipolare tutto lo stato in una sola volta. L'articolo relativo alla panoramica del partizionamento include informazioni relative ai tipi di schemi di partizionamento supportati. Le repliche di ogni partizione vengono distribuite tra i nodi in un cluster, distribuendo così il carico del servizio e assicurando che né il servizio nel suo complesso né le partizioni includano un singolo punto di errore.
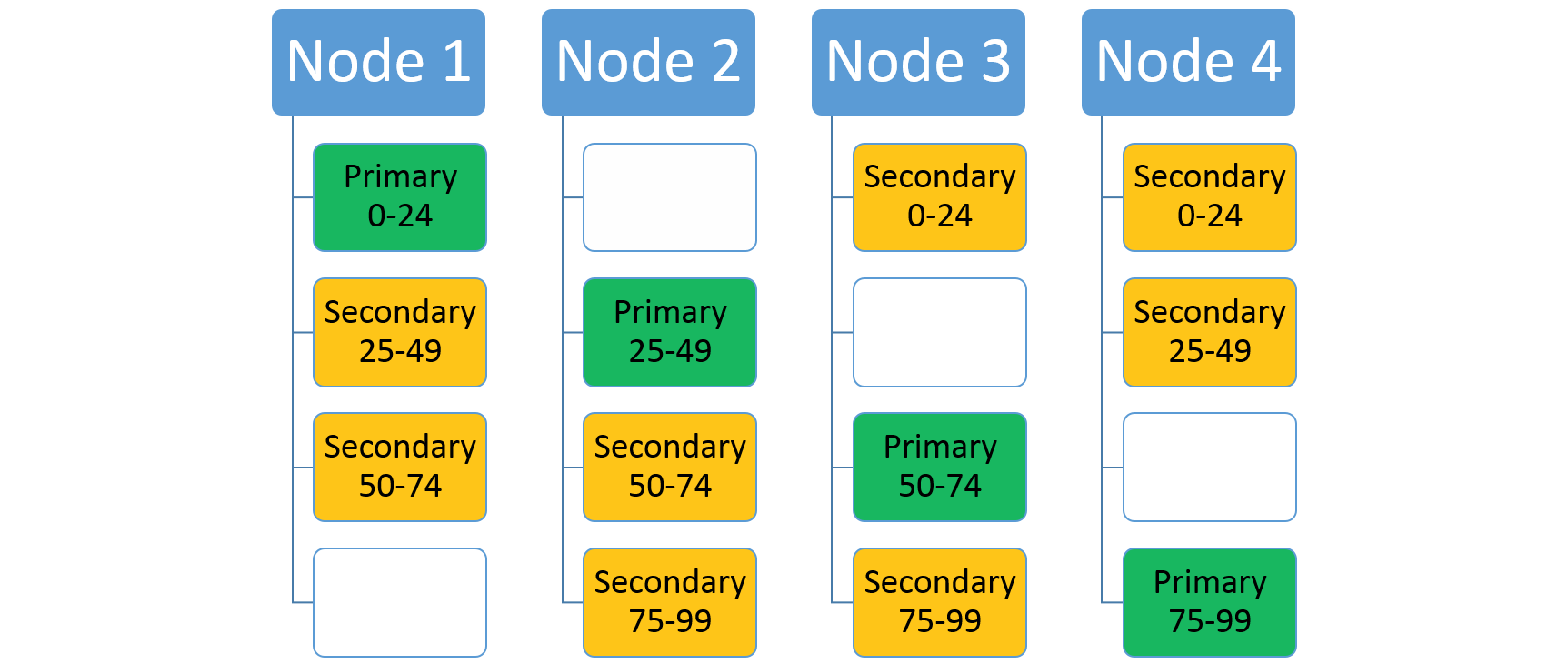
Si consideri un servizio che usa lo schema di partizionamento con intervallo con una chiave inferiore uguale a 0, una chiave superiore uguale a 99 e quattro partizioni. In un cluster a tre nodi il servizio potrebbe avere un layout con quattro repliche che condividono le risorse in ogni nodo, come illustrato di seguito:

Se si aumenta il numero dei nodi, Service Fabric sposta nei nuovi nodi alcune delle repliche esistenti. Si supponga, ad esempio, che il numero di nodi aumenti a quattro e che le repliche vengano ridistribuite. Il servizio dispone a questo punto di tre repliche in esecuzione in ogni nodo, ognuna appartenente a partizioni diverse. Si ottiene così un utilizzo ottimale delle risorse in quanto il nuovo nodo non è ad accesso sporadico. Si ottiene di solito anche un miglioramento delle prestazioni poiché ogni servizio dispone di più risorse.
Implementazione della scalabilità tramite l'utilizzo di Gestione risorse cluster di Service Fabric e di metriche
Le metriche indicano il modo in cui i servizi esprimono il consumo di risorse a Service Fabric. L'uso delle metriche offre a Gestione risorse cluster la possibilità di riorganizzare e ottimizzare il layout del cluster. Nel cluster potrebbero, ad esempio, essere presenti molte risorse, ma non essere allocate ai servizi che svolgono attualmente il lavoro. L'utilizzo delle metriche consente a Gestione risorse cluster di riorganizzare il cluster in modo da garantire che i servizi abbiano accesso alle risorse disponibili.
Implementazione della scalabilità tramite aggiunta e rimozione di nodi dal cluster
Un'altra opzione per la scalabilità con Service Fabric consiste nel modificare le dimensioni del cluster. Modificare le dimensioni del cluster significa aggiungere o rimuovere nodi per uno o più tipi di nodo nel cluster. Si consideri, ad esempio, il caso in cui tutti i nodi del cluster sono attivi. Le risorse del cluster sono quindi quasi tutte usate. In questo caso, aggiungere altri nodi al cluster è il modo migliore per applicare la scalabilità. Dopo che i nuovi nodi sono stati aggiunti al cluster, Gestione risorse cluster di Service Fabric sposta alcuni servizi nei nuovi nodi, riducendo il carico totale sui nodi esistenti. Per i servizi senza stato con numero di istanze = -1, vengono create automaticamente più istanze del servizio. Alcune chiamate possono così spostarsi dai nodi esistenti a quelli nuovi.
Per altre informazioni, vedere Ridimensionamento dei cluster.
Scelta di una piattaforma
A causa delle differenze di implementazione tra sistemi operativi, la scelta di usare Service Fabric con Windows o Linux può essere una parte essenziale del ridimensionamento dell'applicazione. Una potenziale barriera è la modalità di esecuzione della registrazione a fasi. Service Fabric in Windows usa un driver kernel per un log di un computer, condiviso tra le repliche del servizio con stato. Questo log pesa a circa 8 GB. Linux, d'altra parte, usa un log di staging di 256 MB per ogni replica, rendendolo meno ideale per le applicazioni che vogliono ottimizzare il numero di repliche di servizi leggere in esecuzione in un determinato nodo. Queste differenze nei requisiti di archiviazione temporanea potrebbero potenzialmente informare la piattaforma desiderata per la distribuzione del cluster di Service Fabric.
Riassumendo
Si prendano ora tutti i concetti discussi qui e li si applichi a un esempio. Si consideri l'esempio seguente: si intende creare un servizio di rubrica, contenente nomi e informazioni sui contatti.
Emergono subito alcune domande in merito alla scalabilità: quanti utenti useranno il servizio? Quanti contatti archivierà ogni singolo utente? È difficile stabilire subito questi aspetti durante la creazione del servizio. Si supponga di voler iniziare con un unico servizio statico con un numero di partizioni specifico. Scegliere la partizione sbagliata potrebbe portare a problemi di scalabilità futuri. Allo stesso modo, anche se si seleziona il numero corretto, si potrebbe non disporre di tutte le informazioni necessarie. È, ad esempio, necessario decidere in anticipo anche le dimensioni del cluster, sia in termini di numero di nodi che di dimensioni. È in genere difficile prevedere il numero di risorse che un servizio userà nell'arco della sua esistenza. Può inoltre essere difficile sapere a priori il modello di traffico che il servizio vedrà effettivamente. Gli utenti potrebbero, ad esempio, aggiungere e rimuovere i propri contatti come prima cosa al mattino oppure il traffico potrebbe essere distribuito uniformemente nell'arco della giornata. In base al tipo di traffico potrebbe essere necessario aumentare e ridurre le risorse in modo dinamico. Si può forse imparare a prevedere quando sarà necessario aumentare o ridurre, ma in ogni caso sarà probabilmente necessario adottare una soluzione a seconda dei cambiamenti nel consumo di risorse da parte del servizio. Ciò può richiedere la modifica delle dimensioni del cluster per offrire ulteriori risorse quando la riorganizzazione dell'utilizzo delle risorse esistenti non è sufficiente.
Perché mai scegliere uno schema a partizione singola per tutti gli utenti? Perché limitarsi a un servizio e a un cluster statico? La situazione reale è di solito più dinamica.
Quando si compila per scalare, considerare il modello dinamico seguente. Potrebbe essere necessario adattarlo alla propria situazione:
- Invece di tentare di selezionare in anticipo uno schema di partizionamento per tutti gli utenti, creare un "servizio gestione".
- Il compito del servizio gestione è analizzare le informazioni del cliente quando quest'ultimo si iscrive al servizio. A seconda di queste informazioni, il servizio di gestione crea quindi un'istanza del servizio di archiviazione dei contatti effettivosolo per il cliente. Se il cliente richiede una configurazione, un isolamento o aggiornamenti specifici, si può anche decidere di avviare un'istanza dell'applicazione per questo cliente.
Questo modello di creazione dinamico offre molti vantaggi:
- Non si tenterà di indovinare in anticipo il numero di partizioni corretto per tutti gli utenti o di creare un unico servizio che è di per sé scalabile all'infinito.
- I diversi utenti non dovranno avere lo stesso numero di partizioni, numero di repliche, vincoli di posizionamento, metriche, carichi predefiniti, nomi di servizio, impostazioni DNS o qualunque delle altre proprietà specificate a livello di servizio o di applicazione.
- Si ottiene una segmentazione dei dati aggiuntiva. Ogni cliente dispone della propria copia del servizio
- Ogni servizio del cliente può essere configurato in maniera diversa, con più o meno risorse, partizioni o repliche in base alle necessità e alla scalabilità prevista.
- Si supponga, ad esempio, che il cliente abbia pagato per il livello "Gold", che gli consente di ottenere più repliche o un numero superiore di partizioni e potenzialmente risorse dedicate ai servizi attraverso metriche e funzionalità di applicazione.
- Si supponga in alternativa che il cliente abbia indicato che il numero di contatti necessari è "ridotto", quindi ottiene solo alcune partizioni oppure può addirittura essere inserito in un pool di servizi condiviso con altri clienti.
- Ogni servizio del cliente può essere configurato in maniera diversa, con più o meno risorse, partizioni o repliche in base alle necessità e alla scalabilità prevista.
- Non si esegue una serie di istanze del servizio o repliche mentre si attende l'arrivo dei clienti
- Se un cliente lascia il servizio, la rimozione delle informazioni dal servizio è facile quanto fare eliminare dal servizio gestione il servizio o l'applicazione creata.
Passaggi successivi
Per altre informazioni sui concetti relativi a Service Fabric, vedere gli articoli seguenti: