Struttura dei dati
Quando un utente invia un processo, i blocchi di dati HDFS associati vengono caricati e alimentati nelle attività di mapping nella fase di mapping (vedere la figura 2). Ogni attività di mapping elabora uno o più blocchi HDFS incapsulati in una cosiddetta divisione logica. Una divisione logica può contenere uno o più riferimenti (non dati effettivi) a uno o più blocchi HDFS. Le dimensioni delle divisioni logiche, ossia la quantità di blocchi HDFS a cui una divisione logica può fare riferimento, sono un parametro configurabile. Ogni attività di mapping è sempre responsabile dell'elaborazione di una sola divisione logica. Pertanto, il numero di divisioni logiche determina il numero di attività di mapping di un processo MapReduce, che a sua volta determina il parallelismo di mapping complessivo. Se una divisione logica punta a un solo blocco HDFS, il numero di attività di mapping diventa uguale al numero di blocchi HDFS.1,3 Per motivi di località dei dati, una procedura comune in Hadoop consiste nell'incapsulare un unico blocco HDFS in ogni divisione logica. In particolare, MapReduce tenta di pianificare le attività di mapping in prossimità delle divisioni logiche di input, in modo da ridurre il traffico di rete e migliorare le prestazioni delle applicazioni. Di conseguenza, quando una divisione logica fa riferimento a più di un blocco, la probabilità che questi blocchi siano presenti nello stesso nodo in cui viene eseguita la rispettiva attività di mapping diventa bassa. Questo comporta un trasferimento di rete di almeno un blocco (64 MB per impostazione predefinita) per ogni attività di mapping. Con un mapping uno-a-uno tra divisioni logiche e blocchi, invece, un'attività di mapping può essere eseguita nel nodo in cui è presente il blocco necessario e, di conseguenza, può sfruttare la località dei dati e ridurre il traffico di rete.
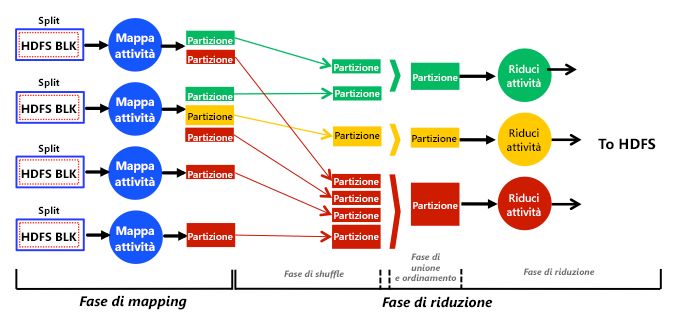
Figura 2: Visualizzazione completa e semplificata delle fasi, delle fasi, delle attività, dell'input dei dati, dell'output dei dati e del flusso di dati nel motore di analisi MapReduce
In presenza di una fase di riduzione, le attività di mapping archiviano le partizioni nei dischi locali (non in HDFS) e ne eseguono l'hash nelle attività di riduzione designate. Ogni attività di riduzione raccoglie (tramite shuffling) le partizioni corrispondenti dai dischi locali, le unisce e le ordina, esegue una funzione di riduzione definita dall'utente e archivia il risultato finale in HDFS. In questo modo, la fase di riduzione è in genere suddivisa negli stadi di shuffling, di unione e ordinamento e di riduzione, come illustrato nella figura 2. In assenza di una fase di riduzione, le attività di mapping scrivono gli output direttamente in HDFS. La figura 2 mostra che le attività di riduzione possono ricevere un numero variabile di partizioni di dimensioni diverse. Questo fenomeno è noto come disallineamento delle partizioni1, 4 e ha alcuni effetti sulla pianificazione delle attività di riduzione.
La figura 2 illustra una visualizzazione semplificata della funzione del motore Hadoop MapReduce. Ad esempio, MapReduce sovrappone le fasi di mapping e di riduzione per motivi di prestazioni. In particolare, le attività di riduzione vengono pianificate dopo il completamento di una determinata percentuale (per impostazione predefinita, 5%) di attività di mapping in modo che possano avviare gradualmente lo shuffling delle partizioni. In particolare, gli stadi di shuffling e di unione e ordinamento vengono eseguiti simultaneamente, per cui le partizioni vengono continuamente unite durante il recupero. La logica alla base di tale strategia è applicare l'interfoliazione all'esecuzione delle attività di mapping e di riduzione e ottimizzare di conseguenza i tempi di turnaround dei processi MapReduce. Una tecnica di interfoliazione di questo tipo è comunemente denominata tecnica di shuffling anticipato.2, 4
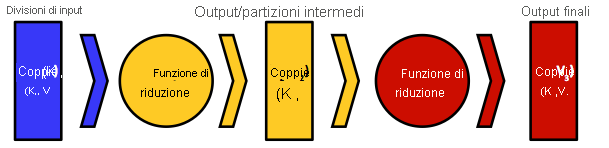
Figura 3: Modello di dati chiave-valore che MapReduce usa e l'input e l'output da e verso le funzioni di mapping e riduzione
MapReduce è stato ispirato dai linguaggi funzionali. I programmatori scrivono codice in stile funzionale che comprende funzioni di mapping e di riduzione sequenziali inviate come processi al motore MapReduce. Il motore trasforma i processi in attività di mapping e riduzione, distribuendole e pianificandole nei nodi del cluster partecipanti.2 Gli input e gli output delle funzioni di mapping e di riduzione sono sempre strutturati come coppie chiave-valore e il flusso di dati segue il modello generale illustrato nella figura 3. In genere, i tipi di chiave e valore dell'input di mapping, $K_{1}- V_{1}$, differiscono dai tipi di chiave e valore dell'output della funzione, $K_{2}$ e $V_{2}$. I tipi di chiave e valore dell'input di riduzione, $K_{2}$ e $V_{2}$, tuttavia, devono corrispondere agli output della funzione di mapping. La funzione di riduzione consente l'aggregazione di valori, quindi in genere riceve un iteratore (elenco) di valori di input da più attività di mapping. Applica quindi la funzione di riduzione definita dall'utente su questi valori collettivamente, restituendo possibilmente nuovi tipi di coppia chiave-valore, $K_{3}$ e $V_{3}$. Una chiave di un'attività di mapping può comparire solo in un'attività di riduzione, mentre un'attività di riduzione può ricevere ed elaborare le chiavi di una o più attività di mapping. Questa proprietà è garantita dal motore MapReduce (in particolare dalla funzione hash usata nel partizionamento dell'output di mapping). Infine, è possibile introdurre un'altra funzione, la funzione di combinatore, nell'output della funzione di mapping, dove agisce come una funzione di riduzione. In questo caso, l'output della funzione di combinatore formerà successivamente l'input della funzione di riduzione.
La funzione di combinatore viene illustrata meglio tramite un esempio. Si supponga che una funzione di mapping analizzi i file che rappresentano i guadagni previsti da un'azienda nei 5 anni successivi, producendo coppie chiave-valore nel formato [$K_{2}$ = anno, $V_{2}$ = guadagni stimati (in milioni di dollari USA)]. Si supponga che più modelli matematici generino le previsioni, possibilmente diverse, per un anno specifico. Si supponga inoltre che una funzione di riduzione riceva l'output di mapping e calcoli i guadagni massimi nel corso degli anni. Si supponga che due attività di mapping, $M_{1}$ e $M_{2}$, elaborino le stime per il 2015 (che si trovano in due divisioni logiche diverse) e generino i risultati {[2015, 29], [2015, 31]} diviso $M_{1}$ e {[2015, 23], [2015, 31], [2015, 28]} diviso $M_{2}$. Gli output di $M_{1}$ e $M_{2}$ verranno quindi sottoposti a hash e trasferiti tramite shuffling nella stessa attività di riduzione, quindi la funzione di riduzione verrà chiamata con l'input {[2015, 29], [2015, 31], [2015, 23], [2015, 31], [2015, 28]} e produrrà l'output [2015, 31] che fornisce l'importo massimo previsto. Se tuttavia una funzione di combinatore calcola anche i guadagni massimi previsti nell'output $M_{1}$ e $M_{2}$, nell'attività di riduzione corrispondente verranno trasferiti tramite shuffling solo [2015, 31] e [2015, 31] da $M_{1}$ e $M_{2}$. Il combinatore diminuirà così la quantità di dati trasferiti tramite shuffling sulla rete, risparmierà la larghezza di banda disponibile nel cluster e potenzialmente migliorerà le prestazioni. Anche se questa tattica funziona per questo calcolo di esempio, non è detto che riesca per altri. Ad esempio, per calcolare la media dei guadagni previsti nel corso degli anni, non è possibile calcolare una media nel combinatore perché, in matematica, la media delle medie di più valori non è sempre uguale alla media di tutti gli stessi valori. Le funzioni di combinatore appropriate devono essere funzioni commutative e associative o funzioni di distribuzione come indicato in Grigio e associate, "Data Cube: A Relational Aggregation Operator Generalizing Group-by, Cross-tab, and Sub-totals".5
1 Il numero di blocchi HDFS di un processo può essere calcolato dividendo le dimensioni del set di dati del processo per le dimensioni dei blocchi HDFS configurabili.
2 Ogni attività di riduzione elabora uno o più valori prodotti da una o più attività di mapping.
Riferimenti
- S. Ibrahim, H. Jin, L. Lu, S. Wu, B. He e L. Qi (dic. 2010). LEEN: Locality/Fairness-Aware Key Partitioning for MapReduce in the Cloud CloudComm
- M. Hammoud e M. F. Sakr (2011). Locality-Aware Reduce Task Scheduling for MapReduce CloudCom
- HDFS Architecture Guide Hadoop
- M. Hammoud, M. S. Rehman e M. F. Sakr (2012). Center-of-Gravity Reduce Task Scheduling to Lower MapReduce Network Traffic CLOUD
- J. Gray, S. Chaudhuri, A. Bosworth, A. Layman, D. Reichart, M. Venkatrao e H. Pirahesh (1997). Data Cube: A Relational Aggregation Operator Generalizing Group-by, Cross-tab, and Sub-totals Data Mining and Knowledge Discovery