オンライン エンドポイントを自動スケーリングする
[アーティクル]
04/04/2023
17 人の共同作成者
フィードバック
この記事の内容
適用対象: Azure CLI ml extension v2 (現行) Python SDK azure-ai-ml v2 (現行)
自動スケールでは、アプリケーションの負荷を処理するために適切な量のリソースが自動的に実行されます。 オンライン エンドポイント は、Azure Monitor 自動スケーリング機能との統合によって、自動スケールをサポートします。
Azure Monitor 自動スケーリング機能では、豊富なルール セットがサポートされています。 メトリックベースのスケーリング (たとえば、CPU 使用率 >70%)、スケジュールに基づくスケーリング (たとえば、営業時間のピーク時のルールのスケーリング)、またはその組み合わせを構成できます。 詳細については、「Microsoft Azure の自動スケールの概要 」を参照してください。
現在、自動スケールは、Azure CLI、REST、ARM、またはブラウザー ベースの Azure portal を使用して管理できます。 Python SDK などの他の Azure Machine Learning SDK によって、今後サポートが追加される予定です。
前提条件
自動スケール プロファイルの定義
エンドポイントに対して自動スケールを有効にするには、最初に自動スケール プロファイルを定義します。 このプロファイルでは、スケール セット容量の既定値、最小値、および最大値が定義されます。 次の例では、既定容量と最小容量を 2 つの VM インスタンスとして設定し、最大容量を 5 に設定します。
適用対象: Azure CLI ML 拡張機能 v2 (現行)
次のスニペットでは、エンドポイントとデプロイの名前を設定します。
# set your existing endpoint name
ENDPOINT_NAME=your-endpoint-name
DEPLOYMENT_NAME=blue
次に、デプロイとエンドポイントの Azure Resource Manager ID を取得します。
# ARM id of the deployment
DEPLOYMENT_RESOURCE_ID=$(az ml online-deployment show -e $ENDPOINT_NAME -n $DEPLOYMENT_NAME -o tsv --query "id")
# ARM id of the deployment. todo: change to --query "id"
ENDPOINT_RESOURCE_ID=$(az ml online-endpoint show -n $ENDPOINT_NAME -o tsv --query "properties.\"azureml.onlineendpointid\"")
# set a unique name for autoscale settings for this deployment. The below will append a random number to make the name unique.
AUTOSCALE_SETTINGS_NAME=autoscale-$ENDPOINT_NAME-$DEPLOYMENT_NAME-`echo $RANDOM`
次のスニペットでは、自動スケーリング プロファイルを作成します。
az monitor autoscale create \
--name $AUTOSCALE_SETTINGS_NAME \
--resource $DEPLOYMENT_RESOURCE_ID \
--min-count 2 --max-count 5 --count 2
適用対象 : Python SDK azure-ai-ml v2 (現行)
モジュールをインポートします。
from azure.ai.ml import MLClient
from azure.identity import DefaultAzureCredential
from azure.mgmt.monitor import MonitorManagementClient
from azure.mgmt.monitor.models import AutoscaleProfile, ScaleRule, MetricTrigger, ScaleAction, Recurrence, RecurrentSchedule
import random
import datetime
ワークスペース、エンドポイント、デプロイの変数を定義します。
subscription_id = "<YOUR-SUBSCRIPTION-ID>"
resource_group = "<YOUR-RESOURCE-GROUP>"
workspace = "<YOUR-WORKSPACE>"
endpoint_name = "<YOUR-ENDPOINT-NAME>"
deployment_name = "blue"
Azure Machine Learning および Azure Monitor のクライアントを取得します。
credential = DefaultAzureCredential()
ml_client = MLClient(
credential, subscription_id, resource_group, workspace
)
mon_client = MonitorManagementClient(
credential, subscription_id
)
エンドポイントとデプロイ オブジェクトを取得します。
deployment = ml_client.online_deployments.get(
deployment_name, endpoint_name
)
endpoint = ml_client.online_endpoints.get(
endpoint_name
)
自動スケーリング プロファイルを作成します。
# Set a unique name for autoscale settings for this deployment. The below will append a random number to make the name unique.
autoscale_settings_name = f"autoscale-{endpoint_name}-{deployment_name}-{random.randint(0,1000)}"
mon_client.autoscale_settings.create_or_update(
resource_group,
autoscale_settings_name,
parameters = {
"location" : endpoint.location,
"target_resource_uri" : deployment.id,
"profiles" : [
AutoscaleProfile(
name="my-scale-settings",
capacity={
"minimum" : 2,
"maximum" : 5,
"default" : 2
},
rules = []
)
]
}
)
Azure Machine Learning スタジオ で、ワークスペースを選択し、ページの左側から [エンドポイント] を選択します。 エンドポイントが一覧表示されたら、構成するエンドポイントを選択します。
エンドポイントの [詳細] タブから、 [自動スケーリングの構成] を選択します。
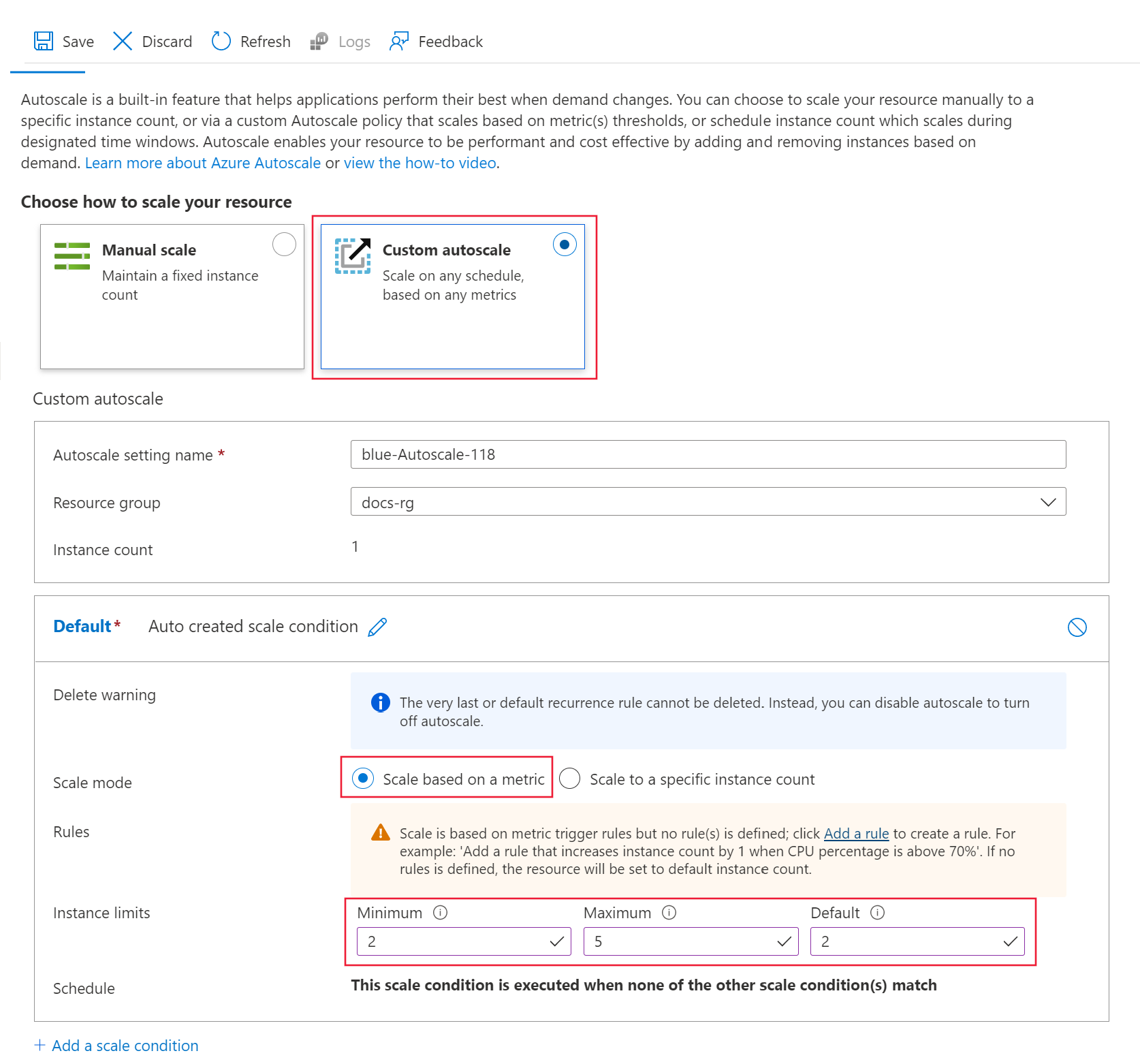
[リソースをスケーリングする方法を選択します] の下で、 [カスタム自動スケーリング] を選択し、構成を開始します。 既定のスケール条件については、次の値を使用します。
[スケール モード] を [メトリックに基づいてスケーリングする] に設定します。[最小値] を 2 に設定します。[最大値] を 5 に設定します。[既定値] を 2 に設定します。
メトリックを使用してスケールアウトするルールを作成する
一般的なスケールアウト ルールは、平均 CPU 負荷が高い場合に VM インスタンスの数を増やすというルールです。 次の例では、5 分間の CPU 平均負荷が 70% を超える場合に、さらに 2 つのノード (最大) を割り当てます。
適用対象: Azure CLI ML 拡張機能 v2 (現行)
az monitor autoscale rule create \
--autoscale-name $AUTOSCALE_SETTINGS_NAME \
--condition "CpuUtilizationPercentage > 70 avg 5m" \
--scale out 2
このルールは my-scale-settings プロファイルに含まれます (autoscale-name はプロファイルの name と一致)。 その condition 引数の値は、"VM インスタンス間の平均 CPU 消費量が 5 分間で 70% を超えた場合にルールがトリガーされる" となっています。その条件が満たされた場合は、さらに 2 つの VM インスタンスが割り当てられます。
適用対象 : Python SDK azure-ai-ml v2 (現行)
ルール定義を作成します。
rule_scale_out = ScaleRule(
metric_trigger = MetricTrigger(
metric_name="CpuUtilizationPercentage",
metric_resource_uri = deployment.id,
time_grain = datetime.timedelta(minutes = 1),
statistic = "Average",
operator = "GreaterThan",
time_aggregation = "Last",
time_window = datetime.timedelta(minutes = 5),
threshold = 70
),
scale_action = ScaleAction(
direction = "Increase",
type = "ChangeCount",
value = 2,
cooldown = datetime.timedelta(hours = 1)
)
)
このルールは、引数 metric_name、time_window、time_aggregation からの最後の 5 分間の CPUUtilizationpercentage の平均を参照します。 メトリックの値が threshold 70 より大きい場合、さらに 2 つの VM インスタンスが割り当てられます。
my-scale-settings プロファイルを更新して、この規則を含めます。
mon_client.autoscale_settings.create_or_update(
resource_group,
autoscale_settings_name,
parameters = {
"location" : endpoint.location,
"target_resource_uri" : deployment.id,
"profiles" : [
AutoscaleProfile(
name="my-scale-settings",
capacity={
"minimum" : 2,
"maximum" : 5,
"default" : 2
},
rules = [
rule_scale_out
]
)
]
}
)
[ルール] セクションで、 [ルールの追加] を選択します。 [スケール ルール] ページが表示されます。 次の情報を使用して、このページのフィールドにデータを入力します。
[メトリック名] を [CPU Utilization Percentage] (CPU 使用率) に設定します。[演算子] を [より大きい] に設定し、 [メトリックのしきい値] を 70 に設定します。[期間 (分)] を 5 に設定します。 [時間グレインの統計] は [Average] のままにしておきます。[操作] を [カウントを増やす量] に設定し、 [インスタンス数] を 2 に設定します。
最後に、 [追加] ボタンを選択してルールを作成します。
メトリックを使用してスケールインするルールを作成する
負荷が軽い場合、スケールインのルールを使用することで、VM インスタンスの数を減らすことができます。 次の例では、CPU 負荷が 5 分間 30% 未満の場合、下限 2 まで、1 つのノードを解放します。
適用対象: Azure CLI ML 拡張機能 v2 (現行)
az monitor autoscale rule create \
--autoscale-name $AUTOSCALE_SETTINGS_NAME \
--condition "CpuUtilizationPercentage < 25 avg 5m" \
--scale in 1
適用対象 : Python SDK azure-ai-ml v2 (現行)
ルール定義を作成します。
rule_scale_in = ScaleRule(
metric_trigger = MetricTrigger(
metric_name="CpuUtilizationPercentage",
metric_resource_uri = deployment.id,
time_grain = datetime.timedelta(minutes = 1),
statistic = "Average",
operator = "LessThan",
time_aggregation = "Last",
time_window = datetime.timedelta(minutes = 5),
threshold = 30
),
scale_action = ScaleAction(
direction = "Increase",
type = "ChangeCount",
value = 1,
cooldown = datetime.timedelta(hours = 1)
)
)
my-scale-settings プロファイルを更新して、この規則を含めます。
mon_client.autoscale_settings.create_or_update(
resource_group,
autoscale_settings_name,
parameters = {
"location" : endpoint.location,
"target_resource_uri" : deployment.id,
"profiles" : [
AutoscaleProfile(
name="my-scale-settings",
capacity={
"minimum" : 2,
"maximum" : 5,
"default" : 2
},
rules = [
rule_scale_out,
rule_scale_in
]
)
]
}
)
[ルール] セクションで、 [ルールの追加] を選択します。 [スケール ルール] ページが表示されます。 次の情報を使用して、このページのフィールドにデータを入力します。
[メトリック名] を [CPU Utilization Percentage] (CPU 使用率) に設定します。[演算子] を [より小さい] に設定し、 [メトリックのしきい値] を 30 に設定します。[期間 (分)] を 5 に設定します。[操作] を [カウントを減らす量] に設定し、 [インスタンス数] を 1 に設定します。
最後に、 [追加] ボタンを選択してルールを作成します。
スケールアウト ルールとスケールイン ルールの両方がある場合、ルールは次のスクリーンショットのようになります。 平均 CPU 負荷が 5 分間で 70% を超える場合は、上限 5 まで、さらに 2 つのノードを割り当てる必要があると指定しました。 CPU 負荷が 5 分間 30% 未満の場合は、下限 2 まで、1 つのノードを解放する必要があります。
エンドポイント メトリックに基づいてスケーリング ルールを作成する
前のルールがデプロイに適用されました。 次に、エンドポイントに適用されるルールを追加します。 この例では、要求の待機時間が 5 分間、平均 70 ミリ秒を超える場合、別のノードを割り当てる必要があります。
適用対象: Azure CLI ML 拡張機能 v2 (現行)
az monitor autoscale rule create \
--autoscale-name $AUTOSCALE_SETTINGS_NAME \
--condition "RequestLatency > 70 avg 5m" \
--scale out 1 \
--resource $ENDPOINT_RESOURCE_ID
適用対象 : Python SDK azure-ai-ml v2 (現行)
ルール定義を作成します。
rule_scale_out_endpoint = ScaleRule(
metric_trigger = MetricTrigger(
metric_name="RequestLatency",
metric_resource_uri = endpoint.id,
time_grain = datetime.timedelta(minutes = 1),
statistic = "Average",
operator = "GreaterThan",
time_aggregation = "Last",
time_window = datetime.timedelta(minutes = 5),
threshold = 70
),
scale_action = ScaleAction(
direction = "Increase",
type = "ChangeCount",
value = 1,
cooldown = datetime.timedelta(hours = 1)
)
)
このルールの metric_resource_uri フィールドは、デプロイではなくエンドポイントを参照するようになります。
my-scale-settings プロファイルを更新して、この規則を含めます。
mon_client.autoscale_settings.create_or_update(
resource_group,
autoscale_settings_name,
parameters = {
"location" : endpoint.location,
"target_resource_uri" : deployment.id,
"profiles" : [
AutoscaleProfile(
name="my-scale-settings",
capacity={
"minimum" : 2,
"maximum" : 5,
"default" : 2
},
rules = [
rule_scale_out,
rule_scale_in,
rule_scale_out_endpoint
]
)
]
}
)
ページの下部にある + Add a scale condition(+ スケール条件の追加) を選択します。
[メトリックに基づいてスケーリングする] を選択してから、 [ルールの追加] を選択します。 [スケール ルール] ページが表示されます。 次の情報を使用して、このページのフィールドにデータを入力します。
[メトリック ソース] を [その他のリソース] に設定します。[リソースの種類] を [機械学習オンライン エンドポイント] に設定します。[リソース] をエンドポイントに設定します。[メトリック名] を [要求の待機時間] に設定します。[演算子] を [より大きい] に設定し、 [メトリックのしきい値] を 70 に設定します。[期間 (分)] を 5 に設定します。[操作] を [カウントを増やす量] に設定し、 [インスタンス数] を 1 に設定します。
スケジュールに基づいてスケーリング ルールを作成する
特定の日または特定の時間にのみ適用されるルールを作成することもできます。 この例では、週末のノード数が 2 に設定されています。
適用対象: Azure CLI ML 拡張機能 v2 (現行)
az monitor autoscale profile create \
--name weekend-profile \
--autoscale-name $AUTOSCALE_SETTINGS_NAME \
--min-count 2 --count 2 --max-count 2 \
--recurrence week sat sun --timezone "Pacific Standard Time"
適用対象 : Python SDK azure-ai-ml v2 (現行)
mon_client.autoscale_settings.create_or_update(
resource_group,
autoscale_settings_name,
parameters = {
"location" : endpoint.location,
"target_resource_uri" : deployment.id,
"profiles" : [
AutoscaleProfile(
name="Default",
capacity={
"minimum" : 2,
"maximum" : 2,
"default" : 2
},
recurrence = Recurrence(
frequency = "Week",
schedule = RecurrentSchedule(
time_zone = "Pacific Standard Time",
days = ["Saturday", "Sunday"],
hours = [],
minutes = []
)
)
)
]
}
)
ページの下部にある + Add a scale condition(+ スケール条件の追加) を選択します。 新しいスケール条件で、次の情報を使用してフィールドに値を入力します。
[特定のインスタンス数にスケーリングする] を選択します。[インスタンス数] を 2 に設定します。[スケジュール] を [特定の曜日に繰り返す] に設定します。[繰り返し間隔] のスケジュールを [土曜日] と [日曜日] に設定します。
リソースを削除する
デプロイを使用しない場合は、次のように削除します。
適用対象: Azure CLI ML 拡張機能 v2 (現行)
# delete the autoscaling profile
az monitor autoscale delete -n "$AUTOSCALE_SETTINGS_NAME"
# delete the endpoint
az ml online-endpoint delete --name $ENDPOINT_NAME --yes --no-wait
適用対象 : Python SDK azure-ai-ml v2 (現行)
mon_client.autoscale_settings.delete(
resource_group,
autoscale_settings_name
)
ml_client.online_endpoints.begin_delete(endpoint_name)
次の手順
Azure Monitor を使用した自動スケーリングの詳細については、次の記事を参照してください。
 Azure CLI ml extension v2 (現行)
Azure CLI ml extension v2 (現行)
![エンドポイントの詳細の [自動スケーリングの構成] リンクのスクリーンショット。](media/how-to-autoscale-endpoints/configure-auto-scaling.png?view=azureml-api-2)