Reti neurali convoluzionali
Benché sia possibile usare modelli di Deep Learning per qualsiasi tipo di Machine Learning, si rivelano particolarmente utili per gestire i dati costituiti da grandi matrici di valori numerici, come le immagini. I modelli di Machine Learning che usano le immagini costituiscono le fondamenta di un'area dell'intelligenza artificiale chiamata visione artificiale e le tecniche di Deep Learning sono alla base degli incredibili progressi compiuti in quest'area negli ultimi anni.
Il successo del Deep Learning in quest'area è determinato da un tipo di modello chiamato rete neurale convoluzionale o CNN (Convolutional Neural Network). Una rete CNN in genere funziona estraendo caratteristiche dalle immagini e quindi inserendo queste caratteristiche in una rete neurale completamente connessa per generare una stima. I livelli di estrazione delle caratteristiche nella rete hanno l'effetto di ridurre il numero delle caratteristiche dalla matrice potenzialmente enorme di singoli valori in pixel a un set di caratteristiche ridotto in grado di supportare la stima delle etichette.
Livelli di una rete CNN
Una rete CNN è costituita da più livelli, ognuno dei quali esegue un'attività specifica per l'estrazione delle caratteristiche o la stima delle etichette.
Livelli convoluzionali
Uno dei principali tipi di livelli è il livello convoluzionale che estrae caratteristiche importanti nelle immagini. Il funzionamento di un livello convoluzionale si basa sull'applicazione di un filtro alle immagini. Il filtro è definito da un kernel costituito da una matrice di valori di peso.
Ad esempio, un filtro 3x3 potrebbe essere definito nel modo seguente:
1 -1 1
-1 0 -1
1 -1 1
Un'immagine è anche semplicemente una matrice di valori in pixel. Per applicare il filtro, è necessario "sovrapporlo" a un'immagine e calcolare una somma ponderata dei valori in pixel dell'immagine corrispondente nel kernel del filtro. Il risultato viene quindi assegnato alla cella centrale di una patch 3x3 equivalente in una nuova matrice di valori con le stesse dimensioni dell'immagine. Si supponga, ad esempio, che un'immagine 6x6 abbia i valori in pixel seguenti:
255 255 255 255 255 255
255 255 100 255 255 255
255 100 100 100 255 255
100 100 100 100 100 255
255 255 255 255 255 255
255 255 255 255 255 255
L'applicazione del filtro alla patch 3x3 superiore sinistra dell'immagine funziona come indicato di seguito:
255 255 255 1 -1 1 (255 x 1)+(255 x -1)+(255 x 1) +
255 255 100 x -1 0 -1 = (255 x -1)+(255 x 0)+(100 x -1) + = 155
255 100 100 1 -1 1 (255 x1 )+(100 x -1)+(100 x 1)
Il risultato viene assegnato al valore in pixel corrispondente nella nuova matrice, come indicato di seguito:
? ? ? ? ? ?
? 155 ? ? ? ?
? ? ? ? ? ?
? ? ? ? ? ?
? ? ? ? ? ?
? ? ? ? ? ?
A questo punto, il filtro viene spostato (convoluzione), in genere usando una dimensione del passaggio di 1 (spostandosi quindi di un pixel a destra), e viene calcolato il valore del pixel successivo.
255 255 255 1 -1 1 (255 x 1)+(255 x -1)+(255 x 1) +
255 100 255 x -1 0 -1 = (255 x -1)+(100 x 0)+(255 x -1) + = -155
100 100 100 1 -1 1 (100 x1 )+(100 x -1)+(100 x 1)
È ora possibile inserire il valore successivo della nuova matrice.
? ? ? ? ? ?
? 155 -155 ? ? ?
? ? ? ? ? ?
? ? ? ? ? ?
? ? ? ? ? ?
? ? ? ? ? ?
Il processo si ripete finché il filtro non è stato applicato a tutte le patch 3x3 dell'immagine per produrre una nuova matrice di valori come la seguente:
? ? ? ? ? ?
? 155 -155 155 -155 ?
? -155 310 -155 155 ?
? 310 155 310 0 ?
? -155 -155 -155 0 ?
? ? ? ? ? ?
A causa delle dimensioni del kernel del filtro, non è possibile calcolare i valori per i pixel sul perimetro, quindi in genere viene semplicemente applicato un valore di riempimento (spesso 0):
0 0 0 0 0 0
0 155 -155 155 -155 0
0 -155 310 -155 155 0
0 310 155 310 0 0
0 -155 -155 -155 0 0
0 0 0 0 0 0
L'output della convoluzione in genere viene trasmesso a una funzione di attivazione, che spesso è una funzione di tipo unità lineare rettificata (ReLU, Rectified Linear Unit) che garantisce che i valori negativi siano impostati su 0:
0 0 0 0 0 0
0 155 0 155 0 0
0 0 310 0 155 0
0 310 155 310 0 0
0 0 0 0 0 0
0 0 0 0 0 0
La matrice risultante è una mappa delle caratteristiche dei valori delle caratteristiche che è possibile usare per eseguire il training di un modello di Machine Learning.
Nota: i valori nella mappa delle caratteristiche possono essere superiori al valore massimo per un pixel (255), quindi se si vuole visualizzare la mappa delle caratteristiche come immagine, è necessario normalizzare i valori delle caratteristiche tra 0 e 255.
Il processo di convoluzione è illustrato nell'animazione riportata di seguito.

- Viene passata un'immagine al livello convoluzionale. In questo caso, l'immagine è una forma geometrica semplice.
- L'immagine è costituita da una matrice di pixel con valori compresi tra 0 e 255 (per le immagini a colori, si tratta in genere di una matrice tridimensionale con valori per i canali rosso, verde e blu).
- Un kernel del filtro viene in genere inizializzato con pesi casuali (in questo esempio, sono stati scelti valori per evidenziare l'effetto che un filtro potrebbe avere sui valori in pixel; tuttavia, in una rete CNN reale, i pesi iniziali di solito vengono generati da una distribuzione gaussiana casuale). Questo filtro verrà usato per estrarre una mappa delle caratteristiche dai dati dell'immagine.
- Si verifica la convoluzione del filtro all'interno dell'immagine, con il calcolo dei valori delle caratteristiche attraverso l'applicazione di una somma dei pesi moltiplicati per i valori in pixel corrispondenti in ogni posizione. Viene applicata una funzione di attivazione di tipo unità lineare rettificata (ReLU) per assicurarsi che i valori negativi siano impostati su 0.
- Dopo la convoluzione, la mappa delle caratteristiche contiene i valori delle caratteristiche estratte, che spesso evidenziano gli attributi visivi chiave dell'immagine. In questo caso, la mappa delle caratteristiche evidenzia gli spigoli e gli angoli del triangolo nell'immagine.
In genere, un livello convoluzionale applica più kernel di filtro. Ogni filtro produce una mappa delle caratteristiche diversa e tutte le mappe delle caratteristiche vengono passate al livello successivo della rete.
Livelli di pooling
Dopo l'estrazione dei valori delle caratteristiche dalle immagini, vengono usati livelli di pooling (o sottocampionamento) per ridurre il numero dei valori delle caratteristiche mantenendo le caratteristiche di differenziazione principali che sono state estratte.
Uno dei tipi di pooling più comuni è detto max pooling, in cui un filtro viene applicato all'immagine e viene mantenuto solo il valore in pixel massimo all'interno dell'area filtro. Quindi, ad esempio, l'applicazione di un kernel di pooling 2x2 alla patch seguente di un'immagine produrrebbe il risultato 155.
0 0
0 155
Si noti che l'effetto del filtro di pooling 2x2 consiste nel ridurre il numero di valori da 4 a 1.
Come per i livelli convoluzionali, i livelli di pooling funzionano applicando il filtro all'intera mappa delle caratteristiche. L'animazione seguente mostra un esempio di max pooling per una mappa immagine.

- La mappa delle caratteristiche estratta da un filtro in un livello convoluzionale contiene una matrice di valori delle caratteristiche.
- Viene usato un kernel di pooling per ridurre il numero dei valori delle caratteristiche. In questo caso, la dimensione del kernel è 2x2, quindi produrrà una matrice con un quarto del numero dei valori delle caratteristiche.
- Si verifica la convoluzione del kernel di pooling attraverso la mappa delle caratteristiche, mantenendo solo il valore in pixel più alto in ogni posizione.
Livelli di rimozione
Una delle problematiche più complesse di una rete CNN è la prevenzione dell'overfitting, per cui il modello risultante garantisce prestazioni ottimali con i dati di training ma non generalizza correttamente i nuovi dati su cui non è stato eseguito il training. Una tecnica che è possibile usare per attenuare l'overfitting consiste nell'includere livelli in cui il processo di training elimina (o rimuove) in modo casuale le mappe delle caratteristiche. Questa operazione può sembrare illogica, ma è un modo efficace per garantire che il modello non impari a dipendere eccessivamente dalle immagini di training.
Altre tecniche che è possibile usare per mitigare l'overfitting includono il capovolgimento casuale, il mirroring o l'inclinazione delle immagini di training per generare dati variabili tra i periodi di training.
Livelli di flattening
Dopo aver usato i livelli convoluzionali e di pooling per estrarre le caratteristiche salienti nelle immagini, le mappe delle caratteristiche risultanti sono matrici multidimensionali di valori in pixel. Viene usato un livello di flattening per rendere flat le mappe delle caratteristiche in un vettore di valori utilizzabili come input per un livello completamente connesso.
Livelli completamente connessi
In genere, una rete CNN termina con una rete completamente connessa in cui i valori delle caratteristiche vengono passati a un livello di input, tramite uno o più livelli nascosti, e generano valori stimati in un livello di output.
L'architettura di una rete CNN di base potrebbe essere simile alla seguente:
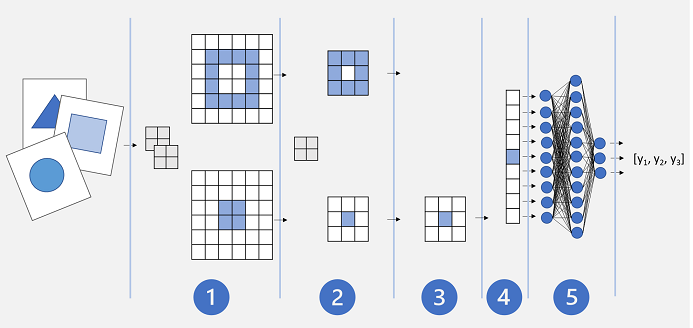
- Le immagini vengono inserite in un livello convoluzionale. In questo caso, sono presenti due filtri, quindi ogni immagine produce due mappe delle caratteristiche.
- Le mappe delle caratteristiche vengono passate a un livello di pooling, in cui un kernel di pooling 2x2 riduce le dimensioni delle mappe delle caratteristiche.
- Un livello di rimozione rimuove in modo casuale alcune delle mappe delle caratteristiche per evitare l'overfitting.
- Un livello di flattening prende le matrici della mappa delle caratteristiche rimanenti e le rende flat in un vettore.
- Gli elementi di vettore vengono inseriti in una rete completamente connessa, che genera le stime. In questo caso, la rete è un modello di classificazione che consente di stimare le probabilità per tre possibili classi di immagini (triangolo, quadrato e cerchio).
Training di un modello CNN
Come per qualsiasi rete neurale profonda, il training di una rete CNN viene eseguito passando attraverso di essa batch di dati di training per più periodi, rettificando i valori di peso e distorsione sulla base della perdita calcolata per ogni periodo. Nel caso di una rete CNN, la retropropagazione dei pesi rettificati include i pesi del kernel del filtro usati nei livelli convoluzionali e i pesi usati nei livelli completamente connessi.