Partizionamento dell'output dei BLOB personalizzato in Analisi di flusso di Azure
Analisi di flusso di Azure supporta il partizionamento dell'output dei BLOB personalizzato con campi o attributi personalizzati o e modelli di percorso di data/ora personalizzati.
Campi o attributi personalizzati
Gli attributi o i campi personalizzati migliorano i flussi di lavoro di elaborazione e reporting downstream, consentendo un maggior controllo sull'output.
Opzioni per la chiave di partizione
La chiave di partizione o il nome di colonna usati per partizionare i dati di input possono contenere qualsiasi carattere accettato per i nomi BLOB. Non è possibile usare campi annidati come chiave di partizione, a meno che non venga usato insieme agli alias, ma è possibile usare determinati caratteri per creare una gerarchia di file. Ad esempio, è possibile usare la query seguente per creare una colonna che combina i dati da due altre colonne per creare una chiave di partizione univoca.
SELECT name, id, CONCAT(name, "/", id) AS nameid
La chiave di partizione deve essere NVARCHAR(MAX), BIGINT, FLOAT o BIT (livello di compatibilità 1.2 o superiore). I tipi DateTime, Array e Record non sono supportati, ma possono essere usati come chiavi di partizione se vengono convertiti in String. Per altre informazioni, vedere Tipi di dati di Analisi di flusso di Azure.
Esempio
Si supponga che un processo accetti dati di input da sessioni utente in tempo reale connesse a un servizio di videogiochi esterno, in cui i dati inseriti contengono una colonna client_id per identificare le sessioni. Per partizionare i dati per client_id, impostare il campo Modello percorso del BLOB in modo includere un token di partizione {client_id} nelle proprietà di output del BLOB quando si crea un processo. Man mano che i dati con vari valori client_id transitano attraverso il processo di Analisi di flusso, i dati di output vengono salvati in cartelle separate in base a un singolo valore client_id per ogni cartella.

Analogamente, se l'input del processo fossero dati provenienti da milioni di sensori, in cui ogni sensore ha un sensor_id, il modello di percorso sarebbe {sensor_id} per partizionare i dati di ogni sensore in cartelle diverse.
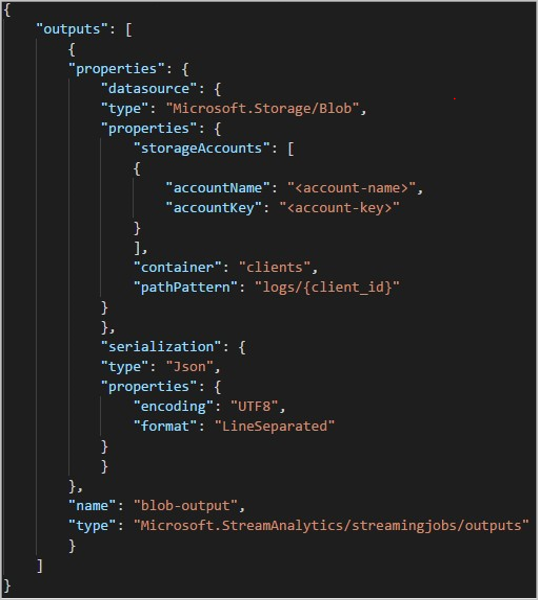
Quando si usa l'API REST, la sezione di output di un file JSON usato per tale richiesta può essere simile all'immagine seguente:
Dopo l'avvio del processo, il clients contenitore potrebbe essere simile all'immagine seguente:
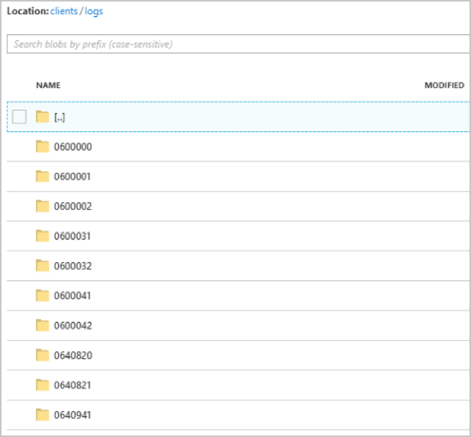
Ogni cartella può contenere più BLOB, ognuno dei quali può contenere uno o più record. Nell'esempio precedente è presente un singolo BLOB in una cartella con etichetta "060000000" con il contenuto seguente:
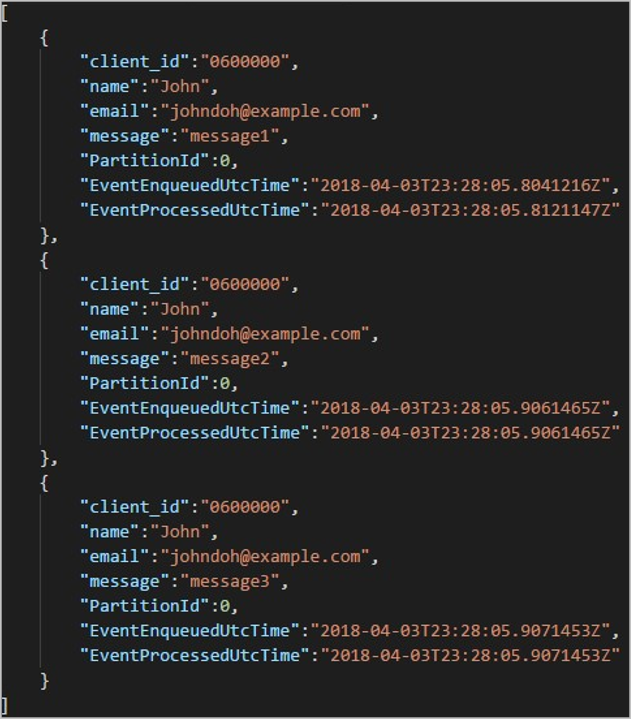
Si noti che ogni record nel BLOB ha una colonna client_id corrispondente al nome della cartella, perché la colonna usata per partizionare l'output nel percorso di output era client_id.
Limitazioni
È consentita solo una chiave di partizione personalizzata nella proprietà di output del BLOB Modello percorso. Tutti i modelli di percorso seguenti sono validi:
- cluster1/{date}/{aFieldInMyData}
- cluster1/{time}/{aFieldInMyData}
- cluster1/{aFieldInMyData}
- cluster1/{date}/{time}/{aFieldInMyData}
Se i clienti vogliono usare più campi di input, possono creare una chiave composita in query per la partizione di percorso personalizzata nell'output BLOB usando CONCAT. Ad esempio, selezionare concat (col1, col2) come compositeColumn in BLOBOutput dall'input. Possono quindi specificare compositeColumn come percorso personalizzato nell'archiviazione BLOB.
Le chiavi di partizione sono senza distinzione tra maiuscole e minuscole, quindi le chiavi di partizione come
Johnejohnsono equivalenti. Inoltre, le espressioni non possono essere usate come chiavi di partizione. Ad esempio, {columnA + columnB} non funziona.Quando un flusso di input è costituito da record con una cardinalità della chiave di partizione sotto 8000, i record vengono aggiunti ai BLOB esistenti e creano solo nuovi BLOB quando necessario. Se la cardinalità è superiore a 8000, non esiste alcuna garanzia che i BLOB esistenti vengano scritti in e i nuovi BLOB non verranno creati per un numero arbitrario di record con la stessa chiave di partizione.
Se l'output BLOB è configurato come non modificabile, Analisi di flusso crea un nuovo BLOB ogni volta che vengono inviati i dati.
Modelli di percorso di data/ora personalizzati
I modelli di percorso di data/ora personalizzati consentono di specificare un formato di output in linea con le convenzioni Streaming Hive, offrendo ad Analisi di flusso di Azure la possibilità di inviare i dati ad Azure HDInsight e Azure Databricks per l'elaborazione downstream. I modelli di percorso di data/ora personalizzati possono essere implementati facilmente usando la parola chiave datetime nel campo Prefisso percorso di output BLOB, con l'identificatore del formato. Ad esempio: {datetime:yyyy}.
Token supportati
I token di identificatore del formato seguenti possono essere usati da soli o in combinazione per ottenere formati di data/ora personalizzati:
| Identificatore di formato | Descrizione | Risultati per l'ora di esempio 2018-01-02T10:06:08 |
|---|---|---|
| {datetime:yyyy} | Anno come numero di quattro cifre | 2018 |
| {datetime:MM} | Mese da 01 a 12 | 01 |
| {datetime:M} | Mese da 1 a 12 | 1 |
| {datetime:dd} | Giorno da 01 a 31 | 02 |
| {datetime:d} | Giorno da 1 a 31 | 2 |
| {datetime:HH} | Ora in formato 24 ore, da 00 a 23 | 10 |
| {datetime:mm} | Minuti da 00 a 60 | 06 |
| {datetime:m} | Minuti da 0 a 60 | 6 |
| {datetime:ss} | Secondi da 00 a 60 | 08 |
Se non si desidera usare modelli DateTime personalizzati, è possibile aggiungere il token {date} e/o {time} al prefisso Percorso per generare un elenco a discesa con formati DateTime predefiniti.
Estendibilità e restrizioni
È possibile usare un numero illimitato di token {datetime:<specifier>} nel modello del percorso, fino a raggiungere il limite di caratteri per il prefisso del percorso. Gli identificatori di formato non possono essere combinati all'interno di un singolo token oltre le combinazioni già presenti negli elenchi a discesa di data e ora.
Per una partizione di percorso logs/MM/dd:
| Espressione valida | Espressione non valida |
|---|---|
logs/{datetime:MM}/{datetime:dd} |
logs/{datetime:MM/dd} |
È possibile usare più volte lo stesso identificatore di formato nel prefisso del percorso. Il token deve essere ripetuto ogni volta.
Convenzioni Streaming Hive
I modelli di percorso personalizzati per l'archiviazione BLOB possono essere usati con la convenzione Streaming Hive, che prevede che le cartelle siano etichettate con column= nel nome della cartella.
Ad esempio: year={datetime:yyyy}/month={datetime:MM}/day={datetime:dd}/hour={datetime:HH}.
Grazie all'output personalizzato, non è più necessario modificare le tabelle e aggiungere manualmente le partizioni per trasferire i dati tra Analisi di flusso di Azure e Hive. È invece possibile aggiungere numerose cartelle automaticamente usando:
MSCK REPAIR TABLE while hive.exec.dynamic.partition true
Esempio
Creare un account di archiviazione, un gruppo di risorse, un processo di portale di Azure Analisi di flusso e un'origine di input in base alla guida di avvio rapido di Analisi di flusso di Azure. Usare gli stessi dati di esempio usati nella guida introduttiva, disponibili anche in GitHub.
Creare un sink di output BLOB con la configurazione seguente:
Il modello di percorso completo è il seguente:
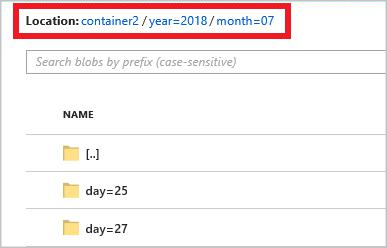
year={datetime:yyyy}/month={datetime:MM}/day={datetime:dd}
Quando si avvia il processo, una struttura di cartelle basata sul modello di percorso viene creata nel contenitore BLOB. È possibile eseguire il drill down a livello di giorno.