Guida sull'architettura di elaborazione delle query
Si applica a:![]() SQL Server
SQL Server![]() Database SQL di Azure
Database SQL di Azure![]() Istanza gestita di SQL Azure
Istanza gestita di SQL Azure
Il motore di database di SQL Server consente di elaborare le query su diverse architetture di archiviazione dei dati, come tabelle locali, tabelle partizionate e tabelle distribuite su più server. Le sezioni seguenti descrivono l'elaborazione delle query e l'ottimizzazione del riutilizzo delle query in SQL Server tramite la memorizzazione nella cache dei piani di esecuzione.
Modalità di esecuzione
Il motore di database di SQL Server può elaborare istruzioni Transact-SQL usando due modalità di elaborazione distinte:
- Esecuzione in modalità riga
- Esecuzione in modalità batch
Esecuzione in modalità riga
L'esecuzione in modalità riga è un metodo di elaborazione delle query utilizzato con le tabelle RDBMS tradizionali in cui i dati vengono archiviati in formato riga. Quando una query viene eseguita e accede ai dati in tabelle rowstore, gli operatori dell'albero di esecuzione e gli operatori figlio leggono ogni riga necessaria in tutte le colonne specificate nello schema della tabella. Da ogni riga letta, SQL Server recupera le colonne richieste per il set di risultati, come indicato dall'istruzione SELECT, dal predicato di JOIN o dal predicato di filtro.
Nota
L'esecuzione in modalità riga è molto efficiente per gli scenari OLTP, ma può rivelarsi meno efficiente nell'analisi di grandi quantità di dati, ad esempio in scenari che coinvolgono data warehouse.
Esecuzione in modalità batch
L'esecuzione in modalità batch è un metodo di elaborazione delle query con cui le query elaborano più righe contemporaneamente. Ogni colonna all'interno di un batch viene archiviata come vettore in un'area separata della memoria, pertanto l'elaborazione in modalità batch è basata su vettore. L'elaborazione in modalità batch usa inoltre algoritmi ottimizzati per le CPU multicore e la maggiore velocità effettiva di memoria dell'hardware moderno.
Quando è stata introdotta per la prima volta, l'esecuzione in modalità batch era strettamente integrata al formato di archiviazione columnstore, per il quale era ottimizzata. Tuttavia, a partire da SQL Server 2019 (15.x) e nel database SQL di Azure, l'esecuzione in modalità batch non richiede più indici columnstore. Per altre informazioni, vedere Modalità batch per rowstore.
L'elaborazione in modalità batch funziona sui dati compressi, quando disponibili, ed elimina gli operatori di scambio utilizzati dall'esecuzione in modalità riga. Ne derivano un migliore parallelismo e prestazioni più veloci.
Quando una query viene eseguita in modalità batch e accede ai dati negli indici columnstore, gli operatori dell'albero di esecuzione e gli operatori figlio leggono più righe insieme in segmenti di colonna. SQL Server legge solo le colonne necessarie per il risultato, come indicato dall'istruzione SELECT, dal predicato di JOIN o dal predicato di filtro. Per altre informazioni sugli indici columnstore, vedere Architettura degli indici columnstore.
Nota
L'esecuzione in modalità batch è molto efficiente negli scenari che coinvolgono data warehouse in cui vengono lette e aggregate grandi quantità di dati.
Elaborazione di istruzioni SQL
L'elaborazione di una singola istruzione Transact-SQL rappresenta la modalità più semplice di esecuzione delle istruzioni Transact-SQL in SQL Server. Per illustrare il processo di base, viene usata la procedura di elaborazione di una singola istruzione SELECT che fa riferimento esclusivamente a tabelle di base locali, non a viste o tabelle remote.
Ordine di precedenza degli operatori logici
Se in un'istruzione vengono usati più operatori logici, viene valutato prima NOT, quindi AND e infine OR. Gli operatori aritmetici (e bit per bit) vengono valutati prima degli operatori logici. Per altre informazioni, vedere Precedenza degli operatori.
Nell'esempio seguente la condizione per il colore riguarda il modello di prodotto 21 e non il modello di prodotto 20, perché AND ha la priorità rispetto a OR.
SELECT ProductID, ProductModelID
FROM Production.Product
WHERE ProductModelID = 20 OR ProductModelID = 21
AND Color = 'Red';
GO
È possibile modificare il significato della query aggiungendo le parentesi in modo da imporre la priorità dell'operatore OR nell'ordine di valutazione. La query seguente trova solo i prodotti di colore rosso dei modelli 20 e 21.
SELECT ProductID, ProductModelID
FROM Production.Product
WHERE (ProductModelID = 20 OR ProductModelID = 21)
AND Color = 'Red';
GO
L'uso delle parentesi, anche quando non è obbligatorio, può contribuire a rendere le query più leggibili e a ridurre il rischio di errori dovuti all'ordine di precedenza degli operatori. Non ha inoltre alcun effetto negativo rilevante sulle prestazioni. L'esempio seguente risulta più leggibile rispetto a quello precedente, anche se sintatticamente i due esempi sono identici.
SELECT ProductID, ProductModelID
FROM Production.Product
WHERE ProductModelID = 20 OR (ProductModelID = 21
AND Color = 'Red');
GO
Ottimizzare le istruzioni SELECT
Un'istruzione SELECT non definisce esattamente la procedura che il server di database deve eseguire per recuperare i dati richiesti. Il server di database deve pertanto analizzare l'istruzione per determinare il metodo più efficace per l'estrazione dei dati. Tale procedura, denominata ottimizzazione dell'istruzione SELECT, viene eseguita dal componente Query Optimizer. I dati di input per Query Optimizer sono costituiti dalla query, dallo schema del database (definizioni di tabella e indice) e dalle statistiche del database. L'output di Query Optimizer è un piano di esecuzione query, talvolta definito piano di query o piano di esecuzione. La descrizione dettagliata del contenuto di un piano di esecuzione è riportata più avanti in questo articolo.
I dati di input e di output di Query Optimizer durante l'ottimizzazione di una singola istruzione SELECT sono illustrati nel diagramma seguente:
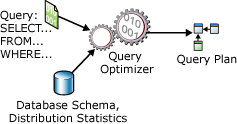
Un'istruzione SELECT definisce soltanto gli elementi seguenti:
- Il formato del set di risultati. Questo elemento viene nella maggior parte dei casi specificato nell'elenco di selezione. Altre clausole, ad esempio
ORDER BYeGROUP BY, possono tuttavia influire sul formato finale del set di risultati. - Le tabelle che contengono i dati di origine. La modalità è specificata nella clausola
FROM. - La relazione logica tra le tabelle ai fini dell'istruzione
SELECT. Questo elemento viene definito nelle specifiche di join, che potrebbero essere incluse nella clausolaWHEREoppure in una clausolaONche segue una clausolaFROM. - Condizioni che le righe delle tabelle di origine devono soddisfare per essere incluse nel risultato dell'istruzione
SELECT. Queste condizioni vengono specificate nelle clausoleWHEREedHAVING.
Il piano di esecuzione di una query è costituito dalla definizione degli elementi seguenti:
La sequenza di accesso alle tabelle di origine.
In genere il server di database può utilizzare molte sequenze diverse per accedere alle tabelle di base e quindi compilare il set di risultati. Ad esempio, se l'istruzioneSELECTfa riferimento a tre tabelle, il server di database può accedere innanzitutto aTableA, usare i dati diTableAper estrarre le righe corrispondenti daTableB, quindi usare i dati diTableBper estrarre i dati daTableC. Di seguito vengono indicate le altre sequenze di accesso alle tabelle utilizzabili dal server di database:
TableC,TableB,TableAo
TableB,TableA,TableCo
TableB,TableC,TableAo
TableC,TableA,TableBI metodi usati per estrarre i dati da ogni tabella.
Per accedere ai dati di ogni tabella sono in genere disponibili metodi diversi. Se sono necessarie solo alcune righe con valori di chiave specifici, il server di database può utilizzare un indice. Se sono necessarie tutte le righe della tabella, il server di database può ignorare gli indici ed eseguire un'analisi di tabella. Se sono necessarie tutte le righe di una tabella, ma l'indice contiene colonne chiave incluse in una clausolaORDER BY, potrebbe essere consigliabile eseguire l'analisi dell'indice anziché della tabella per evitare che il set di risultati venga ordinato separatamente. Se una tabella è di dimensioni molto ridotte, l'analisi della tabella potrebbe rappresentare il metodo più efficiente per quasi tutti gli accessi alla tabella.I metodi usati per eseguire i calcoli e i modi usati per filtrare, aggregare e ordinare i dati da ogni tabella.
Se si accede ai dati dalle tabelle, è possibile usare metodi diversi per eseguire i calcoli sui dati, ad esempio il calcolo dei valori scalari, per aggregare e ordinare i dati come definito nel testo della query, ad esempio quando si usa una clausolaGROUP BYoORDER BY, e per filtrare i dati, ad esempio quando si usa una clausolaWHEREoHAVING.
Il processo di scelta di un piano di esecuzione è denominato ottimizzazione. Query Optimizer è uno dei più importanti componenti del motore di database. L'overhead generato dall'utilizzo di Query Optimizer per l'analisi della query e la scelta di un piano è ampiamente compensato dall'efficienza del piano di esecuzione scelto. Si supponga, ad esempio, che il progetto di costruzione di una casa venga assegnato a due imprese edili diverse. Se un'impresa dedica alcuni giorni alla pianificazione della costruzione della casa e l'altra impresa inizia immediatamente la costruzione senza alcuna pianificazione, è molto probabile che l'impresa che ha pianificato il progetto termini la costruzione per prima.
Query Optimizer di SQL Server è un ottimizzatore basato sui costi. A ogni piano di esecuzione possibile corrisponde un costo in termini di quantità di risorse del computer utilizzate. Query Optimizer analizza i piani possibili e sceglie il piano con il costo stimato minore. Per alcune istruzioni SELECT complesse i piani di esecuzione possibili sono migliaia. In questi casi, Query Optimizer non analizza tutte le combinazioni possibili, ma utilizza algoritmi complessi per individuare rapidamente un piano di esecuzione il cui costo si avvicini il più possibile al costo minimo teorico.
Query Optimizer di SQL Server non sceglie esclusivamente il piano di esecuzione con il costo minore in termini di risorse, ma seleziona il piano che restituisce i risultati all'utente più rapidamente e con un costo ragionevole in termini di risorse. Ad esempio, l'esecuzione parallela di una query in genere utilizza una quantità di risorse maggiore rispetto all'esecuzione seriale, ma consente di completare la query più rapidamente. Query Optimizer di SQL Server utilizzerà un piano di esecuzione parallela per restituire i risultati se il carico sul server non subisce un impatto negativo.
Per eseguire la stima dei costi delle risorse relativi ai diversi metodi di estrazione delle informazioni da una tabella o da un indice, Query Optimizer di SQL Server si affida alle statistiche di distribuzione. Le statistiche di distribuzione vengono registrate per le colonne e gli indici e contengono informazioni sulla densità 1 dei dati sottostanti. Queste informazioni sono usate per indicare la selettività dei valori in un indice o in una colonna. Ad esempio, in una tabella che rappresenta automobili, molte automobili vengono prodotte dallo stesso costruttore, ma a ciascuna è assegnato un numero di identificazione univoco. Un indice basato sul numero di identificazione del veicolo è più selettivo rispetto all'indice basato sul produttore, perché il numero di identificazione del veicolo ha una densità minore rispetto al produttore. Se le statistiche dell'indice non sono aggiornate, Query Optimizer potrebbe non scegliere la soluzione migliore per lo stato corrente della tabella. Per altre informazioni sulle densità, vedere Statistiche.
1 La densità definisce la distribuzione di valori univoci esistenti nei dati, o il numero medio di valori duplicati per una determinata colonna. Man mano che la densità diminuisce, aumenta la selettività di un valore.
Query Optimizer di SQL Server è un componente importante perché consente al server database di adattarsi in modo dinamico alle mutevoli condizioni del database senza fare ricorso all'intervento di un programmatore o di un amministratore di database. In questo modo i programmatori possono concentrarsi sulla descrizione del risultato finale della query. A ogni esecuzione dell'istruzione, Query Optimizer di SQL Server compila un piano di esecuzione efficace per lo stato corrente del database.
Nota
SQL Server Management Studio propone tre opzioni per visualizzare i piani di esecuzione:
- Piano di esecuzione stimato, ovvero il piano compilato generato da Query Optimizer.
- Piano di esecuzione effettivo, ovvero il piano compilato più il contesto di esecuzione. Include le informazioni di runtime disponibili al termine dell'esecuzione, ad esempio gli avvisi relativi all'esecuzione o, nelle versioni più recenti del motore di database, il tempo trascorso e di CPU usato durante l'esecuzione.
- Statistiche sulle query dinamiche, ovvero il piano compilato più il contesto di esecuzione. Includono le informazioni di runtime durante l'avanzamento dell'esecuzione e vengono aggiornate ogni secondo. Le informazioni di runtime includono, ad esempio, il numero effettivo di righe che passano attraverso gli operatori.
Elaborare un'istruzione SELECT
Di seguito viene illustrata la procedura di base necessaria per elaborare una singola istruzione SELECT in SQL Server:
- Il parser esegue l'analisi dell'istruzione
SELECTe la suddivide in unità logiche, quali parole chiave, espressioni, operatori e identificatori. - Viene compilato un albero della query, talvolta denominata sequenza logica, che descrive i passaggi logici necessari per convertire i dati di origine nel formato necessario per il set di risultati.
- Query Optimizer analizza le diverse modalità di accesso alle tabelle di origine e seleziona le serie di passaggi che restituiscono i risultati con maggior rapidità e con minor impiego di risorse. L'albero della query viene aggiornato in modo da registrare la serie esatta di passaggi. La versione finale ottimizzata dell'albero della query è denominato piano di esecuzione.
- Il motore relazionale avvia l'esecuzione del piano di esecuzione. Man mano che vengono elaborati i passaggi che richiedono i dati delle tabelle di base, il motore relazionale richiede al motore di archiviazione di passare i dati dei set di righe richiesti dal motore relazionale stesso.
- Il motore relazionale elabora i dati restituiti dal motore di archiviazione nel formato definito per il set di risultati e restituisce il set di risultati al client.
Valutazione delle espressioni ed elaborazione delle costanti
In SQL Server, alcune espressioni costanti vengono valutate in una fase preliminare per migliorare le prestazioni delle query. Questo comportamento viene denominato elaborazione delle costanti in fase di compilazione. Una costante è un valore letterale Transact-SQL, ad esempio 3, 'ABC', '2005-12-31', 1.0e3, o 0x12345678.
Espressioni per cui è possibile eseguire l'elaborazione delle costanti in fase di compilazione
In SQL Server viene utilizzata l'elaborazione delle costanti in fase di compilazione per i tipi di espressioni seguenti:
- Espressioni aritmetiche che contengono solo costanti, ad esempio
1 + 1e5 / 3 * 2. - Espressioni logiche che contengono solo costanti, ad esempio
1 = 1e1 > 2 AND 3 > 4. - Funzioni predefinite che SQL Server considera idonee per l'elaborazione delle costanti, come
CASTeCONVERT. In genere, per una funzione è possibile eseguire l'elaborazione delle costanti in fase di compilazione se si tratta di una funzione solo dei relativi input e non di altre informazioni contestuali, ad esempio opzioni SET, impostazioni della lingua, opzioni di database e chiavi di crittografia. Per le funzioni non deterministiche non è possibile eseguire l'elaborazione delle costanti in fase di compilazione. Per le funzioni predefinite deterministiche, tranne alcune eccezioni, è possibile eseguire l'elaborazione delle costanti in fase di compilazione. - Metodi deterministici di tipi CLR definiti dall'utente e funzioni CLR definite dall'utente con valori scalari deterministici, a partire da SQL Server 2012 (11.x). Per altre informazioni, vedere Elaborazione delle costanti in fase di compilazione per funzioni e metodi CLR definiti dall'utente.
Nota
Si applica un'eccezione ai tipi LOB. Se il tipo di output del processo di elaborazione delle costanti è un tipo di oggetto Large Object, ossia text,ntext, image, nvarchar(max), varchar(max), varbinary(max) o XML, SQL Server non esegue l'elaborazione delle costanti per l'espressione.
Espressioni per cui non è possibile eseguire l'elaborazione delle costanti in fase di compilazione
Per tutti gli altri tipi di espressione, non è possibile eseguire l'elaborazione delle costanti in fase di compilazione. In particolare, non è possibile eseguire l'elaborazione delle costanti in fase di compilazione per i tipi di espressioni seguenti:
- Espressioni non costanti, ad esempio un'espressione il cui risultato dipende dal valore di una colonna.
- Espressioni il cui risultato dipende da una variabile o un parametro locale, ad esempio @x.
- Funzioni non deterministiche.
- Funzioni Transact-SQL definite dall'utente 1.
- Espressioni il cui risultato dipende dalle impostazioni della lingua.
- Espressioni il cui risultato dipende dalle opzioni SET.
- Espressioni il cui risultato dipende dalle opzioni di configurazione del server.
1 Prima di SQL Server 2012 (11.x), le funzioni e i metodi CLR definiti dall'utente con valori scalari deterministici dei tipi CLR definiti dall'utente non supportavano l'elaborazione in fase di compilazione.
Esempi di espressioni per le quali è possibile eseguire l'elaborazione delle costanti in fase di compilazione e di espressioni per le quali tale elaborazione non è possibile
Considerare la query seguente:
SELECT *
FROM Sales.SalesOrderHeader AS s
INNER JOIN Sales.SalesOrderDetail AS d
ON s.SalesOrderID = d.SalesOrderID
WHERE TotalDue > 117.00 + 1000.00;
Se l'opzione di database PARAMETERIZATION non è impostata su FORCED per questa query, l'espressione 117.00 + 1000.00 viene valutata e sostituita dal relativo risultato, 1117.00, prima della compilazione della query. Tra i vantaggi dell'elaborazione delle costanti in fase di compilazione sono inclusi i seguenti:
- L'espressione non deve essere valutata più volte in fase di esecuzione.
- Il valore dell'espressione in seguito alla valutazione viene usato da Query Optimizer per stimare le dimensioni del set di risultati della parte
TotalDue > 117.00 + 1000.00della query.
Se dbo.f è invece una funzione scalare definita dall'utente, per l'espressione dbo.f(100) non viene eseguita l'elaborazione delle costanti in fase di compilazione, in quanto in SQL Server questa operazione non è possibile per le espressioni che implicano funzioni definite dall'utente, anche se deterministiche. Per altre informazioni sulla parametrizzazione, vedere Parametrizzazione forzata più avanti in questo articolo.
Valutazione di espressioni
Alcune espressioni per cui non viene eseguita l'elaborazione delle costanti ma i cui argomenti sono noti in fase di compilazione, sia che si tratti di parametri o di costanti, vengono valutate tramite lo strumento per la stima delle dimensioni del set di risultati (cardinalità) che è incluso in Query Optimizer durante l'ottimizzazione.
In particolare, se tutti gli input sono noti, in fase di compilazione vengono valutati gli operatori speciali e le funzioni predefinite seguenti: UPPER, LOWER, RTRIM,DATEPART( YY only ), GETDATE, CAST e CONVERT. Anche gli operatori seguenti vengono valutati in fase di compilazione se tutti i relativi input sono noti:
- Operatori aritmetici +, -, , /, - unario -
- Operatori logici
AND,OReNOT - Operatori di confronto: <, >, <=, >=, <>,
LIKE,IS NULL,IS NOT NULL
Gli altri operatori o funzioni non vengono valutati da Query Optimizer durante la stima della cardinalità.
Esempi di valutazione delle espressioni in fase di compilazione
Considerare la stored procedure seguente:
USE AdventureWorks2022;
GO
CREATE PROCEDURE MyProc( @d datetime )
AS
SELECT COUNT(*)
FROM Sales.SalesOrderHeader
WHERE OrderDate > @d+1;
Durante l'ottimizzazione dell'istruzione SELECT nella procedura, Query Optimizer prova a valutare la cardinalità prevista del set di risultati per la condizione OrderDate > @d+1. Per l'espressione @d+1 non viene eseguita l'elaborazione delle costanti in fase di compilazione, in quanto @d è un parametro. Durante l'ottimizzazione, tuttavia, il valore del parametro è noto. Query Optimizer può così stimare in modo accurato le dimensioni del set di risultati e ciò consentirà di selezionare un piano di query appropriato.
Considerare quindi un esempio simile al precedente, ad eccezione del fatto che una variabile locale @d2 sostituisce @d+1 nella query e che l'espressione viene valutata in un'istruzione SET anziché nella query.
USE AdventureWorks2022;
GO
CREATE PROCEDURE MyProc2( @d datetime )
AS
BEGIN
DECLARE @d2 datetime
SET @d2 = @d+1
SELECT COUNT(*)
FROM Sales.SalesOrderHeader
WHERE OrderDate > @d2
END;
Quando l'istruzione SELECT in MyProc2 viene ottimizzata in SQL Server, il valore di @d2 non è noto. Di conseguenza, Query Optimizer usa una stima predefinita per la selettività di OrderDate > @d2, corrispondente in questo caso al 30%.
Elaborare altre istruzioni
La procedura di base descritta per l'elaborazione di un'istruzione SELECT è valida anche per altre istruzioni Transact-SQL, ad esempio INSERT, UPDATE e DELETE. Entrambe le istruzioni UPDATE e DELETE devono definire il set di righe da modificare o eliminare. usando un processo di identificazione delle righe corrispondente a quello che consente di identificare le righe di origine che formano il set di risultati di un'istruzione SELECT . Le istruzioni UPDATE e INSERT potrebbero entrambe contenere istruzioni SELECT incorporate che forniscono i valori di dati da aggiornare o inserire.
Anche le istruzioni DDL (Data Definition Language), ad esempio CREATE PROCEDURE o ALTER TABLE, vengono risolte in una serie di operazioni relazionali eseguite nelle tabelle del catalogo di sistema e in alcuni casi, ad esempio con ALTER TABLE ADD COLUMN, nelle tabelle di dati.
Tabelle di lavoro
Il motore relazionale potrebbe dover compilare una tabella di lavoro per eseguire un'operazione logica specificata in un'istruzione Transact-SQL. Le tabelle di lavoro sono tabelle interne utilizzate per inserirvi i risultati intermedi. Le tabelle di lavoro vengono generate per alcune query GROUP BY, ORDER BYo UNION . Se, ad esempio, una clausola ORDER BY fa riferimento a colonne non coperte da indici, il motore relazionale potrebbe dover generare una tabella di lavoro per disporre il set di risultati nell'ordine richiesto. Le tabelle di lavoro vengono a volte utilizzate anche come spool per conservare temporaneamente il risultato dell'esecuzione di un piano della query. Le tabelle di lavoro vengono compilate in tempdb e vengono eliminate automaticamente quando non sono più necessarie.
Risoluzione delle viste
In Query Processor di SQL Server le viste indicizzate e non indicizzate vengono gestite in modi diversi:
- Le righe di una vista indicizzata vengono archiviate nel database con lo stesso formato di una tabella. Se Query Optimizer decide di utilizzare una vista indicizzata in un piano di query, la vista indicizzata verrà gestita come una tabella di base.
- Viene archiviata solo la definizione di una vista indicizzata e non le righe della vista. Query Optimizer incorpora la logica della definizione della vista nel piano di esecuzione compilato per l'istruzione Transact-SQL che fa riferimento alla vista non indicizzata.
La logica usata da Query Optimizer di SQL Server per decidere quando usare una vista indicizzata è analoga alla logica usata per decidere quando impiegare un indice per una tabella. Se i dati della vista indicizzata coprono l'istruzione SQL in tutto o in parte e Query Optimizer identifica un indice della vista come percorso di accesso più economico, tale indice verrà scelto a prescindere dal fatto che nella query venga fatto o meno riferimento alla vista in questione.
Se un'istruzione Transact-SQL fa riferimento a una vista non indicizzata, il parser e Query Optimizer analizzano le origini dell'istruzione Transact-SQL e della vista e le risolvono quindi in un singolo piano di esecuzione. Il piano di esecuzione è lo stesso per l'istruzione Transact-SQL e per la vista.
Si consideri, ad esempio, la vista seguente:
USE AdventureWorks2022;
GO
CREATE VIEW EmployeeName AS
SELECT h.BusinessEntityID, p.LastName, p.FirstName
FROM HumanResources.Employee AS h
JOIN Person.Person AS p
ON h.BusinessEntityID = p.BusinessEntityID;
GO
In base a questa vista le due istruzioni Transact-SQL seguenti eseguono le stesse operazioni sulle tabelle di base e producono gli stessi risultati:
/* SELECT referencing the EmployeeName view. */
SELECT LastName AS EmployeeLastName, SalesOrderID, OrderDate
FROM AdventureWorks2022.Sales.SalesOrderHeader AS soh
JOIN AdventureWorks2022.dbo.EmployeeName AS EmpN
ON (soh.SalesPersonID = EmpN.BusinessEntityID)
WHERE OrderDate > '20020531';
/* SELECT referencing the Person and Employee tables directly. */
SELECT LastName AS EmployeeLastName, SalesOrderID, OrderDate
FROM AdventureWorks2022.HumanResources.Employee AS e
JOIN AdventureWorks2022.Sales.SalesOrderHeader AS soh
ON soh.SalesPersonID = e.BusinessEntityID
JOIN AdventureWorks2022.Person.Person AS p
ON e.BusinessEntityID =p.BusinessEntityID
WHERE OrderDate > '20020531';
La funzionalità Showplan di SQL Server Management Studio indica che il motore relazionale compila lo stesso piano di esecuzione per entrambe le istruzioni SELECT .
Usare hint con le viste
Gli hint inseriti nelle viste di una query possono entrare in conflitto con altri hint individuati quando la vista viene espansa in modo da accedere alle relative tabelle di base. In questo caso, la query restituisce un errore. Si consideri, ad esempio, la vista seguente nella cui definizione è contenuto un hint di tabella:
USE AdventureWorks2022;
GO
CREATE VIEW Person.AddrState WITH SCHEMABINDING AS
SELECT a.AddressID, a.AddressLine1,
s.StateProvinceCode, s.CountryRegionCode
FROM Person.Address a WITH (NOLOCK), Person.StateProvince s
WHERE a.StateProvinceID = s.StateProvinceID;
Si supponga a questo punto di immettere la query seguente:
SELECT AddressID, AddressLine1, StateProvinceCode, CountryRegionCode
FROM Person.AddrState WITH (SERIALIZABLE)
WHERE StateProvinceCode = 'WA';
La query ha esito negativo perché l'hint SERIALIZABLE applicato nella vista Person.AddrState della query viene propagato a entrambe le tabelle Person.Address e Person.StateProvince quando la vista viene espansa. L'espansione della vista consente anche di rilevare l'hint NOLOCK nella tabella Person.Address. Gli hint SERIALIZABLE e NOLOCK sono in conflitto tra loro, pertanto la query risultante non è corretta.
Gli hint delle tabelle PAGLOCK, NOLOCK, ROWLOCK, TABLOCKo TABLOCKX sono in conflitto tra loro, così come gli hint delle tabelle HOLDLOCK, NOLOCK, READCOMMITTED, REPEATABLEREADe SERIALIZABLE .
Gli hint possono propagarsi in più livelli di viste nidificate. Si supponga, ad esempio, una query che applica l'hint HOLDLOCK in una vista v1. Espandendo v1 , si noterà che la definizione di tale vista include la vista v2 , v2la cui definizione include a NOLOCK sua volta un hint in una delle tabelle di base. Questa tabella eredita anche l'hint HOLDLOCK dalla query sulla vista v1. Gli hint NOLOCK e HOLDLOCK sono in conflitto tra loro, pertanto la query ha esito negativo.
Quando si usa l'hint FORCE ORDER in una query che contiene una vista, l'ordine di join delle tabelle all'interno della vista dipende dalla posizione della vista nel costrutto ordinato. La query seguente, ad esempio, consente di selezionare da tre tabelle e una vista:
SELECT * FROM Table1, Table2, View1, Table3
WHERE Table1.Col1 = Table2.Col1
AND Table2.Col1 = View1.Col1
AND View1.Col2 = Table3.Col2;
OPTION (FORCE ORDER);
La vista View1 viene definita come illustrato di seguito:
CREATE VIEW View1 AS
SELECT Colx, Coly FROM TableA, TableB
WHERE TableA.ColZ = TableB.Colz;
L'ordine di join nel piano di query sarà quindi Table1, Table2, TableA, TableB, Table3.
Risolvere indici nelle viste
Come per qualsiasi indice, in SQL Server viene usata una vista indicizzata nel relativo piano di query solo se tramite Query Optimizer si determina che tale operazione è vantaggiosa.
Le viste indicizzate possono essere create con qualsiasi versione di SQL Server. In alcune edizioni di alcune versioni precedenti di SQL Server, Query Optimizer considera automaticamente la vista indicizzata. In alcune edizioni di alcune versioni precedenti di SQL Server, per usare una vista indicizzata è necessario usare l'hint della tabella NOEXPAND. Prima di SQL Server 2016 (13.x) Service Pack 1, l'uso automatico di una vista indicizzata in Query Optimizer era supportato solo in edizioni specifiche di SQL Server. Da allora, tutte le edizioni supportano l'uso automatico di una vista indicizzata. Database SQL di Azure e Istanza gestita di SQL di Azure supportano l'uso automatico di viste indicizzate senza specificare l'hint NOEXPAND.
Query Optimizer di SQL Server usa una vista indicizzata se vengono soddisfatte le condizioni seguenti:
- Le opzioni relative alla sessione indicate di seguito sono impostate su
ON:ANSI_NULLSANSI_PADDINGANSI_WARNINGSARITHABORTCONCAT_NULL_YIELDS_NULLQUOTED_IDENTIFIER
- L'opzione di sessione
NUMERIC_ROUNDABORTè impostata su OFF. - In Query Optimizer viene individuata una corrispondenza tra le colonne dell’indice della vista e gli elementi della query, tra cui:
- Predicati relativi a condizioni di ricerca nella clausola WHERE
- Operazioni di join
- Funzioni di aggregazione
- Clausole
GROUP BY - Riferimenti a tabelle
- Il costo stimato necessario per l'utilizzo dell'indice è inferiore a quello di qualsiasi altro meccanismo di accesso considerato in Query Optimizer.
- Ogni tabella a cui si fa riferimento nella query, direttamente oppure espandendo una vista per accedere alle tabelle sottostanti, corrispondente a un riferimento alla tabella nella vista indicizzata, deve disporre dello stesso set di hint ad essa applicato nella query.
Nota
Gli hint READCOMMITTED e READCOMMITTEDLOCK sono sempre considerati diversi in questo contesto, indipendentemente dal livello corrente di isolamento delle transazioni.
Ad eccezione dei requisiti relativi alle opzioni SET e agli hint di tabella, si tratta delle stesse regole usate da Query Optimizer per determinare se l'indice di una tabella copre una query. Per utilizzare una vista indicizzata, non è necessario specificare nient'altro nella query.
Non è necessario che una query faccia riferimento in modo esplicito a una vista indicizzata nella clausola FROM affinché Query Optimizer usi la vista indicizzata. Se la query include riferimenti alle colonne delle tabelle di base incluse anche nella vista indicizzata e tramite Query Optimizer si stima che l'utilizzo della vista indicizzata è il meccanismo di accesso più economico, in Query Optimizer viene scelta la vista indicizzata con modalità analoghe a quelle utilizzate per scegliere gli indici delle tabelle di base a cui non viene fatto riferimento diretto in una query. Query Optimizer può scegliere la vista quando include colonne a cui non fa riferimento la query a condizione che la vista stessa rappresenti la soluzione più economica ai fini della copertura di una o più colonne specificate nella query.
Query Optimizer elabora le viste indicizzate a cui fa riferimento la clausola FROM come viste standard. Tramite Query Optimizer la definizione della vista viene espansa nella query all'inizio del processo di ottimizzazione. Viene quindi eseguita la ricerca della corrispondenza nella vista indicizzata. La vista indicizzata può essere usata nel piano di esecuzione finale selezionato da Query Optimizer oppure il piano potrebbe ottenere dalla vista i dati necessari accedendo alle tabelle di base a cui fa riferimento la vista. Tramite Query Optimizer viene scelta l'alternativa con il costo inferiore.
Usare hint con viste indicizzate
È possibile impedire l'uso delle viste indicizzate da parte di una query usando l'hint per la query EXPAND VIEWS oppure è possibile usare l'hint di tabella NOEXPAND per fare in modo che venga impiegato un indice per una vista indicizzata specificata nella clausola FROM di una query. È tuttavia consigliabile lasciar determinare in modo dinamico a Query Optimizer i metodi di accesso migliori da utilizzare per ogni query. Limitare l'uso degli hint EXPAND e NOEXPAND a casi specifici per i quali si è verificato che in tal modo è possibile ottenere un miglioramento significativo delle prestazioni.
L'opzione
EXPAND VIEWSspecifica che in Query Optimizer non verranno usati indici delle viste per l'intera query.Se per una vista viene specificata l'opzione
NOEXPAND, tramite Query Optimizer viene valuta l'opportunità di usare gli indici definiti per la vista. Se l'opzioneNOEXPANDviene specificata con la clausolaINDEX()facoltativa, Query Optimizer userà gli indici specificati. L'opzioneNOEXPANDpuò essere specificata solo per le viste indicizzate e non è supportata per quelle non indicizzate. Prima di SQL Server 2016 (13.x) Service Pack 1, l'uso automatico di una vista indicizzata in Query Optimizer era supportato solo in edizioni specifiche di SQL Server. Da allora, tutte le edizioni supportano l'uso automatico di una vista indicizzata. Database SQL di Azure e Istanza gestita di SQL di Azure supportano l'uso automatico di viste indicizzate senza specificare l'hintNOEXPAND.
Quando non viene specificata né l'opzione NOEXPAND né EXPAND VIEWS in una query contenente una vista, la vista viene espansa per accedere alle tabelle sottostanti. Se la query che compone la vista contiene hint di tabella, tali hint vengono propagati alle tabelle sottostanti. Per altre informazioni su questo processo, vedere Risoluzione delle viste. Se i set di hint presenti nelle tabelle sottostanti della vista sono identici tra loro, la query può essere utilizzata per la ricerca della corrispondenza con una vista indicizzata. La maggior parte delle volte questi hint corrispondono tra loro in quanto vengono ereditati direttamente dalla vista. Se. tuttavia, la query fa riferimento a tabelle anziché a viste e gli hint applicati direttamente a tali tabelle non sono identici, la query non può essere utilizzata per il collegamento movimenti con una vista indicizzata. Se gli hint INDEX, PAGLOCK, ROWLOCK, TABLOCKX, UPDLOCK o XLOCK vengono applicati a tabelle a cui fa riferimento nella query dopo l'espansione della vista, tale query non può essere usata per il collegamento movimenti con una vista indicizzata.
Se un hint di tabella nel formato INDEX (index_val[ ,...n] ) fa riferimento a una vista in una query e non viene specificato anche l'hint NOEXPAND, l'hint per l'indice viene ignorato. Per specificare l'uso di un determinato indice, usare NOEXPAND.
In genere, quando Query Optimizer trova una corrispondenza tra una vista indicizzata e una query, eventuali hint specificati nelle tabelle o nelle viste nella query vengono applicati direttamente alla vista indicizzata. Se tramite Query Optimizer viene scelto di non utilizzare una vista indicizzata, eventuali hint vengono propagati direttamente alle tabelle a cui viene fatto riferimento nella vista. Per altre informazioni, vedere Risoluzione delle viste. Questa propagazione non riguarda gli hint di join, che vengono applicati solo nella relativa posizione originale nella query. Gli hint di join non vengono presi in considerazione da Query Optimizer durante il collegamento movimenti tra query e viste indicizzate. Se in un piano della query viene utilizzata una vista indicizzata che corrisponde a una parte di una query contenente un hint di join, tale hint non viene utilizzato nel piano.
Nelle definizioni delle viste indicizzate non sono consentiti hint. Nella modalità di compatibilità 80 e superiore, in SQL Server vengono ignorati gli hint contenuti nelle definizioni delle viste indicizzate quando ne viene eseguita la manutenzione oppure quando vengono eseguite query in cui sono usate viste indicizzate. Sebbene l'utilizzo di hint nelle definizioni delle viste indicizzate non comporti la generazione di un errore di sintassi nella modalità di compatibilità 80, gli hint vengono ignorati.
Per ulteriori informazioni, vedere Hint di tabella (Transact-SQL).
Risolvere viste partizionate distribuite
Query Processor di SQL Server ottimizza le prestazioni delle viste partizionate distribuite. Per le prestazioni delle viste partizionate distribuite, l'aspetto più importante è rappresentato dalla necessità di ridurre al minimo la quantità di dati trasferiti tra server membri.
In SQL Server vengono compilati piani dinamici e intelligenti che consentono di usare le query distribuite in modo efficiente ai fini dell'accesso ai dati di tabelle membro remote:
- Query Processor usa prima di tutto OLE DB per recuperare le definizioni del vincolo CHECK da ogni tabella membro. In questo modo, può eseguire il mapping della distribuzione dei valori di chiave in tutte le tabelle membro.
- Query Processor confronta gli intervalli di chiavi specificati nella clausola
WHEREdi un'istruzione Transact-SQL con la mappa in cui viene indicata la distribuzione delle righe nelle tabelle membro. Compila quindi un piano di esecuzione delle query che utilizza le query distribuite per recuperare solo le righe remote necessarie per completare l'istruzione Transact-SQL. Il piano di esecuzione viene compilato in modo che tutti gli accessi alle tabelle membro remote vengano rimandati al momento in cui vengono richieste le informazioni, indipendentemente dal fatto che si tratti di dati o metadati.
Si consideri, ad esempio, un sistema in cui la tabella Customers è partizionata tra Server1 (CustomerID da 1 a 3299999), Server2 (CustomerID da 3300000 a 6599999) e Server3 (CustomerID da 6600000 a 9999999).
Considerare quindi il piano di esecuzione compilato per la query eseguita in Server1:
SELECT *
FROM CompanyData.dbo.Customers
WHERE CustomerID BETWEEN 3200000 AND 3400000;
Il piano di esecuzione di questa query estrae dalla tabella membro locale le righe con valori di chiave CustomerID compresi tra 3200000 e 3299999 e quindi esegue una query distribuita per recuperare da Server2 le righe con valori di chiave compresi tra 3300000 e 3400000.
Query Processor di SQL Server può anche compilare una logica dinamica nei piani di esecuzione delle query per istruzioni Transact-SQL in cui i valori delle chiavi non sono noti al momento della compilazione del piano. Si consideri, ad esempio, la stored procedure seguente:
CREATE PROCEDURE GetCustomer @CustomerIDParameter INT
AS
SELECT *
FROM CompanyData.dbo.Customers
WHERE CustomerID = @CustomerIDParameter;
SQL Server non è in grado di determinare in anticipo quale valore della chiave verrà restituito dal parametro @CustomerIDParameter a ogni esecuzione della procedura. Pertanto, nemmeno Query Processor può prevedere a quale tabella membro si accederà. Per gestire questa situazione, SQL Server compila un piano di esecuzione che include una logica condizionale (ovvero filtri dinamici) in grado di determinare in base al valore del parametro di input a quale tabella membro si accederà. Se la stored procedure GetCustomer viene eseguita in Server1, la logica del piano di esecuzione può essere rappresentata nel modo seguente:
IF @CustomerIDParameter BETWEEN 1 and 3299999
Retrieve row from local table CustomerData.dbo.Customer_33
ELSE IF @CustomerIDParameter BETWEEN 3300000 and 6599999
Retrieve row from linked table Server2.CustomerData.dbo.Customer_66
ELSE IF @CustomerIDParameter BETWEEN 6600000 and 9999999
Retrieve row from linked table Server3.CustomerData.dbo.Customer_99
SQL Server compila a volte questi tipi di piani di esecuzione dinamici anche per query senza parametri. Query Optimizer può parametrizzare una query affinché il piano di esecuzione possa essere riutilizzato. Se Query Optimizer esegue la parametrizzazione di una query che fa riferimento a una vista partizionata, non potrà più basarsi sul presupposto che le righe necessarie verranno recuperate da una tabella di base specificata e dovrà utilizzare filtri dinamici nel piano di esecuzione.
Esecuzione di stored procedure e trigger
In SQL Server viene archiviata solo l'origine di stored procedure e trigger. Se una stored procedure o un trigger viene eseguito per la prima volta, l'origine viene compilata in un piano di esecuzione. Se la stored procedure o il trigger viene eseguito nuovamente prima che il piano di esecuzione venga rimosso dalla memoria, il motore relazionale rileva e riutilizza il piano esistente. Se il piano è stato rimosso dalla memoria, viene creato un nuovo piano. Questo processo è simile al processo che SQL Server segue per tutte le istruzioni Transact-SQL. Il vantaggio principale delle prestazioni di stored procedure e trigger in SQL Server rispetto ai batch di istruzioni Transact-SQL dinamiche è che le istruzioni Transact-SQL sono sempre uguali. pertanto, il motore relazionale mette agevolmente in corrispondenza con tutti i piani di esecuzione esistenti. I piani di stored procedure e trigger sono quindi facilmente riutilizzabili.
Il piano di esecuzione delle stored procedure e dei trigger viene eseguito indipendentemente dal piano di esecuzione del batch che chiama la stored procedure o che attiva il trigger. In tal modo viene garantito un maggiore riutilizzo dei piani di esecuzione delle stored procedure e dei trigger.
Memorizzazione nella cache e riutilizzo del piano di esecuzione
In SQL Server è presente un pool di memoria usato per archiviare sia i piani di esecuzione che i buffer dei dati. La percentuale del pool allocata ai piani di esecuzione o ai buffer dei dati varia dinamicamente in base allo stato del sistema. La parte del pool di memoria usata per archiviare i piani di esecuzione è denominata cache dei piani.
La cache dei piani ha due archivi per tutti i piani compilati:
- Archivio della cache di tipo Piani per gli oggetti usato per i piani correlati agli oggetti persistenti (stored procedure, funzioni e trigger).
- Archivio della cache di tipo Piani SQL usato per i piani correlati alle query con parametri automatici, dinamiche o preparate.
La query seguente fornisce informazioni sull'utilizzo della memoria per questi due archivi della cache:
SELECT * FROM sys.dm_os_memory_clerks
WHERE name LIKE '%plans%';
Nota
La cache dei piani ha due archivi aggiuntivi che non vengono usati per l'archiviazione dei piani:
- Archivio della cache di tipo Alberi associati usato per le strutture dei dati usate durante la compilazione di un piano per viste, vincoli e impostazioni predefinite. Queste strutture sono note come alberi associati o alberi di algebrizzazione.
- Archivio della cache di tipo Stored procedure estese usato per le procedure di sistema predefinite, ad esempio
sp_executeSqloxp_cmdshell, che vengono definite usando una DLL e non le istruzioni Transact-SQL. La struttura memorizzata nella cache contiene solo il nome della funzione e il nome della DLL in cui è implementata la procedura.
I piani di esecuzione di SQL Server includono i componenti principali seguenti:
Piano compilato (o piano di query)
Il piano di query generato dal processo di compilazione è per lo più una struttura dei dati rientrante di sola lettura usata da un numero qualsiasi di utenti. Archivia informazioni su:Operatori fisici che implementano l'operazione descritta dagli operatori logici.
Ordine di questi operatori, che determina l'ordine in cui i è possibile accedere ai dati, filtrarli e aggregarli.
Numero di righe stimate che passano attraverso gli operatori.
Nota
Nelle versioni più recenti del motore di database, vengono archiviate anche le informazioni sugli oggetti statistici usate per la Stima della cardinalità.
Oggetti di supporto da creare, ad esempio tabelle di lavoro o file di lavoro in
tempdb. Nel piano di query non vengono archiviate informazioni di contesto utente o di runtime. In memoria non vi sono mai più di una o due copie del piano della query: una copia per tutte le esecuzioni seriali e una per tutte le esecuzioni parallele. La copia parallela copre tutte le esecuzioni parallele, indipendentemente dal loro grado di parallelismo.
Contesto di esecuzione
Ogni utente che esegue la query dispone di una struttura di dati contenente i dati specifici per l'esecuzione, ad esempio i valori dei parametri. Questa struttura di dati è denominata contesto di esecuzione. Le strutture dei dati del contesto di esecuzione vengono riutilizzate, a differenza del contenuto. Se un altro utente esegue la stessa query, le strutture dei dati vengono reinizializzate con il contesto del nuovo utente.
Quando in SQL Server viene eseguita un'istruzione Transact-SQL, il motore di database esegue prima di tutto una ricerca nella cache dei piani per verificare la presenza di un piano di esecuzione esistente per la stessa istruzione Transact-SQL. L'istruzione Transact-SQL si qualifica come esistente se corrisponde letteralmente a un'istruzione Transact-SQL eseguita in precedenza con un piano memorizzato nella cache, carattere per carattere. Se viene trovato un piano, questo viene riutilizzato in SQL Server, consentendo di evitare l'overhead associato alla ricompilazione dell'istruzione Transact-SQL. Se non esiste un piano di esecuzione, in SQL Server viene generato un nuovo piano per la query.
Nota
I piani di esecuzione per alcune istruzioni Transact-SQL non sono persistenti nella cache dei piani, ad esempio le istruzioni per operazioni bulk in esecuzione su rowstore o le istruzioni contenenti valori letterali stringa di dimensioni superiori a 8 KB. Questi piani esistono solo mentre la query è in esecuzione.
In SQL Server è disponibile un algoritmo efficiente per l'individuazione di piani di esecuzione esistenti per una specifica istruzione Transact-SQL. Nella maggior parte dei sistemi, le risorse minime utilizzate da questa analisi sono inferiori a quelle risparmiate riutilizzando i piani esistenti anziché compilando ogni istruzione Transact-SQL.
Per gli algoritmi che consentono di trovare la corrispondenza tra le nuove istruzioni Transact-SQL e i piani di esecuzione esistenti inutilizzati nella cache dei piani, è necessario che i riferimenti agli oggetti siano completi. Ad esempio, si supponga che Person è lo schema predefinito per l'utente che esegue le istruzioni SELECT seguenti. In questo esempio non è necessario che la tabella Person sia completa per essere eseguita. Per la seconda istruzione non viene trovata una corrispondenza a un piano esistente, mentre per la terza viene trovata una corrispondenza:
USE AdventureWorks2022;
GO
SELECT * FROM Person;
GO
SELECT * FROM Person.Person;
GO
SELECT * FROM Person.Person;
GO
La modifica delle seguenti opzioni SET per una determinata esecuzione comprometterà la possibilità di riutilizzare i piani, perché il motore di database esegue l'elaborazione delle costanti in fase di compilazione e queste opzioni influiscono sui risultati di tali espressioni:
ANSI_NULL_DFLT_OFF
FORCEPLAN
ARITHABORT
DATEFIRST
ANSI_PADDING
NUMERIC_ROUNDABORT
ANSI_NULL_DFLT_ON
LANGUAGE
CONCAT_NULL_YIELDS_NULL
DATEFORMAT
ANSI_WARNINGS
QUOTED_IDENTIFIER
ANSI_NULLS
NO_BROWSETABLE
ANSI_DEFAULTS
Memorizzare più piani nella cache per la stessa query
Le query e i piani di esecuzione sono identificabili in modo univoco nel motore di database, proprio come un'impronta digitale:
- Per valore hash del piano di query si intende un valore hash binario calcolato sul piano di esecuzione per una determinata query che consente di identificare in modo univoco piani di esecuzioni analoghi.
- Per valore hash della query si intende un valore hash binario calcolato sul testo Transact-SQL di una query che consente di identificare in modo univoco le query.
Un piano compilato può essere recuperato dalla cache dei piani usando un handle di piani, ovvero un identificatore temporaneo che rimane costante solo mentre il piano è nella cache. L'handle di piani è un valore hash derivato dal piano compilato dell'intero batch. L'handle di piani per un piano compilato rimane invariato anche se una o più istruzioni nel batch vengono ricompilate.
Nota
Se un piano è stato compilato per un batch invece che per una singola istruzione, il piano per le istruzioni individuali del batch può essere recuperato usando l'handle di piani e gli offset delle istruzioni.
La vista DMV sys.dm_exec_requests contiene le colonne statement_start_offset e statement_end_offset per ogni record, che fanno riferimento all'istruzione attualmente in esecuzione di un batch attualmente in esecuzione o di un oggetto persistente. Per altre informazioni, vedere sys.dm_exec_requests (Transact-SQL).
Anche la vista DMV sys.dm_exec_query_stats contiene queste colonne per ogni record, che fanno riferimento alla posizione di un'istruzione all'interno di un batch o di un oggetto persistente. Per altre informazioni, vedere sys.dm_exec_query_stats (Transact-SQL).
Il testo Transact-SQL effettivo di un batch viene archiviato in uno spazio di memoria separato dalla cache dei piani, denominato cache SQL Manager (SQLMGR). Il testo Transact-SQL per un piano compilato può essere recuperato dalla cache SQL Manager usando un handle SQL, ovvero un identificatore temporaneo che rimane costante solo mentre almeno un piano che vi fa riferimento è nella cache dei piani. L'handle SQL è un valore hash derivato dal testo dell'intero batch ed è sicuramente univoco per ogni batch.
Nota
Come un piano compilato, il testo Transact-SQL viene archiviato per batch, inclusi i commenti. L'handle SQL contiene l'hash MD5 dell'intero batch ed è sicuramente univoco per ogni batch.
La query seguente fornisce informazioni sull'utilizzo della memoria per la cache SQL Manager:
SELECT * FROM sys.dm_os_memory_objects
WHERE type = 'MEMOBJ_SQLMGR';
Esiste una relazione 1:N tra un handle SQL e gli handle dei piani. Tale condizione si verifica quando la chiave della cache per i piani compilati è diversa. La causa potrebbe essere una modifica nelle opzioni SET tra due esecuzioni dello stesso batch.
Considerare la stored procedure seguente:
USE WideWorldImporters;
GO
CREATE PROCEDURE usp_SalesByCustomer @CID int
AS
SELECT * FROM Sales.Customers
WHERE CustomerID = @CID
GO
SET ANSI_DEFAULTS ON
GO
EXEC usp_SalesByCustomer 10
GO
Verificare il contenuto che è possibile trovare nella cache dei piani usando la query seguente:
SELECT cp.memory_object_address, cp.objtype, refcounts, usecounts,
qs.query_plan_hash, qs.query_hash,
qs.plan_handle, qs.sql_handle
FROM sys.dm_exec_cached_plans AS cp
CROSS APPLY sys.dm_exec_sql_text (cp.plan_handle)
CROSS APPLY sys.dm_exec_query_plan (cp.plan_handle)
INNER JOIN sys.dm_exec_query_stats AS qs ON qs.plan_handle = cp.plan_handle
WHERE text LIKE '%usp_SalesByCustomer%'
GO
Questo è il set di risultati.
memory_object_address objtype refcounts usecounts query_plan_hash query_hash
--------------------- ------- --------- --------- ------------------ ------------------
0x000001CC6C534060 Proc 2 1 0x3B4303441A1D7E6D 0xA05D5197DA1EAC2D
plan_handle
------------------------------------------------------------------------------------------
0x0500130095555D02D022F111CD01000001000000000000000000000000000000000000000000000000000000
sql_handle
------------------------------------------------------------------------------------------
0x0300130095555D02C864C10061AB000001000000000000000000000000000000000000000000000000000000
Eseguire ora la stored procedure con un parametro diverso, ma senza apportare altre modifiche al contesto di esecuzione:
EXEC usp_SalesByCustomer 8
GO
Verificare ancora il contenuto che è possibile trovare nella cache dei piani. Questo è il set di risultati.
memory_object_address objtype refcounts usecounts query_plan_hash query_hash
--------------------- ------- --------- --------- ------------------ ------------------
0x000001CC6C534060 Proc 2 2 0x3B4303441A1D7E6D 0xA05D5197DA1EAC2D
plan_handle
------------------------------------------------------------------------------------------
0x0500130095555D02D022F111CD01000001000000000000000000000000000000000000000000000000000000
sql_handle
------------------------------------------------------------------------------------------
0x0300130095555D02C864C10061AB000001000000000000000000000000000000000000000000000000000000
Si noti che il valore usecounts è salito a 2, il che significa che lo stesso piano memorizzato nella cache è stato riutilizzato senza modifiche, perché sono state riutilizzate le strutture dei dati del contesto di esecuzione. Modificare ora l'opzione SET ANSI_DEFAULTS ed eseguire la stored procedure usando lo stesso parametro.
SET ANSI_DEFAULTS OFF
GO
EXEC usp_SalesByCustomer 8
GO
Verificare ancora il contenuto che è possibile trovare nella cache dei piani. Questo è il set di risultati.
memory_object_address objtype refcounts usecounts query_plan_hash query_hash
--------------------- ------- --------- --------- ------------------ ------------------
0x000001CD01DEC060 Proc 2 1 0x3B4303441A1D7E6D 0xA05D5197DA1EAC2D
0x000001CC6C534060 Proc 2 2 0x3B4303441A1D7E6D 0xA05D5197DA1EAC2D
plan_handle
------------------------------------------------------------------------------------------
0x0500130095555D02B031F111CD01000001000000000000000000000000000000000000000000000000000000
0x0500130095555D02D022F111CD01000001000000000000000000000000000000000000000000000000000000
sql_handle
------------------------------------------------------------------------------------------
0x0300130095555D02C864C10061AB000001000000000000000000000000000000000000000000000000000000
0x0300130095555D02C864C10061AB000001000000000000000000000000000000000000000000000000000000
Si noti che ora nell'output DMV sys.dm_exec_cached_plans sono presenti due voci:
- La colonna
usecountscontiene il valore1nel primo record, relativo al piano eseguito una volta conSET ANSI_DEFAULTS OFF. - La colonna
usecountscontiene il valore2nel secondo record, relativo al piano eseguito conSET ANSI_DEFAULTS ON, perché è stato eseguito due volte. - Il diverso
memory_object_addresssi riferisce a un'altra voce del piano di esecuzione nella cache dei piani. Il valoresql_handleè tuttavia lo stesso per entrambe le voci perché fanno riferimento allo stesso batch.- L'esecuzione con
ANSI_DEFAULTSimpostato su OFF ha un nuovoplan_handlee può essere riutilizzata per le chiamate con lo stesso set di opzioni SET. Il nuovo handle del piano è necessario perché il contesto di esecuzione è stato reinizializzato a causa delle opzioni SET modificate. Non viene tuttavia attivata una ricompilazione perché entrambe le voci fanno riferimento allo stesso piano e alla stessa query, come indicato dai valoriquery_plan_hashequery_hash.
- L'esecuzione con
Ciò significa che nella cache sono presenti due voci del piano corrispondenti allo stesso batch ed evidenzia l'importanza di verificare che la cache dei piani che influisce sulle opzioni SET sia la stessa, quando le stesse query vengono eseguite ripetutamente, per ottimizzare il riutilizzo del piano e fare in modo che le dimensioni della cache dei piani siano sempre quelle minime necessarie.
Suggerimento
Un problema comune è che client diversi possono avere valori predefiniti diversi per le opzioni SET. Ad esempio, una connessione stabilita tramite SQL Server Management Studio imposta automaticamente QUOTED_IDENTIFIER su ON, mentre SQLCMD imposta QUOTED_IDENTIFIER su OFF. L'esecuzione delle stesse query da questi due client restituirà più piani (come illustrato nell'esempio precedente).
Rimuovere piani di esecuzione dalla cache dei piani
I piani di esecuzione rimangono nella cache dei piani fino a quando è disponibile memoria sufficiente per archiviarli. In caso di utilizzo elevato di memoria, il motore di database di SQL Server adotta un approccio basato sui costi per determinare i piani di esecuzione da rimuovere dalla cache delle procedure. Per prendere una decisione basata sui costi, il motore di database di SQL Server incrementa e decrementa una variabile relativa al costo corrente per ogni piano di esecuzione in base ai fattori descritti di seguito.
Quando un processo utente inserisce un piano di esecuzione nella cache, il costo corrente viene impostato sul costo di compilazione della query originale. Per i piani di esecuzione ad hoc, il processo utente imposta il costo corrente su zero. Quindi, ogni volta che un processo utente fa riferimento a un piano di esecuzione, il costo corrente viene reimpostato sul costo di compilazione originale. Per i piani di esecuzione ad hoc, il processo utente aumenta il costo corrente. Per tutti i piani, il valore massimo per il costo corrente corrisponde al costo di compilazione originale.
In caso di utilizzo elevato di memoria, il motore di database di SQL Server risponde rimuovendo i piani di esecuzione dalla cache delle procedure. Per determinare i piani da rimuovere, il motore di database di SQL Server esamina ripetutamente lo stato di ogni piano di esecuzione e rimuove i piani quando il relativo costo corrente è pari a zero. Un piano di esecuzione con un costo corrente pari a zero non viene rimosso automaticamente in caso di utilizzo elevato di memoria, ma viene rimosso solo nel momento in cui il motore di database di SQL Server esamina il piano e il costo corrente è pari a zero. Durante l'analisi di un piano di esecuzione attualmente non usato da una query, il motore di database di SQL Server decrementa il costo corrente fino a raggiungere il valore zero.
Il motore di database di SQL Server esamina ripetutamente i piani di esecuzione fino a quando non ne viene rimosso un numero sufficiente per soddisfare i requisiti di memoria. In caso di un numero eccessivo di richieste di memoria, è probabile che il costo di un piano di esecuzione venga incrementato e decrementato più di una volta. Quando l’utilizzo elevato di memoria diminuisce, il motore di database di SQL Server arresta la riduzione del costo corrente dei piani di esecuzione non usati e tutti i piani di esecuzione rimangono nella cache dei piani, anche se il costo relativo è pari zero.
Il motore di database di SQL Server usa il monitoraggio risorse e i thread di lavoro dell'utente per liberare memoria dalla cache dei piani in risposta a un numero eccessivo di richieste di memoria. Il monitoraggio risorse e i thread di lavoro dell'utente possono esaminare i piani in esecuzione simultanea per ridurre il costo corrente per ogni piano di esecuzione non usato. Il monitoraggio risorse rimuove i piani di esecuzione dalla cache dei piani quando è presente un numero eccessivo di richieste di memoria globale e libera memoria per applicare i criteri per la memoria di sistema, la memoria processi, la memoria del pool di risorse e la dimensione massima per tutte le cache.
Le dimensioni massime di tutte le cache sono rappresentate da una funzione relativa alle dimensioni del pool di buffer e non possono superare la memoria massima del server. Per altre informazioni sulla configurazione della memoria massima del server, vedere l'impostazione max server memory in sp_configure.
In caso di un numero eccessivo di richieste di memoria cache, i thread di lavoro dell'utente rimuovono i piani di esecuzione dalla cache dei piani e applicano i criteri per le dimensioni massime e per il numero massimo di voci della singola cache.
L'esempio seguente indica quali piani di esecuzione vengono rimossi dalla cache dei piani:
- A un piano di esecuzione viene fatto riferimento di frequente in modo che il costo non sia mai pari a zero. Il piano viene mantenuto nella cache dei piani e non viene rimosso a meno che non vi sia un utilizzo elevato di memoria e il costo corrente non sia pari a zero.
- Viene inserito un piano di esecuzione ad hoc, cui non viene fatto nuovamente riferimento prima che sia presente un utilizzo elevato di memoria. Dato che i piani ad hoc vengono inizializzati con un costo corrente pari a zero, quando il motore di database di SQL Server esamina il piano di esecuzione, individuerà il costo corrente pari a zero e rimuoverà il piano dalla cache dei piani. In assenza di un utilizzo elevato di memoria, il piano di esecuzione ad hoc viene mantenuto nella cache dei piani con un costo corrente pari a zero.
Per rimuovere manualmente un singolo piano o tutti i piani dalla cache, usare DBCC FREEPROCCACHE. DBCC FREESYSTEMCACHE può essere usato anche per cancellare qualsiasi cache, inclusa la cache dei piani. A partire da SQL Server 2016 (13.x), viene usata l'istruzione ALTER DATABASE SCOPED CONFIGURATION CLEAR PROCEDURE_CACHE per cancellare la cache (dei piani) delle procedure per il database nell'ambito.
Una modifica apportata ad alcune impostazioni di configurazione tramite sp_configure e riconfigure comporterà anche la rimozione dei piani dalla cache dei piani. È possibile trovare l'elenco di queste impostazioni di configurazione nella sezione Osservazioni dell'articolo DBCC FREEPROCCACHE. Per una modifica di configurazione di questo tipo verrà registrato il messaggio informativo seguente nel log degli errori:
SQL Server has encountered %d occurrence(s) of cachestore flush for the '%s' cachestore (part of plan cache) due to some database maintenance or reconfigure operations.
Ricompilare i piani di esecuzione
Alcune modifiche in un database possono provocare un piano di esecuzione inefficiente o non valido, in base al nuovo stato del database. SQL Server rileva le modifiche che rendono un piano di esecuzione non valido e contrassegna il piano come tale. Per la successiva connessione che esegue la query, pertanto, è necessaria la ricompilazione di un nuovo piano. Le condizioni che invalidano un piano includono le seguenti:
- Modifiche apportate a una tabella o a una vista a cui fa riferimento la query (
ALTER TABLEeALTER VIEW). - Modifiche apportate a una singola procedura, che elimina dalla cache tutti i piani relativi a questa procedura (
ALTER PROCEDURE). - Modifiche agli indici utilizzati dal piano di esecuzione.
- Aggiornamenti ai dati statistici usati dal piano di esecuzione, generati in modo esplicito da un'istruzione, ad esempio
UPDATE STATISTICS, o automaticamente. - Eliminazione di un indice utilizzato dal piano di esecuzione.
- Chiamata esplicita a
sp_recompile. - Grande quantità di modifiche alle chiavi, generate dalle istruzioni
INSERToDELETEeseguite da altri utenti che modificano una tabella a cui fa riferimento la query. - Nel caso di tabelle con trigger, aumento significativo del numero di righe della tabella inserite o eliminate.
- Esecuzione di una stored procedure usando l'opzione
WITH RECOMPILE.
La maggior parte delle ricompilazioni è necessaria per garantire la correttezza dell'istruzione o per ottenere piani di esecuzione della query potenzialmente più veloci.
Nelle versioni di SQL Server precedenti alla 2005, ogni volta che un'istruzione di un batch provoca la ricompilazione, viene ricompilato l'intero batch, a prescindere dal fatto che sia stato inviato usando una stored procedure, un trigger, un batch ad hoc o un'istruzione preparata. A partire da SQL Server 2005 (9.x), viene ricompilata solo l'istruzione all'interno del batch che ha attivato la ricompilazione. In SQL Server 2005 (9.x) e versioni successive, sono inoltre presenti altri tipi di ricompilazione perché il set di funzionalità è più ampio.
La ricompilazione a livello di istruzione consente di migliorare le prestazioni in quanto, nella maggior parte dei casi, le ricompilazioni e gli svantaggi associati, in termini di blocchi e tempo della CPU, sono dovuti a un piccolo numero di istruzioni. Questi svantaggi possono pertanto essere evitati per le altre istruzioni nel batch che non devono essere ricompilate.
L'evento esteso (XEvent) sql_statement_recompile indica le ricompilazioni a livello di istruzione. Questo XEvent viene generato quando qualsiasi tipo di batch richiede una ricompilazione a livello di istruzione, inclusi trigger, stored procedure, batch ad hoc e query. I batch possono essere inviati tramite varie interfacce, inclusi sp_executesql, SQL dinamico, metodi Prepare e metodi Execute.
La colonna recompile_cause dell'XEvent sql_statement_recompile contiene un codice integer che indica il motivo della ricompilazione. La tabella seguente include i motivi possibili:
Schema modificato
Statistiche modificate
Compilazione posticipata
Opzione SET modificata
Tabella temporanea modificata
Set di righe remoto modificato
AutorizzazioneFOR BROWSE modificata
Ambiente di notifica query modificato
Vista partizionata modificata
Opzioni cursore modificate
OPTION (RECOMPILE) richiesta.
Piano con parametri scaricato
Piano che influisce sulla versione del database modificato
Criteri di uso forzato del piano dell'archivio query modificati
Uso forzato del piano dell'archivio query non riuscito
Piano mancante nell'archivio query
Nota
Nelle versioni di SQL Server in cui non sono disponibili xEvent, è possibile usare l'evento di traccia SP:Recompile di SQL Server Profiler per lo stesso scopo, ovvero segnalare le ricompilazioni a livello di istruzione.
Anche l'evento di traccia SQL:StmtRecompile segnala le ricompilazioni a livello di istruzione e questo evento di traccia può essere usato anche per tenere traccia delle ricompilazioni ed eseguirne il debug.
Mentre SP:Recompile viene generato solo per stored procedure e trigger, SQL:StmtRecompile viene generato per stored procedure, trigger, batch ad hoc, batch eseguiti usando sp_executesql, query preparate e linguaggio SQL dinamico.
La colonna EventSubClass di SP:Recompile e SQL:StmtRecompile contiene un codice integer che indica il motivo della ricompilazione. I codici sono descritti qui.
Nota
Quando l'opzione di database AUTO_UPDATE_STATISTICS è impostata su ON, le query vengono ricompilate quando sono indirizzate a tabelle o viste indicizzate le cui statistiche sono state aggiornate o le cui cardinalità sono state modificate in modo significativo dall'ultima esecuzione.
Questo comportamento si applica alle tabelle standard definite dall'utente, alle tabelle temporanee e alle tabelle inserite ed eliminate, create dai trigger DML. Se le prestazioni delle query sono influenzate da un numero eccessivo di ricompilazioni, è possibile modificare l'impostazione su OFF. Quando l'opzione AUTO_UPDATE_STATISTICS del database è impostata su OFF, non vengono eseguite ricompilazioni in base alle statistiche o alle modifiche delle cardinalità, ad eccezione delle tabelle inserite ed eliminate create dai trigger DML INSTEAD OF. Poiché tali tabelle vengono create in tempdb, la ricompilazione delle query che vi accedono dipende dall'impostazione di AUTO_UPDATE_STATISTICS in tempdb.
Si noti che nelle versioni di SQL Server precedenti alla 2005, la ricompilazione delle query continua in base alle modifiche delle cardinalità delle tabelle inserite ed eliminate del trigger DML, anche quando l'impostazione è OFF.
Parametri e riutilizzo del piano di esecuzione
L'utilizzo dei parametri, inclusi i marcatori di parametro nelle applicazioni ADO, OLE DB e ODBC, può comportare un maggiore riutilizzo dei piani di esecuzione.
Avviso
L'uso di parametri o marcatori di parametro per includere i valori digitati dagli utenti offre una protezione maggiore rispetto alla concatenazione dei valori in una stringa eseguita usando un metodo API di accesso ai dati, l'istruzione EXECUTE o la stored procedure sp_executesql .
L'unica differenza tra le due istruzioni SELECT seguenti è rappresentata dai valori confrontati nella clausola WHERE :
SELECT *
FROM AdventureWorks2022.Production.Product
WHERE ProductSubcategoryID = 1;
SELECT *
FROM AdventureWorks2022.Production.Product
WHERE ProductSubcategoryID = 4;
L'unica differenza tra i piani di esecuzione delle due query è rappresentata dal valore archiviato per il confronto con la colonna ProductSubcategoryID . L'obiettivo principale di SQL Server consiste nel riconoscere sempre che le istruzioni generano essenzialmente lo stesso piano e nel riusare i piani, benché SQL Server a volte non lo rilevi per istruzioni Transact-SQL complesse.
La separazione delle costanti dall'istruzione Transact-SQL tramite i parametri consente al motore relazionale di riconoscere i piani duplicati. È possibile utilizzare i parametri come indicato di seguito:
In Transact-SQL, usare
sp_executesql:DECLARE @MyIntParm INT SET @MyIntParm = 1 EXEC sp_executesql N'SELECT * FROM AdventureWorks2022.Production.Product WHERE ProductSubcategoryID = @Parm', N'@Parm INT', @MyIntParmQuesto metodo è particolarmente adatto per gli script Transact-SQL, le stored procedure o i trigger che generano istruzioni SQL in modo dinamico.
ADO, OLE DB e ODBC utilizzano i marcatori di parametro. I marcatori di parametro sono punti interrogativi (?) che sostituiscono una costante in un'istruzione SQL e sono associati a una variabile di programma. In un'applicazione ODBC, ad esempio, verrebbero eseguite le operazioni seguenti:
Usare
SQLBindParameterper associare una variabile integer al primo marcatore di parametro di un'istruzione SQL.Inserire il valore intero nella variabile.
Eseguire l'istruzione specificando il marcatore di parametro (?):
SQLExecDirect(hstmt, "SELECT * FROM AdventureWorks2022.Production.Product WHERE ProductSubcategoryID = ?", SQL_NTS);
Il provider OLE DB di SQL Server Native Client e il driver ODBC di SQL Server Native Client inclusi in SQL Server usano
sp_executesqlper inviare istruzioni a SQL Server quando nelle applicazioni vengono usati marcatori di parametro.Progettare stored procedure, che utilizzano parametri per schema.
Se non si compilano parametri in modo esplicito nella progettazione dell'applicazione, è anche possibile basarsi su Query Optimizer di SQL Server per parametrizzare automaticamente query specifiche usando il comportamento predefinito di parametrizzazione semplice. In alternativa, è possibile forzare Query Optimizer affinché esegua la parametrizzazione di tutte le query nel database impostando l'opzione PARAMETERIZATION dell'istruzione ALTER DATABASE su FORCED.
Quando viene attivata la parametrizzazione forzata, la parametrizzazione semplice può essere comunque eseguita. La query seguente, ad esempio, non può essere parametrizzata in base alle regole di parametrizzazione forzata:
SELECT * FROM Person.Address
WHERE AddressID = 1 + 2;
La query può tuttavia essere parametrizzata in base alle regole di parametrizzazione semplice. Quando un tentativo di parametrizzazione forzata ha esito negativo, viene successivamente tentata la parametrizzazione semplice.
Parametrizzazione semplice
In SQL Server, l'uso di parametri o di marcatori di parametro nelle istruzioni di Transact-SQL consente di aumentare la capacità del motore relazionale di trovare una corrispondenza tra le nuove istruzioni Transact-SQL e i piani di esecuzione esistenti compilati in precedenza.
Avviso
L'uso di parametri o marcatori di parametro per includere i valori digitati dagli utenti offre una protezione maggiore rispetto alla concatenazione dei valori in una stringa eseguita usando un metodo API di accesso ai dati, l'istruzione EXECUTE o la stored procedure sp_executesql .
Se un'istruzione Transact-SQL viene eseguita senza parametri, in SQL Server l'istruzione viene parametrizzata a livello interno per aumentare la possibilità di trovare una corrispondenza con un piano di esecuzione esistente. Questo processo viene definito parametrizzazione semplice. Nelle versioni di SQL Server precedenti alla 2005, il processo è definito parametrizzazione automatica.
Considerare l'istruzione seguente:
SELECT * FROM AdventureWorks2022.Production.Product
WHERE ProductSubcategoryID = 1;
Il valore 1 alla fine dell'istruzione può essere specificato come parametro. Tramite il motore relazionale compilato il piano di esecuzione per questo batch come se fosse stato specificato un parametro al posto del valore 1. Grazie a questa semplice parametrizzazione, in SQL Server viene riconosciuto che le due istruzioni seguenti generano essenzialmente lo stesso piano di esecuzione e il primo piano viene riutilizzato per la seconda istruzione:
SELECT * FROM AdventureWorks2022.Production.Product
WHERE ProductSubcategoryID = 1;
SELECT * FROM AdventureWorks2022.Production.Product
WHERE ProductSubcategoryID = 4;
Durante l'elaborazione di istruzioni Transact-SQL complesse, è possibile che il motore relazionale incontri difficoltà nel determinare le espressioni che è possibile parametrizzare. Per aumentare la capacità del motore relazionale di associare istruzioni Transact-SQL complesse ai piani di esecuzione esistenti inutilizzati, specificare in modo esplicito i parametri usando sp_executesql o i marcatori di parametro.
Nota
Quando vengono usati gli operatori aritmetici +, -, *, / o % per eseguire una conversione implicita o esplicita di valori costanti int, smallint, tinyint o bigint in tipi di dati float, real, decimal o numeric, in SQL Server vengono applicate regole specifiche per calcolare il tipo e la precisione dei risultati dell'espressione. Queste regole, tuttavia, variano in base al fatto che la query includa o meno parametri. Espressioni simili nelle query possono pertanto in alcuni casi generare risultati diversi.
In base al comportamento predefinito della parametrizzazione semplice, in SQL Server viene parametrizzato un numero relativamente piccolo di query. È tuttavia possibile fare in modo che tutte le query in un database vengano parametrizzate, rispettando determinate limitazioni, impostando l'opzione PARAMETERIZATION del comando ALTER DATABASE su FORCED. In questo modo, è possibile migliorare le prestazioni dei database in cui viene eseguito un numero elevato di query simultanee riducendo la frequenza di compilazione delle query.
In alternativa, è possibile specificare la parametrizzazione di una singola query e di tutte le altre con sintassi equivalente ma che differiscono solo per i valori dei parametri.
Suggerimento
Quando si usa una soluzione ORM (Object-Relational Mapping) come Entity Framework (EF), le query dell'applicazione come alberi di query LINQ manuali o alcune query SQL non elaborate potrebbero non essere parametrizzate, il che influisce sul riutilizzo del piano e sulla possibilità di rilevare le query in Query Store. Per altre informazioni, consultare Memorizzazione nella cache e parametrizzazione delle query EF e Query SQL non elaborate EF.
Parametrizzazione forzata
È possibile ignorare il comportamento predefinito parametrizzazione semplice di SQL Server specificando la parametrizzazione di tutte le istruzioni SELECT, INSERT, UPDATEe DELETE di un database in base a limiti specifici. La parametrizzazione forzata viene attivata impostando l'opzione PARAMETERIZATION su FORCED nell'istruzione ALTER DATABASE . La parametrizzazione forzata potrebbe offrire un miglioramento delle prestazioni di alcuni database riducendo la frequenza delle operazioni di compilazione e ricompilazione delle query. I database che potrebbero essere soggetti a un miglioramento delle prestazione grazie alla parametrizzazione forzata sono in genere quelli che ricevono volumi elevati di query simultanee da origini quali le applicazioni POS.
Quando l'opzione PARAMETERIZATION è impostata su FORCED, qualsiasi valore letterale visualizzato in un'istruzione SELECT, INSERT, UPDATEo DELETE , inviato in qualsiasi forma, viene convertito in un parametro durante la compilazione delle query. Le eccezioni consistono in valori letterali presenti nei costrutti di query seguenti:
- Istruzioni
INSERT...EXECUTE. - Istruzioni all'interno del corpo di stored procedure, trigger o funzioni definite dall'utente. SQL Server riutilizza già piani di query per tali routine.
- Istruzioni preparate già parametrizzate nell'applicazione sul lato client.
- Istruzioni contenenti chiamate al metodo XQuery, in cui il metodo appare in un contesto in cui i relativi argomenti verrebbero in genere parametrizzati, ad esempio una clausola
WHERE. Se il metodo appare in un contesto in cui i relativi argomenti non verrebbero parametrizzati, il resto dell'istruzione viene parametrizzato. - Istruzioni all'interno di un cursore Transact-SQL. Le istruzioni
SELECTall'interno dei cursori API vengono parametrizzate. - Costrutti di query deprecati.
- Qualsiasi istruzione che viene eseguita nel contesto di
ANSI_PADDINGoANSI_NULLSimpostata suOFF. - Istruzioni contenenti oltre 2.097 valori letterali idonei per la parametrizzazione.
- Istruzioni che fanno riferimento a variabili, ad esempio
WHERE T.col2 >= @bb. - Istruzioni contenenti l'hint per la query
RECOMPILE. - Istruzioni contenenti una clausola
COMPUTE. - Istruzioni contenenti una clausola
WHERE CURRENT OF.
Inoltre, le seguenti clausole di query non vengono parametrizzate. In questi casi, soltanto le clausole non vengono parametrizzate. Altre clausole all'interno della stessa query possono essere idonee per la parametrizzazione forzata.
- <select_list> di qualsiasi istruzione
SELECT. Ciò include elenchiSELECTdelle sottoquery ed elenchiSELECTall'interno delle istruzioniINSERT. - Istruzioni
SELECTdelle sottoquery incluse in un'istruzioneIF. - Clausole
TOP,TABLESAMPLE,HAVING,GROUP BY,ORDER BY,OUTPUT...INTOoFOR XMLdi una query. - Argomenti, diretti o sottoespressioni, a
OPENROWSET,OPENQUERY,OPENDATASOURCE,OPENXMLo qualsiasi operatoreFULLTEXT. - Argomenti pattern ed escape_character di una clausola
LIKE. - Argomento style di una clausola
CONVERT. - Costante integer all'interno di una clausola
IDENTITY. - Costanti specificate utilizzando la sintassi delle estensioni ODBC.
- Espressioni per le quali è possibile eseguire l'elaborazione delle costanti in fase di compilazione che rappresentano argomenti degli operatori
+,-,*,/e%. Quando viene valutata l'idoneità per la parametrizzazione forzata, in SQL Server un'espressione viene considerata come idonea per l'elaborazione delle costanti in fase di compilazione quando si verificano le condizioni seguenti:- Nell'espressione non è inclusa alcuna colonna, variabile o subquery.
- L'espressione contiene una clausola
CASE.
- Argomenti delle clausole degli hint per le query. Sono inclusi l'argomento number_of_rows dell'hint per la query
FAST, l'argomento number_of_processors dell'hint per la queryMAXDOPe l'argomento number dell'hint per la queryMAXRECURSION.
La parametrizzazione viene eseguita a livello di singole istruzioni Transact-SQL. In altri termini, vengono parametrizzate le singole istruzioni presenti in un batch. In seguito alla compilazione, una query con parametri viene eseguita nel contesto del batch in cui è stata inviata originariamente. Se un piano di esecuzione per una query viene memorizzato nella cache, è possibile determinare se è stata eseguita la parametrizzazione della query facendo riferimento alla colonna sql della vista a gestione dinamica sys.syscacheobjects. Se è stata eseguita la parametrizzazione di una query, i nomi e i tipi di dati dei parametri precedono il testo del batch inviato nella colonna, ad esempio @1 tinyint.
Nota
I nomi dei parametri sono arbitrari. Gli utenti o le applicazioni non devono basarsi su un ordine di denominazione specifico. È anche possibile che nomi dei parametri, scelta dei valori letterali con parametri e spaziatura nel testo con parametri cambino tra le versioni di SQL Server e gli aggiornamenti dei Service Pack.
Tipi di dati dei parametri
Quando in SQL Server vengono parametrizzati valori letterali, i parametri vengono convertiti nei tipi di dati seguenti:
- I valori letterali interi le cui dimensioni altrimenti si adatterebbero al tipo di dati int vengono parametrizzati in int. I valori letterali interi di dimensioni maggiori inclusi in predicati che comportano qualsiasi operatore di confronto, tra cui
<,<=,=,!=,>,>=,!<,!>,<>,ALL,ANY,SOME,BETWEENeIN, vengono parametrizzati in numeric(38,0). I valori letterali di dimensioni maggiori non inclusi in predicati che comportano operatori di confronto vengono parametrizzati in numeric, la cui precisione è tale da supportarne le dimensioni e il cui valore di scala è 0. - I valori letterali numerici a virgola fissa inclusi in predicati che comportano operatori di confronto vengono parametrizzati in numeric con precisione 38 e valore di scala tale da supportarne le dimensioni. I valori letterali numerici a virgola fissa non inclusi in predicati che comportano operatori di confronto vengono parametrizzati in numeric con precisione e valore di scala tali da supportarne le dimensioni.
- I valori letterali numerici a virgola mobile vengono parametrizzati in float(53).
- I valori letterali stringa vengono parametrizzati in varchar(8000) se il valore letterale non supera gli 8000 caratteri e in varchar(max) se è maggiore di 8000 caratteri.
- I valori letterali stringa vengono parametrizzati in nvarchar(4000) se il valore letterale non supera i 4000 caratteri e in nvarchar(max) se è maggiore di 4000 caratteri.
- I valori letterali binari vengono parametrizzati in varbinary(8000) se il valore letterale non supera gli 8000 byte. Se il valore letterale è maggiore di 8000 byte, viene convertito in varbinary(max).
- I valori letterali di tipo money vengono parametrizzati in money.
Linee guida per l'utilizzo della parametrizzazione forzata
Quando si desidera impostare l'opzione PARAMETERIZATION su FORCED, considerare gli aspetti seguenti:
- Tramite la parametrizzazione forzata, in pratica, le costanti letterali incluse in una query vengono modificate in parametri durante la compilazione di una query. È pertanto probabile che in Query Optimizer vengano scelti piani non ottimali per le query. In particolare, è meno probabile che Query Optimizer associ la query a una vista indicizzata o a un indice in una colonna calcolata. Potrebbero inoltre essere scelti piani non ottimali per le query formulate nelle tabelle partizionate e nelle viste partizionate distribuite. Non utilizzare la parametrizzazione forzata negli ambienti basati in modo significativo su viste indicizzate e indici in colonne calcolate. In generale l'opzione
PARAMETERIZATION FORCEDdeve essere usata solo da amministratori di database esperti dopo avere determinato che le prestazioni non subiranno alcun impatto negativo. - Le query distribuite che fanno riferimento a più di un database sono idonee per la parametrizzazione forzata a condizione che l'opzione
PARAMETERIZATIONsia impostata suFORCEDnel database nel cui contesto viene eseguita la query. - L'impostazione dell'opzione
PARAMETERIZATIONsuFORCEDconsente di scaricare tutti i piani di query dalla cache dei piani del database, ad eccezione di quelli di cui è in corso la compilazione, la ricompilazione o l'esecuzione. I piani per le query di cui è in corso la compilazione o l'esecuzione durante la modifica dell'impostazione verranno parametrizzati alla successiva esecuzione della query. - L'impostazione dell'opzione
PARAMETERIZATIONè un'operazione online che richiede che non vi sia alcun blocco esclusivo a livello del database. - L'impostazione corrente dell'opzione
PARAMETERIZATIONviene mantenuta quando un database viene ricollegato o ripristinato.
È possibile ignorare il comportamento della parametrizzazione forzata specificando che su una singola query, e su qualsiasi altra query sintatticamente equivalente ma che differisca solo nei valori dei parametri, venga eseguita la parametrizzazione semplice. Viceversa è possibile specificare che la parametrizzazione forzata venga tentata solo su un set di query sintatticamente equivalenti, anche se disabilitata nel database. A tale scopo, vengono usate leguide di piano .
Nota
Quando l'opzione PARAMETERIZATION è impostata su FORCED, la segnalazione dei messaggi di errore potrebbe presentare differenze rispetto a quando l'opzione PARAMETERIZATION è impostata su SIMPLE: potrebbero segnalati più messaggi di errore nei casi di parametrizzazione forzata, laddove sarebbe segnalato un numero di messaggi di errore inferiore in nei casi di parametrizzazione semplice e i numeri di riga nei quali si sono verificati gli errori potrebbero non essere segnalati correttamente.
Preparare le istruzioni SQL
Il motore relazionale di SQL Server offre supporto completo per la preparazione di istruzioni Transact-SQL prima della relativa esecuzione. Se in un'applicazione è necessario eseguire più volte un'istruzione Transact-SQL, è possibile utilizzare l'API di database per:
- Preparare l'istruzione una sola volta. L'istruzione Transact-SQL viene compilata in un piano di esecuzione.
- Eseguire il piano di esecuzione precompilato ogni volta che è necessario eseguire l'istruzione. In questo modo, si evita di ricompilare l'istruzione Transact-SQL a ogni esecuzione dopo la prima volta. La preparazione e l'esecuzione delle istruzioni è controllata dalle funzioni e dai metodi dell'API. Non è inclusa nel linguaggio Transact-SQL. Il modello di preparazione/esecuzione per l'esecuzione di istruzioni Transact-SQL è supportato dal Provider OLE DB Native Client di SQL Server e dal driver ODBC Native Client di SQL Server. A una richiesta di preparazione, il provider o il driver invia l'istruzione a SQL Server con una richiesta di preparazione dell'istruzione. SQL Server compila un piano di esecuzione e restituisce un handle del piano al provider o al driver. Alla richiesta di esecuzione, il provider o il driver invia al server una richiesta di esecuzione del piano associato all'handle.
Le istruzioni preparate non possono essere usate per creare oggetti temporanei in SQL Server. Nelle istruzioni preparate, infatti, non è consentito fare riferimento a stored procedure di sistema che creano oggetti temporanei, ad esempio tabelle temporanee. Tali procedure devono essere eseguite in modo diretto.
L'utilizzo eccessivo del modello di preparazione/esecuzione può determinare un peggioramento delle prestazioni. Se un'istruzione viene eseguita una sola volta, è sufficiente l'esecuzione diretta, che richiede un solo ciclo di andata e ritorno in rete per il server. La preparazione e l'esecuzione di un'istruzione Transact-SQL che viene eseguita una sola volta richiedono un ciclo di andata e ritorno in rete aggiuntivo (uno per preparare l'istruzione e uno per eseguirla).
È possibile preparare un'istruzione in modo più efficiente utilizzando i marcatori di parametro. Si supponga, ad esempio, che a un'applicazione venga richiesto occasionalmente di recuperare informazioni sui prodotti dal database di esempio AdventureWorks . L'applicazione può eseguire questa operazione in due modi diversi.
L'applicazione può innanzitutto eseguire una query distinta per ogni prodotto richiesto:
SELECT * FROM AdventureWorks2022.Production.Product
WHERE ProductID = 63;
Altrimenti, l'applicazione può eseguire le operazioni seguenti:
Preparare un'istruzione contenente un marcatore di parametro (?):
SELECT * FROM AdventureWorks2022.Production.Product WHERE ProductID = ?;Associare una variabile di programma al marcatore di parametro.
A ogni richiesta di informazioni sul prodotto, inserire nella variabile associata il valore di chiave ed eseguire l'istruzione.
Il secondo metodo è più efficiente se l'istruzione viene eseguita più di tre volte.
In SQL Server, il modello di preparazione/esecuzione non presenta alcun vantaggio significativo per le prestazioni rispetto all'esecuzione diretta, a causa della modalità in cui SQL Server riutilizza i piani di esecuzione. SQL Server ha algoritmi efficienti per la corrispondenza di istruzioni Transact-SQL correnti con i piani di esecuzione generati per esecuzioni precedenti della stessa istruzione Transact-SQL. Se un'applicazione esegue più volte un'istruzione Transact-SQL con marcatori di parametro, SQL Server riutilizzerà il piano di esecuzione della prima esecuzione per la seconda e le successive esecuzioni, a meno che il piano non venga rimosso per invalidità dalla cache dei piani. Il modello di preparazione/esecuzione presenta comunque i vantaggi seguenti:
- È più conveniente cercare un piano di esecuzione tramite un handle di identificazione che non utilizzare gli algoritmi per trovare una corrispondenza tra un'istruzione Transact-SQL e i piani di esecuzione esistenti.
- L'applicazione può controllare il momento della creazione del piano di esecuzione e del suo riutilizzo.
- Il modello di preparazione/esecuzione è utilizzabile con altri database, incluse le versioni precedenti di SQL Server.
Sensibilità ai parametri
Il termine "sensibilità ai parametri", noto anche come "analisi dei parametri", si riferisce a un processo in base al quale SQL Server individua i valori dei parametri correnti durante la compilazione o la ricompilazione e li passa a Query Optimizer in modo che possano essere usati per generare piani di esecuzione di query potenzialmente più efficienti.
I valori dei parametri vengono individuati durante la compilazione o ricompilazione per i seguenti tipi di batch:
- Stored procedure
- Query inviate tramite
sp_executesql - Query preparate
Per ulteriori informazioni sulla risoluzione dei problemi di analisi dei parametri, vedere:
- Analizzare e risolvere i problemi sensibili ai parametri
- Parametri e riutilizzo del piano di esecuzione
- Ottimizzazione del piano sensibile ai parametri
- Risolvere i problemi relativi ai piani di esecuzione delle query sensibili ai parametri nel database SQL di Azure
- Risolvere i problemi relativi ai piani di esecuzione delle query sensibili ai parametri nell’Istanza gestita di SQL di Azure
Nota
Per le query che usano l'hint RECOMPILE, vengono individuati sia i valori dei parametri che i valori correnti delle variabili locali. I valori individuati (dei parametri e delle variabili locali) sono quelli esistenti nella posizione all'interno del batch prima dell'istruzione con l'hint RECOMPILE. In particolare, per i parametri, non vengono individuati i valori passati con la chiamata del batch.
Elaborazione parallela di query
In SQL Server è possibile eseguire query parallele, che consentono di ottimizzare l'esecuzione delle query e le operazioni sugli indici nei computer che dispongono di più microprocessori (CPU). La possibilità di eseguire una query o un'operazione sugli indici in parallelo in SQL Server usando diversi thread di lavoro del sistema operativo assicura maggiore velocità ed efficienza.
Durante l'ottimizzazione delle query, SQL Server ricerca le query o le operazioni sugli indici che potrebbero trarre vantaggio dall'esecuzione parallela. Nel piano di esecuzione di tali query SQL Server inserisce operatori di scambio per preparare la query all'esecuzione parallela. Un operatore di scambio è un operatore del piano di esecuzione della query responsabile della gestione dei processi, della ridistribuzione dei dati e del controllo di flusso. L'operatore di scambio include gli operatori logici Distribute Streams, Repartition Streamse Gather Streams come sottotipi, ognuno dei quali può essere incluso nell'output Showplan del piano di esecuzione parallela di una query.
Importante
Alcuni costrutti impediscono a SQL Server di utilizzare il parallelismo nell'intero piano di esecuzione o in parti del piano di esecuzione.
I costrutti che impediscono il parallelismo includono:
Funzioni definite dall'utente scalari
Per altre informazioni sulle funzioni definite dall'utente scalari, vedere Creare funzioni definite dall'utente. A partire da SQL Server 2019 (15.x), il motore di database di SQL Server può eseguire l'inline di queste funzioni e sbloccare l'uso del parallelismo durante l'elaborazione delle query. Per altre informazioni sull'inlining di funzioni definite dall'utente scalari, vedere Elaborazione di query intelligenti.Remote Query
Per altre informazioni su Remote Query, vedere Guida di riferimento a operatori Showplan logici e fisici.Cursori dinamici
Per altre informazioni sui cursori, vedere DECLARE CURSOR.Query ricorsive
Per altre informazioni sulla ricorsione, vedere Linee guida per la definizione e l'utilizzo delle espressioni di tabella comuni ricorsive e Recursion in T-SQL (Ricorsione in T-SQL).Funzioni con valori di tabella con istruzioni multiple (MSTVF)
Per altre informazioni sulle funzioni con valori di tabella con istruzioni multiple (MSTVF), vedere Creazione di funzioni definite dall'utente (Motore di database).Parola chiave TOP
Per altre informazioni, vedere TOP (Transact-SQL).
Un piano di esecuzione delle query può contenere l'attributo NonParallelPlanReason nell'elemento QueryPlan che descrive il motivo per cui non è stato usato il parallelismo. I valori per questo attributo sono:
| Valore NonParallelPlanReason | Descrizione |
|---|---|
| MaxDOPSetToOne | Massimo grado di parallelismo impostato su 1. |
| EstimatedDOPIsOne | Grado di parallelismo stimato pari a 1. |
| NoParallelWithRemoteQuery | Parallelismo non supportato per le query remote. |
| NoParallelDynamicCursor | Piani paralleli non supportati per i cursori dinamici. |
| NoParallelFastForwardCursor | Piani paralleli non supportati per i cursori fast forward. |
| NoParallelCursorFetchByBookmark | Piani paralleli non supportati per i cursori che eseguono il recupero tramite segnalibro. |
| NoParallelCreateIndexInNonEnterpriseEdition | Creazione di indici paralleli non supportata per edizioni diverse da Enterprise Edition. |
| NoParallelPlansInDesktopOrExpressEdition | Piani paralleli non supportati per Desktop Edition ed Express Edition. |
| NonParallelizableIntrinsicFunction | Query con riferimenti a una funzione intrinseca non parallelizzabile. |
| CLRUserDefinedFunctionRequiresDataAccess | Parallelismo non supportato per una funzione CLR definita dall'utente che richiede l'accesso ai dati. |
| TSQLUserDefinedFunctionsNotParallelizable | Query con riferimenti a una funzione T-SQL definita dall'utente non parallelizzabile. |
| TableVariableTransactionsDoNotSupportParallelNestedTransaction | Transazioni annidate parallele non supportate dalle transazioni di variabili di tabella. |
| DMLQueryReturnsOutputToClient | Query DML che restituisce l'output al client e non è parallelizzabile. |
| MixedSerialAndParallelOnlineIndexBuildNotSupported | Combinazione non supportata di piani seriali e paralleli per una singola compilazione indice online. |
| CouldNotGenerateValidParallelPlan | Verifica del piano parallelo non superata. Failback al piano seriale. |
| NoParallelForMemoryOptimizedTables | Parallelismo non supportato per le tabelle OLTP in memoria a cui si fa riferimento. |
| NoParallelForDmlOnMemoryOptimizedTable | Parallelismo non supportato per DML in una tabella OLTP in memoria. |
| NoParallelForNativelyCompiledModule | Parallelismo non supportato per i moduli compilati in modo nativo a cui si fa riferimento. |
| NoRangesResumableCreate | Generazione dell'intervallo non riuscita per un'operazione di creazione ripristinabile. |
Dopo l'inserimento degli operatori di scambio, si ottiene un piano di esecuzione parallela della query. Questo tipo di piano può usare più di un thread di lavoro. In un piano di esecuzione seriale, usato da una query non parallela (seriale), l'esecuzione è invece affidata a un solo thread di lavoro. Il numero effettivo di thread di lavoro usati da una query parallela viene determinato al momento dell'inizializzazione del piano di esecuzione della query e dipende dalla complessità del piano e dal grado di parallelismo.
Il grado di parallelismo (DOP) determina il numero massimo di CPU usate, ma non il numero di thread di lavoro usati. Il limite DOP viene impostato per task. Non è un limite per richiesta o per query. Ciò significa che durante l'esecuzione di query parallele, una singola richiesta può generare più task che vengono assegnate a un pianificatore. Un numero maggiore di processori rispetto a quello specificato da MAXDOP potrebbe essere usato contemporaneamente in un determinato punto di esecuzione delle query, quando vengono eseguite contemporaneamente attività diverse. Per altre informazioni, vedere Guida sull'architettura dei thread e delle attività.
Quando una qualsiasi delle condizioni seguenti è vera, Query Optimizer di SQL Server non usa un piano di esecuzione parallela per una query:
- Il piano di esecuzione seriale è semplice o non supera la soglia di costo per l'impostazione di parallelismo.
- Il piano di esecuzione seriale ha un costo del sottoalbero stimato inferiore rispetto a qualsiasi piano di esecuzione parallela esplorato dall'ottimizzatore.
- La query contiene operatori scalari o relazionali che non possono essere eseguiti in parallelo. Alcuni operatori possono richiedere l'esecuzione seriale di una sezione della query o dell'intero piano.
Nota
Il costo totale stimato del sottoalbero di un piano parallelo può essere inferiore alla soglia di costo per l'impostazione di parallelismo. Ciò indica che il costo totale stimato del sottoalbero del piano seriale lo ha superato e che è stato scelto il piano di query con il costo stimato del sottoalbero inferiore.
Grado di parallelismo (DOP)
SQL Server rileva automaticamente il grado di parallelismo ottimale per ogni istanza di esecuzione parallela di una query o di operazione DDL sull'indice, utilizzando i criteri seguenti:
Esecuzione di SQL Server in un computer con più microprocessori o CPU, ad esempio un computer SMP (Symmetric Multiprocessing). Solo i computer con più CPU possono utilizzare le query parallele.
Se è disponibile di un numero sufficiente di thread di lavoro. Per l'esecuzione di una query o di un'operazione su un indice è necessario un numero specifico di thread di lavoro. L'esecuzione di un piano parallelo richiede un numero di thread di lavoro maggiore rispetto all'esecuzione di un piano seriale e il numero di thread di lavoro necessari aumenta con il grado di parallelismo. Se non è possibile rispettare i requisiti di thread di lavoro del piano parallelo per un grado di parallelismo specifico, il motore di database di SQL Server riduce automaticamente il grado di parallelismo o ignora completamente il piano parallelo nel contesto del carico di lavoro specificato. ed esegue il piano seriale (un solo thread di lavoro).
Tipo di query o di operazione sull'indice eseguita. Le operazioni di creazione o ricompilazione di un indice o di eliminazione di un indice cluster e le query che utilizzano molte risorse CPU sono candidate ideali per un piano parallelo. Esempi di operazioni di questo tipo sono i join di tabelle di grandi dimensioni, le aggregazioni di ampia portata e gli ordinamenti di set di risultati estesi. Nel caso di query semplici, spesso presenti nelle applicazioni di elaborazione delle transazioni, il coordinamento aggiuntivo necessario per eseguire una query in parallelo viene compensato dal potenziale miglioramento delle prestazioni. Per distinguere le query che possono trarre vantaggio dal parallelismo o meno, il motore di database di SQL Server confronta il costo stimato per l'esecuzione della query o dell'operazione sull'indice con il valore soglia costo per parallelismo. È possibile modificare il valore predefinito di 5 usando sp_configure se da un test appropriato risulta che è preferibile usare un valore diverso per il carico di lavoro in esecuzione.
Presenza di un numero sufficiente di righe da elaborare. Se Query Optimizer determina che il numero di righe di un flusso è troppo basso, non introduce gli operatori di scambio per la distribuzione delle righe. Gli operatori vengono pertanto eseguiti in modo seriale, evitando così le situazioni in cui il costo di avvio, distribuzione e coordinamento supera i vantaggi ottenuti tramite l'esecuzione parallela dell'operatore.
Disponibilità di statistiche di distribuzione correnti. Se il grado di parallelismo massimo non è disponibile, prima di abbandonare il piano parallelo vengono considerati i gradi inferiori. Ad esempio, quando si crea un indice cluster in una vista, non è possibile valutare le statistiche di distribuzione perché l'indice cluster non esiste ancora. In questo caso, il motore di database di SQL Server non può fornire il grado di parallelismo massimo per l'operazione sull'indice. Alcuni operatori, ad esempio quelli relativi all'ordinamento e all'analisi, possono tuttavia trarre vantaggi dall'esecuzione parallela.
Nota
Le operazioni parallele sugli indici sono disponibili solo nelle edizioni Enterprise, Developer ed Evaluation di SQL Server.
Al momento dell'esecuzione, il motore di database di SQL Server determina se il carico di lavoro di sistema corrente e i dati di configurazione illustrati in precedenza consentono l'esecuzione parallela. Se l'esecuzione parallela è garantita, il motore di database di SQL Server determina il numero ottimale di thread di lavoro e suddivide l'esecuzione del piano parallelo tra tali thread di lavoro. Dal momento in cui viene avviata l'esecuzione parallela su più thread di lavoro di una query o di un'operazione sull'indice, viene usato lo stesso numero di thread di lavoro fino al completamento dell'operazione. Il motore di database di SQL Server riesamina il numero ottimale di decisioni di thread di lavoro ogni volta che viene recuperato un piano di esecuzione dalla cache dei piani. Ad esempio, l'esecuzione di una query può comportare l'uso di un piano seriale, un'esecuzione successiva della stessa query può richiedere un piano parallelo con tre thread di lavoro e una terza esecuzione può richiedere un piano parallelo con quattro thread di lavoro.
Gli operatori di aggiornamento ed eliminazione in un piano di esecuzione di query parallele vengono eseguiti in modo seriale, ma la clausola WHERE di un'istruzione UPDATE o DELETE può essere eseguita in parallelo. Le modifiche apportate ai dati verranno quindi applicate in modo seriale al database.
Fino a SQL Server 2012 (11.x), anche l'operatore di inserimento viene eseguito in modo seriale. La parte SELECT di un'istruzione INSERT, tuttavia, può essere eseguita in parallelo. Le modifiche apportate ai dati verranno quindi applicate in modo seriale al database.
A partire da SQL Server 2014 (12.x) e dal livello di compatibilità del database 110, l'istruzione SELECT ... INTO può essere eseguita in parallelo. Altre forme di operatori di inserimento funzionano nello stesso modo descritto per SQL Server 2012 (11.x).
A partire da SQL Server 2016 (13.x) e dal livello di compatibilità del database 130, l'istruzione INSERT ... SELECT può essere eseguita in parallelo durante l'inserimento in heap o indici columnstore cluster (CCI) e usando l'hint TABLOCK. Anche gli inserimenti all'interno di tabelle temporanee locali (identificate dal prefisso #) e di tabelle temporanee globali (identificate da prefissi ##) sono abilitati per il parallelismo usando l'hint TABLOCK. Per altre informazioni, vedere INSERT (Transact-SQL).
I cursori statici e gestiti da keyset possono essere popolati tramite piani di esecuzione parallela. La funzionalità dei cursori dinamici può invece essere implementata solo tramite l'esecuzione seriale. Query Optimizer genera sempre un piano di esecuzione seriale per le query che fanno parte di un cursore dinamico.
Sostituire i gradi di parallelismo
Il grado di parallelismo imposta il numero di processori da usare durante l'esecuzione di piani paralleli. Questa configurazione può essere impostata a diversi livelli:
A livello di server, con l'opzione di configurazione del servermassimo grado di parallelismo (MAXDOP).
Si applica a: SQL ServerNota
SQL Server 2019 (15.x) presenta raccomandazioni automatiche per l'impostazione dell'opzione di configurazione del server MAXDOP durante il processo di installazione. L'interfaccia utente del programma di installazione consente di accettare le impostazioni consigliate o di immettere valori personalizzati. Per altre informazioni, vedere Pagina Configurazione del motore di database - MaxDOP.
A livello di carico di lavoro, usando l'opzione di configurazione del gruppo di carico di lavoro di Resource Governor MAX_DOP.
Si applica a: SQL ServerA livello di database, usando la configurazione con ambito databaseMAXDOP.
Si applica a: SQL Server e database SQL di AzureA livello di istruzione di query o di indice, con l’hint per la queryMAXDOP o l'opzione di indice MAXDOP. Ad esempio, è possibile usare questa opzione per aumentare o diminuire il numero di processori dedicati a un'operazione sull'indice online. Ciò consente di bilanciare le risorse utilizzate per un'operazione sull'indice con quelle degli utenti simultanei.
Si applica a: SQL SQL Server e database SQL di Azure
L'impostazione dell'opzione max degree of parallelism su 0 (impostazione predefinita) consente a SQL Server di usare tutti i processori disponibili fino a un massimo di 64 nell'esecuzione di piani paralleli. Anche se SQL Server imposta una destinazione di runtime di 64 processori logici quando l'opzione MAXDOP è impostata su 0, è possibile impostare manualmente un valore diverso se necessario. L'impostazione di MAXDOP su 0 per query e indici consente l'uso da parte di SQL Server di tutti i processori disponibili fino a un massimo di 64 per le query o gli indici specificati nell'esecuzione di piani paralleli. MAXDOP non è un valore imposto per tutte le query parallele, ma piuttosto un valore target provvisorio per tutte le query idonee per il parallelismo. Ciò significa che se ci sono thread di lavoro sufficienti disponibili in fase di esecuzione, una query potrebbe essere eseguita con un grado di parallelismo minore rispetto all'opzione di configurazione del server MAXDOP.
Suggerimento
Per altre informazioni, vedere Indicazioni su MAXDOP per la configurazione di MAXDOP a livello di server, database, query o hint.
Esempio di query parallela
Nella query seguente viene eseguito il conteggio del numero di ordini effettuati nel trimestre con inizio 1 aprile 2000. Per questi ordini, almeno uno degli articoli è stato ricevuto dal cliente successivamente alla data prevista. La query indica il numero totale di tali ordini raggruppati per priorità di ordine e disposti in ordine di priorità crescente.
Nell'esempio seguente vengono utilizzati nomi di tabelle e colonne fittizi.
SELECT o_orderpriority, COUNT(*) AS Order_Count
FROM orders
WHERE o_orderdate >= '2000/04/01'
AND o_orderdate < DATEADD (mm, 3, '2000/04/01')
AND EXISTS
(
SELECT *
FROM lineitem
WHERE l_orderkey = o_orderkey
AND l_commitdate < l_receiptdate
)
GROUP BY o_orderpriority
ORDER BY o_orderpriority
Si supponga che per le tabelle lineitem e orders vengano definiti gli indici seguenti:
CREATE INDEX l_order_dates_idx
ON lineitem
(l_orderkey, l_receiptdate, l_commitdate, l_shipdate)
CREATE UNIQUE INDEX o_datkeyopr_idx
ON ORDERS
(o_orderdate, o_orderkey, o_custkey, o_orderpriority)
Di seguito viene riportato un possibile piano parallelo generato per la query indicata in precedenza:
|--Stream Aggregate(GROUP BY:([ORDERS].[o_orderpriority])
DEFINE:([Expr1005]=COUNT(*)))
|--Parallelism(Gather Streams, ORDER BY:
([ORDERS].[o_orderpriority] ASC))
|--Stream Aggregate(GROUP BY:
([ORDERS].[o_orderpriority])
DEFINE:([Expr1005]=Count(*)))
|--Sort(ORDER BY:([ORDERS].[o_orderpriority] ASC))
|--Merge Join(Left Semi Join, MERGE:
([ORDERS].[o_orderkey])=
([LINEITEM].[l_orderkey]),
RESIDUAL:([ORDERS].[o_orderkey]=
[LINEITEM].[l_orderkey]))
|--Sort(ORDER BY:([ORDERS].[o_orderkey] ASC))
| |--Parallelism(Repartition Streams,
PARTITION COLUMNS:
([ORDERS].[o_orderkey]))
| |--Index Seek(OBJECT:
([tpcd1G].[dbo].[ORDERS].[O_DATKEYOPR_IDX]),
SEEK:([ORDERS].[o_orderdate] >=
Apr 1 2000 12:00AM AND
[ORDERS].[o_orderdate] <
Jul 1 2000 12:00AM) ORDERED)
|--Parallelism(Repartition Streams,
PARTITION COLUMNS:
([LINEITEM].[l_orderkey]),
ORDER BY:([LINEITEM].[l_orderkey] ASC))
|--Filter(WHERE:
([LINEITEM].[l_commitdate]<
[LINEITEM].[l_receiptdate]))
|--Index Scan(OBJECT:
([tpcd1G].[dbo].[LINEITEM].[L_ORDER_DATES_IDX]), ORDERED)
Nella figura seguente è illustrato un piano di query eseguito con grado di parallelismo 4 e con un join a due tabelle.
Il piano parallelo contiene tre operatori di parallelismo. Sia l'operatore Index Seek dell'indice o_datkey_ptr che l'operatore Index Scan dell'indice l_order_dates_idx vengono eseguiti in parallelo. In questo modo vengono creati diversi flussi esclusivi. Ciò può essere determinato dagli operatori di parallelismo più vicini sopra gli operatori Index Scan e Index Seek, rispettivamente. Entrambi gli operatori eseguono la ripartizione del tipo di scambio, ovvero ridistribuiscono i dati tra i flussi creando nell'output lo stesso numero di flussi presenti nell'input. Questo numero di flussi equivale al grado di parallelismo.
L'operatore di parallelismo sopra l'operatore Index Scan l_order_dates_idx esegue la ripartizione dei flussi di input usando il valore di L_ORDERKEY come chiave. In questo modo, lo stesso valore di L_ORDERKEY viene incluso nello stesso flusso di output. Allo stesso tempo, i flussi di output mantengono l'ordine della colonna L_ORDERKEY per soddisfare il requisito di input dell'operatore Merge Join.
L'operatore di parallelismo sopra l'operatore Index Seek esegue la ripartizione dei flussi di input utilizzando il valore di O_ORDERKEY. Poiché l'input non viene ordinato nei valori della colonna O_ORDERKEY, che rappresenta la colonna di join dell'operatore Merge Join, l'operatore Sort tra gli operatori di parallelismo e di join di unione assicura che l'input venga ordinato per l'operatore Merge Join nelle colonne di join. Analogamente all'operatore Merge Join, l'operatore Sort viene eseguito in parallelo.
L'operatore di parallelismo superiore riunisce i risultati di numerosi flussi in un singolo flusso. Le aggregazioni parziali eseguite dall'operatore Stream Aggregate sottostante all'operatore di parallelismo vengono quindi riunite in un singolo valore SUM per ogni valore diverso di O_ORDERPRIORITY nell'operatore Stream Aggregate sopra l'operatore di parallelismo. Poiché include due segmenti di scambio con grado di parallelismo 4, questo piano usa otto thread di lavoro.
Per altre informazioni sugli operatori usati in questo esempio, consultare la Guida di riferimento a operatori Showplan logici e fisici.
Operazioni parallele sugli indici
I piani di query compilati ai fini della creazione o della ricompilazione di un indice, oppure dell'eliminazione di un indice cluster, consentono in computer con più microprocessori di eseguire operazioni parallele con più thread di lavoro.
Nota
Le operazioni parallele sugli indici sono disponibili solo nell'edizione Enterprise, a partire da SQL Server 2008 (10.0.x).
In SQL Server, per determinare il grado di parallelismo (il numero totale di singoli thread di lavoro da eseguire) delle operazioni sugli indici vengono, usati gli stessi algoritmi impiegati per altre query. Il grado massimo di parallelismo per un'operazione sugli indici dipende dal valore impostato per l'opzione di configurazione del server Massimo grado di parallelismo . È possibile ignorare il valore dell'opzione Massimo grado di parallelismo per singole operazioni sull'indice impostando l'opzione per gli indici MAXDOP nelle istruzioni CREATE INDEX, ALTER INDEX, DROP INDEX e ALTER TABLE.
Quando tramite il motore di database di SQL Server viene creato un piano di esecuzione dell'indice, il numero di operazioni parallele è impostato sul valore più basso tra i seguenti:
- Il numero di microprocessori, o CPU, del computer.
- Il numero specificato per l'opzione di configurazione del server Massimo grado di parallelismo.
- Il numero di CPU che non hanno già superato una determinata soglia di carico di elaborazione per l'esecuzione dei thread di lavoro di SQL Server.
Ad esempio, in un computer con 8 CPU in cui, tuttavia, l'opzione max degree of parallelism è impostata su 6, per un'operazione sugli indici verranno generati al massimo 6 thread di lavoro paralleli. Se 5 CPU del computer hanno superato la soglia di carico di elaborazione per SQL Server al momento della compilazione del piano di esecuzione per l'indice, il piano userà solo 3 thread di lavoro paralleli.
Le fasi principali di un'operazione parallela sugli indici includono quanto segue:
- Un thread di lavoro di coordinamento esegue rapidamente l'analisi casuale della tabella per produrre una stima della distribuzione delle chiavi dell'indice. Il thread di lavoro di coordinamento stabilisce i limiti delle chiavi in base ai quali verrà creato un numero di intervalli di chiavi equivalente al grado di operazioni parallele. Ogni intervallo di chiavi copre un numero di righe simile. Se ad esempio la tabella include 4 milioni di righe e il grado di parallelismo è 4, il thread di lavoro di coordinamento determinerà i valori di chiave che delimitano 4 set di righe che includono 1 milione di righe ciascuno. Se non è possibile stabilire un numero sufficiente di intervalli di chiavi per utilizzare tutte le CPU, il grado di parallelismo viene ridotto di conseguenza.
- Il thread di lavoro di coordinamento recapita un numero di thread di lavoro pari al grado di operazioni parallele e attende che tali thread di lavoro completino le rispettive operazioni. Ogni thread di lavoro esegue l'analisi della tabella di base usando un filtro che recupera solo le righe con valori di chiave inclusi nell'intervallo assegnato al thread di lavoro. Ogni thread di lavoro compila una struttura di indice per le righe nel rispettivo intervallo di chiavi. Nel caso di indici partizionati ogni thread di lavoro compila un numero specifico di partizioni. Le partizioni non sono condivise tra i thread di lavoro.
- Quando tutti i thread di lavoro paralleli sono stati completati, il thread di lavoro di coordinamento connette le sottounità dell'indice in un unico indice. Questa fase viene eseguita solo nelle operazioni sugli indici offline.
Singole istruzioni CREATE TABLE o ALTER TABLE possono avere più vincoli che richiedono la creazione di un indice. Le operazioni di creazione dell'indice vengono eseguite in serie, anche se in un computer con più CPU ogni singola operazione potrebbe essere eseguita in parallelo.
Architettura delle query distribuita
Microsoft SQL Server supporta due metodi per fare riferimento a origini dati OLE DB eterogenee nelle istruzioni Transact-SQL:
Nomi di server collegati
Per assegnare il nome di un server a un'origine dei dati OLE DB vengono usate le stored procedure di sistemasp_addlinkedserveresp_addlinkedsrvlogin. Per fare riferimento agli oggetti di server collegati nelle istruzioni Transact-SQL, è possibile usare nomi in quattro parti. Se ad esempio si definisce il nome del server collegatoDeptSQLSrvrper un'altra istanza di SQL Server, l'istruzione seguente fa riferimento a una tabella di tale server:SELECT JobTitle, HireDate FROM DeptSQLSrvr.AdventureWorks2022.HumanResources.Employee;È anche possibile specificare il nome del server collegato in un'istruzione
OPENQUERYper aprire un set di righe dall'origine dei dati OLE DB. Successivamente, è possibile inserire i riferimenti a tale set di righe nelle istruzioni Transact-SQL in base alle stesse modalità usate per i riferimenti a una tabella.Nomi di connettore ad hoc
Nel caso di un numero limitato di riferimenti a un'origine dei dati, nella funzioneOPENROWSEToOPENDATASOURCEvengono specificate le informazioni necessarie per la connessione al server collegato. In seguito, sarà possibile fare riferimento a tale set di righe nelle istruzioni Transact-SQL in base alle stesse modalità usate per i riferimenti a una tabella:SELECT * FROM OPENROWSET('Microsoft.Jet.OLEDB.4.0', 'c:\MSOffice\Access\Samples\Northwind.mdb';'Admin';''; Employees);
SQL Server usa OLE DB per la comunicazione tra il motore relazionale e il motore di archiviazione. Il motore relazionale suddivide ogni istruzione Transact-SQL in una serie di operazioni su set di righe OLE DB semplici, aperti dal motore di archiviazione nelle tabelle di base. Pertanto, il motore relazionale può aprire inoltre set di righe OLE DB semplici in qualsiasi origine dei dati OLE DB.

Il motore relazionale utilizza l'API OLE DB per aprire i set di righe nei server collegati, recuperare le righe e gestire le transazioni.
Per ogni origine dei dati OLE DB accessibile come server collegato, è necessario un provider OLE DB nel server che esegue SQL Server. La serie di operazioni Transact-SQL che è possibile usare per un'origine dei dati OLE DB specifica dipende dalle funzionalità del provider OLE DB.
Per ogni istanza di SQL Server, i membri del ruolo predefinito del server sysadmin possono abilitare o disabilitare l'uso di nomi di connettore ad hoc per un provider OLE DB tramite la proprietà DisallowAdhocAccess di SQL Server. Quando l'accesso ad hoc è abilitato, qualsiasi utente collegato a tale istanza può eseguire istruzioni Transact-SQL contenenti nomi di connettore ad hoc che fanno riferimento a qualsiasi origine dati in rete accessibile tramite tale provider OLE DB. Per controllare l'accesso alle origini dati, i membri del ruolo sysadmin possono disabilitare l'accesso ad hoc per il provider OLE DB corrispondente, limitando in tal modo l'accesso da parte degli utenti alle sole origini dati a cui viene fatto riferimento dai nomi dei server collegati definiti dagli amministratori. Per impostazione predefinita, l'accesso ad hoc è abilitato per il provider OLE DB di SQL Server e disabilitato per tutti gli altri provider OLE DB.
Le query distribuite consentono agli utenti di accedere a un'altra origine dei dati (ad esempio file, origini dati non relazionali come Active Directory e così via) tramite il contesto di sicurezza dell'account di Microsoft Windows usato per l'esecuzione del servizio SQL Server. SQL Server imita correttamente l'account di accesso nel caso degli accessi di Windows, ma non per l’accesso di SQL Server. In tal modo, è possibile che l'utente di una query distribuita acceda a un'altra origine dati per cui non dispone delle autorizzazioni necessarie, ma l'account usato per l'esecuzione del servizio SQL Server dispone di tali autorizzazioni. Per definire gli account di accesso specifici autorizzati per l'accesso al server collegato corrispondente, usare la stored procedure sp_addlinkedsrvlogin . Poiché tale controllo non è disponibile per i nomi ad hoc, prestare attenzione quando si attiva l'accesso ad hoc in un provider OLE DB.
Quando possibile, SQL Server invia operazioni relazionali quali join, restrizioni, proiezioni, ordinamenti e operazioni su gruppi all'origine dati OLE DB. SQL Server non analizza per impostazione predefinita la tabella di base in SQL Server e non esegue operazioni relazionali in autonomia. SQL Server esegue query sul provider OLE DB per determinare il livello di grammatica SQL supportata e, in base a tali informazioni, invia al provider il maggior numero possibile di operazioni relazionali.
In SQL Server è disponibile un meccanismo in base al quale il provider OLE DB restituisce statistiche che indicano la modalità di distribuzione dei valori di chiave all'interno dell'origine dei dati OLE DB. In tal modo, Query Optimizer di SQL Server può analizzare in modo più approfondito lo schema di dati nell'origine dati in base ai requisiti di ogni istruzione Transact-SQL, accrescendo la capacità di Query Optimizer di generare piani di esecuzione ottimali.
Miglioramenti apportati all'elaborazione di query su tabelle e indici partizionati
In SQL Server 2008 (10.0.x) sono state migliorate le prestazioni di elaborazione delle query su tabelle partizionate per molti piani paralleli, modificate le modalità di rappresentazione dei piani seriali e paralleli, nonché ottimizzate le informazioni relative al partizionamento fornite nei piani di esecuzione sia della fase di compilazione che di esecuzione. In questo articolo vengono descritti i miglioramenti apportati, viene spiegato come interpretare i piani di esecuzione delle query relativi a tabelle e indici partizionati e vengono fornite le procedure consigliate per migliorare le prestazioni delle query su oggetti partizionati.
Nota
Fino a SQL Server 2014 (12.x), il partizionamento di indici e tabelle è supportato solo nelle edizioni Enterprise, Developer ed Evaluation di SQL Server. A partire da SQL Server 2016 (13.x) SP1, sono supportate anche tabelle e indici partizionati nell’edizione Standard di SQL Server.
Nuova operazione di ricerca con riconoscimento delle partizioni
In SQL Server, la rappresentazione interna di una tabella partizionata viene modificata in modo che la tabella sia visibile all'elaboratore di query come indice multicolonna con PartitionID come colonna iniziale. PartitionID è una colonna calcolata nascosta usata internamente per rappresentare il valore ID della partizione che contiene una riga specifica. Ad esempio, si supponga che la tabella T, definita come T(a, b, c), venga partizionata in base alla colonna A e includa un indice cluster nella colonna B. In SQL Server questa tabella partizionata viene considerata internamente come una tabella non partizionata caratterizzata dallo schema T(PartitionID, a, b, c) e con un indice cluster sulla chiave composta ( (PartitionID, b)). In questo modo Query Optimizer è in grado di eseguire operazioni di ricerca basate su PartitionID su qualsiasi tabella o indice partizionato.
L'eliminazione della partizione viene ora eseguita durante tale operazione di ricerca.
In addition, the Query Optimizer is extended so that a seek or scan operation with one condition can be done on PartitionID (come colonna iniziale logica) e su altre colonne chiave indice e quindi un'operazione di ricerca di secondo livello, con una condizione diversa, su una o più colonne aggiuntive, per ogni valore distinto che soddisfa la qualificazione per l'operazione di ricerca di primo livello. Questa operazione, denominata skip scan consente a Query Optimizer di eseguire un'operazione di ricerca o di analisi basata su un unica condizione per determinare le partizioni a cui eseguire l'accesso e un'operazione Index Scan di secondo livello all'interno di tale operatore per restituire le righe delle partizioni che soddisfano una condizione diversa. Considerare ad esempio la query seguente.
SELECT * FROM T WHERE a < 10 and b = 2;
Per questo esempio si supponga che la tabella T, definita come T(a, b, c), venga partizionata in base alla colonna A e includa un indice cluster nella colonna B. I limiti delle partizione per la tabella T sono definiti dalla funzione di partizione seguente:
CREATE PARTITION FUNCTION myRangePF1 (int) AS RANGE LEFT FOR VALUES (3, 7, 10);
Per risolvere la query, Query Processor esegue un'operazione di ricerca di primo livello per individuare tutte le partizioni contenenti righe che soddisfano la condizione T.a < 10. In tal modo vengono identificate le partizioni a cui effettuare l'accesso. All'interno di ciascuna partizione identificata, viene quindi eseguita una ricerca di secondo livello nell'indice cluster della colonna B per individuare le righe che soddisfano le condizioni T.b = 2 e T.a < 10.
Nell'illustrazione seguente è riportata una rappresentazione logica dell'operazione di "skip scan". Include la tabella T con i dati nelle colonne a e b. Le partizioni sono numerate da 1 a 4 e i limiti delle partizioni sono contraddistinti da righe verticali tratteggiate. In seguito a un'operazione di ricerca di primo livello eseguita sulle partizioni (non riportata nell'illustrazione) è stato determinato che le partizioni 1, 2 e 3 soddisfano la condizione di ricerca prevista dal partizionamento definito per la tabella e il predicato sulla colonna a, ovvero T.a < 10. Il percorso attraversato dalla parte di ricerca di secondo livello dell'operazione di skip scan è illustrata dalla linea curva. In pratica, l'operazione di skip scan cerca in ciascuna di queste partizioni le righe che soddisfano la condizione b = 2. Il costo totale dell'operazione di skip scan equivale a quello di tre operazioni Index Seek distinte.

Visualizzare informazioni sul partizionamento nei piani di esecuzione delle query
È possibile esaminare i piani di esecuzione delle query su tabelle e indici partizionati usando le istruzioni SET di Transact-SQL SET SHOWPLAN_XML o SET STATISTICS XMLoppure l'output del piano di esecuzione grafico restituito in SQL Server Management Studio. È, ad esempio, possibile visualizzare il piano di esecuzione della fase di compilazione facendo clic su Visualizza piano di esecuzione stimato sulla barra degli strumenti dell'Editor di query e il piano della fase di esecuzione facendo clic su Includi piano di esecuzione effettivo.
Questi strumenti consentono di verificare le informazioni seguenti:
- Operazioni come
scans,seeks,inserts,updates,mergesedeletesche accedono alle tabelle partizionate o agli indici. - Partizioni a cui viene effettuato l'accesso tramite la query. Ad esempio, il totale delle partizioni e gli intervalli relativi alle partizioni contigue a cui viene effettuato l'accesso sono disponibili nei piani di esecuzione della fase di esecuzione.
- Utilizzo dell'operazione di skip scan in un'operazione di ricerca o analisi per recuperare dati da una o più partizioni.
Miglioramenti apportati alle informazioni sulle partizioni
SQL Server fornisce informazioni migliorate sul partizionamento per i piani di esecuzione sia della fase di compilazione che della fase di esecuzione. I piani di esecuzione includono ora le informazioni seguenti:
- Un attributo
Partitionedfacoltativo per indicare che su una tabella partizionata viene eseguito un operatore, ad esempioseek,scan,insert,update,mergeodelete. - Un elemento
SeekPredicateNewnuovo con un sottoelementoSeekKeysche includePartitionIDcome colonna chiave di indice iniziale e condizioni di filtro che specificano ricerche di intervallo suPartitionID. La presenza di due sottoelementiSeekKeysindica che suPartitionIDviene usata un'operazione di skip scan. - Informazioni di riepilogo che includono il totale delle partizioni a cui viene effettuato l'accesso. Queste informazioni sono disponibili solo nei piani della fase di esecuzione.
Per illustrare la modalità di visualizzazione di queste informazioni nell'output del piano di esecuzione grafico e nell'output di Showplan XML, considerare la query seguente sulla tabella partizionata fact_sales. Questa query implica l'aggiornamento dei dati in due partizioni.
UPDATE fact_sales
SET quantity = quantity - 2
WHERE date_id BETWEEN 20080802 AND 20080902;
Nella figura seguente sono illustrate le proprietà dell'operatore Clustered Index Seek nel piano di esecuzione di runtime per questa query. Per visualizzare la definizione della tabella fact_sales e la definizione della partizione, vedere la sezione "Esempio" in questo articolo.

Attributo Partitioned
Quando su una tabella o un indice partizionato si esegue un operatore quale Index Seek, l'attributo Partitioned viene incluso sia nel piano della fase di compilazione che in quello della fase di esecuzione ed è impostato su True (1). L'attributo non viene visualizzato quando è impostato su False (0).
L'attributo Partitioned può essere visualizzato negli operatori fisici e logici seguenti:
- Table Scan
- Index Scan
- Index Seek
- Inserisci
- Update
- Delete
- Unire
Come illustrato nella figura precedente, questo attributo viene visualizzato nelle proprietà dell'operatore in cui è definito. Nell'output di Showplan XML, questo attributo è indicato come Partitioned="1" nel nodo RelOp dell'operatore nel quale è definito.
Nuovo predicato Seek
Nell'output di Showplan XML l'elemento SeekPredicateNew è visualizzato nell'operatore nel quale è definito. Può contenere fino a due occorrenze del sottoelemento SeekKeys. Il primo elemento SeekKeys specifica l'operazione di ricerca di primo livello a livello di ID della partizione dell'indice logico. Tale ricerca consente di determinare le partizioni a cui è necessario accedere per soddisfare le condizioni della query. Il secondo elemento SeekKeys specifica la parte della ricerca di secondo livello dell'operazione di skip scan che viene eseguita all'interno di ciascuna partizione identificata nella ricerca di primo livello.
Informazioni di riepilogo sulle partizioni
Nei piani di esecuzione della fase di esecuzione le informazioni di riepilogo sulle partizioni includono il totale delle partizioni e l'identità delle partizioni effettive a cui viene effettuato l'accesso. È possibile utilizzare queste informazioni per verificare che le partizioni a cui viene effettuato l'accesso tramite la query sono corrette e che tutte le altre partizioni non vengono considerate.
Vengono fornite le informazioni seguenti: Actual Partition Counte Partitions Accessed.
Actual Partition Count corrisponde al numero totale di partizioni a cui si accede tramite la query.
Nell'output di Showplan XMLPartitions Accessedcorrisponde alle informazioni di riepilogo sulle partizioni che vengono visualizzate nel nuovo elemento RuntimePartitionSummary del nodo RelOp dell'operatore nel quale è definito. Nell'esempio seguente è illustrato il contenuto dell'elemento RuntimePartitionSummary , in cui è indicato che viene eseguito l'accesso a due partizioni totali, ovvero la 2 e la 3.
<RunTimePartitionSummary>
<PartitionsAccessed PartitionCount="2" >
<PartitionRange Start="2" End="3" />
</PartitionsAccessed>
</RunTimePartitionSummary>
Visualizzare le informazioni sulle partizioni utilizzando altri metodi di Showplan
I metodi SHOWPLAN_ALL, SHOWPLAN_TEXT e STATISTICS PROFILE di Showplan non segnalano le informazioni sulle partizioni descritte in questo articolo, con l'unica eccezione illustrata di seguito. In quanto incluse nel predicato SEEK , le partizioni a cui eseguire l'accesso sono identificate da un predicato di intervallo nella colonna calcolata che rappresenta l'ID di partizione. L'esempio seguente mostra il predicato SEEK per un operatore Clustered Index Seek . Viene effettuato l'accesso alle partizioni 2 e 3 e l'operatore di ricerca applica il filtro sulle righe che soddisfano la condizione date_id BETWEEN 20080802 AND 20080902.
|--Clustered Index Seek(OBJECT:([db_sales_test].[dbo].[fact_sales].[ci]),
SEEK:([PtnId1000] >= (2) AND [PtnId1000] \<= (3)
AND [db_sales_test].[dbo].[fact_sales].[date_id] >= (20080802)
AND [db_sales_test].[dbo].[fact_sales].[date_id] <= (20080902))
ORDERED FORWARD)
Interpretare i piani di esecuzione per heap partizionati
Un heap partizionato viene considerato come un indice logico sull'ID di partizione. In un piano di esecuzione l'eliminazione di partizioni in un heap partizionato viene rappresentata come un operatore Table Scan con un predicato SEEK sull'ID di partizione. Nell'esempio seguente sono illustrate le informazioni di Showplan fornite:
|-- Table Scan (OBJECT: ([db].[dbo].[T]), SEEK: ([PtnId1001]=[Expr1011]) ORDERED FORWARD)
Interpretare i piani di esecuzione per join collocati
La collocazione dei join può verificarsi quando due tabelle vengono partizionate utilizzando una funzione di partizionamento identica o equivalente e le colonne di partizionamento di entrambi lati del join sono specificate nella condizione di join della query. Query Optimizer può generare un piano in cui le partizioni di ogni tabella con ID di partizione uguali sono unite in join separatamente. I join collocati possono risultare più rapidi di quelli non collocati perché possono richiedere una minor quantità di memoria e tempi di elaborazione inferiori. Query Optimizer sceglie un piano non collocato o un piano collocato sulla base delle stime dei costi.
In un piano collocato il join Nested Loops legge una o più partizioni di tabelle o indici unite in join dal lato interno. I numeri all'interno degli operatori Constant Scan rappresentano i numeri della partizione.
Quando per le tabelle o gli indici partizionati si generano piani paralleli per join collocati, viene visualizzato un operatore Parallelism tra gli operatori di join Constant Scan e Nested Loops . In questo caso, ognuno dei thread di lavoro sul lato esterno del join legge ed elabora una partizione diversa.
Nella figura seguente viene illustrato un piano di query parallele per un join collocato.
Strategia di esecuzione delle query parallele per oggetti partizionati
Query Processor utilizza una strategia di esecuzione parallela per query che eseguono la selezione da oggetti partizionati. Nell’ambito della strategia di esecuzione, Query Processor determina le partizioni della tabella necessarie per eseguire la query e la proporzione di thread di lavoro da allocare a ogni partizione. Nella maggior parte dei casi, Query Processor alloca un numero di thread di lavoro uguale o quasi uguale a ogni partizione, quindi esegue la query in parallelo tra le partizioni. Nei paragrafi seguenti viene descritta più dettagliatamente l'allocazione dei thread di lavoro.
Se il numero di thread di lavoro è minore di quello delle partizioni, Query Processor assegna ogni thread di lavoro a una partizione diversa, lasciando inizialmente una o più partizioni senza un thread di lavoro assegnato. Quando termina l'esecuzione di un thread di lavoro in una partizione, Query Processor assegna tale thread alla partizione successiva finché non viene assegnato un singolo thread di lavoro a ogni partizione. Questo è l'unico caso in cui Query Processor rialloca i thread di lavoro ad altre partizioni.
Mostra il thread di lavoro riassegnato al termine dell'esecuzione. Se il numero di thread di lavoro è uguale a quello delle partizioni, Query Processor assegna un thread di lavoro a ogni partizione. Quando un thread di lavoro termina, non viene riallocato ad altre partizioni.

Se il numero di thread di lavoro è maggiore di quello delle partizioni, Query Processor alloca un numero uguale di thread di lavoro a ogni partizione. Se il numero di thread di lavoro non è un multiplo esatto del numero di partizioni, Query Processor alloca un thread di lavoro aggiuntivo ad alcune partizioni per usare tutti i thread di lavoro disponibili. Se la partizione è unica, tutti i thread di lavoro verranno assegnati a tale partizione. Nel diagramma seguente sono presenti quattro partizioni e 14 thread di lavoro. Ogni partizione dispone di 3 thread di lavoro assegnati e due partizioni dispongono di un thread di lavoro aggiuntivo, per un totale di 14 thread di lavoro assegnati. Quando un thread di lavoro termina, non viene riassegnato ad altre partizioni.

Sebbene negli esempi precedenti venga suggerito un modo semplice per allocare i thread di lavoro, la strategia effettiva è più complessa e tiene conto di altre variabili che possono presentarsi durante l'esecuzione di query. Ad esempio, se la tabella è partizionata e dispone di un indice cluster nella colonna A e se in una query è presente la clausola del predicato WHERE A IN (13, 17, 25), Query Processor allocherà uno o più thread di lavoro a ciascuno dei tre valori di ricerca (A=13, A=17 e A=25) anziché eseguire l'allocazione a ogni partizione della tabella. È necessario solo eseguire la query nelle partizioni che contengono questi valori e, se tutti i predicati SEEK si trovano nella stessa partizione della tabella, tutti i thread di lavoro verranno assegnati alla partizione specifica.
Per illustrare un altro esempio, si supponga che la tabella dispone di quattro partizioni nella colonna A con punti limite (10, 20, 30), un indice nella colonna B e che la query include una clausola WHERE B IN (50, 100, 150)del predicato. Dal momento che partizioni della tabella sono basate sui valori di A, i valori di B possono trovarsi in qualsiasi partizione della tabella. Di conseguenza Query Processor ricercherà ciascuno dei tre valori di B (50, 100, 150) in ognuna delle quattro partizioni della tabella e assegnerà proporzionatamente i thread di lavoro in modo da eseguire ciascuna delle 12 analisi della query in parallelo.
| Partizioni della tabella basate sulla colonna A | Ricerca della colonna B in ogni partizione della tabella |
|---|---|
| Partizione della tabella 1: A < 10 | B=50, B=100, B=150 |
| Partizione della tabella 2: A >= 10 AND A < 20 | B=50, B=100, B=150 |
| Partizione della tabella 3: A >= 20 AND A < 30 | B=50, B=100, B=150 |
| Partizione della tabella 4: A >= 30 | B=50, B=100, B=150 |
Procedure consigliate
Per migliorare le prestazioni di query che accedono a una grande quantità di dati da tabelle e indici partizionati estesi, è opportuno adottare le procedure consigliate seguenti:
- Eseguire lo striping di ogni partizione tra molti dischi. Questo è particolarmente importante durante l'uso della rotazione dei dischi.
- Quando possibile, utilizzare un server con memoria principale sufficiente per contenere partizioni a cui viene effettuato l'accesso frequentemente o a tutte le partizioni in memoria per ridurre il costo delle operazioni di I/O.
- Se i dati oggetto della query non sono tutti contenuti in memoria, comprimere le tabelle e gli indici al fine di ridurre il costo delle operazioni di I/O.
- Utilizzare un server con processori veloci e il maggior numero possibile di core del processore per sfruttare a pieno la funzionalità di elaborazione di query parallele.
- Assicurarsi che per il server sia disponibile larghezza di banda sufficiente del controller I/O.
- Creare un indice cluster in ogni tabella partizionata grande per sfruttare le ottimizzazioni dell'analisi dell'albero B.
- Quando si esegue il caricamento bulk di dati in tabelle partizionate, attenersi ai requisiti della procedura consigliata nel white paper The Data Loading Performance Guide (Guida alle prestazioni del caricamento dati).
Esempio
Nell'esempio seguente viene creato un database di test che contiene un'unica tabella con sette partizioni. Per l'esecuzione delle query in questo esempio utilizzare gli strumenti descritti in precedenza per visualizzare le informazioni sul partizionamento relative ai piani della fase di compilazione e della fase di esecuzione.
Nota
In questo esempio nella tabella viene inserito più di un milione di righe. A seconda dell'hardware disponibile. l'esecuzione di questo esempio può richiedere diversi minuti. Prima di eseguire questo esempio, verificare di disporre di almeno 1,5 GB di spazio libero su disco.
USE master;
GO
IF DB_ID (N'db_sales_test') IS NOT NULL
DROP DATABASE db_sales_test;
GO
CREATE DATABASE db_sales_test;
GO
USE db_sales_test;
GO
CREATE PARTITION FUNCTION [pf_range_fact](int) AS RANGE RIGHT FOR VALUES
(20080801, 20080901, 20081001, 20081101, 20081201, 20090101);
GO
CREATE PARTITION SCHEME [ps_fact_sales] AS PARTITION [pf_range_fact]
ALL TO ([PRIMARY]);
GO
CREATE TABLE fact_sales(date_id int, product_id int, store_id int,
quantity int, unit_price numeric(7,2), other_data char(1000))
ON ps_fact_sales(date_id);
GO
CREATE CLUSTERED INDEX ci ON fact_sales(date_id);
GO
PRINT 'Loading...';
SET NOCOUNT ON;
DECLARE @i int;
SET @i = 1;
WHILE (@i<1000000)
BEGIN
INSERT INTO fact_sales VALUES(20080800 + (@i%30) + 1, @i%10000, @i%200, RAND() - 25, (@i%3) + 1, '');
SET @i += 1;
END;
GO
DECLARE @i int;
SET @i = 1;
WHILE (@i<10000)
BEGIN
INSERT INTO fact_sales VALUES(20080900 + (@i%30) + 1, @i%10000, @i%200, RAND() - 25, (@i%3) + 1, '');
SET @i += 1;
END;
PRINT 'Done.';
GO
-- Two-partition query.
SET STATISTICS XML ON;
GO
SELECT date_id, SUM(quantity*unit_price) AS total_price
FROM fact_sales
WHERE date_id BETWEEN 20080802 AND 20080902
GROUP BY date_id ;
GO
SET STATISTICS XML OFF;
GO
-- Single-partition query.
SET STATISTICS XML ON;
GO
SELECT date_id, SUM(quantity*unit_price) AS total_price
FROM fact_sales
WHERE date_id BETWEEN 20080801 AND 20080831
GROUP BY date_id;
GO
SET STATISTICS XML OFF;
GO
Contenuto correlato
- Guida di riferimento a operatori Showplan logici e fisici
- Panoramica degli eventi estesi
- Procedure consigliate per il monitoraggio dei carichi di lavoro con Query Store
- Stima della cardinalità (SQL Server)
- Elaborazione di query intelligenti nei database SQL
- Precedenza degli operatori (Transact-SQL)
- Panoramica del piano di esecuzione
- Centro prestazioni per il motore di database di SQL Server e il database SQL di Azure
Commenti e suggerimenti
Presto disponibile: nel corso del 2024 verranno dismessi i problemi di GitHub come meccanismo di feedback per il contenuto e verranno sostituiti con un nuovo sistema di feedback. Per altre informazioni, vedere: https://aka.ms/ContentUserFeedback.
Invia e visualizza il feedback per