キャッシュ不使用のアンチパターン
アンチパターンは、ストレス状況下でソフトウェアやアプリケーションを破壊する可能性があるため見落とさないようにする必要がある一般的な設計上の欠陥です。 "キャッシュ不使用のアンチパターン" は、多数の同時要求を処理するクラウド アプリケーションによって同じデータが繰り返しフェッチされる場合に発生します。 これにより、パフォーマンスとスケーラビリティが低下する可能性があります。
データがキャッシュされていないことで、次のように、多数の好ましくない動作を引き起こすことがあります。
- I/O オーバーヘッドや待ち時間の点でアクセス コストの大きいリソースから同じ情報を繰り返しフェッチする。
- 複数の要求で同じオブジェクトまたは同じデータ構造を繰り返し構築する。
- サービス クォータのあるリモート サービスや、特定の限度を超えたときにクライアントをスロットルするリモート サービスを必要以上に呼び出す。
これらの問題は、応答時間の遅さ、データ ストアにおける競合の増加、スケーラビリティの低さとして跳ね返ってくることがあります。
キャッシュ不使用のアンチパターンの例
以下の例では、Entity Framework を使用してデータベースに接続しています。 まったく同じデータをフェッチする要求が複数あっても、クライアントの要求ごとに毎回データベースが呼び出されます。 要求が繰り返されることで、I/O オーバーヘッドとデータ アクセス料金の観点から見たコストはたちまち累積していくことでしょう。
public class PersonRepository : IPersonRepository
{
public async Task<Person> GetAsync(int id)
{
using (var context = new AdventureWorksContext())
{
return await context.People
.Where(p => p.Id == id)
.FirstOrDefaultAsync()
.ConfigureAwait(false);
}
}
}
完全なサンプルは、こちらでご覧いただけます。
このアンチパターンは、通常、次の理由で発生します。
- キャッシュを使わない方が、実装が簡単で、負荷の低い条件下では動作上問題がない。 キャッシュを使うとコードが複雑化する。
- キャッシュを使うことの利点と欠点がよくわからない。
- キャッシュされたデータの確度と鮮度を維持することで生じるオーバーヘッドが気になる。
- ネットワーク待ち時間が問題にならないオンプレミス システムからアプリケーションを移行した。オンプレミス システムは高価で高性能なハードウェア上で運用されていたため、当初の設計ではキャッシュが考慮されていない。
- 特定のシナリオでキャッシュが有効な選択肢となりうることを開発者が理解していない。 たとえば Web API を実装する際に ETag が検討されない。
キャッシュ不使用のアンチパターンを修正する方法
最も一般的なキャッシュ方式は "オンデマンド" と "キャッシュ アサイド" です。
- 読み取り時、アプリケーションはキャッシュからデータの読み取りを試みます。 データがキャッシュにない場合、アプリケーションはデータ ソースからデータを取得してキャッシュに追加します。
- 書き込み時、アプリケーションは変更を直接データ ソースに書き込み、古い値をキャッシュから削除します。 次回必要になったときに、それが取得されてキャッシュに追加されます。
この方法は、頻繁に変更されるデータに適しています。 以下に示したのは、キャッシュ アサイド パターンを使用するように先ほどの例を書き換えたものです。
public class CachedPersonRepository : IPersonRepository
{
private readonly PersonRepository _innerRepository;
public CachedPersonRepository(PersonRepository innerRepository)
{
_innerRepository = innerRepository;
}
public async Task<Person> GetAsync(int id)
{
return await CacheService.GetAsync<Person>("p:" + id, () => _innerRepository.GetAsync(id)).ConfigureAwait(false);
}
}
public class CacheService
{
private static ConnectionMultiplexer _connection;
public static async Task<T> GetAsync<T>(string key, Func<Task<T>> loadCache, double expirationTimeInMinutes)
{
IDatabase cache = Connection.GetDatabase();
T value = await GetAsync<T>(cache, key).ConfigureAwait(false);
if (value == null)
{
// Value was not found in the cache. Call the lambda to get the value from the database.
value = await loadCache().ConfigureAwait(false);
if (value != null)
{
// Add the value to the cache.
await SetAsync(cache, key, value, expirationTimeInMinutes).ConfigureAwait(false);
}
}
return value;
}
}
GetAsync メソッドに注目してください。先ほどはデータベースを直接呼び出していましたが、CacheService クラスを呼び出しています。 CacheService クラスはまず、Azure Cache for Redis から項目の取得を試みます。 その値がキャッシュに見つからなかった場合、CacheService は、呼び出し元から渡されたラムダ関数を呼び出します。 このラムダ関数の役割は、データベースからデータをフェッチすることです。 この実装によって、特定のキャッシュ ソリューションからリポジトリが分離され、CacheService がデータベースから分離されています。
キャッシュ方式に関する考慮事項
一時的な障害などでキャッシュが利用できない場合、クライアントにはエラーを返さないでください。 代わりに、元のデータ ソースからデータをフェッチするようにします。 ただしキャッシュを回復している間に、元のデータ ストアが要求に対応しきれず、タイムアウトが発生したり接続に失敗したりする可能性があります (結局はそれが、キャッシュを使用するそもそもの動機の 1 つです)。サーキット ブレーカー パターンなどの手法を用いて、データ ソースへの過剰な負荷を回避してください。
動的データをキャッシュするアプリケーションは、結果整合性をサポートするように設計されている必要があります。
Web API に関しては、要求メッセージと応答メッセージに Cache-Control ヘッダーを追加し、ETag を使ってオブジェクトのバージョンを識別することによって、クライアント側キャッシュをサポートできます。 詳細については、「API の実装」を参照してください。
エンティティ全体をキャッシュする必要はありません。 エンティティの大半が静的データで、頻繁に変更される部分がごく一部に限られるのであれば、静的な要素をキャッシュして、動的な要素はデータ ソースから取得するようにしてください。 この方法には、データ ソースに対して実行される I/O の量を減らす効果があります。
場合によっては、存続期間が短い揮発性データはキャッシュすると効果的です。 たとえば最新のステータス情報を絶えず送信するデバイスがあるとします。 受信した情報をキャッシュし、永続ストアには一切書き込まないことは理にかなっていると考えられます。
データの鮮度を保つために、多くのキャッシュ ソリューションは有効期限を構成できるようになっていて、その場合、一定時間が経過したデータはキャッシュから自動的に削除されます。 その有効期限は、実際のシナリオに応じて自分で調整することが必要になる場合があります。 変更頻度の低い静的なデータは、すぐに鮮度が落ちる揮発性データよりも長くキャッシュに置くことができます。
キャッシュ ソリューションに有効期限が標準装備されていない場合は、キャッシュが際限なく肥大化するのを防ぐために、ときどきキャッシュを掃除するバックグラウンド処理を独自に実装する必要があります。
外部データ ソースからデータをキャッシュするだけでなく、キャッシュを使用して、複雑な計算の結果を保存することもできます。 ただしその前に、アプリケーションをインストルメント化して、アプリケーションに本当に CPU 制約が適用されているかどうかを確かめてください。
場合によっては、アプリケーションが起動した時点で最初からキャッシュにデータを投入しておくと効果的です。 使用される可能性が最も高いデータをキャッシュに格納してください。
キャッシュ ヒットとキャッシュ ミスを検出するインストルメンテーションは必ず追加してください。 その情報をもとに、キャッシュするデータやキャッシュにデータを保持する時間 (有効期限) など、キャッシュ ポリシーを調整することができます。
キャッシュがないことがボトルネックになっている場合に、キャッシュを追加したことで要求のボリュームが増えすぎて、Web フロントエンドがオーバーフローする可能性があります。 クライアントに HTTP 503 (サービスを利用できません) エラーが返されることがあります。 それらはフロントエンドのスケールアウトの必要性を示す徴候となります。
キャッシュ不使用のアンチパターンを検出する方法
キャッシュの不使用がパフォーマンスの問題につながるどうかを特定しやすくするために、次の手順を実行してください。
アプリケーションの設計を確認します。 アプリケーションで使用するすべてのデータ ストアの一覧を作成してください。 それぞれについて、アプリケーションにキャッシュが使用されているかどうかを確認します。 可能であれば、データの変更頻度を特定します。 まずキャッシュの候補となるのは、少しずつ変化するデータや、頻繁に読み取られる静的な参照データです。
アプリケーションをインストルメント化したうえでライブ システムを監視し、アプリケーションがデータを取得したり情報を計算したりする頻度を突き止めます。
テスト環境でアプリケーションをプロファイリングし、データ アクセス操作やその他の頻繁に実行される計算に関連付けられたオーバーヘッドについて、低レベルのメトリックを収集します。
テスト環境でロード テストを実行し、通常のワークロード下と大きな負荷がかかっている状況下でシステムが応答するようすを確認します。 ロード テストでは、運用環境で観察されるデータ アクセスのパターンを現実的なワークロードでシミュレートする必要があります。
基になるデータ ストアに関してデータ アクセスの統計を調査し、同じデータ要求が繰り返される頻度を確認します。
診断の例
以降のセクションでは、これらの手順を前述のサンプル アプリケーションに適用していきます。
アプリケーションをインストルメント化してライブ システムを監視する
アプリケーションをインストルメント化して監視し、その運用環境でユーザーが実行する具体的な要求についての情報を入手します。
次の画像は、ロード テスト時に New Relic によって収集された監視データを示したものです。 この例で実行された HTTP GET 操作は Person/GetAsync だけです。 しかし実際の運用環境では、個々の要求が実行される相対的な頻度を把握することで、キャッシュすべきリソースについての洞察が得られます。
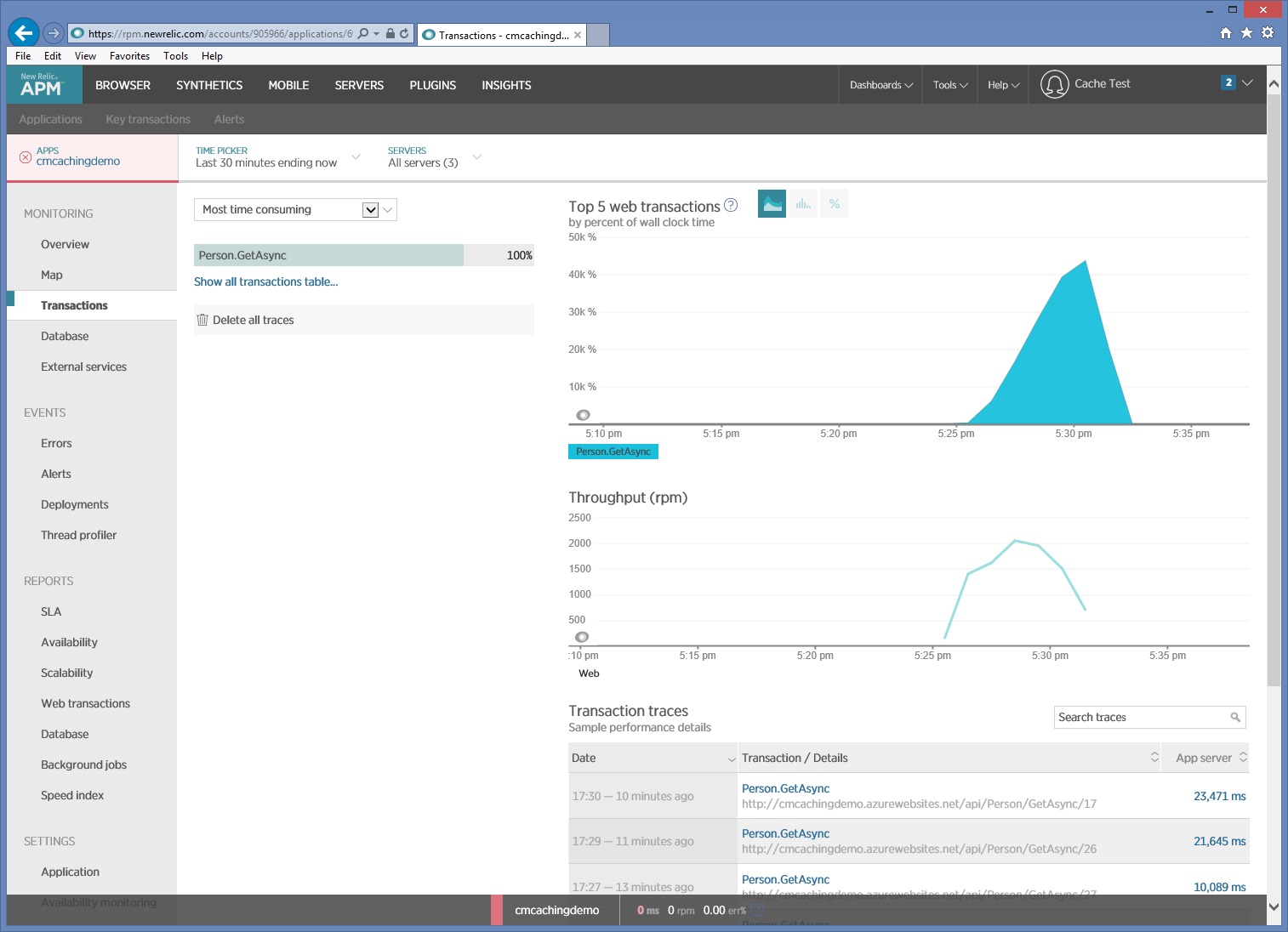
さらに詳しく分析する必要がある場合は、プロファイラーを使用して低レベルのパフォーマンス データを (運用環境のシステムではなく) テスト環境で収集することができます。 I/O 要求レート、メモリ使用量、CPU 使用率などのメトリックに注目してください。 データ ストアやサービスに対する大量の要求、または同じ計算を実行する処理の繰り返しが、これらのメトリックによって明らかになる場合があります。
アプリケーションのロード テストを実行する
次のグラフは、サンプル アプリケーションのロード テストの結果を示しています。 このロード テストでは、標準的な操作の流れを実行するユーザーの負荷を最大 800 人まで段階的に増やしていくシミュレーションを実行します。
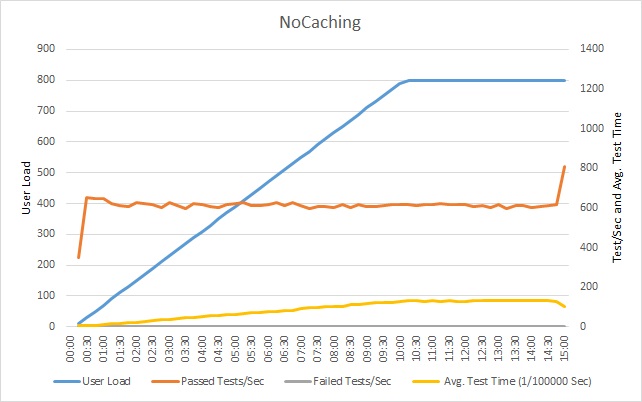
1 秒あたりの成功したテストの数が頭打ちになると、結果的にそれ以降の要求は処理速度が低下します。 平均テスト時間は、ワークロードと共に着実に増えていきます。 ユーザー負荷がピークに達した後、応答時間は横ばいになります。
データ アクセスの統計を調査する
データ アクセスの統計をはじめ、データ ストアから提供される各種の情報から、どのクエリが極端な頻度で繰り返されているかなど、有益なデータが得られる場合があります。 たとえば Microsoft SQL Server では、最近実行されたクエリの統計情報が sys.dm_exec_query_stats 管理ビューに表示されます。 各クエリのテキストは、sys.dm_exec-query_plan ビューで確認できます。 SQL Server Management Studio などのツールから次の SQL クエリを実行することで、クエリの実行頻度を確認できます。
SELECT UseCounts, Text, Query_Plan
FROM sys.dm_exec_cached_plans
CROSS APPLY sys.dm_exec_sql_text(plan_handle)
CROSS APPLY sys.dm_exec_query_plan(plan_handle)
実行結果の UseCount 列にそれぞれのクエリの実行頻度が示されます。 次の画像を見ると、3 つ目クエリが 250,000 回以上実行され、他のクエリに比べて著しく多いことがわかります。
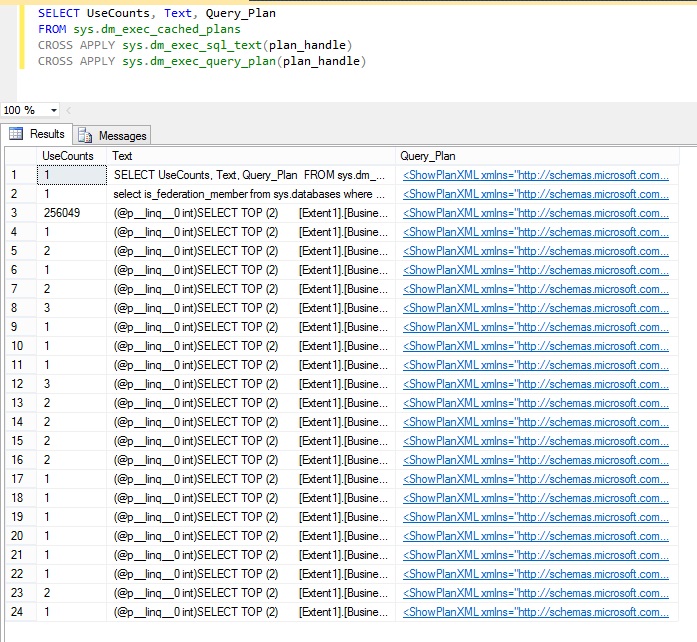
多数のデータベース要求の原因となっている SQL クエリを次に示します。
(@p__linq__0 int)SELECT TOP (2)
[Extent1].[BusinessEntityId] AS [BusinessEntityId],
[Extent1].[FirstName] AS [FirstName],
[Extent1].[LastName] AS [LastName]
FROM [Person].[Person] AS [Extent1]
WHERE [Extent1].[BusinessEntityId] = @p__linq__0
このクエリは、前述の GetByIdAsync メソッドで Entity Framework によって生成されたものです。
キャッシュ方式ソリューションを実装して結果を検証する
キャッシュを実装したうえで再度ロード テストを実行し、キャッシュを使わずに行った前回のロード テストの結果と比較します。 サンプル アプリケーションにキャッシュを追加した後のロード テストの結果は次のとおりです。
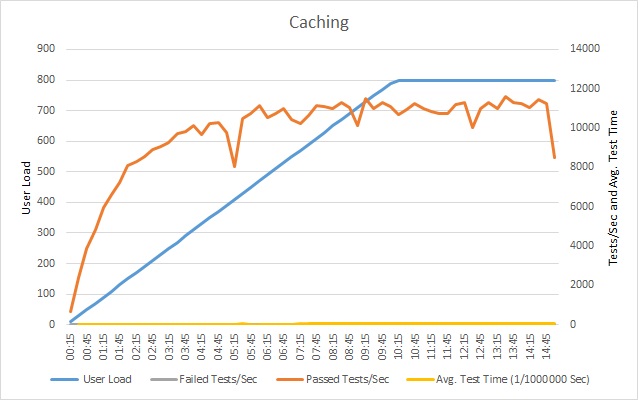
成功したテストの数はやはり頭打ちになりますが、そのときのユーザー負荷は、さきほどよりも高くなっています。 この負荷時の要求レートは、前回よりも大幅に高くなっています。 平均テスト時間は負荷と共に依然として上昇しますが、最大応答時間は 0.05 ミリ秒 と、前回の 1 ミリ秒と比べて 20 倍の改善が見られます。
関連リソース
フィードバック
以下は間もなく提供いたします。2024 年を通じて、コンテンツのフィードバック メカニズムとして GitHub の issue を段階的に廃止し、新しいフィードバック システムに置き換えます。 詳細については、「https://aka.ms/ContentUserFeedback」を参照してください。
フィードバックの送信と表示