一時的な障害処理 (Azure を使用したクラウド アプリ Real-World 構築)
作成者 : Rick Anderson、 Tom Dykstra
修正プロジェクトのダウンロード または 電子書籍のダウンロード
Azure 電子書籍 を使用した Real World Cloud Apps の構築 は、Scott Guthrie によって開発されたプレゼンテーションに基づいています。 クラウド向けの Web アプリの開発を成功させるために役立つ 13 のパターンとプラクティスについて説明します。 電子書籍の詳細については、 最初の章を参照してください。
実際のクラウド アプリを設計するときは、一時的なサービスの中断を処理する方法について考慮する必要があります。 この問題は、ネットワーク接続と外部サービスに依存しているため、クラウド アプリでは一意に重要です。 多くの場合、自己復旧である小さな不具合が発生する可能性があり、インテリジェントに処理する準備ができていない場合は、顧客に悪いエクスペリエンスが生じる可能性があります。
一時的な障害の原因
クラウド環境では、障害が発生し、データベース接続が定期的に発生していることがわかります。 これは、Web サーバーとデータベース サーバーが直接接続されているオンプレミス環境と比較して、ロード バランサーの数が多いためです。 また、マルチテナント サービスに依存している場合、サービスを使用する他のユーザーがサービスに大きな影響を受けているため、サービスの呼び出しが遅くなったり、タイムアウトしたりすることがあります。 また、サービスに頻繁にアクセスしているユーザーが、サービスの他のテナントに悪影響を与えないようにするために、サービスによって意図的に調整 (接続を拒否) している可能性があります。
スマート再試行/バックオフ ロジックを使用して、一時的な障害の影響を軽減する
例外をスローして、利用できないまたはエラー ページを顧客に表示する代わりに、通常は一時的なエラーを認識し、エラーが発生した操作を自動的に再試行できます。この操作は、時間が経つ前に成功することを期待しています。 ほとんどの場合、操作は 2 回目の試行で成功し、顧客が問題があることを認識しなくてもエラーから回復します。
スマート再試行ロジックを実装するには、いくつかの方法があります。
Microsoft Patterns & Practices グループには、(Entity Framework ではなく) SQL Database アクセスに ADO.NET を使用している場合に、すべてを実行する一時的な障害処理アプリケーション ブロックがあります。 再試行のポリシー (クエリまたはコマンドを再試行する回数と試行間の待機時間) を設定し、 USING ブロックで SQL コードをラップするだけです。
public void HandleTransients() { var connStr = "some database"; var _policy = RetryPolicy.Create < SqlAzureTransientErrorDetectionStrategy( retryCount: 3, retryInterval: TimeSpan.FromSeconds(5)); using (var conn = new ReliableSqlConnection(connStr, _policy)) { // Do SQL stuff here. } }TFH では、 Azure In-Role Cache と Service Bus もサポートされています。
Entity Framework を使用する場合、通常は SQL 接続を直接操作しないため、この Patterns and Practices パッケージを使用することはできませんが、Entity Framework 6 では、この種の再試行ロジックがフレームワークに直接ビルドされます。 同様の方法で再試行戦略を指定した後、EF はデータベースにアクセスするたびにその戦略を使用します。
Fix It アプリでこの機能を使用するには、 DbConfiguration から派生したクラスを追加し、再試行ロジックを有効にする必要があります。
// EF follows a Code based Configuration model and will look for a class that // derives from DbConfiguration for executing any Connection Resiliency strategies public class EFConfiguration : DbConfiguration { public EFConfiguration() { AddExecutionStrategy(() => new SqlAzureExecutionStrategy()); } }フレームワークが一般的に一時的なエラーとして識別するSQL Database例外の場合、次に示すコードは、再試行間の指数バックオフ遅延と最大遅延 5 秒で、操作を最大 3 回再試行するように EF に指示します。 指数バックオフとは、再試行に失敗するたびに、再試行を再試行する前に、より長い期間待機することを意味します。 1 行に 3 回の試行が失敗すると、例外がスローされます。 サーキット ブレーカーに関する次のセクションでは、指数バックオフと限られた回数の再試行が必要な理由について説明します。
Azure Storage サービスを使用しているときにも、Blob 用の Fix It アプリと同様の問題が発生する可能性があり、.NET ストレージ クライアント API には同じ種類のロジックが既に実装されています。 再試行ポリシーを指定するだけです。既定の設定に問題がなければ、それを行う必要もありません。
遮断 器
一定期間に何度も再試行したくない理由はいくつかあります。
- 失敗した要求を永続的に再試行するユーザーが多すぎると、他のユーザーのエクスペリエンスが低下する可能性があります。 何百万人ものユーザーが繰り返し再試行要求を行っている場合は、IIS ディスパッチ キューを作成し、それ以外の場合は正常に処理できる要求をアプリが処理できないようにすることができます。
- サービスの障害が原因で全員が再試行している場合は、キューに入っている要求が非常に多いため、復旧を開始するとサービスがフラッディングされる可能性があります。
- エラーが調整によるものであり、サービスが調整に使用する期間がある場合、再試行を続けると、そのウィンドウが外に移動し、調整が続行される可能性があります。
- ユーザーが Web ページのレンダリングを待機している場合があります。 待ち時間が長すぎると、後でもう一度やり直すよう比較的早くアドバイスする方が迷惑な場合があります。
指数バックオフでは、サービスがアプリケーションから取得できる再試行の頻度を制限することで、これらの問題の一部に対処します。 ただし、 サーキット ブレーカーも必要です。これは、特定の再試行しきい値でアプリが再試行を停止し、次のような他のアクションを実行することを意味します。
- カスタム フォールバック。 ロイターから株価を取得できない場合は、ブルームバーグから入手できます。または、データベースからデータを取得できない場合は、キャッシュからデータを取得できる可能性があります。
- サイレントに失敗します。 サービスに必要なものがアプリのすべてまたは何もない場合は、データを取得できないときに null を返すだけです。 Fix It タスクを表示していて、BLOB サービスが応答していない場合は、画像なしでタスクの詳細を表示できます。
- 高速で失敗します。 他のユーザーにサービスの中断を引き起こす可能性がある再試行要求でサービスがフラッディングされないように、ユーザーにエラーが発生したり、調整期間が延長されたりする可能性があります。 わかりやすい "後でやり直してください" というメッセージを表示できます。
万能の再試行ポリシーはありません。 非同期バックグラウンド ワーカー プロセスでは、ユーザーが応答を待機している同期 Web アプリよりも、再試行回数を増やし、長く待つことができます。 リレーショナル データベース サービスの再試行間隔は、キャッシュ サービスの場合よりも長く待機できます。 数値がどのように異なるかを知るために推奨される再試行ポリシーのサンプルを次に示します。 ("Fast First" は、最初の再試行の前に遅延がないことを意味します。
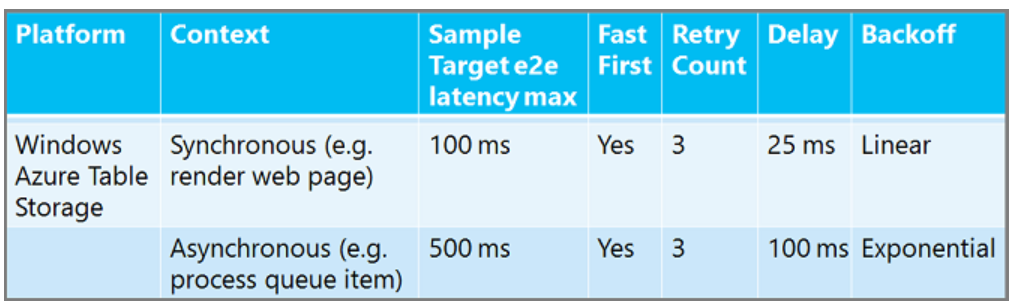
再試行ポリシーのガイダンスSQL Databaseについては、「SQL Databaseへの一時的なエラーと接続エラーのトラブルシューティング」を参照してください。
まとめ
再試行/バックオフ戦略は、ほとんどの場合、一時的なエラーを顧客に見えないようにするのに役立ちます。Microsoft には、ADO.NET、Entity Framework、または Azure Storage サービスのどちらを使用しているかに関係なく、戦略を実装する作業を最小限に抑えるために使用できるフレームワークが用意されています。
次の 章では、分散キャッシュを使用してパフォーマンスと信頼性を向上させる方法について説明します。
リソース
詳細については、次のリソースを参照してください。
ドキュメント
- Azure Cloud Services での Large-Scale サービスの設計に関するベスト プラクティス。 Mark Simms と Michael Thomassy によるホワイト ペーパー。 Failsafe シリーズに似ていますが、詳細な操作方法について説明します。 「テレメトリと診断」セクションを参照してください。
- フェールセーフ: 回復性のあるクラウド アーキテクチャのガイダンス。 Marc Mercuri、Ulrich Homann、Andrew Townhill のホワイト ペーパー。 FailSafe ビデオ シリーズの Web ページ バージョン。
- Microsoft のパターンとプラクティス - Azure ガイダンス。 「再試行パターン」、「Scheduler Agent Supervisor パターン」を参照してください。
- Entity Framework - 接続の回復性/再試行ロジック。 Entity Framework 6 の一時的な障害処理機能を使用してカスタマイズする方法。
- ASP.NET MVC アプリケーションでの Entity Framework との接続の回復性とコマンド インターセプト。 9 部構成のチュートリアル シリーズの 4 つ目は、SQL Databaseの EF 6 接続の回復性機能を設定する方法を示しています。
ビデオ
- FailSafe: スケーラブルで回復性の高いCloud Servicesの構築。 ウルリヒ・ホーマン、マルク・メルキュール、マーク・シムズによる9部構成のシリーズ。 Microsoft カスタマー アドバイザリ チーム (CAT) の実際の顧客との経験から得たストーリーを使用して、高レベルの概念とアーキテクチャの原則を非常にアクセスしやすく興味深い方法で提示します。 40:55 から始まるエピソード 3 のサーキット ブレーカーの説明を参照してください。
- 大きなビルド: Azure のお客様から学んだ教訓 - パート 2。 Mark Simms は、障害、一時的な障害処理、およびすべてをインストルメント化するための設計について説明します。
コード サンプル
- Azure のクラウド サービスの基礎。 エンタープライズ ライブラリの一時的な障害処理ブロック (TFH) の使用方法を示す Microsoft Azure カスタマー アドバイザリ チームによって作成されたサンプル アプリケーション。 詳細については、「Cloud Service Fundamentals Data Access Layer – Transient Fault Handling (クラウド サービスの基本データ アクセス層 – 一時的エラー処理)」を参照してください。 TFH は、(Entity Framework を使用せずに) ADO.NET を直接使用してデータベースにアクセスする場合に推奨されます。
フィードバック
以下は間もなく提供いたします。2024 年を通じて、コンテンツのフィードバック メカニズムとして GitHub の issue を段階的に廃止し、新しいフィードバック システムに置き換えます。 詳細については、「https://aka.ms/ContentUserFeedback」を参照してください。
フィードバックの送信と表示