Application Gateway の正常性プローブの概要
Azure Application Gateway は、バックエンド プール内のすべてのサーバーの正常性を監視し、異常と見なされるすべてのサーバーへのトラフィックの送信を自動的に停止します。 プローブはこのような異常なサーバーを開始し続け、プローブが正常であると検出するとすぐに、ゲートウェイによってトラフィックのルーティングが再び開始されます。
既定のプローブでは、関連付けられているバックエンド設定とその他のプリセット構成のポート番号が使用されます。 カスタム プローブを使用して、独自の方法で構成できます。
プローブの動作
ソース IP アドレス
プローブの発信元 IP アドレスは、バックエンド サーバーの種類によって異なります。
- バックエンド プール内のサーバーがパブリック エンドポイントの場合、ソース アドレスはアプリケーション ゲートウェイのフロントエンド パブリック IP アドレスになります。
- バックエンド プール内のサーバーがプライベート エンドポイントの場合、発信元 IP アドレスはアプリケーション ゲートウェイ サブネットのアドレス空間から取得されます。
プローブ操作
ゲートウェイは、ルールをバックエンド設定とバックエンド プール (およびリスナー) に関連付けることで、規則を構成した直後にプローブの起動を開始します。 この図は、ゲートウェイがすべてのバックエンド プール サーバーを個別にプローブすることを示しています。 到着を開始する受信要求は、正常なサーバーにのみ送信されます。 プローブ応答が正常に受信されるまで、バックエンド サーバーは既定で異常としてマークされます。
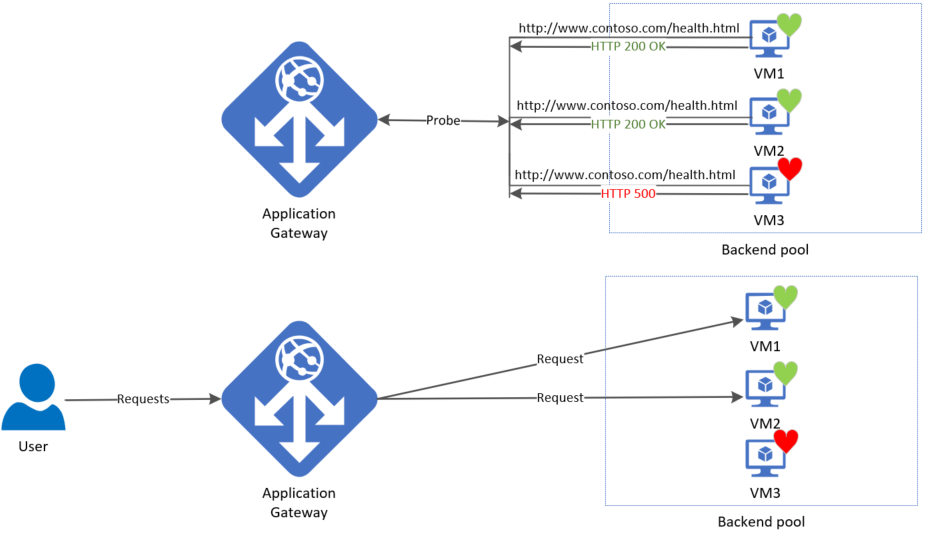
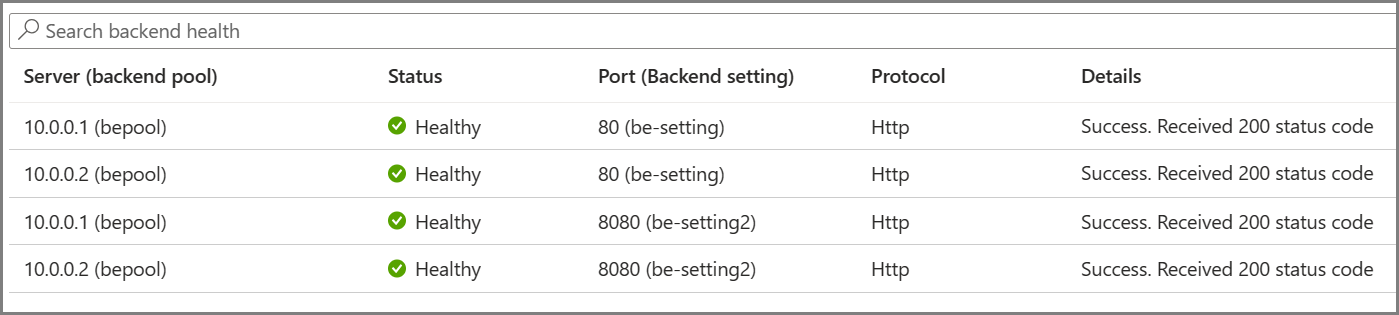
必要なプローブは、バックエンド サーバーとバックエンド設定の一意の組み合わせに基づいて決定されます。 たとえば、2 つのサーバーと 2 つのバックエンド設定がある 1 つのバックエンド プールを持つゲートウェイについて考えてみます。それぞれのポート番号が異なります。 これらの個別のバックエンド設定がそれぞれのルールを使用して同じバックエンド プールに関連付けられている場合、ゲートウェイにより各サーバーのプローブとバックエンド設定の組み合わせが作成されます。 これは、[バックエンドの正常性] ページで確認できます。
さらに、アプリケーション ゲートウェイのすべてのインスタンスは、互いに独立してバックエンド サーバーをプローブします。
プローブの期間
Application Gateway の各インスタンスに、同じプローブ構成が適用されます。 たとえば、アプリケーション ゲートウェイに 2 つのインスタンスがあり、プローブ間隔が 20 秒に設定されている場合、両方のインスタンスにより正常性プローブが 20 秒ごとに送信されます。
プローブで、失敗した応答が検出されると、"異常のしきい値" のカウンターがオフに設定され、連続する失敗数が構成されたしきい値と一致した場合はサーバーが異常としてマークされます。 したがって、この異常のしきい値を 2 に設定した場合、後続のプローブにより最初にこのエラーが検出されます。 その後、アプリケーション ゲートウェイによって、2 回連続して失敗したプローブ [最初の検出 20 秒 + (連続して失敗したプローブが 2 つ * 20 秒)] の後に、サーバーが異常としてマークされます。
Note
バックエンド正常性レポートは、それぞれのプローブの更新間隔に基づいて更新され、ユーザーの要求に依存しません。
既定の正常性プローブ
カスタム プローブ構成を設定しない場合、アプリケーション ゲートウェイにより既定の正常性プローブが自動で構成されます。 監視は、バックエンド プール内の構成済みの IP アドレスまたは FQDN に対して HTTP GET 要求を行うことで実行されます。 既定のプローブでは、バックエンドの http 設定が HTTPS に対応するように構成されている場合、プローブはバックエンド サーバーの正常性をテストする際に HTTPS を使用します。
たとえば、バックエンド サーバー A、B、C を使用して ポート 80 で HTTP ネットワーク トラフィックを受信するように、アプリケーション ゲートウェイを構成したとします。 既定の正常性監視では、30 秒ごとにこれら 3 つのサーバーに対して HTTP 応答が正常であるかどうかがテストされます。その際、各要求に対して 30 秒のタイムアウトが適用されます。 正常な HTTP 応答の 状態コード は、200 から 399 の間です。 この場合、正常性プローブの HTTP GET 要求は http://127.0.0.1/ のようになります。 「Application Gateway の HTTP 応答コード」も参照してください。
サーバー A に対する既定のプローブ チェックが失敗した場合、Application Gateway はこのサーバーへの要求の転送を停止します。 既定のプローブは、削除後もサーバー A を 30 秒ごとにチェックし続けます。 サーバー A が既定の正常性プローブからの 1 つの要求に正常に応答すると、Application Gateway はサーバーへの要求の転送を再び開始します。
既定の正常性プローブの設定
| プローブのプロパティ | 値 | 説明 |
|---|---|---|
| プローブの URL | <protocol>://127.0.0.1:<port>/ | プロトコルとポートは、プローブが関連付けられているバックエンド HTTP 設定から継承されます。 |
| Interval | 30 | 次の正常性プローブが送信されるまでの秒数です。 |
| タイムアウト | 30 | アプリケーション ゲートウェイがプローブの応答を待機する秒数です。これを超えると、プローブは異常としてマークされます。 プローブが正常として返された場合は、対応するバックエンドがすぐに正常としてマークされます。 |
| 異常のしきい値 | 3 | 通常の正常性プローブで障害が発生した場合に送信するプローブの数を制御します。 v1 SKU では、これらの追加の正常性プローブは、バックエンドの正常性をすばやく確認するために、プローブ間隔を待つことなく立て続けに送信されます。 v2 SKU の場合、正常性プローブはその期間を待ちます。 プローブの連続失敗回数が異常のしきい値に達すると、バックエンド サーバーは「ダウン」とマークされます。 |
既定のプローブは、正常性状態を判断する際に <protocol>://127.0.0.1:<port> だけをチェックします。 カスタム URL をチェックするように正常性プローブを構成するか、その他の設定を変更する必要がある場合は、カスタム プローブを使用する必要があります。 HTTPS プローブの詳細については、「Application Gateway での TLS 終了とエンド ツー エンド TLS の概要」を参照してください。
カスタムの正常性プローブ
カスタム プローブを使用すると、正常性監視をより細かく制御できます。 カスタム プローブを使用する場合、カスタム ホスト名、URL パス、プローブ間隔、およびバックエンド プール インスタンスを「異常」とマークするまでの応答の失敗回数などを構成することができます。
カスタムの正常性プローブの設定
カスタム正常性プローブのプロパティの定義を次の表に示します。
| プローブのプロパティ | 説明 |
|---|---|
| 名前 | プローブの名前。 この名前は、バックエンドの HTTP 設定でプローブを識別して参照するために使用されます。 |
| プロトコル | プローブを送信するために使用するプロトコル。 これは、関連付けられているバックエンド HTTP 設定で定義されているプロトコルと一致している必要があります |
| Host | プローブを送信するホスト名。 v1 SKU では、この値はプローブ要求のホスト ヘッダーに対してのみ使用されます。 v2 SKU では、ホスト ヘッダーおよび SNI の両方として使用されます |
| Path | プローブの相対パス。 パスは先頭が "/" である必要があります。 |
| Port | 定義されている場合は、宛先ポートとして使用されます。 それ以外の場合は、関連付けられている HTTP 設定と同じポートを使用します。 このプロパティは、v2 SKU でのみ使用できます。 |
| Interval | プローブの間隔 (秒)。 この値は、2 つの連続するプローブの時間間隔です |
| タイムアウト | プローブのタイムアウト (秒)。 このタイムアウト期間内に正常な応答が受信されなかった場合は、プローブが「失敗」とマークされます |
| 異常のしきい値 | プローブの再試行回数。 プローブの連続失敗回数が異常のしきい値に達すると、バックエンド サーバーは「ダウン」とマークされます |
プローブの一致
既定では、状態コードが 200 から 399 の HTTP(S) 応答は正常と見なされます。 カスタム正常性プローブでは、さらに 2 つの一致条件がサポートされます。 一致条件を使用して、正常な応答を行うための既定の解釈を必要に応じて変更できます。
一致条件は、次のとおりです。
- HTTP 応答の状態コードの一致 - ユーザー指定 http 応答コードまたは応答コードの範囲を受け入れるためのプローブの一致条件。 個々のコンマ区切りの応答状態コードまたは状態コードの範囲がサポートされています。
- HTTP 応答本文の一致 - HTTP 応答本文をチェックし、ユーザー指定文字列と一致させるプローブの一致条件。 一致ではユーザー指定文字列が応答本文内にあるかどうかのみがチェックされ、完全な正規表現の一致ではありません。 指定した一致は 4090 文字以下にする必要があります。
一致条件は New-AzApplicationGatewayProbeHealthResponseMatch コマンドレットを使用して指定できます。
次に例を示します。
$match = New-AzApplicationGatewayProbeHealthResponseMatch -StatusCode 200-399
$match = New-AzApplicationGatewayProbeHealthResponseMatch -Body "Healthy"
一致条件は、PowerShell の -Match 演算子を使用してプローブ構成にアタッチできます。
カスタム プローブの一部のユース ケース
- バックエンド サーバーによって、認証されたユーザーにのみアクセスが許可された場合、アプリケーション ゲートウェイ プローブは 200 ではなく 403 応答コードを受け取ります。 クライアント (ユーザー) がライブ トラフィックに対して自身を認証するようにバインドされるため、プローブ トラフィックを構成して、期待される応答として 403 を受け入れるようにすることができます。
- バックエンド サーバーにワイルドカード証明書 (*.contoso.com) がインストールされ、異なるサブドメインを提供する場合は、特定のホスト名 (SNI に必要) を指定してカスタム プローブを使用できます。このプローブは、正常な TLS プローブを確立し、そのサーバーを正常と報告するために受け入れられます。 バックエンド設定の [ホスト名の上書き] を [いいえ] に設定すると、異なる受信ホスト名 (サブドメイン) がバックエンドにそのまま渡されます。
NSG に関する考慮事項
パブリック プレビューでは、NSG ルールを使用して Application Gateway サブネットを細かく制御できます。 詳細については、こちらをご覧ください。
現在の機能には、いくつかの制限があります。
Application Gateway v1 SKU の TCP ポート 65503 ~ 65534 と、v2 SKU の TCP ポート 65200 ~ 65535 で、宛先サブネットが [すべて]、ソースが GatewayManager サービス タグである着信インターネット トラフィックを許可する必要があります。 このポート範囲は、Azure インフラストラクチャの通信に必要です。
さらに、送信インターネット接続はブロックできないため、AzureLoadBalancer タグから送信された受信トラフィックを許可する必要があります。
詳細については、「アプリケーション ゲートウェイ構成の概要」を参照してください。
次のステップ
Application Gateway による正常性監視について学習した後は、Azure Portal でカスタム正常性プローブを構成することも、PowerShell と Azure Resource Manager デプロイ モデルを使用してカスタム正常性プローブを構成することもできます。