Azure Machine Learning によってキュレーションされたオープンソースの基盤モデルを使用する方法
この記事では、モデル カタログ内の基礎モデルを微調整、評価、デプロイする方法について説明します。
モデル カードのサンプル推論フォームを使用して、事前トレーニング済みモデルをすばやくテストし、結果をテストするための独自のサンプル入力を提供できます。 さらに、各モデルのモデル カードには、モデルの簡単な説明と、モデルの推論、微調整、評価に関するコード ベースのサンプルへのリンクが含まれています。
独自のテスト データを使用して基盤モデルを評価する方法
テスト データセットに対して基盤モデルを評価するために、評価 UI フォームを使用するか、モデル カードからリンクされたコード ベースのサンプルを使用できます。
スタジオを使用した評価
任意の基盤モデルのモデル カードの [評価] ボタンをクリックして、[モデルの評価] フォームを呼び出すことができます。
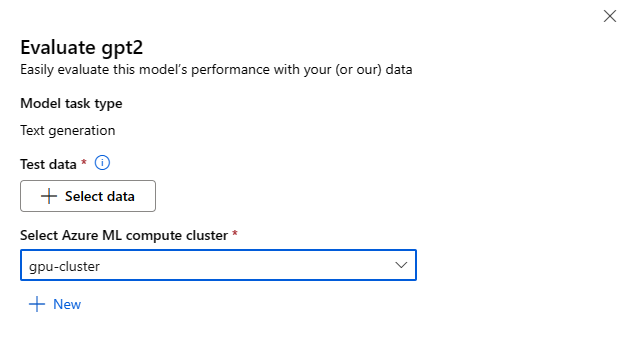
各モデルは、そのモデルが使用される特定の推論タスクについて評価できます。
テスト データ:
- モデルの評価に使用するテスト データを渡します。 ローカル ファイル (JSONL 形式) をアップロードするか、ワークスペースから既存の登録済みデータセットを選ぶかを選択できます。
- データセットを選択したら、タスクに必要なスキーマに基づいて、入力データの列をマップする必要があります。 たとえば、テキスト分類の '文' キーと 'ラベル' キーに対応する列名をマップします

コンピューティング:
モデルの微調整に使用する Azure Machine Learning コンピューティング クラスターを指定します。 評価は GPU コンピューティングで実行する必要があります。 使用するコンピューティング SKU に十分なコンピューティング クォータがあることを確認します。
評価フォームで [完了] を選んで、評価ジョブを送信します。 ジョブが完了すると、モデルの評価メトリックを表示できます。 評価メトリックに基づいて、独自のトレーニング データを使用してモデルを微調整するかどうかを決定できます。 さらに、モデルを登録してエンドポイントにデプロイするかどうかを決定できます。
コード ベースのサンプルを使用した評価
ユーザーがモデルの評価を開始できるように、azureml-examples の Git リポジトリの評価サンプルにサンプル (Python ノートブックと CLI の例の両方) が公開されています。 各モデル カードは、対応するタスクの評価サンプルにもリンクされています
独自のトレーニング データを使用して基盤モデルを微調整する方法
ワークロードでモデルのパフォーマンスを向上させるために、独自のトレーニング データを使用して基盤モデルを微調整する必要がある場合があります。 これらの基盤モデルを簡単に微調整するには、スタジオの微調整設定を使用するか、モデル カードからリンクされたコード ベースのサンプルを使用します。
スタジオを使用して微調整する
任意の基盤モデルのモデル カードの [微調整] ボタンを選択して、微調整設定フォームを呼び出すことができます。
微調整設定:
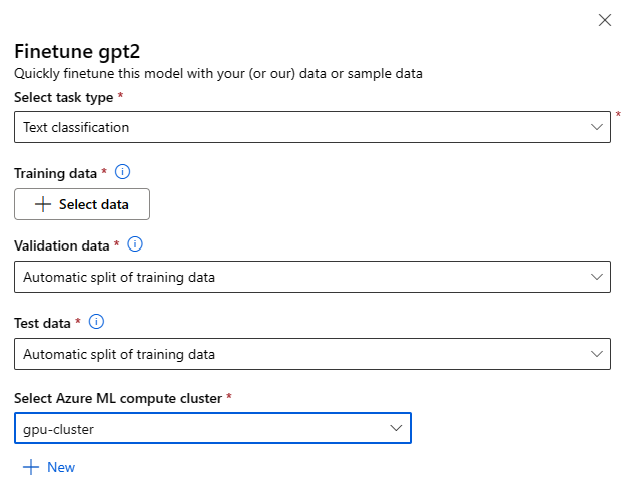
タスクの種類の微調整
- モデル カタログのすべての事前トレーニング済みモデルは、特定のタスク セット (テキスト分類、トークン分類、質問応答など) に対して微調整できます。 ドロップダウンから使用するタスクを選びます。
トレーニング データ
モデルの微調整に使用するトレーニング データを渡します。 ローカル ファイル (JSONL、CSV または TSV 形式) をアップロードするか、ワークスペースから既存の登録済みデータセットを選ぶかを選択できます。
データセットを選択したら、タスクに必要なスキーマに基づいて、入力データの列をマップする必要があります。 たとえば、テキスト分類の '文' キーと 'ラベル' キーに対応する列名をマップします

- 検証データ: モデルの検証に使用するデータを渡します。 [自動分割] を選ぶと、トレーニング データの自動分割が検証用に予約されます。 または、別の検証データセットを指定することもできます。
- テスト データ: 微調整したモデルの評価に使用するテスト データを渡します。 [自動分割] を選ぶと、トレーニング データの自動分割がテスト用に予約されます。
- コンピューティング: モデルの微調整に使用する Azure Machine Learning コンピューティング クラスターを指定します。 微調整は GPU コンピューティングで実行する必要があります。 微調整を行うときは、A100/V100 GPU でコンピューティング SKU を使用することをお勧めします。 使用するコンピューティング SKU に十分なコンピューティング クォータがあることを確認します。
- 微調整フォームで [完了] を選択して、微調整ジョブを送信します。 ジョブが完了すると、微調整したモデルの評価メトリックを表示できます。 その後、微調整ジョブによって微調整されたモデル出力を登録し、推論のためにこのモデルをエンドポイントにデプロイできます。
コード ベースのサンプルを使用した微調整
現在、Azure Machine Learning では、次の言語タスクのモデルの微調整がサポートされています。
- テキスト分類
- トークンの分類
- 質問応答
- 概要
- 翻訳
ユーザーが微調整をすばやく開始できるように、azureml-examples の Git リポジトリの微調整サンプルに、各タスクのサンプル (Python ノートブックと CLI の例の両方) が公開されています。 各モデル カードは、サポートされている微調整タスクの微調整サンプルにもリンクされています。
推論のためにエンドポイントに基盤モデルをデプロイする
基盤モデルを、推論に使用できるエンドポイントにデプロイできます。これらの基盤モデルには、モデル カタログから事前トレーニングされたモデルと、ワークスペースに登録された微調整されたモデルの両方が含まれます。 リアル タイム エンドポイントとバッチ エンドポイントの両方へのデプロイがサポートされています。 これらのモデルをデプロイするには、UI の展開ウィザードを使用するか、モデル カードからリンクされたコード ベースのサンプルを使用します。
スタジオを使用したデプロイ
デプロイ UI フォームを呼び出すには、任意の基盤モデルのモデル カードの [デプロイ] ボタンをクリックし、[リアルタイム エンドポイント] または [バッチ エンドポイント] を選択します

展開の設定
スコアリング スクリプトと環境は基盤モデルに自動的に含まれるため、指定する必要があるのは、使用する仮想マシン SKU、インスタンスの数、デプロイに使用するエンドポイント名だけです。
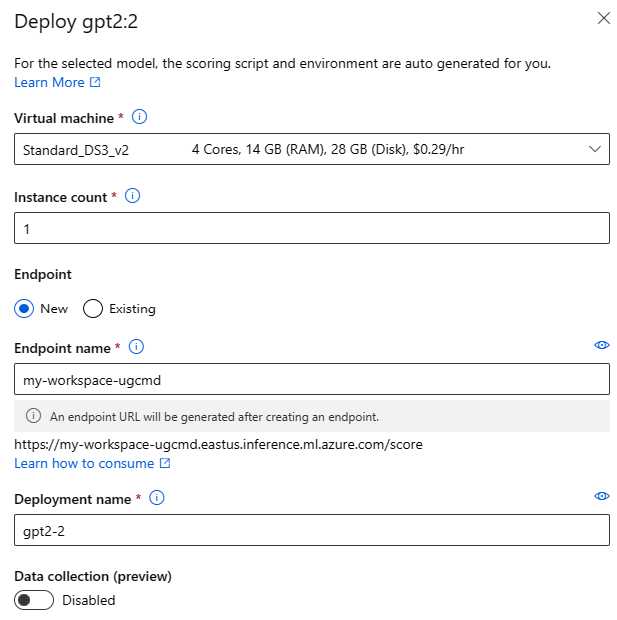
共有クォータ
モデル カタログから Llama-2、Phi、Nemotron、Mistral、Dolly または Deci-DeciLM のモデルをデプロイしているものの、デプロイに十分なクォータがない場合、Azure Machine Learning では、共有クォータ プールからのクォータを限られた時間使用できます。 共有クォータの詳細については、[Azure Machine Learning 共有クォータ を参照してください。

コード ベースのサンプルを使用したデプロイ
ユーザーがデプロイと推論をすばやく開始できるように、azureml-examples の Git リポジトリの推論サンプルに、サンプルが公開されています。 公開されているサンプルには、Python ノートブックと CLI の例が含まれます。 各モデル カードは、リアル タイムおよびバッチ推論の推論サンプルにもリンクされています。
基盤モデルのインポート
モデル カタログに含まれていないオープンソース モデルを使用する場合は、Hugging Face から Azure Machine Learning ワークスペースにモデルをインポートできます。 Hugging Face は、一般的な NLP タスク用に事前トレーニング済みのモデルを提供する自然言語処理 (NLP) 用のオープンソース ライブラリです。 現時点では、モデル インポート ノートブックに記載されている要件をモデルが満たしている限り、モデル インポートでは次のタスクのモデルのインポートがサポートされています。
- fill-mask
- token-classification
- question-answering
- summarization (概要)
- text-generation
- text-classification
- 変換 (translation)
- image-classification
- text-to-image
注意
Hugging Face のモデルには、Hugging Face モデルの詳細ページで入手可能なサードパーティ ライセンス条項が適用されます。 モデルのライセンス条項を遵守するのは、お客様の責任です。
モデル カタログの右上にある [インポート] ボタンを選択すると、モデル インポート ノートブックを使用できます。
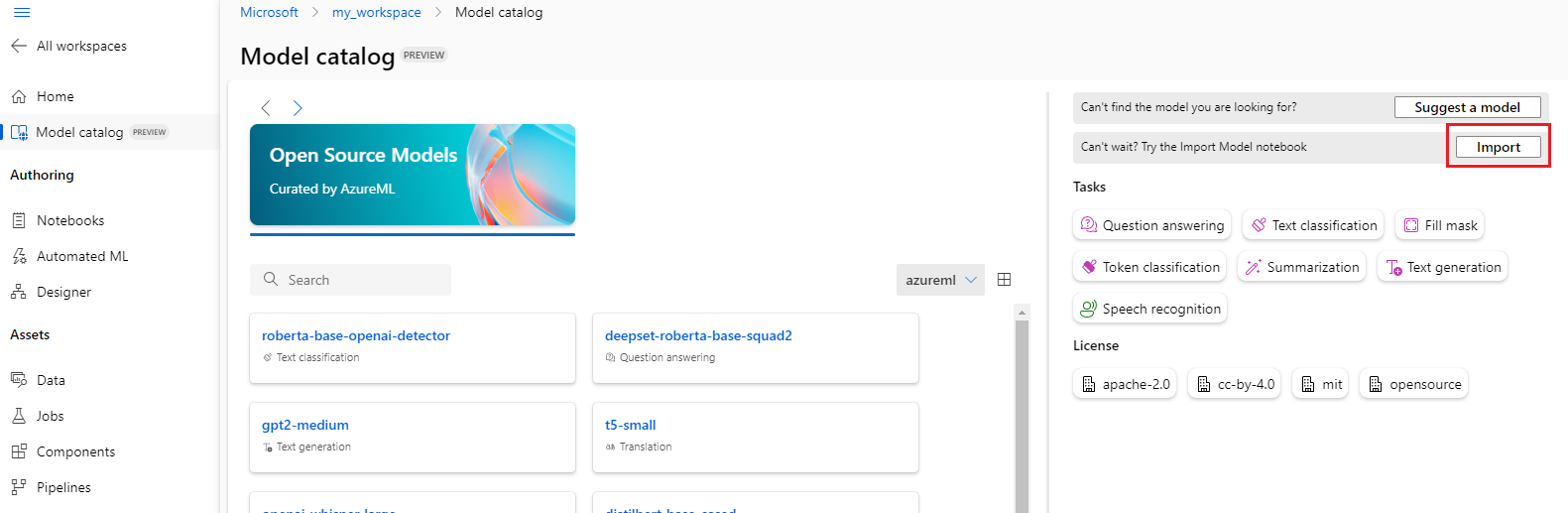
モデル インポート ノートブックは、こちらの azureml-examples の Git リポジトリにも含まれています。
モデルをインポートするには、Hugging Face からインポートするモデルの MODEL_ID を渡す必要があります。 Hugging Face ハブでモデルを参照し、インポートするモデルを特定します。 モデルのタスクの種類が、サポートされているタスクの種類の 1 つであることを確認します。 モデル ID をコピーします。これはページの URI で使用できます。または、モデル名の横にあるコピー アイコンを使用してコピーできます。 モデル インポート ノートブックの変数 'MODEL_ID' に割り当てます。 次に例を示します。
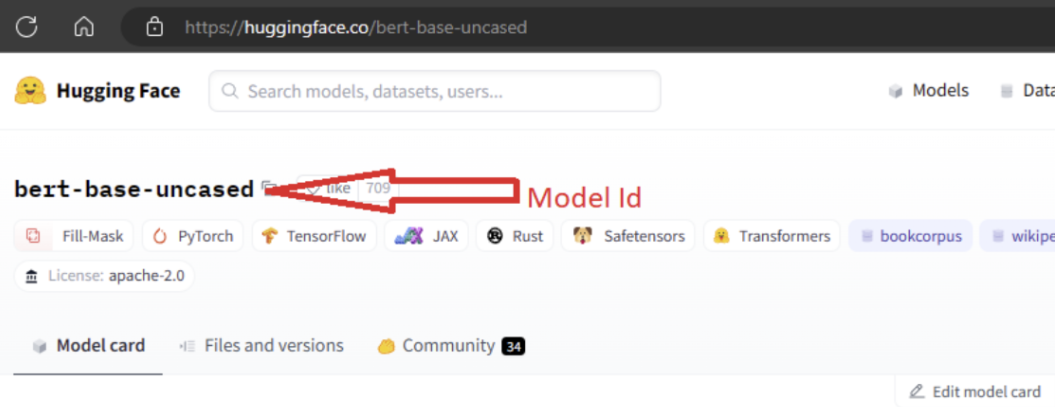
モデルのインポートを実行するには、コンピューティングを提供する必要があります。 モデル インポートを実行すると、指定したモデルが Hugging Face からインポートされ、Azure Machine Learning ワークスペースに登録されます。 その後、このモデルを微調整するか、推論のためにエンドポイントにデプロイできます。
詳細情報
- Azure Machine Learning スタジオでモデル カタログを調べます。 カタログを調べるには、Azure Machine Learning ワークスペースが必要です。
- モデル カタログとコレクションについて確認する