Pianificazione di processi e attività
MapReduce pianifica il lavoro a livello di processo e di attività. I client inviano i processi e il JobTracker (JT) li partiziona in attività di mapping e di riduzione. La pianificazione dei processi determina il processo successivo da eseguire e la pianificazione delle attività ordina le attività in un processo. In Hadoop MapReduce il JT pianifica sia i processi che le attività, anche se i pianificatori dei processi sono collegabili, ovvero non fanno parte del codice di JT. I pianificatori delle attività, al contrario, sono integrati nel codice di JT. L'introduzione dei pianificatori di processi collegabili nel framework Hadoop è considerata un'evoluzione del cluster computing.4 I pianificatori collegabili consentono di personalizzare Hadoop per specifici carichi di lavoro e applicazioni. Questa funzionalità offre la possibilità di ottimizzare i pianificatori di processi per l'elenco in continua crescita di applicazioni MapReduce. Inoltre, i pianificatori collegabili migliorano la leggibilità del codice e facilitano le attività di sperimentazione e test essenziali per la ricerca.
Hadoop MapReduce usa diversi pianificatori di processi alternativi, tra cui il modello FiFO (First-in, First-out) predefinito, oltre a Fair Scheduler e Capacity Scheduler.4, 5, 6, 7, 13 Il modello FIFO suggerisce di estrarre i processi da una coda di lavoro in ordine di ricezione, a partire dal meno recente, e di avviarli uno dopo l'altro. Anche se tale strategia sembra semplice e facile da usare, in realtà presenta diversi svantaggi:
- La pianificazione FIFO non supporta la precedenza dei processi. Non è possibile interrompere i processi in esecuzione per consentire il proseguimento di quelli in attesa e soddisfare gli obiettivi di prestazioni, ad esempio evitando di distogliere risorse dai processi e/o condividendo efficacemente le risorse. Di conseguenza, la condivisione simultanea di risorse del cluster non è fattibile. Finché un processo assorbe tutte le risorse (slot) di un cluster, nessun altro può procedere. Quindi, il processo successivo in coda deve aspettare fino a quando gli slot per le attività risultano liberi e il processo corrente non ha altre attività da eseguire. Questa limitazione può facilmente generare un conflitto di equità, in cui un processo a esecuzione prolungata blocca l'intero cluster, distogliendo risorse da tutti i processi più piccoli.
- Il pianificatore FIFO non considera la priorità o le dimensioni dei processi, per cui la priorità di un processo viene stabilita unicamente dall'ora di invio. Di conseguenza, i processi possono rimanere in attesa nella coda per periodi prolungati, indipendentemente dal fatto che siano cruciali o urgenti. Questa limitazione pone ulteriori problemi di equità e velocità di risposta.
Per rispondere alle carenze del pianificatore FIFO, Facebook ha sviluppato un meccanismo più sofisticato, il Fair Scheduler5, che ora fa parte della distribuzione Apache Hadoop. Il Fair Scheduler rappresenta le risorse del cluster in termini di slot di mapping e di riduzione e suggerisce un modo per condividere i cluster tale che tutti i processi ricevano, in media, una quota uguale di slot nel corso del tempo. Il pianificatore presuppone la disponibilità di un set di pool in cui vengono posizionati i processi. A ogni pool viene assegnato un set di quote in base agli slot di mapping e di riduzione che i relativi processi costituenti possono occupare. Maggiore è il numero di quote assegnate a un pool, maggiore è il numero di slot di mapping e di riduzione che i processi possono usare. I processi di un pool possono essere pianificati tramite il pianificatore FIFO o con il Fair Scheduler stesso. I processi nei pool vengono sempre pianificati con il Fair Scheduler.
Quando viene inviato solo un singolo processo, il Fair Scheduler gli assegna tutti gli slot di mapping e di riduzione disponibili del cluster. Ai nuovi processi inviati vengono assegnati gli slot che diventano disponibili. Supponendo una distribuzione uniforme di slot, ogni processo otterrà approssimativamente la stessa quantità di tempo della CPU. Questa strategia può ovviamente consentire l'esecuzione simultanea di diversi processi nello stesso cluster Hadoop, "condividendo nello spazio" gli slot del cluster. Questa frase implica che ogni processo abbia accesso esclusivo a un numero specifico di slot nel cluster Hadoop. Questa organizzazione è simile alla condivisione della memoria nei sistemi operativi, per cui il sistema alloca a ogni processo una parte indipendente della memoria principale. Il risultato è che possono coesistere più processi. La condivisione nello spazio, offerta dal Fair Scheduler, consente il completamento dei processi brevi in periodi di tempo ragionevoli, senza distogliere risorse dai processi lunghi. I processi che richiedono meno tempo possono essere eseguiti e completati, mentre quelli che richiedono più tempo continuano a essere eseguiti. Per ridurre al minimo la congestione dovuta alla condivisione e completare il lavoro in modo tempestivo, il Fair Scheduler consente di limitare il numero di processi che possono essere attivi contemporaneamente.
Il Fair Scheduler supporta anche le priorità dei processi, assegnando pesi che influiscono sulla percentuale del tempo totale della CPU che ognuno può ottenere. Può inoltre garantire quote minime ai pool, assicurando che tutti i processi di un pool ottengano un numero sufficiente di slot di mapping e di riduzione. Anche se un pool contiene processi, ottiene almeno una quota minima di risorse. Quando il pool diventa vuoto (nessun altro processo da pianificare), il Fair Scheduler distribuisce i relativi slot assegnati in modo uniforme tra i pool attivi. Se un pool non usa tutta la quota garantita, il Fair Scheduler può anche dividere equamente gli slot di mapping e di riduzione in eccesso tra gli altri pool.
Per soddisfare la quota minima garantita di ogni pool, il Fair Scheduler facoltativamente supporta l'interruzione di processi in altri pool. Questa procedura comporta l'interruzione piuttosto brutale di alcune o tutte le attività di mapping e di riduzione esterne. Poiché Hadoop MapReduce non supporta ancora la sospensione di attività in esecuzione, il Fair Scheduler termina semplicemente le attività di altri pool che superano le loro quote minime garantite. Hadoop può tollerare la perdita di attività, quindi questa strategia non influisce negativamente sui processi interrotti. Può tuttavia influire sull'efficienza, perché le attività terminate devono essere rieseguite, con un conseguente spreco di lavoro. Per ridurre al minimo tale calcolo ridondante, il Fair Scheduler seleziona per la terminazione le attività avviate più di recente tra i processi sovrallocati.
Un terzo modello, il Capacity Scheduler sviluppato da Yahoo!, condivide alcuni principi con il Fair Scheduler. Analogamente al Fair Scheduler, il Capacity Scheduler condivide le risorse (slot) nello spazio. Tuttavia, crea diverse code invece dei pool. Ogni coda include un numero configurabile (capacità) di slot di mapping e di riduzione e può contenere più processi. Tutti i processi di una coda possono accedere alla capacità allocata della stessa. In una coda la pianificazione viene eseguita su base prioritaria, con specifici limiti flessibili o massimi configurabili. Inoltre, le priorità possono essere modificate in base all'ora di invio dei processi. Quando uno slot diventa disponibile, il Capacity Scheduler lo assegna alla coda meno carica, in cui sceglie il processo inviato meno recente. Le capacità in eccesso tra le code (slot inutilizzati) vengono assegnate temporaneamente ad altre code che ne hanno bisogno, anche nel caso in cui superino le capacità allocate inizialmente. Se la coda originale richiede in seguito questi slot riassegnati, il Capacity Scheduler consente il completamento delle attività in esecuzione al loro interno. Solo quando tali attività terminano, gli slot sottostanti vengono restituiti dalle code e ai processi originali (ossia, le attività non vengono terminate). Anche se gli slot vengono riassegnati ai processi precedenti, le code di origine subiscono ritardi, ma evitando l'interruzione dei processi il modello Capacity risulta più semplice ed elimina lo spreco di calcoli. Infine, analogamente al Fair Scheduler, il Capacity Scheduler fornisce una garanzia di capacità minima a ogni coda. In particolare, a ogni coda viene assegnata una capacità garantita, per cui la capacità totale del cluster equivale alla somma delle capacità di tutte le code, senza overcommit.
La pianificazione di un processo con FIFO, Fair Scheduler o Capacity Scheduler implica la pianificazione di tutte le attività costitutive. Per quest'ultima procedura, Hadoop MapReduce usa una strategia pull. Questo significa che, dopo la pianificazione di un processo, il JobTracker non esegue immediatamente il push delle relative attività di mapping e di riduzione ai TaskTracker, ma piuttosto aspetta che i TT effettuino le richieste appropriate tramite il meccanismo di heartbeat. Nella ricezione delle richieste per le attività di mapping, il JT segue un principio di pianificazione di base che indica che "lo spostamento del calcolo verso i dati è più economico rispetto allo spostamento dei dati verso il calcolo". Di conseguenza, cercando di ridurre il traffico di rete, il JT tenta di pianificare le attività di mapping nelle vicinanze dei blocchi di input HDFS pertinenti. Questo obiettivo è facile da realizzare perché l'input di un'attività di mapping viene in genere ospitato in un singolo TT.
Quando si pianificano le attività di riduzione, tuttavia, il JT ignora questo principio, soprattutto perché l'input dell'attività di riduzione (una o più partizioni) è in genere costituito dall'output di molte attività di mapping generato presso più TT. Quando un TT lo chiede, il JT assegna un'attività di riduzione, $R$, indipendentemente dalla distanza della rete del TT dai TT di alimentazione di $R$.7 Con questa strategia, il pianificatore di attività di riduzione di Hadoop non riconosce la località.
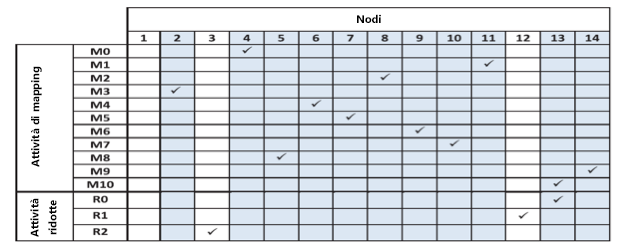
Figura 5: Nodi in cui Hadoop nativo ha pianificato ogni attività di mapping e ridurre l'attività del benchmark WordCount
Per illustrare il non riconoscimento della località e le relative implicazioni, viene definita una distanza totale della rete di un'attività di riduzione, $R$, $(TNDR)$, con la formula $\Sigma_{i=0}^n ND_{iR}$, dove n è il numero di partizioni fornite a $R$ da n nodi e $ND$ è la distanza della rete necessaria per lo shuffling di una partizione $i$ in $R$. Ovviamente, con l'aumento della distanza totale della rete, è necessario più tempo per lo shuffling delle partizioni di $R$ e viene dissipata una larghezza di banda di rete aggiuntiva. La figura 5 indica i nodi in cui ogni attività di mapping, $M_{i}$, e ogni attività di riduzione, $R_{i}$, del benchmark WordCount sono state pianificate da Hadoop nativo. In questo caso, ogni attività di mapping alimenta ogni attività di riduzione e ogni attività di mapping viene pianificata in un nodo distinto. I nodi da 1 a 7 sono ospitati in un rack e il resto in un altro. Hadoop pianifica le attività di riduzione$R_{0}$, $R_{1}$ e $R_{2}$ rispettivamente nei nodi 13, 12 e 3. Il risultato è $TND_{R_{0}}$ = 30, $TND_{R_{1}}$ = 32 e $TND_{R}$ = 34. Se tuttavia le attività $R_{1}$ e $R_{2}$ vengono pianificate rispettivamente nei nodi 11 e 8, il risultato è $TND_{R_{1}}$ = 30 e $TND_{R_{2}}$ = 30. Hadoop, nella versione attuale, non può prendere decisioni di pianificazione così controllate.
Il pianificatore corrente di attività di riduzione di Hadoop, oltre a non riconoscere la posizione, non riconosce neanche il disallineamento delle partizioni. Il disallineamento delle partizioni fa riferimento a una varianza significativa nelle frequenze delle chiavi intermedie e nella relativa distribuzione tra nodi di dati diversi.1, 3 La figura 6 illustra il fenomeno di disallineamento delle partizioni. Mostra le dimensioni delle partizioni che ogni attività di mapping distribuisce a ogni attività di riduzione in due varianti del benchmark Sort, ovvero Sort1 e Sort2, ognuna con un set di dati diverso, in WordCount e in K-means.8 Il disallineamento delle partizioni causa il disallineamento dello shuffling, per cui alcune attività di riduzione ricevono più dati di altre. Il problema del disallineamento dello shuffling può comportare una riduzione delle prestazioni, perché un processo può subire ritardi mentre un'attività di riduzione recupera dati di input di grandi dimensioni, ma il nodo in cui è pianificata un'attività di riduzione può mitigare questo effetto. In generale, l'impatto del pianificatore delle attività di riduzione si può estendere fino a determinare il modello di comunicazione di rete, influendo sulla quantità di dati trasferiti tramite shuffling e sui runtime dei processi MapReduce.
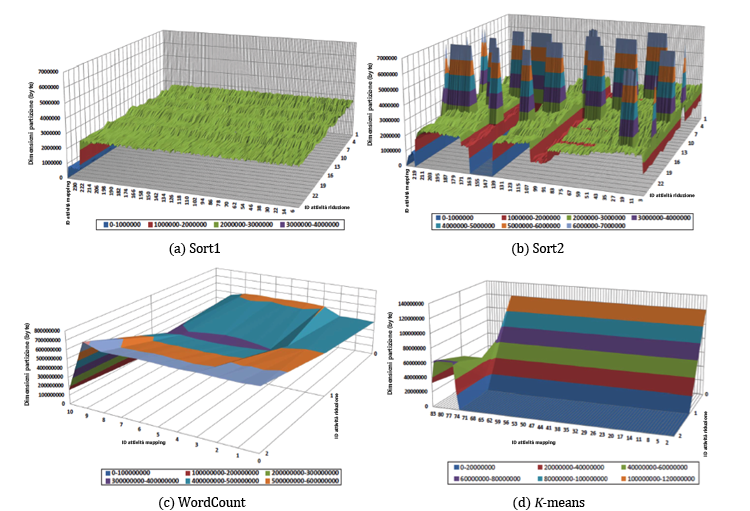
Figura 6: Dimensioni delle partizioni prodotte da ogni attività di mapping di alimentazione per ogni attività di riduzione in Sort1, Sort2, WordCount e K-means
Per rendere più efficace il pianificatore delle attività di riduzione di Hadoop MapReduce, è necessario affrontare congiuntamente la località dei dati e il disallineamento delle partizioni. Per un esempio specifico, la figura 7 illustra un cluster Hadoop con due rack, ognuno dei quali include tre nodi. Si supponga di avere un'attività di riduzione, $R$, con due nodi di alimentazione, TT1 e TT2. L'obiettivo consiste nel pianificare l'attività $R$ per un TT richiedente, presupponendo che i TT 1, 2 e 4 eseguano il polling per un'attività di riduzione. Con il pianificatore nativo di Hadoop, il JT può assegnare $R$ a qualsiasi TT richiedente. Se l'attività $R$ viene assegnata a TT4, $TNDR$ restituirà 8. Se invece $R$ viene assegnata a TT1 o a TT2, $TNDR$ sarà 2. Come illustrato in precedenza, una distanza totale delle rete ridotta produce meno traffico e, di conseguenza, prestazioni più elevate.
Numerosi documenti di ricerca sottolineano l'esigenza di un pianificatore di attività con riconoscimento della località dei dati e del disallineamento delle partizioni.1, 2, 3, 10, 11, 12 Il modello CoGRS (Center-of-Gravity Reduce Scheduler),3 ad esempio, assicura la pianificazione di attività di riduzione con riconoscimento di località e disallineamento. Per ridurre al minimo il traffico di rete, questo modello prova a pianificare ogni attività di riduzione, $R$, nel relativo nodo al centro di gravità, determinato dalle posizioni in rete dei nodi di alimentazione di $R$ e dal disallineamento nelle dimensioni delle partizioni di $R$. In particolare, CoGRS introduce una nuova metrica denominata distanza totale della rete ponderata ($WTND$) e la definisce per ogni $R$* con la formula $WTND_{R}$ = $\Sigma_{i=0}^n ND_{iR} \times w_{i}$, dove $n$ è il numero di partizioni necessarie per $R$, $ND$ è la distanza della rete necessaria per lo shuffling di una partizione, $i$, in $R$ e $w_{i}$ è il peso di una partizione, $i$. In teoria, il centro di gravità di $R$ è sempre uno dei nodi di alimentazione di $R$, perché l'accesso ai dati in locale è meno costoso del trasferimento tramite shuffling sulla rete. Pertanto, CoGRS designa il nodo di alimentazione di $R$, che prevede il valore minimo di $WTND$, come centro di gravità di $R$.
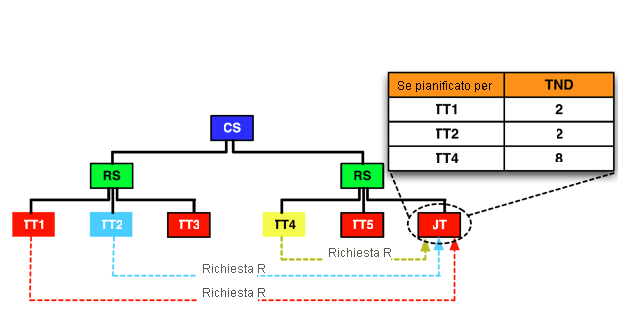
Figura 7: Opzioni per la pianificazione di un'attività di riduzione, $R$, con i nodi di alimentazione TT1 e TT2 in un cluster con due rack (CS = commutatore principale, RS = commutatore rack, TT = TaskTracker e JT = JobTracker)
7 Il TT di alimentazione di un'attività di riduzione, $R$, è quello che ospita almeno una delle attività di mapping di alimentazione di $R$.
8 Si tratta del programma di clustering Apache Mahout K-means.8 K-means è un algoritmo di clustering noto per l'individuazione di conoscenze e il data mining.9
Riferimenti
- S. Ibrahim, H. Jin, L. Lu, S. Wu, B. He e L. Qi (dic. 2010). LEEN: Locality/Fairness-Aware Key Partitioning for MapReduce in the Cloud CloudCom
- M. Hammoud e M. F. Sakr (2011). Locality-Aware Reduce Task Scheduling for MapReduce CloudCom
- M. Hammoud, M. S. Rehman e M. F. Sakr (2012). Center-of-Gravity Reduce Task Scheduling to Lower MapReduce Network Traffic CLOUD
- Hadoop scheduling IBM
- Hadoop fair scheduler Hadoop
- B. Thirumala Rao e L. S. S. Reddy (novembre 2011). Survey on Improved Scheduling in Hadoop MapReduce in Cloud Environments International Journal of Computer Applications
- M. Zaharia, D. Borthakur, J. S. Sarma, K. Elmeleegy, S. Shenker e I. Stoica (aprile 2010). Delay Scheduling: A Simple Technique for Achieving Locality and Fairness in Cluster Scheduling EuroSys, pp. 265-278
- Mahout Homepage Apache Mahout
- S. Huang, J. Huang, J. Dai, T. Xie e B. Huang (2010). The HiBench Benchmark Suite: Characterization of the MapReduce-Based Data Analysis ICDEW
- P. C. Chen, Y. L. Su, J. B. Chang e C. K. Shieh (2010). Variable-Sized Map and Locality-Aware Reduce on Public-Resource Grids GPC
- S. Seo, I. Jang, K. Woo, I. Kim, J. Kim e S. Maeng (2009). HPMR: Prefetching and Pre-Shuffling in Shared MapReduce Computation Environment CLUSTER
- M. Isard, V. Prabhakaran, J. Currey, U. Wieder, K. Talwar e A. Goldberg (2009). Quincy: Fair Scheduling for Distributed Computing Clusters SOSP
- A. C. Murthy, C. Douglas, M. Konar, O. O'Malley, S. Radia, S. Agarwal e K. V. Vinod (2011). Architecture of Next Generation Apache Hadoop MapReduce Framework Apache Jira