データ コネクタの正常性を監視する
Microsoft Sentinel サービスでの完全で中断のないデータ インジェストを確保するために、データ コネクタの正常性、接続性、パフォーマンスを追跡します。
次の機能で、Microsoft Sentinel からこの監視を実行できます。
データ収集の正常性監視ブック: このブックには、追加の監視機能を提供し、異常を検出し、ワークスペースのデータ インジェストの状態に関する分析情報を提供します。 ブックのロジックを使用して、取り込まれたデータの全般的な正常性を監視したり、カスタム ビューやルールベースのアラートを作成したりすることができます。
SentinelHealth データ テーブル (プレビュー): このテーブルに対してクエリを実行すると、コネクタごとの最新の障害イベントや、成功状態から失敗状態に変化したコネクタなどの、正常性ドリフトに関する分析情報が提供されます。これを使用して、アラートや他の自動アクションを作成できます。 SentinelHealth データ テーブルは、現在、一部のデータ コネクタでのみサポートされています。
重要
SentinelHealth データ テーブルは、現在、プレビュー段階です。 ベータ版、プレビュー版、または一般提供としてまだリリースされていない Azure の機能に適用されるその他の法律条項については、「Microsoft Azure プレビューの追加使用条件」を参照してください。
接続されている SAP システムの正常性と状態を表示する: SAP データ コネクタで SAP システムの正常性情報を確認し、アラート ルール テンプレートを使用して SAP エージェントのデータ収集の正常性に関する情報を取得します。
正常性監視ブックを使用する
Microsoft Sentinel ポータルで、ナビゲーション メニューの [コンテンツ管理] セクションから [コンテンツ ハブ] を選択します。
[コンテンツ ハブ] で、検索バーに「正常性」と入力し、結果から [データ収集の正常性の監視] を選択します。
詳細ウィンドウから [インストール] を選択します。 ブックがインストールされていることを示す通知メッセージが表示される場合、または [インストール] ではなく [構成] が表示される場合は、次の手順に進みます。
ナビゲーション メニューの [脅威管理] セクションで [ブック] を選択します。
[ブック] ページで [テンプレート] タブを選択し、検索バーに「正常性」と入力し、結果から [データ収集の正常性の監視] を選択します。
ブックをそのまま使用するには [テンプレートの表示] を選択し、ブックの編集可能なコピーを作成するには [保存] を選択します。 コピーが作成されたら、 [保存されたブックの表示] を選択します。
ブック内で、最初に表示したいサブスクリプションとワークスペースを選択した後、必要に応じてデータをフィルター処理するための TimeRange を定義します。 [ヘルプの表示] トグルを使用すると、ブックの組み込みの説明が表示されます。


このブックには、次の 3 つのタブ付きセクションがあります。
[概要] タブには、選択されたワークスペース内のデータ インジェストの全般的な状態 (ボリュームのメジャー、EPS 率、最後のログ受信時刻) が表示されます。
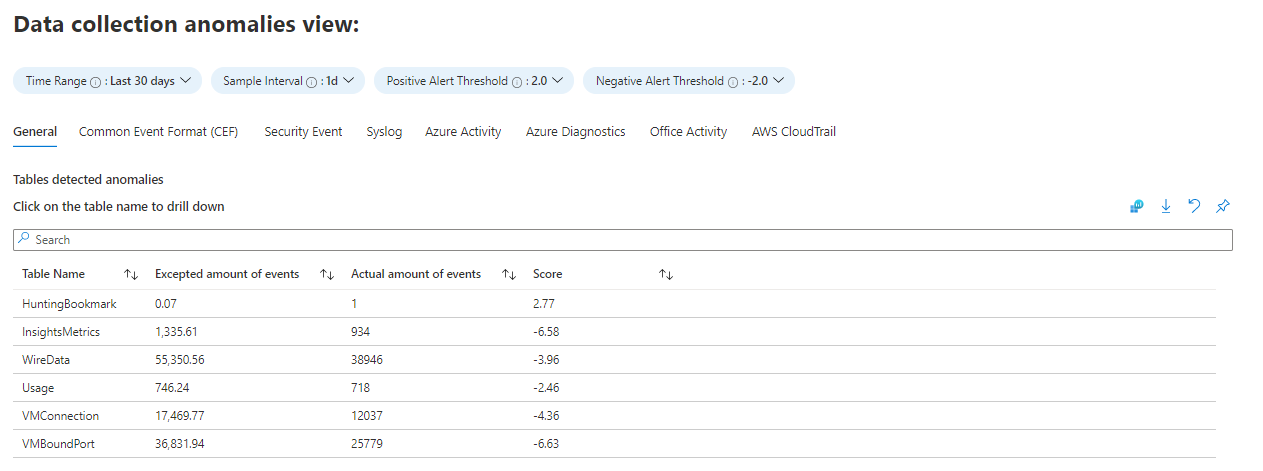
[データ収集の異常] タブでは、テーブルとデータ ソースによってデータ収集プロセスの異常を検出できます。 各タブには、特定のテーブルの異常が表示されます ( [全般] タブには、テーブルのコレクションが含まれています)。 異常は、異常スコアを返す series_decompose_anomalies() 関数を使用して計算されます。 この関数については、こちらを参照してください。 評価する関数に次のパラメーターを設定します。
AnomaliesTimeRange:この時刻の選択は、データ収集の異常ビューにのみ適用されます。
SampleInterval:指定された時間範囲内にデータがサンプリングされる時間間隔。 異常スコアは、最後の間隔のデータに対してのみ計算されます。
PositiveAlertThreshold:この値は、正の異常スコアのしきい値を定義します。 これは 10 進値を受け入れます。
NegativeAlertThreshold:この値は、負の異常スコアのしきい値を定義します。 これは 10 進値を受け入れます。
[エージェントの情報] タブには、さまざまなマシン (Azure VM、他のクラウド VM、オンプレミスの VM、または物理) にインストールされている Log Analytics エージェントの正常性に関する情報が表示されます。 以下のものを監視できます。
システムの場所
ハートビートの状態と待機時間
使用可能なメモリとディスク領域
エージェントの操作
このセクションでは、マシンの環境を説明するタブを選択する必要があります。Azure Arc で管理されているマシンのみを表示する場合は、 [Azure で管理されているマシン] タブを選択します。Log Analytics エージェントがインストールされている管理対象および Azure 以外のマシンの両方を表示するには、 [すべてのマシン] タブを選択します。



SentinelHealth データ テーブル (パブリック プレビュー) を使用する
SentinelHealth データ テーブルからデータ コネクタの正常性データを取得するには、最初に、ワークスペースの Microsoft Sentinel 正常性機能を有効にする必要があります。 詳細については、「Microsoft Sentinel の正常性監視を有効にする」を参照してください。
正常性機能が有効になると、データ コネクタに関して生成された最初の成功または失敗イベントで SentinelHealth データ テーブルが作成されます。
サポートされているデータ コネクタ
SentinelHealth データ テーブルは、現在、次のデータ コネクタでのみサポートされています。
- アマゾン ウェブ サービス (CloudTrail および S3)
- Dynamics 365
- Office 365
- Microsoft Defender for Endpoint
- 脅威インテリジェンス - TAXII
- 脅威インテリジェンス プラットフォーム
SentinelHealth テーブル イベントについて
SentinelHealth テーブルには、次の種類の正常性イベントが記録されます。
データフェッチの状態の変更。 データ コネクタの状態が安定していて、継続的に成功イベントまたは失敗 イベントが発生している限り、1 時間に 1 回、ログに記録されます。 余分な監査を防ぎ、テーブル サイズを小さくするために、データ コネクタの状態が変化しない限り、監視は 1 時間ごとにのみ機能します。 データ コネクタの状態が継続的に失敗となる場合は、失敗に関する追加情報が ExtendedProperties 列に含まれます。
データ コネクタの状態が、成功から失敗に、または失敗から成功に変わる場合、または失敗の理由が変化する場合は、イベントが直ちにログに記録されるため、チームは、プロアクティブなアクションを直ちに実行できます。
ソース サービスの調整など、一時的と考えられるエラーは、60 分を超えて続いた後にのみログに記録されます。 この 60 分で Microsoft Sentinel は、バックエンドの一時的な問題を克服し、ユーザーの操作を必要とせずにデータからの遅れを解消します。 明らかに一時的ではないエラーは、直ちにログに記録されます。
失敗の概要。 コネクタごと、およびワークスペースごとに 1 時間に 1 回、ログに記録され、失敗の概要が集計されます。 失敗の概要イベントは、一定の時間にコネクタでポーリング エラーが発生した場合にのみ作成されます。 これには、ExtendedProperties 列に記載された詳細が含まれます。たとえば、コネクタのソース プラットフォームのクエリが実行された期間や、その期間中に発生した失敗の明確な一覧などです。
詳細については、「SentinelHealth テーブル列のスキーマ」を参照してください。
クエリを実行して正常性ドリフトを検出する
SentinelHealth テーブルに対するクエリを作成すると、データ コネクタの正常性ドリフトの検出に役立ちます。 次に例を示します。
コネクタごとに最新の失敗イベントを検出します。
SentinelHealth
| where TimeGenerated > ago(3d)
| where OperationName == 'Data fetch status change'
| where Status in ('Success', 'Failure')
| summarize TimeGenerated = arg_max(TimeGenerated,*) by SentinelResourceName, SentinelResourceId
| where Status == 'Failure'
失敗状態から成功状態に変化したコネクタを検出します。
let lastestStatus = SentinelHealth
| where TimeGenerated > ago(12h)
| where OperationName == 'Data fetch status change'
| where Status in ('Success', 'Failure')
| project TimeGenerated, SentinelResourceName, SentinelResourceId, LastStatus = Status
| summarize TimeGenerated = arg_max(TimeGenerated,*) by SentinelResourceName, SentinelResourceId;
let nextToLastestStatus = SentinelHealth
| where TimeGenerated > ago(12h)
| where OperationName == 'Data fetch status change'
| where Status in ('Success', 'Failure')
| join kind = leftanti (lastestStatus) on SentinelResourceName, SentinelResourceId, TimeGenerated
| project TimeGenerated, SentinelResourceName, SentinelResourceId, NextToLastStatus = Status
| summarize TimeGenerated = arg_max(TimeGenerated,*) by SentinelResourceName, SentinelResourceId;
lastestStatus
| join kind=inner (nextToLastestStatus) on SentinelResourceName, SentinelResourceId
| where NextToLastStatus == 'Failure' and LastStatus == 'Success'
成功状態から失敗状態に変化したコネクタを検出します。
let lastestStatus = SentinelHealth
| where TimeGenerated > ago(12h)
| where OperationName == 'Data fetch status change'
| where Status in ('Success', 'Failure')
| project TimeGenerated, SentinelResourceName, SentinelResourceId, LastStatus = Status
| summarize TimeGenerated = arg_max(TimeGenerated,*) by SentinelResourceName, SentinelResourceId;
let nextToLastestStatus = SentinelHealth
| where TimeGenerated > ago(12h)
| where OperationName == 'Data fetch status change'
| where Status in ('Success', 'Failure')
| join kind = leftanti (lastestStatus) on SentinelResourceName, SentinelResourceId, TimeGenerated
| project TimeGenerated, SentinelResourceName, SentinelResourceId, NextToLastStatus = Status
| summarize TimeGenerated = arg_max(TimeGenerated,*) by SentinelResourceName, SentinelResourceId;
lastestStatus
| join kind=inner (nextToLastestStatus) on SentinelResourceName, SentinelResourceId
| where NextToLastStatus == 'Success' and LastStatus == 'Failure'
正常性の問題に関するアラートと自動アクションを構成する
Microsoft Sentinel 分析ルールを使用して Microsoft Sentinel ログで自動化を構成することもできますが、データ コネクタの正常性ドリフトに関する通知を受け取り、直ちに対処することを望む場合は、Azure Monitor アラート ルールの使用をお勧めします。
次に例を示します。
Azure Monitor アラート ルールで、ルール スコープとして Microsoft Sentinel ワークスペースを、最初の条件としてカスタム ログ検索を選択します。
頻度やルックバック期間など、必要に応じてアラート ロジックをカスタマイズし、クエリを使用して正常性ドリフトを検索します。
ルール アクションとして、既存のアクション グループを選択するか、必要に応じて新しいアクション グループを作成して、プッシュ通知を構成するか、ロジック アプリ、Webhook、Azure 関数のシステムでのトリガーなどの他の自動化されたアクションを構成します。
詳細については、Azure Monitor アラートの概要に関するページ、および Azure Monitor アラート ログに関するページを参照してください。
次のステップ
- Microsoft Sentinel での監査と稼働状況の監視について確認します。
- Microsoft Sentinel で監査と稼働状況の監視を有効にします。
- オートメーション ルールとプレイブックの正常性を監視します。
- 分析ルールの正常性と整合性を監視します。
- "SentinelHealth" および "SentinelAudit" テーブル スキーマの詳細を確認します。