人工知能 (AI) と機械学習 (ML) では、仮想ワールドと物理ワールドにまたがる操作に固有の機会と課題が提供されます。 AI と ML では、現実の入力データと結果の間の相関関係を認識し、複雑な物理的工業システムを自動化する決定を行うことができます。 しかし、AI 機械学習システムでは、探索、即興、創造的思考、因果関係の決定など、より高度な認知機能を実行することはできません。
"機械教示" は、次のような機械学習システム向けの新しいパラダイムです。
- 自動化された AI システム モデルに "分野に関する専門知識" を提供します。
- "ディープ強化学習" を使用して、学習プロセスのパターンを明らかにし、独自のメソッドで肯定的な行動を採用します。
- "シミュレートされた環境" を利用して、ドメイン固有のユース ケースやシナリオに対する大量の合成データを生成します。
機械学習では、新しい学習アルゴリズムの開発や、既存のアルゴリズムの改善に焦点が当てられます。 機械教示では、教師自身の有効性に焦点が当てられます。 AI の複雑さを抽象化して、分野に関する専門知識や現実的な条件に焦点を当てることで、強力な AI モデルと ML モデルが作成され、自動制御システムが "自律システム" になります。
この記事では、機械教示で使用される AI の開発と概念の履歴について説明します。 関連記事では、自律システムについて詳しく説明します。
自動化の歴史
人間は、何千年にもわたり、タスクをより効率的に実行するための物理的なツールとマシンを設計してきました。 これらのテクノロジの目的は、より低コストと、より少ない直接的手作業で、より一貫した出力を実現することです。
18 世紀末から 19 世紀初頭にかけての第 1 次産業革命では、1700s 1800s 遅延させることで、製造業で手作業を置き換えるために機械が導入されました。 産業革命では、蒸気動力による自動化と、家内から組織化された工場への製造の移動による統合を通じて、製造効率の向上が実現されました。 19 世紀中頃から 20 世紀初頭にかけての第 2 次産業革命では、電化と製造ラインにより、製造能力が向上しました。
第 1 次と第 2 次の世界大戦では、情報理論、通信、信号処理において、大幅な進歩がもたらされました。 トランジスタの開発により、物理システムの制御に情報理論を簡単に適用できるようになりました。 この第 3 次産業革命では、製造、輸送、医療などの物理システムのハードコーディングされた制御にコンピューター システムが進出しました。 プログラムによる自動化の利点としては、一貫性、信頼性、セキュリティなどがあります。
第 4 次産業革命では、サイバー物理システムと工業での "モノのインターネット (IoT) " の概念が導入されました。 人が制御したいシステムは、大きすぎ、複雑すぎて、完全に規定されたルールを記述することが難しくなっています。 人工知能を使用すると、通常は人間の知能を必要とするタスクをスマート マシンで実行できます。 機械学習を使用すると、明示的にプログラミングしなくても、コンピューターはエクスペリエンスから自動的に学習して改善できます。
AI と ML
AI と ML は新しい概念ではなく、理論の多くは数十年にわたり変わっていませんが、ストレージ、帯域幅、コンピューティングにおける最近の技術的な進歩により、より正確で便利なアルゴリズム予測が可能になりました。 デバイスの処理能力、小型化、ストレージ容量、ネットワーク容量の向上により、システムと機器をさらに自動化できます。 また、このような進歩により、大量のリアルタイム センサー データの収集と照合が可能になります。
"コグニティブ オートメーション" は、情報集中型のプロセスとシステムにソフトウェアと AI を適用したものです。 コグニティブ AI を使用すると、手作業の労働者を支援して生産性を向上させ、単調なまたは危険な現場の従業員を置き換え、大量のデータを処理できることから新しい分析情報を獲得することができます。 コンピューター ビジョン、自然言語処理、チャットボット、ロボット工学といったコグニティブ テクノロジは、以前は人間しかできなかったタスクを実行できます。
現在の多くの生産システムでは、工業ロボットを使用してエンジニアリングと製造を自動化され、大きな成果が実現されています。 製造業界における工業自動化の使用と進化により、高品質で安全性の高い製品が生産され、エネルギーと原材料がより効率的に使用されています。 しかし、ほとんどの場合、ロボットは高度に構造化された環境でのみ動作します。 通常は、変化に柔軟に対応することはできず、当面のタスクに極度に特化しています。 また、動作を管理するハードウェアとソフトウェアのルールのため、ロボットの開発には大きな費用がかかる場合があります。
"自動化のパラドックス" では、自動システムがより効率的になるほど、運用に対する人間的要素の重要性が高くなると言われています。 人間の役割は、日常的な作業単位の労働力から、自動システムの改善と管理および重要な各分野の専門知識の貢献に変化します。 自動システムではより効率的に出力を生成できますが、設計や稼働が適切でないと、無駄や問題が発生する可能性もあります。 自動化を効率的に使おうとすると、人間はいらなくなるどころか、ますます重要になります。
AI のユース ケース
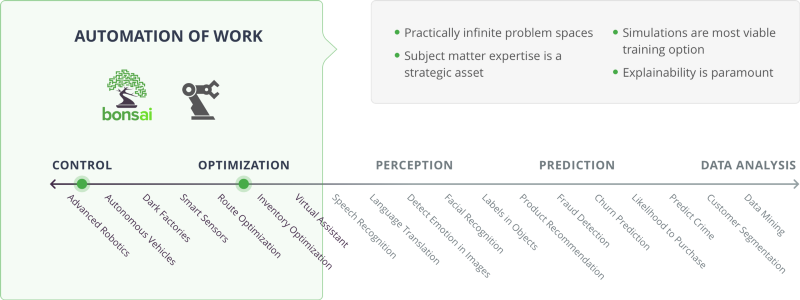
上の図では、制御と最適化のカテゴリは、作業の自動化に関連しています。 AI の対象範囲のこの側には、実質的に無限の問題領域があります。 分野に関する専門知識は戦略的資産であり、シミュレーションは最も実行可能なトレーニング オプションであり、説明可能性は最重要事項です。
オーケストレーターには、スマート製造と Bonsai 機械教示プラットフォームが含まれます。 ユース ケースには、高度なロボット、自律車両、ダーク工場、スマート センサー、ルート最適化、インベントリ最適化、仮想アシスタントなどがあります。
強化学習
機械教示では、"強化学習 (RL) " を利用して、モデルがトレーニングされ、学習プロセスのパターンが明らかにされて独自のメソッドで肯定的な行動が採用されます。 "ディープ強化学習 (DRL) " では、複雑なディープ ラーニング ニューラル ネットワークに強化学習が適用されます。
機械学習の RL では、環境における報酬や望ましい結果を最大限にすることをソフトウェア エージェントが学習する方法が検討されます。 RL は、次の 3 つの基本的な機械学習パラダイムの 1 つです。
- "教師あり学習" では、タグ付けされたデータまたは構造化されたデータからの一般化が行われます。
- "教師なし学習" では、ラベルのないデータまたは構造化されていないデータが圧縮されます。
- "強化学習" は、試行錯誤によって動作します。
教師あり学習では例による学習が行われますが、強化学習では経験からの学習が行われます。 適切なデータセットの検索とラベル付けに重点が置かれる教師あり学習とは異なり、RL ではタスクの実行方法のモデルを設計することが重視されます。
RL の主要なコンポーネントは次のとおりです。
- エージェント: 現在の環境の変更を決定できるエンティティ。
- 環境: エージェントが動作する物理的世界またはシミュレートされた世界。
- 状態: エージェントとその環境の現在の状況。
- アクション: 環境でのエージェントによる相互作用。
- 報酬: エージェントのアクションに対して得られる、環境からのフィードバック。
- ポリシー: エージェントとその環境の現在の状態をアクションにマップするためのメソッドまたは関数。
RL では、報酬関数とポリシーを使用して、エージェントのアクションが評価され、フィードバックが提供されます。 エージェントは、現在の環境に基づいてシーケンシャルな意思決定を行うことにより、経時的に報酬を最大にし、特定の状況において最適なアクションを予測することを学習します。
RL では、望ましい動作に対しては報酬を与え、望ましくない動作に対しては報酬を与えないことにより、目標を達成することをエージェントに教示します。 次の図では、RL の概念的なフローと、主要なコンポーネントの相互作用方法を示します。
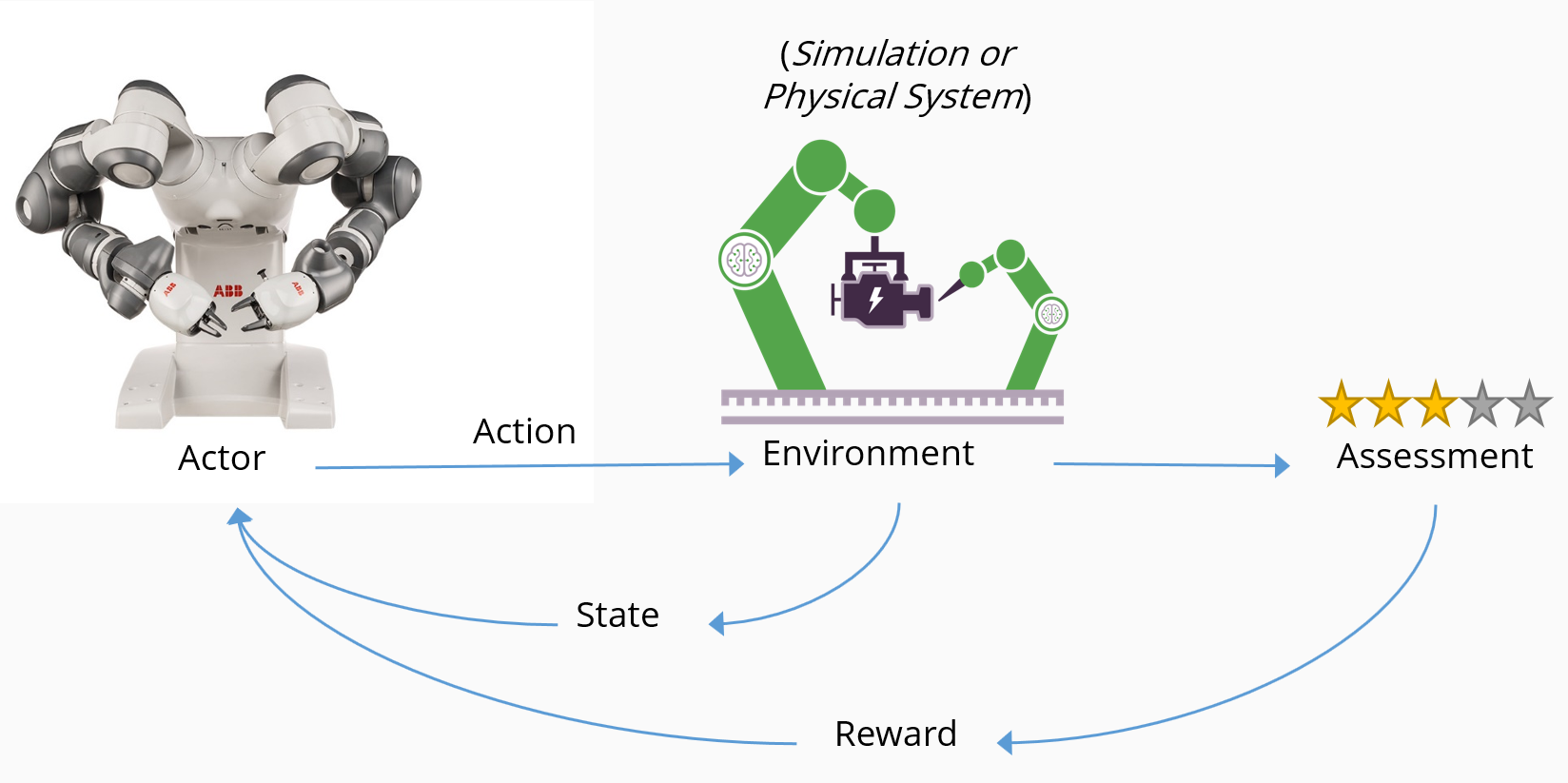
- "エージェント" (この場合はロボット) は、"環境" (この場合はスマート製造ライン) において "アクション" を実行します。
- アクションにより、環境の "状態" が変化し、変更された状態がエージェントに返されます。
- 評価メカニズムにより、"ポリシー" が適用されて、エージェントに配信される結果が決定されます。
- "報酬" メカニズムでは、プラスの報酬を与えることによって良い行動が促進され、ペナルティを与えることによって悪い行動を阻止できます。
- 報酬によって望ましいアクションが増える一方、ペナルティによって望ましくないアクションが減ります。
問題の性質は、確率論的 (ランダム) である場合と、決定論的である場合があります。 エージェントは 1 つであるのが最も一般的ですが、環境内に複数のエージェントが存在する場合もあります。 エージェントは、観測によって環境を検知します。 環境は完全に観察可能な場合と部分的に観察可能な場合があり (エージェントのセンサーによって決まります)、観測は不連続でも連続でもかまいません。
各観測の後でアクションが実行され、それによって環境が変更されます。 終了状態に達するまで、このサイクルが繰り返されます。 通常、システムにはメモリはなく、アルゴリズムでは開始状態、終了状態、受け取った報酬だけが配慮されます。
エージェントは、試行錯誤を通じて学習するとき、アクションを評価するために大量のデータを必要とします。 RL は、大規模な履歴データのあるドメインや、シミュレートされたデータを簡単に生成できるドメインに最も適しています。
報酬関数
特定のアクションに対してどの程度の報酬をいつ与えるかは、"報酬関数" によって決定されます。 通常、報酬の構造の定義は、システムの所有者に委ねられます。 このパラメーターを調整することで、結果に大きな影響を与えることができます。
エージェントは、報酬関数を使用して、周囲の世界の物理的および動的な状態について学習します。 エージェントが報酬を最大にする方法を学習する基本的なプロセスは、少なくとも最初は、試行錯誤です。
探索と利用のトレードオフ
目標と報酬関数に応じて、エージェントは探索と報酬最大化のバランスを取る必要があります。 この選択は、"探索と利用のトレードオフ" と呼ばれます。 現実世界の多くの面と同様に、エージェントは、環境をさらに詳しく探索することのメリットと (将来的に、いっそう適切に決定を下せるようになる可能性があります)、エージェントが世界に関して現在所有している報酬最大化のためのすべての知識を使用して環境を利用することとの、バランスを取る必要があります。 異なるアクションを実行すると、新しい視点が提供される可能性があります (特に、それまで試されたことのないアクションの場合)。
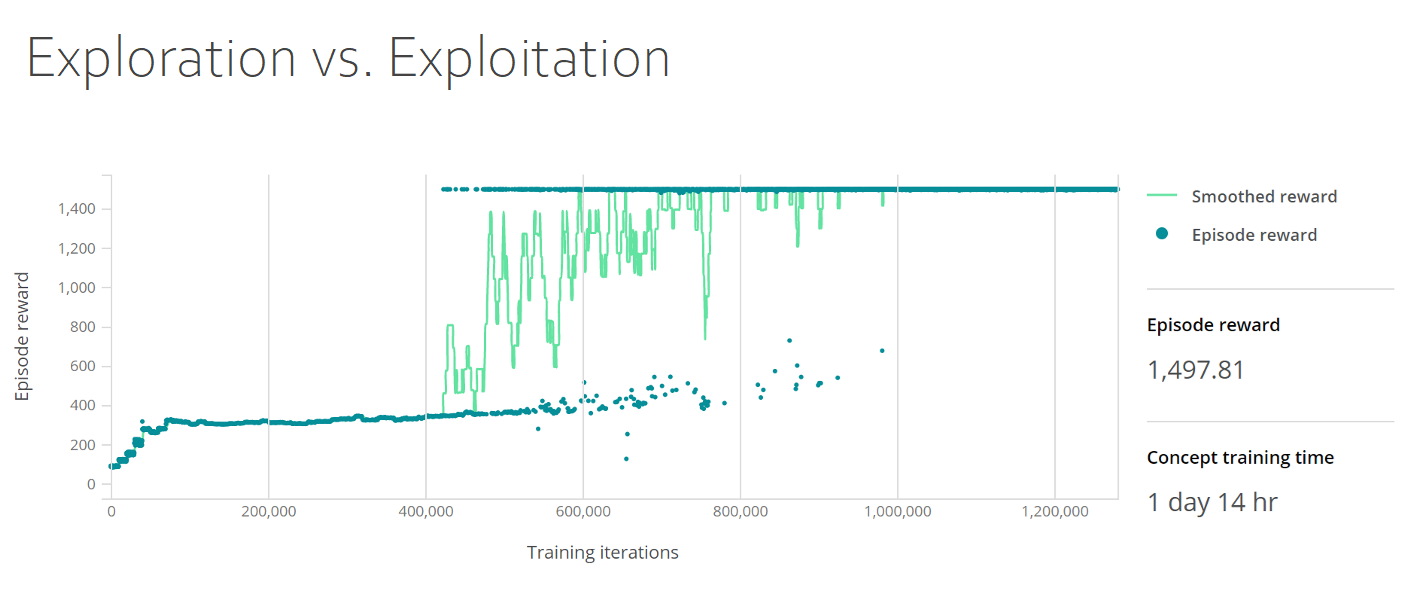
次のトレーニング ダッシュボードでは、探索と利用のトレードオフが示されています。 グラフには、平滑化された報酬とエピソード報酬の両方が示されており、y 軸はエピソード報酬、x 軸はトレーニングのイテレーションを示します。 エピソード報酬密度は、最初の 50,000 イテレーションで 400 に増加した後、400,000 イテレーションまでは安定しており、その後 1,500 まで上昇して安定します。
コブラ効果
報酬は、経済学で "コブラ効果" と呼ばれるものの影響を受けます。 英国植民地時代のインドで、政府は、すべての死んだコブラに対して報酬を出すことで、大量の野生コブラを減らすことにしました。 当初は、報酬を得るために多数の蛇が殺されたため、このポリシーは成功しました。 しかしすぐに、人々は制度を悪用し始め、報酬を得るためにコブラをわざと飼育するようになりました。 最終的に、当局はこのことに気付き、プログラムを取り消しました。 もう報酬が得られなくなったコブラの飼育者は蛇を放してしまい、結果として、報酬制度が始まる前より、野生のコブラの数は増加しました。
善意による奨励策により、状況は改善するどころか悪化しました。 教訓として、奨励した動作をエージェントが学習しても、意図した結果が得られない可能性があります。
整形された報酬
特定の "形状" を持つ報酬関数を作成すると、エージェントは適切なポリシーをより簡単かつ迅速に学習できるようになります。
ステップ関数は、エージェントにそのアクションがどの程度よかったかをあまり伝えない "スパース報酬関数" の例です。 次のステップ報酬関数では、0.0 と0.1 の間の距離アクションのみで 1.0 の完全な報酬が生成されます。 距離が0.1 より大きい場合、報酬はありません。

これに対し、"整形報酬関数" では、アクションが望ましい応答にどの程度近いかがエージェントに示されます。 次の整形報酬関数では、望ましい 0.0 のアクションに対する応答の近さに応じて、より多くの報酬が与えられます。 関数の曲線は双曲線です。 距離 0.0 に対する報酬が 1.0 で、距離が 1.0 に近づくに従って徐々に 0.0 まで落下します。
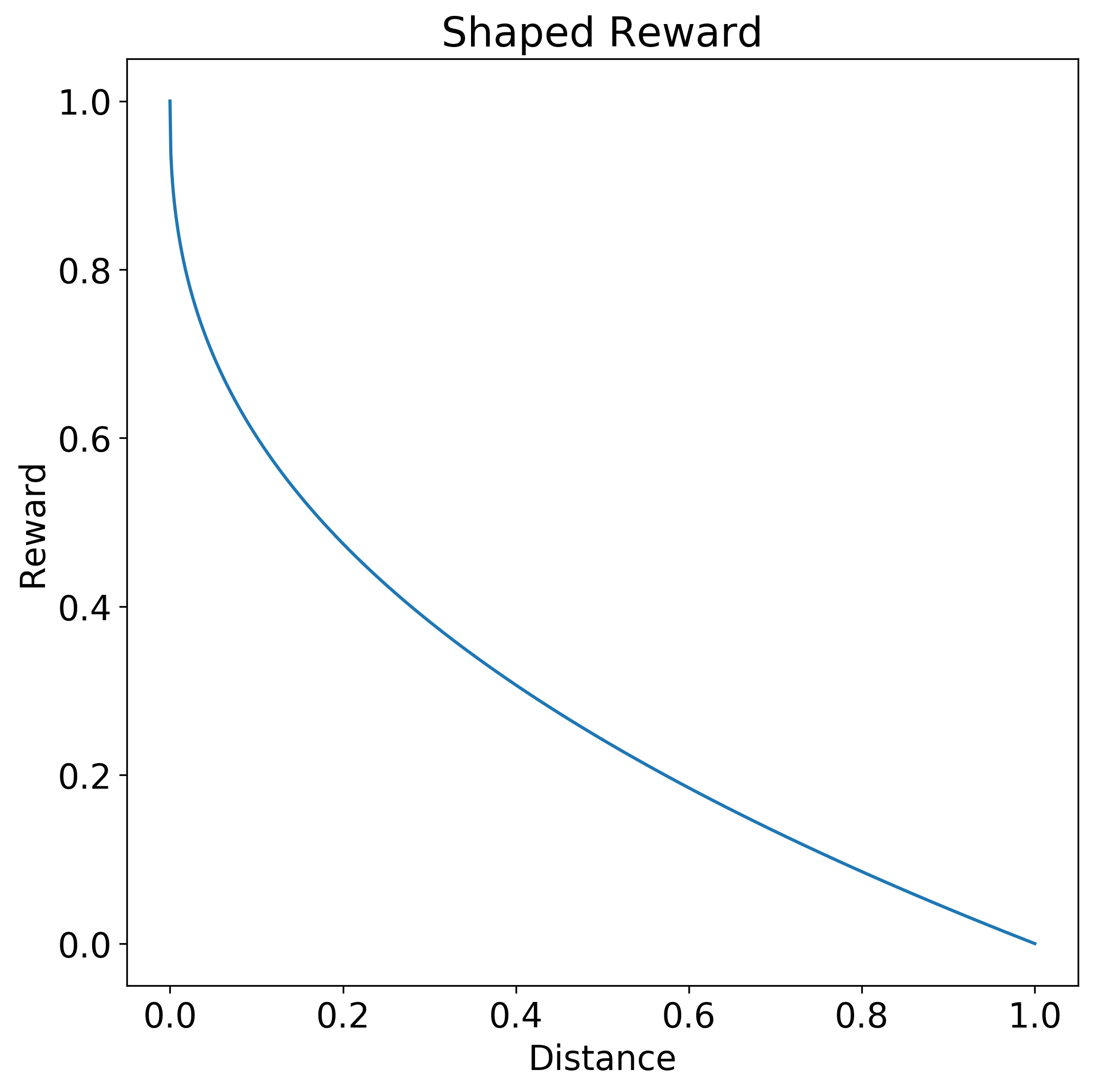
整形では、将来の報酬の価値を短期の報酬より低くしたり、目標に対する報酬のサイズを縮小することで探索を促したりする場合があります。
場合によっては、報酬関数で時間的および空間的な考慮を指定して、アクションの順序シーケンスを奨励することがあります。 ただし、整形報酬関数が大きく複雑になっている場合は、問題を小さなステージに分割し、概念ネットワークを使用することを検討します。
概念ネットワーク
"概念ネットワーク" を使用すると、ドメイン固有の知識と分野に関する専門知識を指定および再利用して、動作の必要な順序を個別のタスクの特定のシーケンスにまとめることができます。 概念ネットワークは、エージェントが動作してアクションを実行できる検索領域を制限するのに役立ちます。
物をつかんで積み重ねることに関する次の概念ネットワークでは、Grasp and Stack ボックスは、2 つの灰色のボックスReach と Move および 3 つの緑色のボックス Orient、Grasp、Stack の親です。
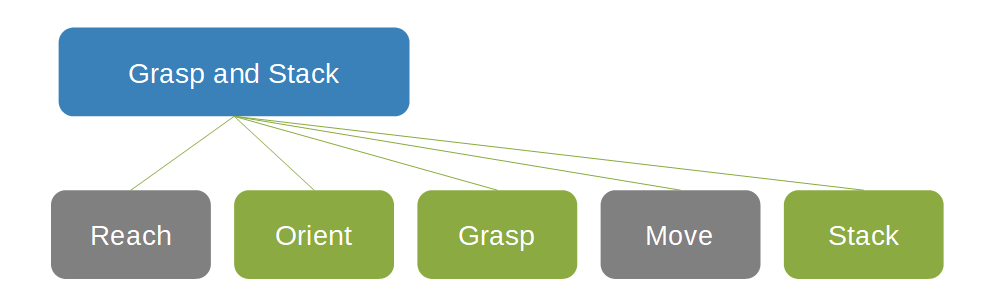
概念ネットワークでは、多くの場合、報酬機能をより簡単に定義できます。 各概念では、そのタスクに最適な方法を使用できます。 概念ネットワークの考え方は、構成要素へのソリューションの分解可能性に役立ちます。 システム全体を再トレーニングしなくてもコンポーネントを置き換えることができるため、事前トレーニング済みのモデルを再利用したり、既存のコントローラーや他の既存のエコシステム コンポーネントを使用したりできます。 特に産業制御システムでは、完全に取り去って置き換えるより、段階的に少しずつ改善する方が望ましい場合があります。
カリキュラム学習と実習学習
問題を概念ネットワークで個別のシーケンシャル タスクに分割すると、問題を難しさのステージに分割し、段階的に難しくなる "カリキュラム" としてエージェントに提示できます。 この段階的なアプローチでは、簡単な問題から始めて、エージェントに訓練させ、能力が高くなるに従って困難にしていきます。 報酬関数は、そのタスクに対するエージェントの能力が高くなるのに合わせて、変化し、進化します。 この "カリキュラム学習" アプローチは、探索をガイドし、必要なトレーニング時間を大幅に短縮するのに役立ちます。
また、外部の専門家の行動を模倣することによって学習するよう指示することで、エージェントに対するポリシー検索領域を制限することもできます。 "実習学習" では、専門家のガイド付き手本を使用して、エージェントが探索する状態領域を制限します。 実習学習では、新しいソリューションを発見しない代わりに、既知のソリューションをより迅速に学習できます。
実習学習の例は、人間のドライバーのアクションを模倣するように、自動運転車のエージェントを教育することです。 エージェントは、運転方法を学習しますが、教師の欠点や特異性も受け継いでしまいます。
RL ベースの AI システムの設計
次の戦略は、RL ベースの AI システムを設計して構築するための実用的なガイドです。
- 状態、終了条件、アクション、報酬を策定して反復します。
- 報酬関数を作成し、必要に応じて整形します。
- 特定のサブ目標に報酬を割り当てます。
- 必要に応じて、報酬を積極的に割り引きます。
- 初期状態を試します。
- トレーニング用の例のサンプリングを試します。
- トレーニング中のシミュレーション動態パラメーターのバリエーションを制限します。
- 予測の間に一般化し、トレーニングを可能な限り円滑に維持します。
- 物理的に関連するノイズを導入し、実際のマシンでのノイズに対応します。
シミュレーション
AI システムはデータを大量に消費し、適切な意思決定を行うようトレーニングされていることを確認するために、多くのシナリオにさらされる必要があります。 システムでは、実際の環境に悪影響を与える可能性のある高価なプロトタイプが必要になることがよくあります。 再現性の高いトレーニング データを収集し、手動でラベル付けするコストは、時間と直接的な労力の両方において高くなります。 シミュレーターと、シミュレーターによって生成される高密度でラベルの付いたトレーニング データを使用することは、このようなデータの不足に対処するための強力な手段です。
"次元の呪い" とは、高次元空間で大量のデータを処理するときに発生する現象を指します。 特定のシナリオと問題セットを正確にモデル化するには、ディープ ニューラル ネットワークを使用する必要があります。 これらのネットワーク自体は高次元であり、フィッティングの必要なパラメーターが多くあります。 次元が増加すると、使用できる現実のデータが希薄になるような速さで領域が拡大するため、統計的に有意な相関関係を作成するのに十分なデータを収集することが困難になります。 十分なデータがない場合、トレーニング結果のモデルはデータに十分に適合せず、新しいデータに対して適切に一般化されないため、モデルの目的が損なわれることになります。
次の 2 つの問題があります。
- トレーニング アルゴリズムには、問題を正確にモデル化するための大きな学習容量がありますが、適合性が低くなるのを防ぐには、より多くのデータが必要です。
- この大量のデータを収集してラベル付けする作業は、可能であったとしても、困難で、コストがかかり、エラーが発生しやすくなります。
シミュレーションにより、実際の物理環境でのシステムを仮想的にモデル化することによって、実際のトレーニング データを大量に収集する必要がなくなります。 シミュレーションを使用すると、危険な環境や、さまざまな種類の気象条件のような現実世界での再現が困難な状況で、トレーニングを行うことができます。 データを人為的にシミュレートすると、データ収集の難しさが回避され、アルゴリズムには、現実の世界に正確に一般化されるシナリオの例が適切に提供され続けます。
シミュレーションは、次のような理由で DRL の理想的なトレーニング ソースです。
- カスタム環境に対する柔軟性。
- データ生成に対する安全性とコスト効率。
- 並列化できるため、トレーニング時間の短縮が可能。
シミュレーションは、機械と電気工学、自律走行車、セキュリティとネットワーク、交通と物流、ロボットなど、幅広い業界やシステムで利用できます。
シミュレーション ツールには次のものがあります。
- Simulink は、MathWorks によって開発された、動的システムのモデリング、シミュレーション、分析のためのグラフィカル プログラミング ツールです。
- Gazebo は、複雑な屋内環境や屋外環境でのロボットの集団を正確にシミュレーションできるツールです。
- Microsoft AirSim は、オープンソースのロボット シミュレーション プラットフォームです。
機械教示のパラダイム
"機械教示" によって提供される ML システム構築用の新しいパラダイムでは、焦点がアルゴリズムから適切なモデルの生成と展開に移ります。 機械教示により学習プロセス自体に含まれるパターンが識別されて、独自の方法に肯定的な行動を採用されます。 機械学習でのアクティビティの多くでは、既存のアルゴリズムの改善や、新しい学習アルゴリズムの開発に重点が置かれています。 それに対し、機械教示では、教師自身の有効性に焦点が当てられます。
機械教示:
- 人間のドメイン専門家による "分野に関する専門知識" と AI および ML を結合します。
- "ディープ強化学習" のアルゴリズムとモデルの生成と管理を自動化します。
- モデルの最適化とスケーラビリティのために "シミュレーション" を統合します。
- 結果として得られるモデルの動作の "説明可能性" が向上します。
機械学習の状態は、少数のアルゴリズム専門家によって主に決定されてきました。 これらの専門家は ML を深く理解しており、必要なパフォーマンスまたは精度の基準を満たすように ML のアルゴリズムまたはアーキテクチャを変更することができます。 世界的な ML 専門家の数は万の単位と推定され、そのために ML ソリューションの導入の速度は低下しています。 モデルの圧倒的な複雑さにより、多くの人にとって ML の機能は理解の範囲を超えています。
ML の専門家は少数ですが、分野に関する専門家は豊富にいます。 世界的に見れば、分野の専門家は何千万人もいます。 機械教示では、問題のセマンティクスを理解して例を示すことはできるが、ML の複雑さを意識する必要はない、この大規模な専門家のプールを利用します。 機械教示は、教示の内容と方法を体系化ことによって、分野に関する専門知識を効率的にプログラミングするために必要な基本的な抽象化です。 AI の背景を持たない分野の専門家は、専門知識をステップとタスク、条件、および望ましい結果に分割することができます。
エンジニアの場合、機械教示により抽象化の水準が AI アルゴリズムの選択とハイパーパラメーターの微調整より高くなり、より価値のあるアプリケーション ドメインの問題に重点が置かれます。 自律システムを構築するエンジニアは、システムと環境の正確で詳細なモデルを作成し、ディープ ラーニング、模倣学習、強化学習などの手法を使用して、それをインテリジェントにすることができます。 機械教示のもう 1 つの歓迎すべき結果は、開発の間に機械学習の専門家による手動介入の必要性が減るか、なくなることで、モデルの展開にかかる時間が短縮されることです。
機械教示を使用すると、一般的な ML 方法が探索されて、有益な戦略が独自の手法に導入されることにより、ML ソリューションを構築するプロセスが効率化されます。 開発者による指示と構成によると、Microsoft Autonomous Systems プラットフォームの機械教示サービスである Bonsai を使用すると、AI モデルから AI システムへの発展を自動化できます。
Bonsai では、各プロジェクトの現在の状態をバージョン管理ツールで追跡する、わかりやすい一元的なダッシュボードが提供されています。 この機械教示インフラストラクチャを使用すると、モデルの結果を再現することができ、開発者は、将来の AI アルゴリズムのブレイクスルーによって AI システムを簡単に更新できるようになります。
機械教示手法に視点がシフトすることで、ML モデルを生成して展開するためのより合理的でアクセスしやすいプロセスにより、ML の導入が促進されます。 機械教示では、DRL の力をツールとして適用する手段が分野の専門家に提供されます。 機械教示によって、AI のテクノロジの焦点が、ML のアルゴリズムと手法から、ドメインの専門家による現実の問題に対するこれらのアルゴリズムの適用に移ります。
機械教示のプロセス
機械教示の開発と展開には、3 つのフェーズがあります。ビルド、トレーニング、および展開です。
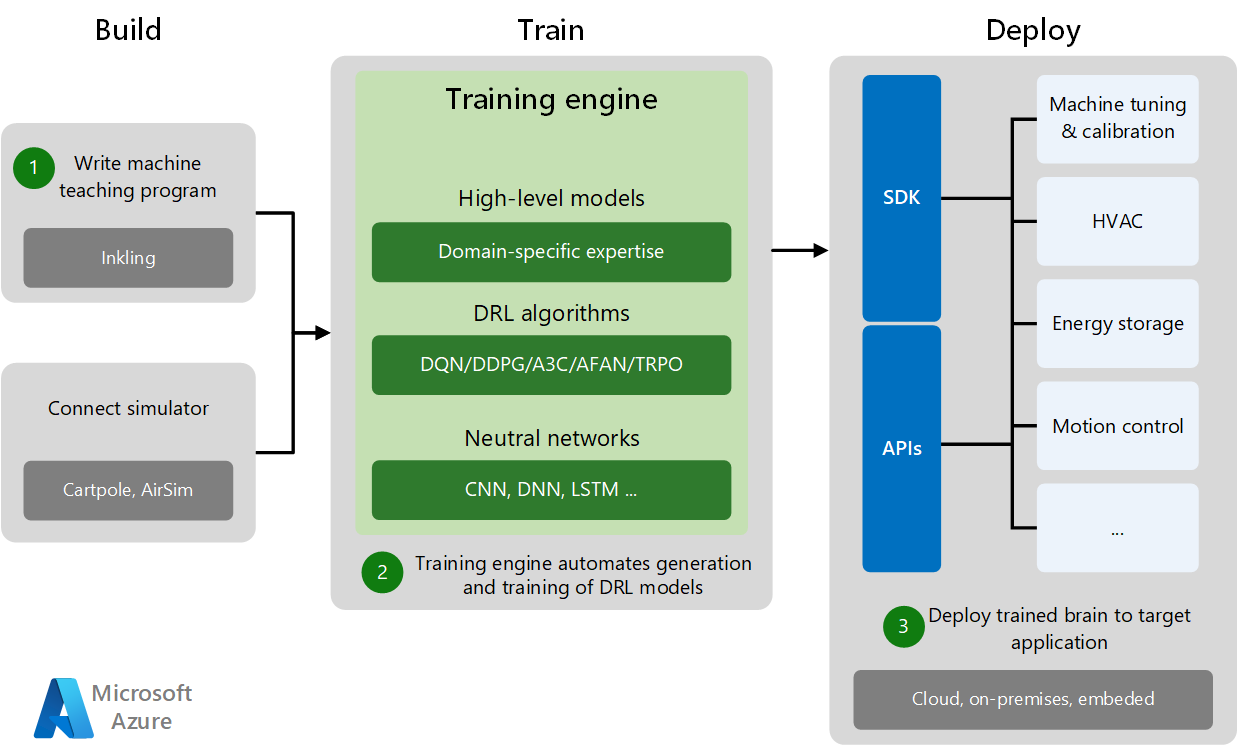
- ビルド フェーズは、機械教示プログラムの作成と、分野固有のトレーニング シミュレーターへの接続から構成されます。 シミュレーターによって、実験と機械の訓練に十分なトレーニング データが生成されます。
- トレーニング フェーズでは、高レベルの分野モデルと、適切な DRL アルゴリズムおよびニューラル ネットワークを組み合わせることで、トレーニング エンジンによって DRL モデルの生成とトレーニングが自動化されます。
- 展開フェーズでは、トレーニングされたモデルが、クラウド、オンプレミス、またはサイトへの埋め込みの形式でターゲット アプリケーションに展開されます。 特定の SDK および展開 API によって、トレーニングされた AI システムはさまざまなターゲット アプリケーションに展開され、マシンのチューニングが実行され、物理システムが制御されます。
"シミュレートされた環境" により、多くのユース ケースやシナリオをカバーする大量の合成データが生成されます。 シミュレーションを使用すると、モデル アルゴリズムのトレーニング用のデータ生成の安全性とコスト効率が高くなり、シミュレーションの並列化によってトレーニングの時間が短縮されます。 シミュレーションは、さまざまな種類の環境条件やシナリオにわたってモデルをトレーニングするために役立ちます。これは、実環境で実現するよりもはるかに高速かつ安全です。
分野に関する専門家は、シミュレーション環境で問題を解決する作業がエージェントで行われているときに監督することができます。また、エージェントがシミュレーション内で動的に適応できるフィードバックとガイダンスを提供することができます。 トレーニングが完了すると、エンジニアはそのトレーニングされたエージェントを実際のハードウェアに展開し、そこで自分の知識を使用して実環境の自律システムを強化できます。
機械学習と機械教示
機械学習と機械学習は補完的であり、独立して進化させることができます。 機械学習の研究では、機械学習アルゴリズムを向上させることで、学習器をよりよくすることに焦点が当てられています。 機械教示の研究では、教示器による機械学習モデルの構築の生産性を高めることに焦点が当てられています。 機械教示のソリューションでは、教示プロセス全体でモデルを生成してテストするために、複数の機械学習アルゴリズムが必要です。
次の図は、機械学習モデルを構築するための代表的なパイプラインを示したものです。
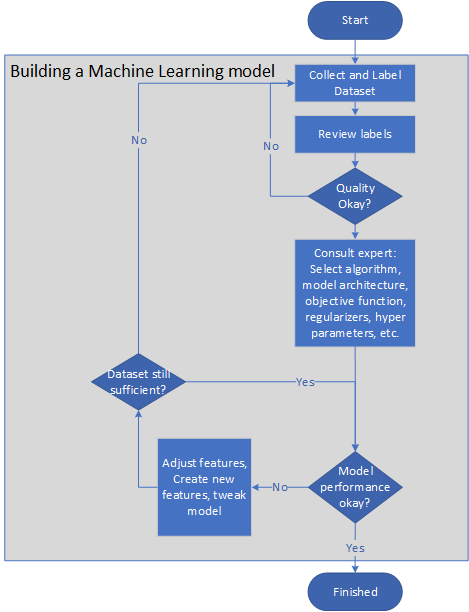
- 問題の所有者は、データセットを収集してラベルを付けるか、ラベル付けタスクをアウトソーシングできるようにラベル ガイドラインを作成します。
- 問題の所有者は、品質が十分になるまでラベルをレビューします。
- 機械学習の専門家は、アルゴリズム、モデル アーキテクチャ、目標関数、正則化、クロス検証セットを選択します。
- エンジニアは、モデルを周期的にトレーニングし、特徴を調整するか、新しい特徴を作成して、モデルの精度と速度を向上させます。
- モデルを小さいサンプルでテストします。 システムがテストで適切に動作しない場合は、上記の手順を繰り返します。
- モデルのパフォーマンスを、現場で監視します。 パフォーマンスがクリティカル レベルより低下した場合は、前記の手順を繰り返してモデルを修正します。
機械教示により、このようなモデルの作成が自動化され、学習プロセスにおける手作業の介入の必要性が減り、特徴の選択や例またはハイパーパラメーターの調整が改善されます。 実際には、機械教示により、モデルの AI 要素に抽象レベルが導入されるため、開発者は分野の知識に専念できます。 また、この抽象化により、AI アルゴリズムを新しいより革新的なアルゴリズムにすぐに置き換えることができます。問題を再指定する必要はありません。
教示器の役割は、学習アルゴリズムへの知識の転送を最適化して、有用なモデルを生成できるようにすることです。 また、教示器は、データの収集とラベル付けで中心的な役割を果たします。 教示器では、ラベルのないデータをフィルター処理して特定の例を選択したり、使用可能なサンプル データを調べ、独自の洞察やバイアスに基づいてそのラベルを推測したりできます。 同様に、教示器では、ラベルの付いていない大きなセットについての 2 つの特徴から、より優れている方を推測できます。
次の図では、機械教示の高度なプロセスが示されています。
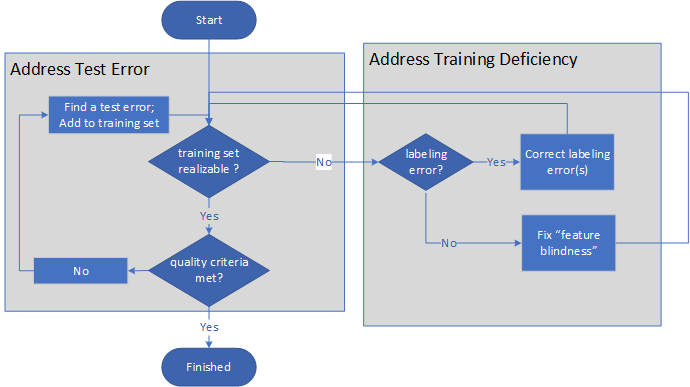
- 教示器では、最初に、トレーニング セットが実現可能かどうかが確認されます。
- トレーニング セットが実現可能でない場合、教示器では、問題の原因が不適切なラベル付けや特徴の不備であるかどうかが判断されます。 ラベル付けを修正したり特徴を追加したりした後、教示器では、トレーニング セ ットが実現可能かどうかが再び評価されます。
- トレーニングセットが実現可能である場合、教示器によりトレーニング品質基準が満たされているかどうかが評価されます。
- 品質基準が満たされていない場合、教示器では、テスト エラーが検出され、トレーニング セットに修正が追加された後、評価の手順が繰り返されます。
- トレーニング セットが実現可能になり、品質基準が満たされると、プロセスは終了します。
プロセスは無限ループのペアであり、モデルとトレーニング自体の品質が十分になった場合にのみ終了します。
モデルの学習容量は、要求に応じて増加します。 教示器によって必要なときにのみ特徴を追加することで学習システムの容量が制御されるため、従来のような正則化は必要ありません。
機械教示と従来のプログラミング
機械教示は、プログラミングの一種です。 プログラミングと機械教示の目的はどちらも、"関数" を作成することです。 入力 X を与えると値 Y が返されるステートレス ターゲット関数を作成する手順は、どちらのプロセスも似ています。
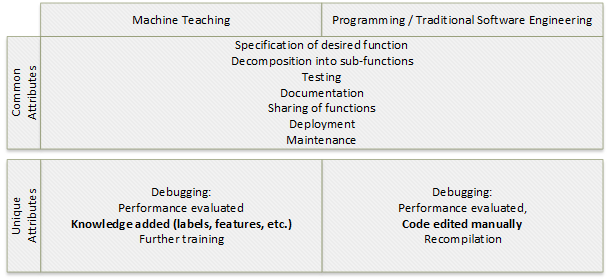
- ターゲット関数を指定します。
- 該当する場合、ターゲット関数をサブ関数に分解します。
- 関数とサブ関数をデバッグしてテストします。
- 関数を文書化します。
- 関数を共有します。
- 関数を展開します。
- スケジュール化された、およびスケジュール化されていないデバッグ サイクルで、関数をメンテナンスします。
ソリューションのパフォーマンスの "デバッグ" または評価には、2 つのプロセス間で異なる属性があります。 プログラミングのデバッグには、コードの手動編集と再コンパイルが含まれます。 機械教示のデバッグには、ナレッジ ラベルと特徴の追加と、追加のトレーニングが含まれます。
入力 X に対してクラス Y を返すターゲット分類関数の構築には機械学習アルゴリズムが関係しますが、機械教示のプロセスは上記の一連のプログラミング手順に似ています。
次の表では、従来のプログラミングと機械教示で概念的に似ている点を示します。
| プログラミング | 機械教示 |
|---|---|
| コンパイラ | 機械学習アルゴリズム、サポート ベクター マシン (SVMS)、ニューラル ネットワーク、トレーニング エンジン |
| オペレーティング システム、サービス、統合開発環境 (IDE) | トレーニング、サンプリング、特徴選択、機械トレーニング サービス |
| フレームワーク | ImageNet、word2vec |
| Python や C# などのプログラミング言語 | Inkling、ラベル、特徴、スキーマ |
| 専門知識のプログラミング | 専門知識の教示 |
| バージョン コントロール | バージョン コントロール |
| 仕様、単体テスト、展開、監視などの開発プロセス | データ収集、テスト、発行などの教示プロセス |
複雑な問題を解決するシステムをソフトウェア エンジニアが記述できる強力な概念は、"分解" です。 分解では、より単純な概念を使用して、より複雑な概念が表現されます。 機械教示器は、適切なツールと経験により、複雑な機械学習の問題を分解する方法を学習できます。 機械教示の規範により、機械教示成功の公算をプログラミングと匹敵するレベルにすることができます。
機械教示プロジェクト
前提条件:
- データを収集、探索、クリーニング、準備、分析するための何らかのエクスペリエンス
- 目標関数、トレーニング、クロス検証、正則化など、ML の基本的な概念に関する知識
機械学習プロジェクトを構築する場合は、現実とそっくりではあっても比較的単純なモデルで始めて、高速なイテレーションと定式化を可能にします。 その後、モデルの忠実性を反復的に改善し、シナリオのカバレッジを高めることによってモデルをより一般化できるようにします。
次の図では、反復的な機械教示モデル開発のフェーズを示します。 後続の各ステップでは、より多くのトレーニング サンプルが必要です。
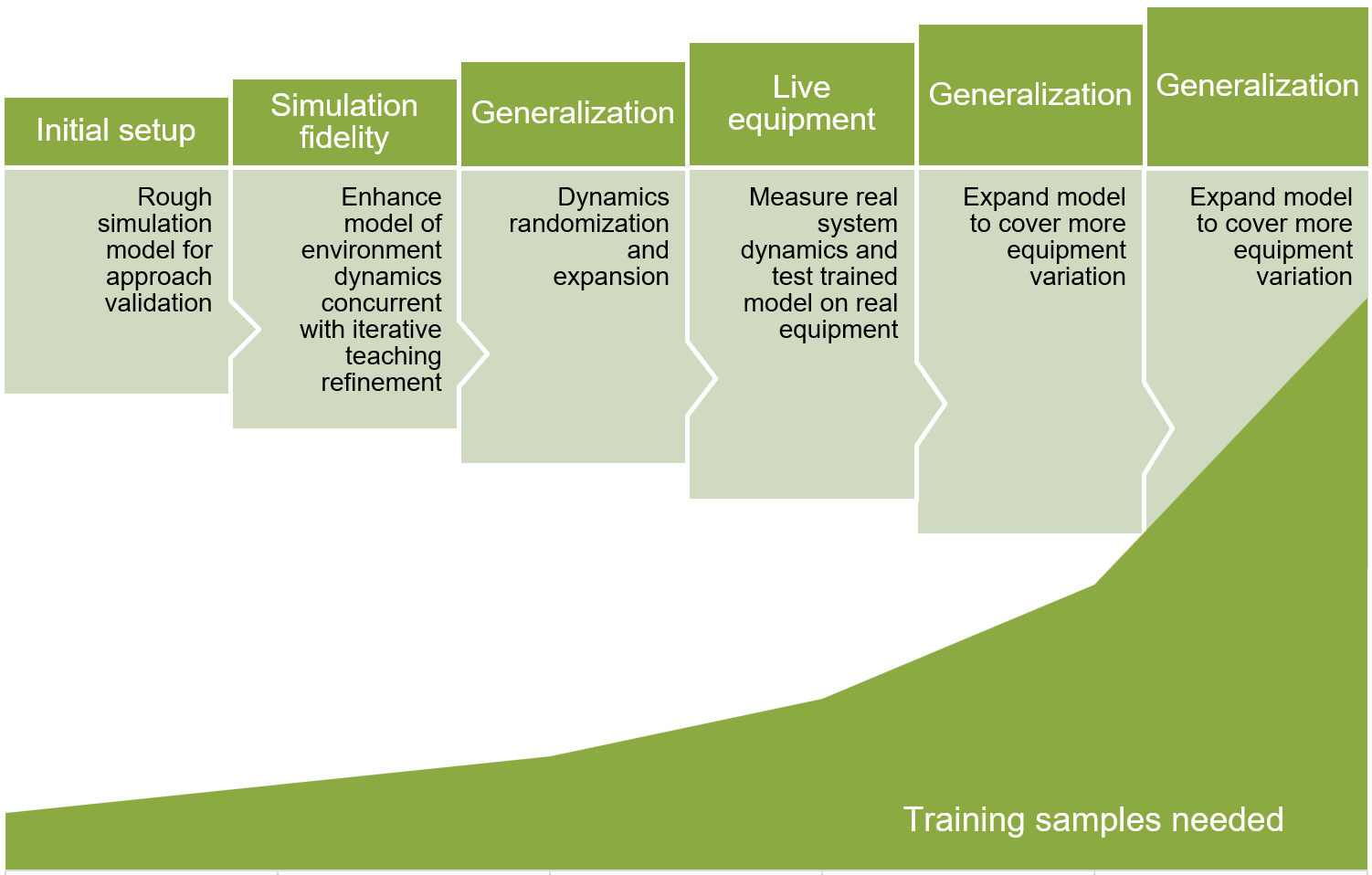
- アプローチを検証するために最初のラフなシミュレーション モデルを設定します。
- 反復的な教示の調整と同時に、環境の動態をモデリングすることで、シミュレーションの精度を高めます。
- 動的なランダム化と拡張を使用してモデルを一般化します。
- 実際のシステムの動態を測定し、実際の機器でトレーニング済みのモデルをテストします。
- より多くの機器のバリエーションをカバーするように、モデルを拡張します。
機械教示プロジェクトの正確なパラメーターを定義するには、非常に多くの実験と実験的探求が必要です。 Microsoft Autonomous Systems プラットフォームにおける Bonsai のような機械教示プラットフォームでは、DRL の革新とシミュレーションを使用して、AI モデルの開発が簡略化されます。
プロジェクトの例
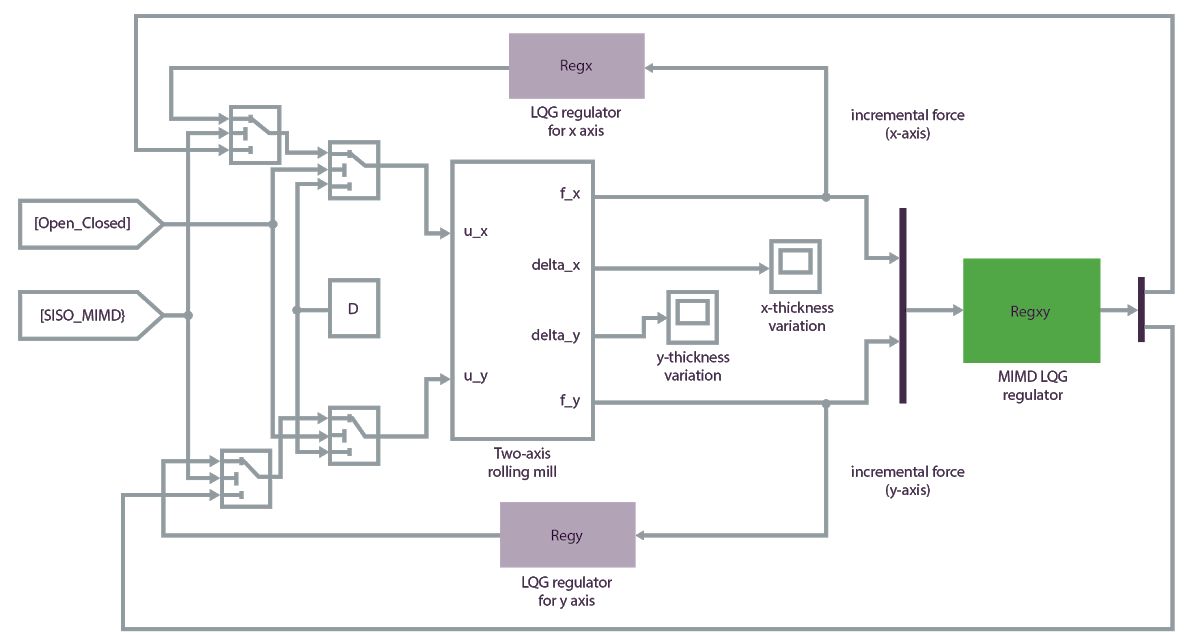
自律システム AI プロジェクトの例は、製造プロセスの最適化のユース ケースです。 目標は、生産ラインで製造される鉄骨の厚さの許容誤差を最適化することです。 ローラーにより鉄に圧力が加えられて、設計された厚さに形成されます。
AI システムへの機械の状態の入力は、圧延荷重、ローラー エラー、およびローラーのノイズです。 AI システムからの制御アクションは、ローラーの操作と動作を制御し、鉄骨の厚さの許容誤差を最適化するためのアクチュエータ コマンドです。
最初に、エージェント、センサー、環境をシミュレートできるシミュレーターを見つけるか、開発します。 次の Matlab シミュレーション モデルでは、この AI システムに対する正確なトレーニング環境が提供されます。
Microsoft Autonomous Systems プラットフォームの Bonsai 機械教示サービスを使用して、モデルに機械教示プランを組み込み、シミュレーターに対してモデルをトレーニングして、トレーニング済みの AI システムを実際の運用施設に展開します。 Inkling は、機械教示プランを正式に記述するための特定目的の言語です。 Bonsai では、Inkling を使用して、問題をスキーマに分解できます。

次に、AI システムを教示するための主要な "概念" を定義して "カリキュラム" を作成し、シミュレーション状態に対する報酬関数を指定します。

AI システムにより、機械教示の概念に従って、シミュレーションの最適化タスクを実施することで学習が行われます。 シミュレーションを Bonsai にアップロードすることができます。そこでは、実行中のトレーニングの進行状況の視覚化が提供されます。
モデルまたは "ブレイン" を構築してトレーニングしたら、それをエクスポートして運用環境に展開することができます。これにより、リアルタイムでオペレーターの意思決定をサポートする最適なアクチュエータ コマンドが AI エンジンからストリーミングされます。
アプリケーションの他の例
次の機械教示の例では、物理システムの動きを制御するポリシーを作成します。 どちらの場合も、エージェントのポリシーを手動で作成するのは不可能であるか、非常に困難です。 エージェントがシミュレーションで領域を探索できるようにし、報酬機能によって選択をガイドすることで、正確なソリューションを生成します。
Cartpole
Bonsai のサンプル プロジェクト Cartpole での目標は、移動するカート上で真っすぐに立っているようポールを教示することです。 ポールは、摩擦のない軌道に沿って動くカートに、非駆動関節で取り付けられています。使用できるセンサー情報として、カートの位置と速度、ポールの角度と角速度があります。
カートに力を加えると、システムがコントロールされます。 サポートされているエージェントのアクションは、カートを左または右に押すことです。 このプログラムでは、ポールが垂直を保っているすべての時間ステップに対して、正の報酬が提供されます。 エピソードは、ポールが垂直から 15 度を超えるか、中心から事前定義された単位数を超えてカートが移動したときに終了します。
この例では、Inkling 言語を使用して機械教示プログラムを記述し、提供されている Cartpole シミュレーターを使用してトレーニングを高速化し、改善しています。
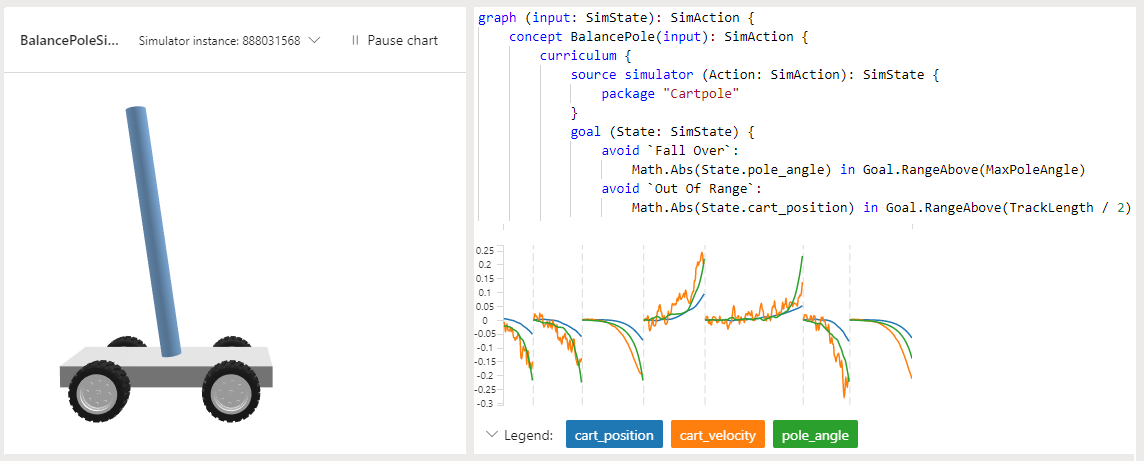
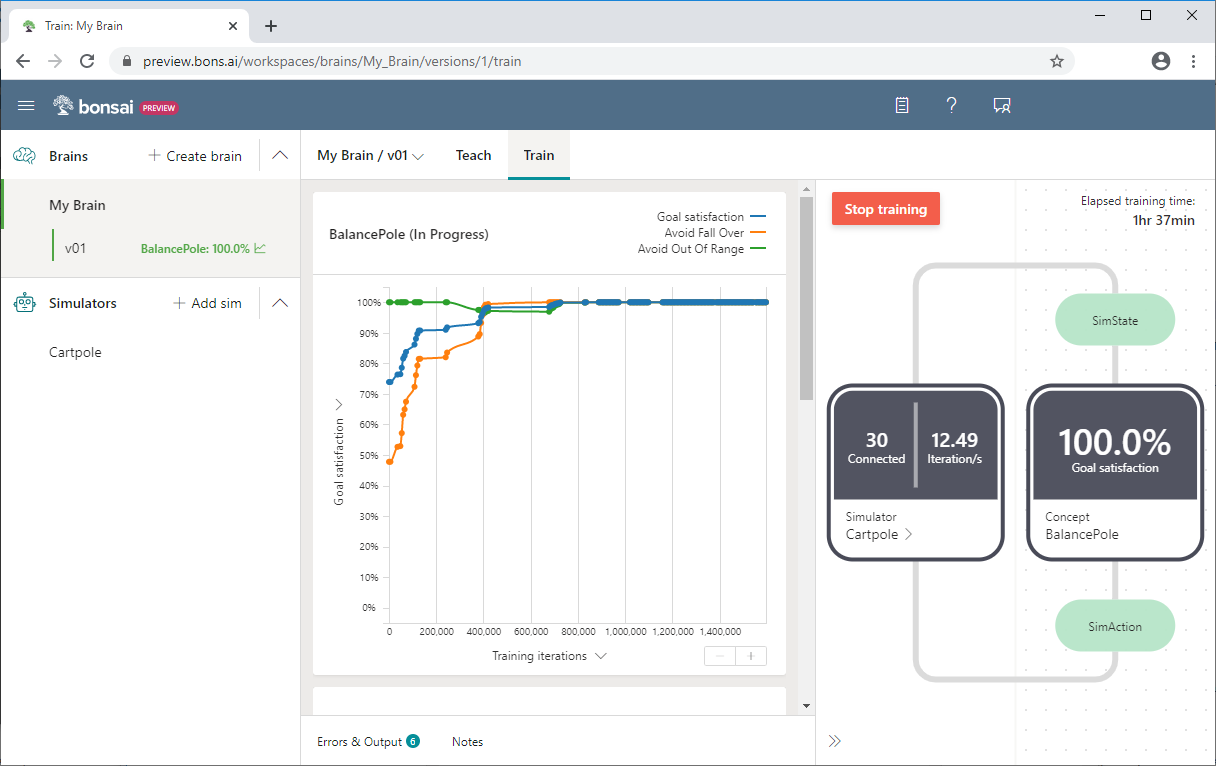
次の Bonsai のスクリーンショットでは、y 軸に [Goal satisfaction](目標満足度) 、x 軸に [Training iterations](トレーニングの反復) を使用した Cartpole のトレーニングが示されています。 Bonsai のダッシュボードには、目標の満足度のパーセンテージと、合計トレーニング時間も表示されます。
Cartpole の例または自分で試す方法の詳細については、「AI エージェントにバランスを取るように教える方法」を参照してください。
石油の掘削
水平石油掘削アプリケーションは、地下を水平に掘削する石油掘削装置を自動化するためのモーション コントローラーです。 オペレーターはジョイスティックで地下のドリルを制御して、障害物を回避しながらオイル シェールの内部にドリルを維持します。 掘削を高速にするため、ドリルではステアリング操作を可能な限り少なくします。 目標は、強化学習を使用して、水平石油掘削の制御を自動化することです。
使用可能なセンサー情報としては、ドリル ビットの力の向き、ドリル ビットの重さ、横方向の力、掘削の角度などがあります。 サポートされているエージェント アクションは、ドリル ビットを上、下、左、右に動かすことです。 プログラムでは、ドリルがチャンバーの壁の許容距離内にある場合に、肯定的な報酬が提供されます。 モデルでは、異なる油井プラン、ドリル開始位置、センサーの不正確さに適合することが学習されます。
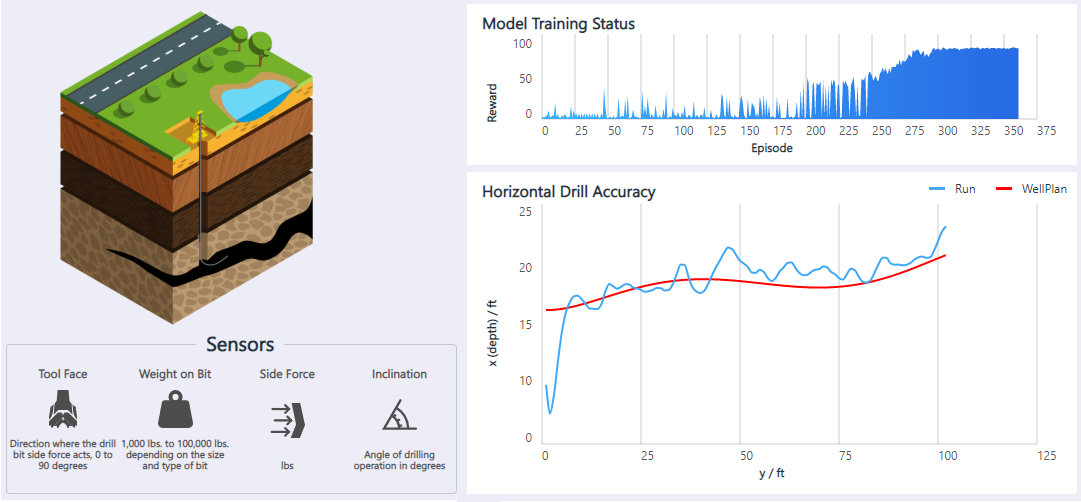
このソリューションの詳細とデモについては、「モーション コントロール: 水平石油掘削」を参照してください。
共同作成者
この記事は、Microsoft によって保守されています。 当初の寄稿者は以下のとおりです。
プリンシパル作成者:
- Jose Contreras | プリンシパル ソフトウェア エンジニアリング マネージャー
パブリックでない LinkedIn プロファイルを表示するには、LinkedIn にサインインします。
次のステップ
- 自律システムのための機械教示
- Microsoft AI を使用した自律システム
- 産業制御システムの自律性
- 機械教示: 人間の専門知識により、AI がどのようにしてさらに強力になるか
- Microsoft はエンジニアや開発者のために自律システム ツールの使用可能な範囲を広げる
- イノベーション空間: 自律システム (ビデオ)
- Microsoft の AI ブログ
- Aerial Informatics and Robotics Platform (AirSim)
- Gazebo
- Simulink
機械教示の詳細については、以下を参照してください。
- 「Bonsai、すべての人のための AI」、2016 年 3 月 2 日
- 「AI ユース ケース: 単なる簡単な例題以上のものを解決するイノベーション」、2017 年 3 月 2 日
- Patrice Y. Simard、Saleema Amershi、David M. Chickering、他、「機械教示: 機械学習システムを構築するための新しいパラダイム」、2017 年
- Carlos E. Perez、「ディープ教示: 将来の最も魅力的なジョブ」、2017 年 7 月 29 日
- Tambet Matiisen、「ディープ強化学習を分かりやすく説明する」、2015 年 12 月 19 日
- Andrej Karpathy、「ディープ強化学習: ピクセルからの Pong」、2016 年 5 月 31 日
- David Kestenbaum、「ポップ クイズ: 船長が乗客を殺さないようにするにはどうすればよいか」、2010 年 9 月 10 日