Team Data Science Process (TDSP) は、予測分析ソリューションとAIアプリケーションを効率的に提供するために使用できるアジャイルで反復的なデータサイエンス手法です。 TDSPは、チームの役割が最適に連携する方法を提案することで、チームのコラボレーションと学習の向上に役立ちます。 TDSPには、Microsoftやその他の業界リーダーによるベストプラクティスと構造が含まれており、チームがデータサイエンスイニシアチブを正常に実装し、分析プログラムの利点を最大限に活用できるように支援します。
この記事では、TDSP とその主な構成要素について概要を紹介します。 Microsoftのツールとインフラストラクチャを使用してTDSPを実装する方法に関するガイダンスを提供します。 この記事全体で、より詳細なリソースを見つけることができます。
TDSP の主な構成要素
TDSPには、次の主要コンポーネントがあります。
- データ サイエンス ライフサイクルの定義
- 標準プロジェクト構造
- データ サイエンス プロジェクトに推奨されるインフラストラクチャとリソース
- プロジェクト実行に推奨されるツールとユーティリティ
データ サイエンス ライフサイクル
TDSPは、データサイエンスプロジェクトの開発の構造化に使用できるライフサイクルを提供します。 ライフサイクルには、正常なプロジェクトが従う完全な手順の概要が示されます。
タスクベースのTDSPは、データマイニングの業界間標準プロセス (CRISP-DM) 、データベースでのナレッジ検出 (KDD) プロセス、または別のカスタムプロセスなど、他のデータサイエンスライフサイクルと組み合わせることができます。 大局的に見ると、これらの各種の手法には多くの共通点があります。
インテリジェントアプリケーションの一部であるデータサイエンスプロジェクトがある場合は、このライフサイクルを使用する必要があります。 インテリジェントアプリケーションでは、予測分析のために機械学習またはAIモデルをデプロイします。 このプロセスは、探索的なデータサイエンスプロジェクトや即席の分析プロジェクトにも使用できます。
TDSPライフサイクルは、チームが反復的に実行する5つの主要なステージで構成されています。 次の段階があります。
TDSPライフサイクルの視覚的な表現を次に示します。
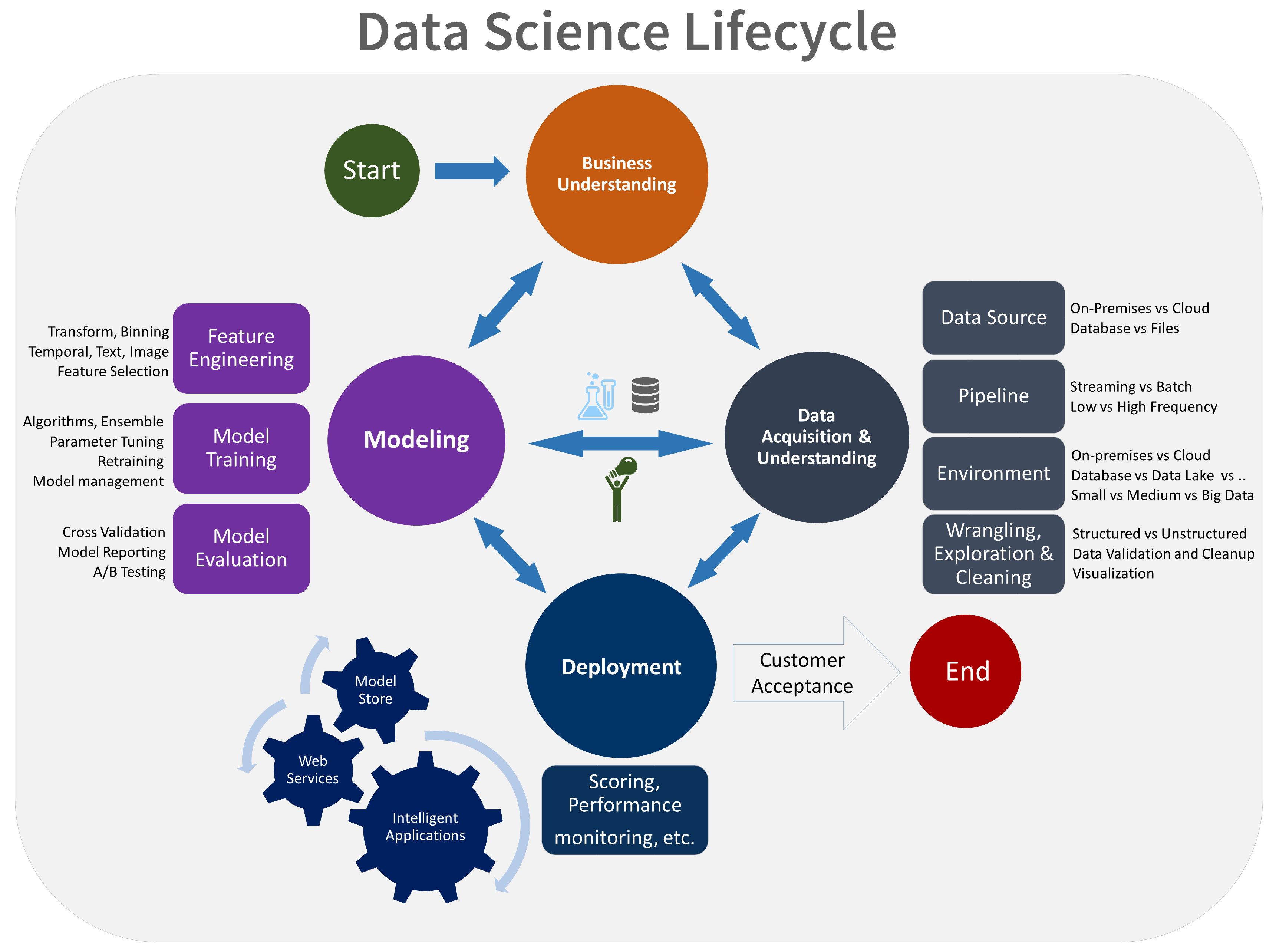
各ステージの目標、タスク、ドキュメント成果物の詳細については、Team Data Science Processライフサイクルに関するページを参照してください。
これらのタスクと成果物は、次のようなプロジェクトロールに関連付けられています。
- ソリューションアーキテクト。
- プロジェクト管理者。
- データエンジニア。
- データ サイエンティスト。
- アプリケーション開発者。
- プロジェクトリーダー。
次の図は、これらのロール (縦軸) のライフサイクルの各ステージ (横軸) に関連付けられているタスク (青) と成果物 (緑) を示しています。

標準プロジェクト構造
チームは、Azureインフラストラクチャを使用してデータサイエンス資産を整理できます。
Azure Machine Learningでは、オープンソースのMLflowがサポートされています。 データサイエンスとAIのプロジェクト管理には、MLflowを使用することをお勧めします。 MLflowは、機械学習のライフサイクル全体を管理するように設計されています。 さまざまなプラットフォームでモデルのトレーニングと提供を行うため、実験を実行する場所に関係なく、一貫したツールセットを使用できます。 MLflowは、コンピューター、リモートコンピューティング先、仮想マシン、またはMachine Learningコンピューティングインスタンスでローカルに使用できます。
MLflowは、いくつかの主要な機能で構成されています。
実験の追跡: MLflowを使用すると、パラメーター、コードバージョン、メトリック、出力ファイルなど、実験を追跡できます。 この機能は、さまざまな実行を比較し、実験プロセスを効率的に管理するのに役立ちます。
パッケージコード: 依存関係と構成を含む機械学習コードをパッケージ化するための標準化された形式を提供します。 このパッケージ化により、実行を再現し、他のユーザーとコードを共有することが容易になります。
モデルの管理: MLflowは、モデルを管理およびバージョン管理するための機能を提供します。 さまざまな機械学習フレームワークをサポートしているため、モデルを格納、バージョン管理、および提供できます。
モデルの提供とデプロイ: MLflowはモデルの提供とデプロイの機能を統合するため、さまざまな環境にモデルを簡単にデプロイできます。
モデルの登録: バージョン管理、ステージ遷移、注釈など、モデルのライフサイクルを管理できます。 MLflowは、コラボレーション環境で一元化されたモデルストアを維持する場合に便利です。
APIとUIの使用: Azure内では、MLflowはMachine Learning APIバージョン2にバンドルされているため、プログラムでシステムと対話できます。 Azure portalを使用してUIと対話できます。
MLflowは、実験からデプロイまで、機械学習開発のプロセスを簡素化および標準化することを目的としています。
Machine LearningはGitリポジトリと統合されるため、Gitと互換性のあるサービスを使用できます。GitHub、GitLab、Bitbucket、Azure DevOps、またはその他のGitと互換性のあるサービス。 Machine Learningで既に追跡されているアセットに加えて、チームはGitと互換性のあるサービス内で独自の分類を開発して、次のような他のプロジェクト情報を格納できます。
- ドキュメント
- プロジェクト (最終プロジェクトレポートなど)
- データレポート (データ辞書やデータ品質レポートなど)
- モデル (モデルレポートなど)
- コード
- データ準備
- モデルの開発
- 運用化 (セキュリティやコンプライアンスなど)
インフラストラクチャとリソース
TDSPでは、次のような共有分析およびストレージインフラストラクチャを管理するための推奨事項を提供します。
- データセットを格納するためのクラウドファイルシステム
- データベース
- ビッグデータクラスター (SQLやSparkなど)
- Machine Learning Services
未加工のデータセットと処理済みのデータセットが格納される分析とストレージのインフラストラクチャを、クラウドまたはオンプレミスに配置できます。 このインフラストラクチャによって分析の再現性が得られます。 また、不整合や不要なインフラストラクチャコストにつながる可能性のある重複も防止できます。 インフラストラクチャには、共有リソースをプロビジョニングし、それらを追跡し、各チームメンバーがそれらのリソースに安全に接続できるようにするためのツールがあります。 プロジェクトメンバーに一貫性のあるコンピューティング環境を作成させることもお勧めします。 その後、さまざまなチームメンバーが実験をレプリケートして検証できます。
複数のプロジェクトで作業し、さまざまなクラウド分析インフラストラクチャコンポーネントを共有するチームの例を次に示します。

ツールとユーティリティ
ほとんどの組織では、プロセスを導入することは困難です。 インフラストラクチャには、TDSPとライフサイクルを実装するためのツールが用意されており、導入の障壁を低くし、一貫性を高めるのに役立ちます。
Machine Learningを使用すると、データサイエンティストはデータサイエンスパイプラインまたはワークフローの一部としてオープンソースツールを適用できます。 Machine Learningでは、Microsoftの責任あるAI標準の達成に役立つ責任あるAIツールを推進しています。
ピアレビューされた引用文献
TDSPは、Microsoftの取り組み全体で使用される確立された方法論であるため、ピアレビューされた文献で文書化され、研究されています。 これらの引用文献は、TDSPの機能とアプリケーションを調査する機会を提供します。 引用文献の一覧については、ライフサイクルの概要ページを参照してください。