Azure SQL Database を使用して世界規模の可用性を備えたサービスを設計する
適用対象:![]() Azure SQL Database
Azure SQL Database
Azure SQL データベースを使用してクラウド サービスを構築してデプロイするときは、アクティブ geo レプリケーションまたはフェールオーバー グループを使用して、局地的な機能停止や致命的な障害に対する回復力を用意します。 同じ機能を使用して、データへのローカル アクセス向けに最適化された、世界規模で分散されたアプリケーションを作成することができます。 この記事では一般的なアプリケーション パターンについて説明したうえで、それぞれの選択肢の利点とトレードオフについて説明します。
Note
Premium または Business Critical データベースとエラスティック プールを使用している場合、これらをゾーン冗長デプロイ構成に変換することで、リージョン障害に対する回復性を与えることができます。 「ゾーン冗長データベース」をご覧ください。
シナリオ 1:最小限のダウンタイムでのビジネス継続性のための 2 つの Azure リージョンの使用
このシナリオのアプリケーションには次のような特徴があります。
- アプリケーションは 1 つの Azure リージョンでアクティブです
- すべてのデータベース セッションで、データの読み取りおよび書き込みアクセス (RW) が必要です
- 待機時間とトラフィック コストを減らすため、Web 層とデータ層を併置する必要があります
- 基本的に、このようなアプリケーションに対するビジネス リスクは、データの損失よりダウンタイムの方が高くなります
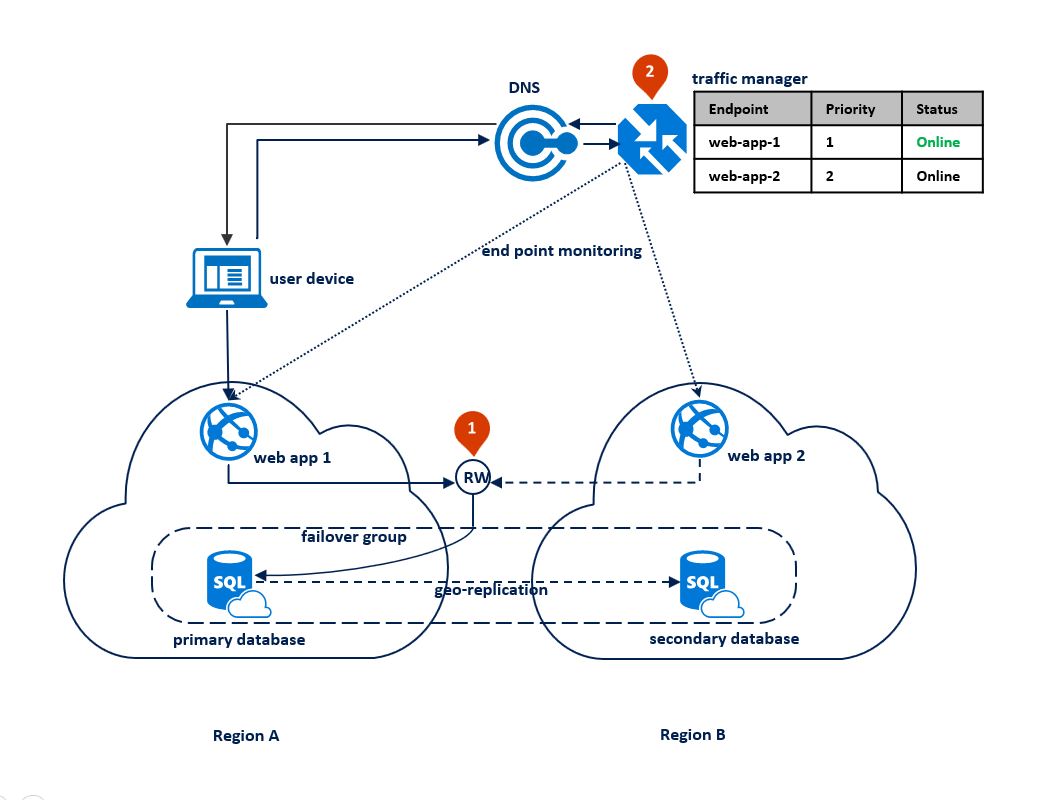
このケースでは、すべてのアプリケーション コンポーネントをまとめてフェールオーバーする必要があるとき、地域ごとの障害に対処するようにアプリケーションのデプロイ トポロジが最適化されます。 次の図にこのトポロジを示します。 地理的な冗長性の場合は、アプリケーションのリソースをリージョン A とリージョン B にデプロイします。ただし、リージョン B のリソースは、リージョン A で障害が発生するまで使われません。 データベース接続、レプリケーション、フェールオーバーを管理するため、2 つのリージョンの間にフェールオーバー グループを構成します。 両方のリージョンの Web サービスを、読み取り/書き込みリスナー <フェールオーバー グループ名>.database.windows.net を介してデータベースにアクセスするように構成します (1)。 優先順位によるルーティング方法を使うように Azure Traffic Manager を設定します (2)。
Note
Azure Traffic Manager は、あくまで例として使用しています。 優先順位によるルーティング方法に対応していればどのような負荷分散ソリューションを使ってもかまいません。
この構成の機能停止前の状態を示したのが次の図です。
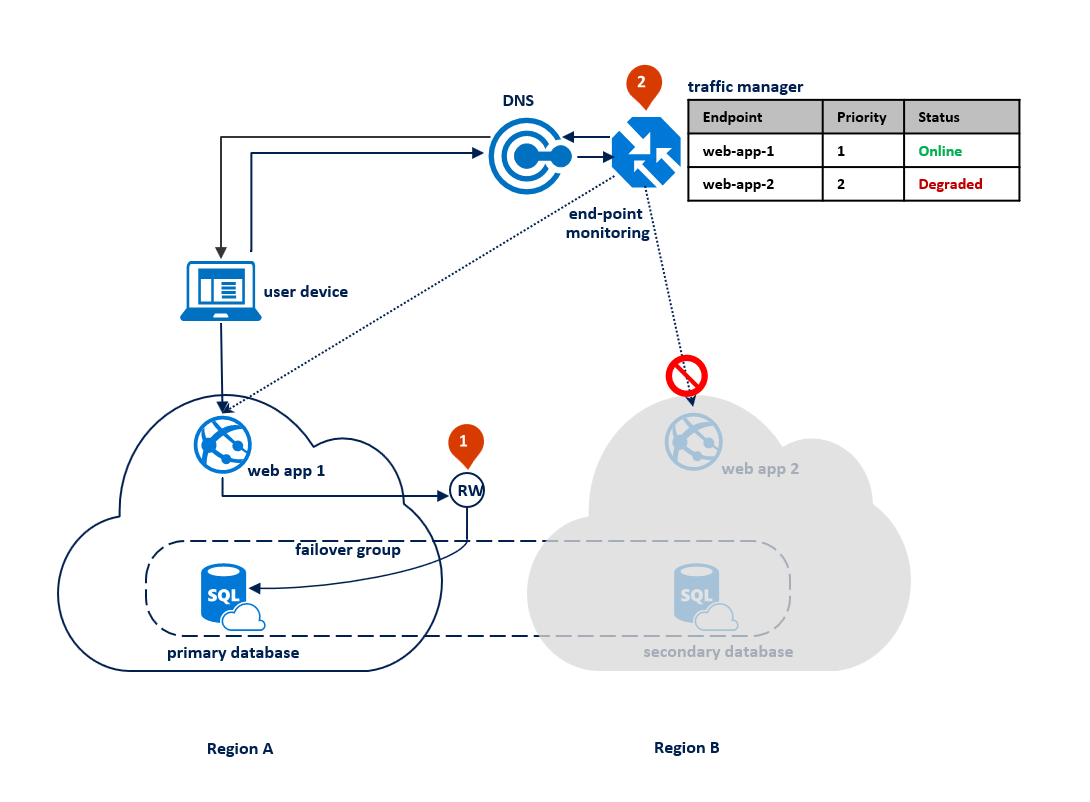
プライマリ リージョンで障害が発生すると、SQL Database によりプライマリ データベースにアクセスできないことが検出され、自動フェールオーバー ポリシーのパラメーターに基づいてセカンダリ リージョンへのフェールオーバーがトリガーされます (1)。 アプリケーションの SLA によっては、障害の検出からフェールオーバー発生までの時間を制御する猶予期間を構成できます。 フェールオーバー グループがデータベースのフェールオーバーをトリガーする前に、Azure Traffic Manager がエンドポイントのフェールオーバーを開始する可能性があります。 その場合、Web アプリケーションはデータベースにすぐに再接続できません。 ただし、データベースのフェールオーバーが完了すると、再接続は自動的に成功します。 障害が発生したリージョンは復元されてオンラインに戻り、古いプライマリは新しいセカンダリとして自動的に再接続します。 次の図では、フェールオーバー後の構成を示します。
Note
フェールオーバー後にコミットされたすべてのトランザクションは、再接続の間に失われます。 フェールオーバーが完了した後、リージョン B にアプリケーションは、再接続し、ユーザー要求の処理を再開できます。 Web アプリケーションとプライマリ データベースはどちらもリージョン B に存在するようになり、併置が維持されます。
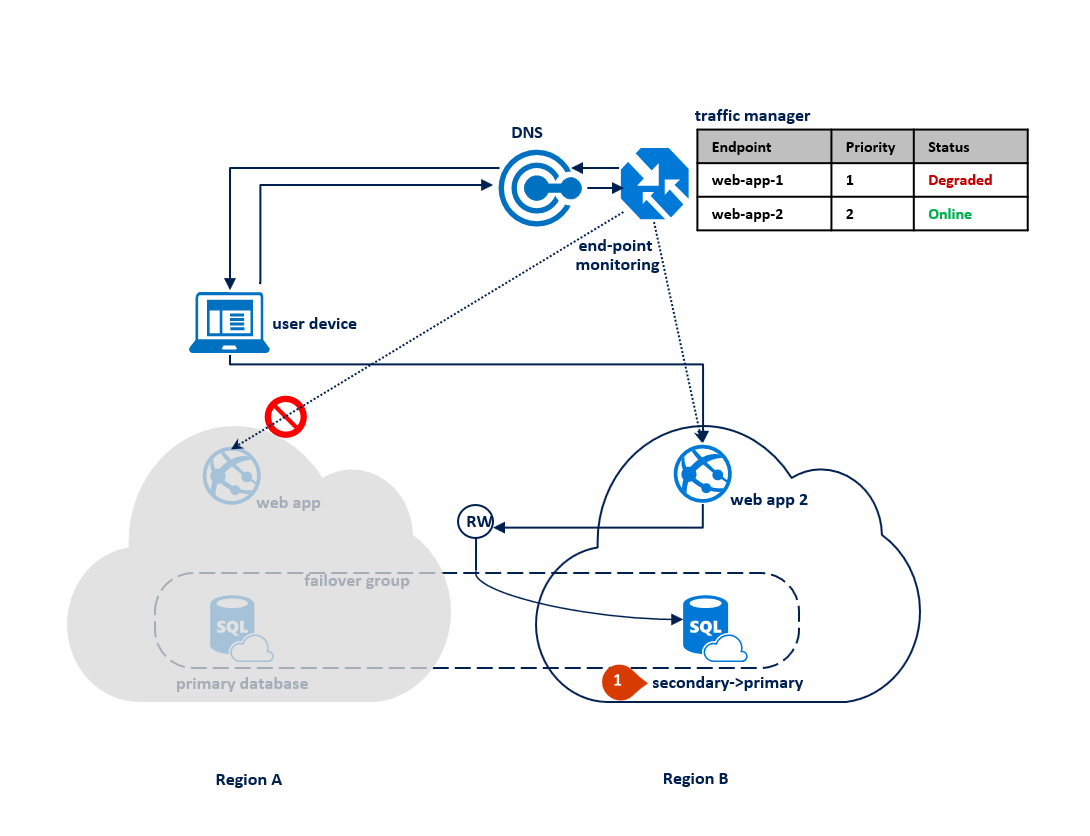
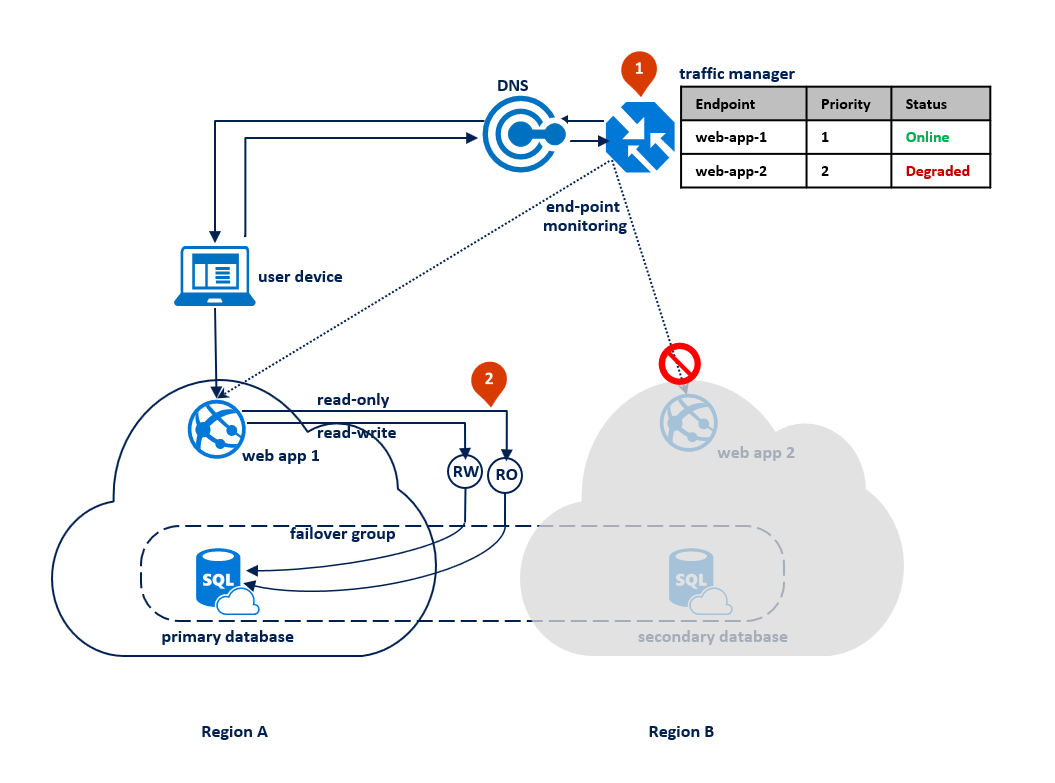
リージョン B の機能が停止した場合は、プライマリ データベースとセカンダリ データベースの間のレプリケーション プロセスは中断されますが、両者の間のリンクは維持されます (1)。 Traffic Manager でリージョン B への接続が失われたことが検出され、エンドポイントの Web アプリ 2 が "低下" とマークされます (2)。 このケースではアプリケーションのパフォーマンスは影響を受けませんが、データベースは保護されていない状態になり、続けてリージョン A で障害が発生するとデータ損失が起こる高いリスクがあります。
Note
ディザスター リカバリーのため、アプリケーションのデプロイ先を 2 つのリージョンに限定する構成にすることをお勧めします。 これは、Azure で地理的に割り当てられるリージョンがほとんどの場合 2 つだけであるからです。 この構成では、両方のリージョンで同時発生した致命的な障害からアプリケーションは保護されません。 万一そのような障害が発生した場合は、geo リストア操作を使って、第 3 のリージョンのデータベースを復元することができます。 詳しくは、「Azure SQL Database のディザスター リカバリー ガイダンス」をご覧ください。
停止していた機能が復旧すると、セカンダリ データベースがプライマリ データベースと自動的に再同期されます。 同期の間に、プライマリ データベースのパフォーマンスが低下することがあります。 具体的な影響は、フェールオーバー以降に新しいプライマリが取得したデータの量に依存します。
Note
機能停止が対処されると、Traffic Manager は、優先度が高いエンドポイントとしての、リージョン A にあるアプリケーションへの接続のルーティングを開始します。 プライマリをしばらくリージョン B のままにする場合は、それに応じて Traffic Manager プロファイルの優先順位テーブルを変更する必要があります。
次の図は、セカンダリ リージョンの機能が停止した場合の例です。
この設計パターンの主な 利点 は次のとおりです。
- 同じ Web アプリケーションがリージョン固有の構成なしで両方のリージョンにデプロイされ、フェールオーバーを管理するための追加ロジックは必要ありません。
- アプリケーションとデータベースが常に併置されるので、フェールオーバーが Web アプリケーションのパフォーマンスに影響することはありません。
主なトレードオフは、ほとんどの期間、リージョン B のアプリケーション リソースの使用率が低いことです。
シナリオ 2: データが最大限に保存されるビジネス継続性のための Azure リージョン
この設計パターンは、以下の特性を持ったアプリケーションに最適な選択肢です。
- 少しのデータ損失も多大なビジネス リスクを招く。 データベースのフェールオーバーはあくまで、機能停止が致命的な障害によるものである場合の最終手段です。
- アプリケーションは操作の読み取り専用または読み取り/書き込みモードをサポートし、一定時間は「読み取り専用モード」で機能します。
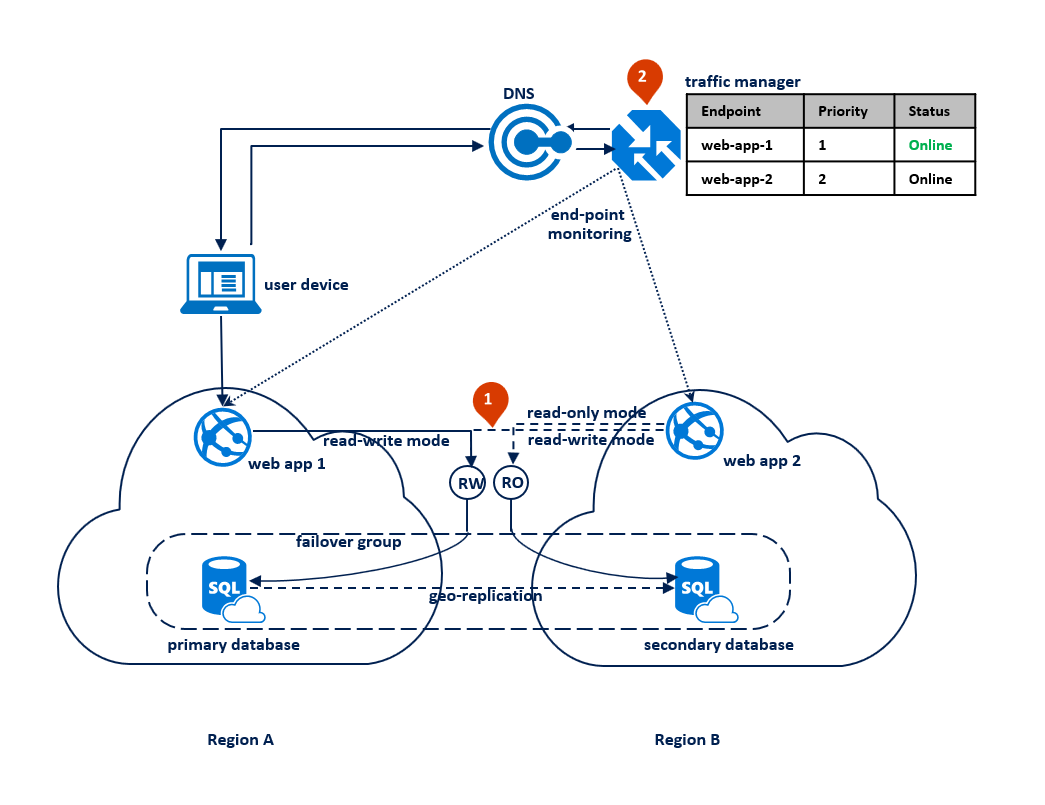
このパターンでは、読み取り/書き込み接続がタイムアウト エラーを受け取るようになったときにアプリケーションが読み取り専用モードに切り替わります。 Web アプリケーションは両方のリージョンにデプロイされ、読み取りおよび書き込みリスナー エンドポイントへの接続と、読み取り専用リスナー エンドポイントへの別の接続が含まれます (1)。 Traffic Manager プロファイルには、優先順位によるルーティングを使う必要があります。 各リージョンのアプリケーション エンドポイントで、エンドポイントの監視を有効にする必要があります (2)。
この構成の機能停止前の状態を示したのが次の図です。
Traffic Manager でリージョン A への接続障害が検出されると、ユーザーのトラフィックはリージョン B のアプリケーション インスタンスに自動的に切り替えられます。このパターンでは、データ消失の猶予期間を十分に高い値 (24 時間など) に設定することが重要です。 これにより、機能の停止がその期間内に対処された場合にデータ消失を防ぐことができます。 リージョン B の Web アプリケーションがアクティブになると、読み取りおよび書き込み操作が失敗するようになります。 その時点で、読み取り専用モードに切り替える必要があります (1)。 このモードでは、要求が自動的にセカンダリ データベースにルーティングされます。 停止の原因が致命的な障害である場合は、通常、猶予期間内に軽減することはできません。 期限が切れると、フェールオーバー グループはフェールオーバーをトリガーします。 その後、読み取り/書き込みリスナーが使用できるようになり、リスナーに対する接続は失敗しなくなります (2)。 次の図は、復旧プロセスの 2 つのステージを示したものです。
Note
プライマリ リージョンの停止していた機能が猶予期間内に対処された場合、プライマリ リージョンの接続の復旧で Traffic Manager で検出され、ユーザー トラフィックがリージョン A のアプリケーション インスタンスに戻されます。そのアプリケーション インスタンスはリージョン A のプライマリ データベースを使って読み取りおよび書き込みモードで再開され、運用されます (前の図を参照)。
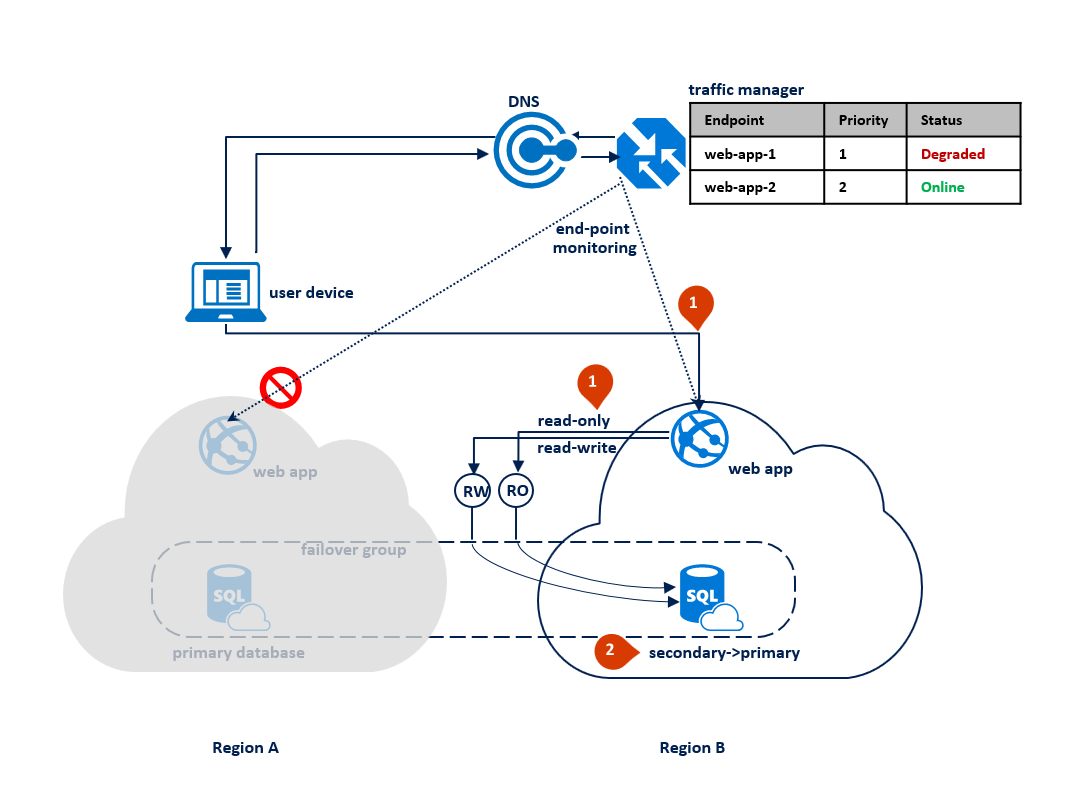
リージョン B が停止した場合、Traffic Manager でリージョン B のエンドポイント web-app-2 の障害が検出され、"低下" とマークされます (1)。 その間、フェールオーバー グループは読み取り専用リスナーをリージョン A に切り替えます (2)。 この停止はエンドユーザー エクスペリエンスに影響を与えませんが、停止中にプライマリ データベースが公開されます。 次の図は、セカンダリ リージョンで障害が発生した場合の例です。
機能停止が対処されると、セカンダリ データベースが即時にプライマリと同期され、読み取り専用リスナーがリージョン B のセカンダリ データベースに切り戻されます。同期対象のデータの量によっては、プライマリのパフォーマンスが同期中やや低下する場合があります。
この設計パターンには次のようにいくつかの 利点があります。
- 一時的な機能停止の間、データ損失を防ぐことができる。
- ダウンタイムを左右するのは、Traffic Manager が接続障害を検出するのにかかる時間のみであり、その時間は設定によって変更可能。
トレードオフは、アプリケーションは読み取り専用モードで動作できなければならないことです。
ビジネス継続性計画:クラウド障害復旧用のアプリケーション設計を選択する
実際のクラウド ディザスター リカバリー戦略では、対象アプリケーションのニーズに合わせて、これらの設計パターンを組み合わせたり拡張したりすることができます。 既に述べたように、選択すべき戦略は、利用者に提供する SLA とアプリケーションのデプロイ トポロジによって異なります。 以下の表では、意思決定の目安として、復旧ポイントの目標 (RPO) と推定復旧時間 (ERT) に基づいてそれぞれの選択肢を比較しています。
| Pattern | RPO | ERT |
|---|---|---|
| アクティブ/パッシブ デプロイとデータベース併置によるディザスター リカバリー | 読み取り/書き込みアクセス < 5 秒 | 障害検出時間 + DNS TLL |
| アクティブ/アクティブ デプロイによるアプリケーション負荷分散 | 読み取り/書き込みアクセス < 5 秒 | 障害検出時間 + DNS TLL |
| アクティブ/パッシブ デプロイによるデータ保存 | 読み取り専用アクセス < 5 秒 | 読み取り専用アクセス = 0 |
| 読み取り/書き込みアクセス = 0 | 読み取り/書き込みアクセス = 障害検出時間 + データ消失の猶予期間 |
次のステップ
- ビジネス継続性の概要およびシナリオについては、ビジネス継続性の概要を参照してください。
- アクティブ geo レプリケーションについては、アクティブ geo レプリケーションに関するページを参照してください。
- フェールオーバー グループについては、フェールオーバー グループに関するページを参照してください。
- エラスティック プールでのアクティブ geo レプリケーションについては、Elastic Pool のディザスター リカバリー戦略に関するページを参照してください。
フィードバック
以下は間もなく提供いたします。2024 年を通じて、コンテンツのフィードバック メカニズムとして GitHub の issue を段階的に廃止し、新しいフィードバック システムに置き換えます。 詳細については、「https://aka.ms/ContentUserFeedback」を参照してください。
フィードバックの送信と表示