Resilienza della piattaforma Azure
Suggerimento
Questo contenuto è un estratto dell'eBook, Progettazione di applicazioni .NET native del cloud per Azure, disponibile in .NET Docs o come PDF scaricabile gratuitamente che può essere letto offline.

La creazione di un'applicazione affidabile nel cloud è diversa dallo sviluppo di applicazioni locali tradizionali. Sebbene in passato l'hardware di fascia alta sia stato acquistato per aumentare le prestazioni, in un ambiente cloud con scalabilità orizzontale. Invece di tentare di prevenire gli errori, l'obiettivo è ridurre al minimo i loro effetti e mantenere stabile il sistema.
Detto questo, le applicazioni cloud affidabili mostrano caratteristiche distinte:
- Sono resilienti, recuperano normalmente dai problemi e continuano a funzionare.
- Sono a disponibilità elevata e vengono eseguiti come progettati in uno stato integro senza tempi di inattività significativi.
Comprendere come queste caratteristiche interagiscono e come influiscono sui costi, è essenziale per creare un'applicazione nativa del cloud affidabile. Verranno ora esaminati i modi in cui è possibile creare resilienza e disponibilità nelle applicazioni native del cloud sfruttando le funzionalità del cloud di Azure.
Progettare con resilienza
Si è detto che la resilienza consente all'applicazione di reagire agli errori e di rimanere funzionante. Il white paper sulla resilienza in Azure fornisce indicazioni per ottenere resilienza nella piattaforma Azure. Ecco alcuni consigli chiave:
Errore hardware. Compilare la ridondanza nell'applicazione distribuendo componenti in domini di errore diversi. Ad esempio, assicurarsi che le macchine virtuali di Azure siano posizionate in rack diversi usando i set di disponibilità.
Errore del data center. Creare ridondanza nell'applicazione con zone di isolamento degli errori tra data center. Ad esempio, assicurarsi che le macchine virtuali di Azure siano posizionate in data center con isolamento degli errori diversi usando le zone di disponibilità di Azure.
Errore a livello di area. Replicare i dati e i componenti in un'altra area in modo che le applicazioni possano essere ripristinate rapidamente. Ad esempio, usare Azure Site Recovery per replicare le macchine virtuali di Azure in un'altra area di Azure.
Carico pesante. Bilanciare il carico tra istanze per gestire i picchi di utilizzo. Ad esempio, inserire due o più macchine virtuali di Azure dietro un servizio di bilanciamento del carico per distribuire il traffico a tutte le macchine virtuali.
Eliminazione o danneggiamento accidentale dei dati. Eseguire il backup dei dati in modo che possa essere ripristinato in caso di eliminazione o danneggiamento. Ad esempio, usare Backup di Azure per eseguire periodicamente il backup delle macchine virtuali di Azure.
Progettare con ridondanza
Gli errori variano nell'ambito dell'impatto. Un errore hardware, ad esempio un errore nel disco, può influire su un singolo nodo in un cluster. Un errore nel commutatore di rete potrebbe influire su un intero rack del server. Errori meno comuni, ad esempio la perdita di energia, potrebbero compromettere un intero data center. Raramente, un'intera area diventa non disponibile.
La ridondanza è un modo per offrire resilienza alle applicazioni. Il livello esatto di ridondanza necessario dipende dai requisiti aziendali e influisce sia sul costo che sulla complessità del sistema. Ad esempio, una distribuzione in più aree è più costosa e più complessa da gestire rispetto a una distribuzione a singola area. Sono necessarie procedure operative per gestire il failover e il failback. Il costo aggiuntivo e la complessità potrebbero essere giustificati per alcuni scenari aziendali, ma non per altri.
Per progettare la ridondanza, è necessario identificare i percorsi critici nell'applicazione e quindi determinare se è presente ridondanza in ogni punto del percorso? Se un sottosistema da un errore, l'applicazione eseguirà il failover in un altro modo? Infine, è necessaria una chiara comprensione di queste funzionalità integrate nella piattaforma cloud di Azure che è possibile sfruttare per soddisfare i requisiti di ridondanza. Ecco le raccomandazioni per progettare la ridondanza:
Distribuire più istanze di servizi. Se l'applicazione dipende da una singola istanza di un servizio, crea un singolo punto di errore. Il provisioning di più istanze migliora sia la resilienza che la scalabilità. Per l’hosting nel servizio Azure Kubernetes, è possibile configurare in modo dichiarativo le istanze ridondanti (set di repliche) nel file manifesto Kubernetes. Il valore del numero di repliche può essere gestito a livello di codice, nel portale o tramite funzionalità di scalabilità automatica.
Uso di un servizio di bilanciamento del carico. Il bilanciamento del carico distribuisce le richieste dell'applicazione alle istanze del servizio integre e rimuove automaticamente le istanze non integre dalla rotazione. Quando si esegue la distribuzione in Kubernetes, il bilanciamento del carico può essere specificato nel file manifesto Kubernetes nella sezione Servizi.
Pianificare la distribuzione di più aree. Se si distribuisce l'applicazione in una singola area e tale area diventa non disponibile, anche l'applicazione non sarà più disponibile. Ciò potrebbe non essere accettabile in base ai termini dei contratti di servizio dell'applicazione. Prendere invece in considerazione la distribuzione dell'applicazione e dei relativi servizi in più aree. Ad esempio, un cluster del servizio Azure Kubernetes viene distribuito in una singola area. Per proteggere il sistema da un errore a livello di area, è possibile distribuire l'applicazione in più cluster del servizio Azure Kubernetes in aree diverse e usare la funzionalità Aree abbinate per coordinare gli aggiornamenti della piattaforma e definire le priorità per le attività di ripristino.
Abilita replica geografica. La replica geografica per servizi come il database SQL di Azure e Cosmos DB creerà repliche secondarie dei dati in più aree. Mentre entrambi i servizi replicano automaticamente i dati all'interno della stessa area, la replica geografica protegge l'utente da un'interruzione a livello di area consentendo di eseguire il failover in un'area secondaria. Un'altra procedura consigliata per la replica geografica riguarda l'archiviazione delle immagini del contenitore. Per distribuire un servizio nel servizio Azure Kubernetes, è necessario archiviare ed eseguire il pull dell'immagine da un archivio. Registro Azure Container si integra con il servizio Azure Kubernetes e può archiviare in modo sicuro le immagini del contenitore. Per migliorare le prestazioni e la disponibilità, prendere in considerazione la replica geografica delle immagini in un registro in ogni area in cui è presente un cluster del servizio Azure Kubernetes. Ogni cluster del servizio Azure Kubernetes esegue quindi il pull delle immagini del contenitore dal registro contenitori locale nella relativa area, come illustrato nella figura 6-4:
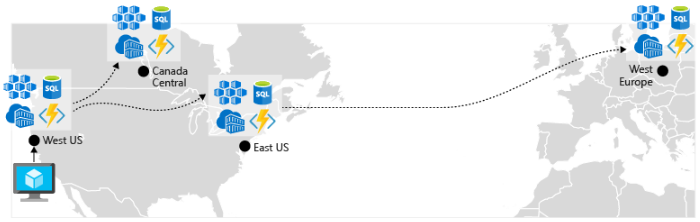
Figura 6-4. Risorse replicate tra aree
- Implementare un servizio di bilanciamento del carico del traffico DNS.Gestione traffico di Azure offre disponibilità elevata per le applicazioni critiche bilanciando il carico a livello di DNS. Può instradare il traffico a diverse aree in base all'area geografica, al tempo di risposta del cluster e anche all'integrità dell'endpoint dell'applicazione. Ad esempio, Gestione traffico di Azure può indirizzare i clienti al cluster e all'istanza dell'applicazione del servizio Azure Kubernetes più vicina. Se sono presenti più cluster del servizio Azure Kubernetes in aree diverse, usare Gestione traffico per controllare il flusso del traffico verso le applicazioni eseguite in ogni cluster. La figura 6-5 illustra questo scenario.
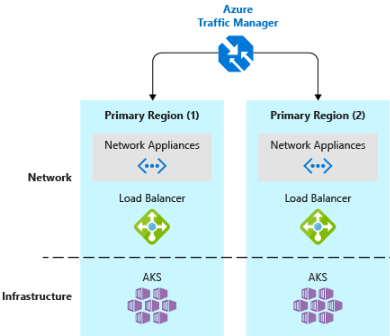
Figura 6-5. Servizio Azure Kubernetes e Gestione traffico di Azure
Progettazione per la scalabilità
Il cloud cresce sul ridimensionamento. La possibilità di aumentare o ridurre le risorse di sistema per affrontare l'aumento o la riduzione del carico di sistema è una chiave del cloud di Azure. Tuttavia, per ridimensionare in modo efficace un'applicazione, è necessaria una conoscenza delle funzionalità di ridimensionamento di ogni servizio di Azure incluso nell'applicazione. Ecco le raccomandazioni per implementare in modo efficace il ridimensionamento nel sistema.
Progettare per la scalabilità. Un'applicazione deve essere progettata per il ridimensionamento. Per iniziare, i servizi devono essere senza stato in modo che le richieste possano essere indirizzate a qualsiasi istanza. La presenza di servizi senza stato significa anche che l'aggiunta o la rimozione di un'istanza non influisce negativamente sugli utenti attuali.
Carichi di lavoro di partizione. La scomposizione dei domini in microservizi indipendenti e autonomi consente a ogni servizio di ridimensionarsi indipendentemente da altri. In genere, i servizi avranno esigenze e requisiti di scalabilità diversi. Il partizionamento consente di ridimensionare solo ciò che deve essere ridimensionato senza il costo non necessario per il ridimensionamento di un'intera applicazione.
Favorire il scale-out. Le applicazioni basate sul cloud favoriscono il ridimensionamento delle risorse anziché l'aumento delle prestazioni. Lo scale-out (noto anche come scalabilità orizzontale) comporta l'aggiunta di altre risorse di servizio a un sistema esistente per soddisfare e condividere un livello di prestazioni desiderato. Lo scale-up (noto anche come scalabilità verticale) comporta la sostituzione delle risorse esistenti con hardware più potente (più dischi, memoria ed elaborazione dei core). Lo scale-out può essere richiamato automaticamente con le funzionalità di scalabilità automatica disponibili in alcune risorse cloud di Azure. Lo scale-out tra più risorse aggiunge anche ridondanza al sistema complessivo. Infine, lo scale-up di una singola risorsa è in genere più costoso rispetto allo scale-out tra molte risorse più piccole. La figura 6-6 illustra i due approcci:
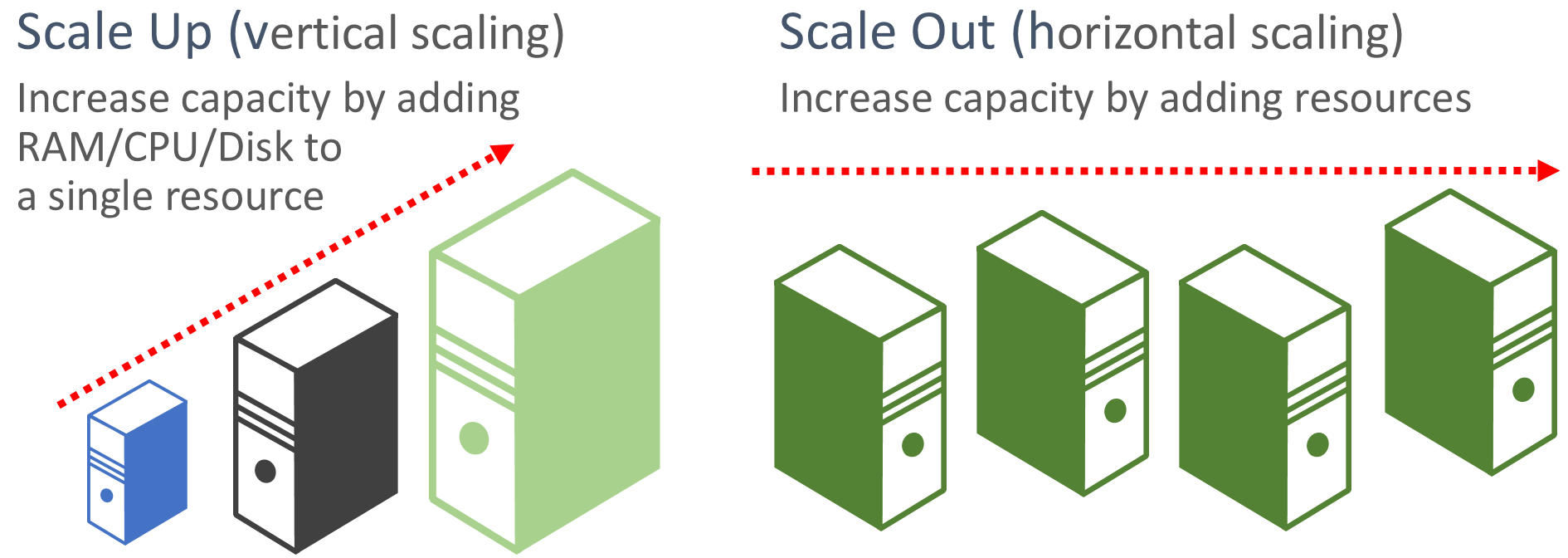
Figura 6-6. Aumentare lo scale-up rispetto allo scale-out
Scalare proporzionalmente. Quando si ridimensiona un servizio, è necessario pensare in termini di set di risorse. Se si dovesse aumentare notevolmente il numero di istanze di un servizio specifico, quale impatto potrebbe avere sugli archivi dati back-end, sulle cache e sui servizi dipendenti? Alcune risorse, ad esempio Cosmos DB, possono aumentare proporzionalmente, mentre molte altre non possono. Si vuole assicurarsi di non aumentare il numero di istanze di una risorsa in un punto in cui esaurirà altre risorse associate.
Evitare l'affinità. Una procedura consigliata consiste nel garantire che un nodo non richieda affinità locale, spesso definita sessione permanente. Una richiesta deve essere in grado di instradare a qualsiasi istanza. Se è necessario rendere persistente lo stato, deve essere salvato in una cache distribuita, ad esempio cache Redis di Azure.
Sfruttare le funzionalità di scalabilità automatica della piattaforma. Usare le funzionalità di scalabilità automatica predefinite, quando possibile, anziché meccanismi personalizzati o di terze parti. Se possibile, usare le regole di ridimensionamento pianificate per garantire che le risorse siano disponibili senza un ritardo di avvio, ma aggiungere la scalabilità automatica reattiva alle regole in base alle esigenze, per far fronte a cambiamenti imprevisti nella domanda. Per ulteriori informazioni, consultare Linee guida per la scalabilità automatica.
Aumentare il numero di istanze in modo deciso. Una pratica finale consiste nell'aumentare il numero di istanze in modo aggressivo in modo da poter soddisfare rapidamente picchi immediati nel traffico senza perdere attività aziendali. E quindi ridurre in modo conservativo (ovvero rimuovere le istanze non necessarie) per mantenere stabile il sistema. Un modo semplice per implementare questa operazione consiste nell'impostare il periodo di raffreddamento, ovvero il tempo di attesa tra le operazioni di ridimensionamento, fino a cinque minuti per l'aggiunta di risorse e fino a 15 minuti per la rimozione delle istanze.
Tentativi predefiniti nei servizi
È stata consigliata la procedura consigliata per implementare operazioni di ripetizione dei tentativi a livello di codice in una sezione precedente. Tenere presente che molti servizi di Azure e gli SDK client corrispondenti includono anche meccanismi di ripetizione dei tentativi. L'elenco seguente riepiloga le funzionalità di ripetizione dei tentativi in molti dei servizi di Azure illustrati in questo libro:
Azure Cosmos DB. La classe DocumentClient dall'API client ritira automaticamente i tentativi non riusciti. Il numero di tentativi e il tempo di attesa massimo sono configurabili. Le eccezioni generate dall'API client sono richieste che superano i criteri di ripetizione dei tentativi o gli errori non temporanei.
Cache Redis di Azure. Il client Redis StackExchange usa una classe di gestione connessione che include tentativi in caso di tentativi non riusciti. Il numero di tentativi, criteri di ripetizione specifici e tempo di attesa sono tutti configurabili.
Bus di servizio di Azure. Il client del bus di servizio espone una classe RetryPolicy che può essere configurata con un intervallo di back-off, un numero di tentativi e TerminationTimeBuffer, che specifica il tempo massimo necessario per un'operazione. Il criterio predefinito è costituito da nove tentativi massimi con un periodo di backoff di 30 secondi tra i tentativi.
Database SQL di Azure. Il supporto per i tentativi viene fornito quando si usa la libreria Entity Framework Core.
Archiviazione di Azure. La libreria client di archiviazione supporta operazioni di ripetizione dei tentativi. Le strategie variano in base alle tabelle di archiviazione di Azure, ai BLOB e alle code. Quando la funzionalità di ridondanza geografica è abilitata, anche i tentativi alternativi passano tra le posizioni dei servizi di archiviazione primari e secondari.
Hub eventi di Azure. La libreria client dell'hub eventi include una proprietà RetryPolicy, che include una funzionalità di backoff esponenziale configurabile.
Commenti e suggerimenti
Presto disponibile: Nel corso del 2024 verranno gradualmente disattivati i problemi di GitHub come meccanismo di feedback per il contenuto e ciò verrà sostituito con un nuovo sistema di feedback. Per altre informazioni, vedere https://aka.ms/ContentUserFeedback.
Invia e visualizza il feedback per