このクライアント プロジェクトは、Fortune 500 食品会社の需要予測の改善に役立ちました。 同社は、複数の小売店に製品を直接出荷しています。 この改善は、米国の複数の地域間で、さまざまな店舗の製品在庫の最適化に役立ちました。 これを実現するために、Microsoft の商用ソフトウェア エンジニアリング (CSE) チームは、クライアントのデータ サイエンティストと協力してパイロット調査を行い、選択した地域用にカスタマイズされた機械学習モデルを開発しました。 モデルでは、次の要件が考慮されます。
- 買い物客の人口統計
- 天気の履歴と予測
- 過去の出荷
- 製品の返品
- 特別なイベント
在庫の最適化という目標は、プロジェクトの主要な構成要素であり、クライアントは初期のフィールド評価版で大幅な売上増加を実現しました。 また、予測平均絶対誤差率 (MAPE) は、過去の平均ベースライン モデルと比較して 40% 減少しました。
プロジェクトの重要な部分は、データ サイエンス ワークフローをパイロット調査から実稼働レベルにスケールアップする方法を理解することでした。 この実稼働レベルのワークフローでは、CSE チームが次のことを行う必要がありました。
- さまざまな地域のモデルを開発する。
- モデルのパフォーマンスを継続的に更新および監視する。
- データ チームとエンジニアリング チーム間のコラボレーションを促進する。
現在の典型的なデータ サイエンス ワークフローは、実稼働ワークフローというよりも、1 回限りのラボ環境に近いものです。 データ サイエンティストの環境は、次の目的に適している必要があります。
- データを準備する。
- さまざまなモデルを使って実験する。
- ハイパーパラメーターを調整する。
- ビルド、テスト、評価、調整のサイクルを作成する。
これらのタスクに使用されるほとんどのツールは、特定の目的を持ち、自動化に適していません。 実稼働レベルの機械学習運用では、アプリケーション ライフサイクル管理と DevOps について、さらに考慮する必要があります。
CSE チームは、クライアントが実稼働レベルに運用をスケールアップすることを支援しました。 継続的インテグレーション (CI)/継続的デリバリー (CD) 機能のさまざまな側面を実装し、可観測性や Azure 機能との統合などの問題に対処しました。 実装中に、チームは既存の MLOps ガイダンスのギャップを明らかにしました。 MLOps をより深く理解して、大規模に適用するためには、それらのギャップを埋める必要がありました。
MLOps のプラクティスを理解することで、組織は、システムが生成する機械学習モデルが、ビジネスのパフォーマンスを向上させる実稼働品質のモデルであることを確認できます。 MLOps が実装されると、組織は、実稼働レベルの運用に対応した機械学習モデルの開発と実行に必要なインフラストラクチャとエンジニアリング作業に関連する低レベルの詳細に多くの時間を費やす必要がなくなります。 MLOps を実装すると、データ サイエンスとソフトウェア エンジニアリング コミュニティが協力して運用対応システムを提供する方法を学ぶのにも役立ちます。
CSE チームは、このプロジェクトを利用して、MLOps 成熟度モデルの開発などの問題に取り組むことで、機械学習コミュニティのニーズに対応します。 これらの取り組みは、MLOps プロセスの主要プレーヤーの典型的な課題を理解して、MLOps の導入を改善することを目的としていました。
エンゲージメントと技術のシナリオ
エンゲージメント シナリオでは、CSE チームが解決する必要があった実際の課題について説明します。 技術シナリオでは、確立された DevOps ライフサイクルと同程度に信頼できる MLOps ライフサイクルを作成するための要件を定義します。
エンゲージメント シナリオ
クライアントは、定期的なスケジュールで製品を小売販売店舗に直接配送します。 小売店ごとに製品の使用パターンが異なるため、毎週の配送の際に製品の在庫を変動させる必要があります。 顧客が使用している需要予測手法の目標は、売上を最大化し、製品の返品と販売機会の損失を最小限に抑えることです。 このプロジェクトでは、機械学習を使用した予測の改善に重点を置いています。
CSE チームは、プロジェクトを 2 つのフェーズに分割しました。 フェーズ 1 では、選択した販売地域での機械学習予測の効果に関するフィールドベースのパイロット調査をサポートするため、機械学習モデルの開発に重点を置きました。 フェーズ 1 の成功は、フェーズ 2 につながりました。このフェーズでは、チームは、1 つの地理的な領域をサポートする最小限のモデル グループから、クライアントのすべての販売地域に対する一連の持続可能な実稼働レベルのモデルへと、初期パイロット調査をスケールアップしました。 スケールアップしたソリューションに関する主な考慮事項は、多くの地理的な地域と、その地域の小売店に対応する必要があることでした。 このチームは、機械学習モデルを各地域の大規模小売店と小規模小売店の両方の専用としました。
フェーズ 1 のパイロット調査では、ある地域の小売店専用モデルで現地の販売履歴、現地の人口統計、天気、特別なイベントを使用して、その地域の小売店の需要予測を最適化できる可能性があることが確認されました。 4 つのアンサンブル機械学習予測モデルが、1 つの地域で販売店舗にサービスを提供しました。 モデルでは、週単位のバッチでデータを処理しました。 また、比較のために、チームは履歴データを使用して 2 つのベースライン モデルを開発しました。
スケールアップ フェーズ 2 ソリューションの最初のバージョンでは、CSE チームは小規模および大規模な販売店舗を含む 14 の地理的な地域を選択しました。 50 を超える機械学習予測モデルを使用しました。 チームは、さらなるシステムの拡張と機械学習モデルの継続的な改良を予想しました。 このような広範囲な機械学習ソリューションは、機械学習環境に関する DevOps のベスト プラクティス原則に基づいている場合にのみ持続可能であることが、すぐに明らかになりました。
| 環境 | 販売地域 | Format | モデル | モデルの区分 | モデルの説明 |
|---|---|---|---|---|---|
| 開発環境 | それぞれの地理的な市場または地域 (例: 北米) | 大型店舗 (スーパーマーケット、大規模小売店など) | 2 つのアンサンブル モデル | 動きの遅い製品 | 低速と高速の両方で、最小絶対収縮および選択演算子 (LASSO) 線形回帰モデルとカテゴリ埋め込みを使用したニューラル ネットワークのアンサンブルがあります |
| 動きの速い製品 | 低速と高速の両方で、LASSO 線形回帰モデルとカテゴリ埋め込みを使用したニューラル ネットワークのアンサンブルがあります | ||||
| 1 つのアンサンブル モデル | 該当なし | 履歴平均 | |||
| 小型店舗 (薬局、コンビニエンス ストアなど) | 2 つのアンサンブル モデル | 動きの遅い製品 | 低速と高速の両方で、LASSO 線形回帰モデルとカテゴリ埋め込みを使用したニューラル ネットワークのアンサンブルがあります | ||
| 動きの速い製品 | 低速と高速の両方で、LASSO 線形回帰モデルとカテゴリ埋め込みを使用したニューラル ネットワークのアンサンブルがあります | ||||
| 1 つのアンサンブル モデル | 該当なし | 履歴平均 | |||
| その他の 13 の地理的な領域については上記と同じ | |||||
| 実稼働環境については上記と同じ |
MLOps プロセスは、機械学習モデルのライフサイクル全体に対応するスケールアップされたシステムのフレームワークを提供しました。 フレームワークには、開発、テスト、デプロイ、操作、監視が含まれます。 これは、従来の CI/CD プロセスのニーズを満たします。 ただし、DevOps と比較して相対的に未成熟なため、既存の MLOps ガイダンスにギャップがあったことが明らかになりました。 プロジェクト チームは、これらのギャップの一部を埋めるように作業しました。 彼らは、スケールアップされた機械学習ソリューションの有効性を保証する機能プロセス モデルを提供したいと考えました。
このプロジェクトから開発された MLOps プロセスは、MLOps をより高いレベルの成熟度と実行可能性に移行するための重要な実際のステップになりました。 新しいプロセスは、他の機械学習プロジェクトに直接適用できます。 CSE チームは、学んだことを使用して、だれもが他の機械学習プロジェクトに適用できる MLOps 成熟度モデルのドラフトを構築しました。
技術のシナリオ
機械学習の DevOps とも呼ばれる MLOps は、運用環境での機械学習ライフサイクルの実装に関連する哲学、プラクティス、テクノロジを含む包括的な用語です。 それはまだ比較的新しい概念です。 MLOps とは何かを定義する試みが数多く行われ、データ サイエンティストがデータを準備する方法から、機械学習の結果を最終的に提供、監視、評価する方法まで、MLOps がすべてを包含できるかどうかについては、多くの人々が疑問に思っています。 DevOps では、一連の基本的なプラクティスの開発に何年もかかりましたが、MLOps はまだ開発の初期段階にあります。 進化するにつれて、さまざまなスキル セットと優先順位で動作する 2 つの規範 (ソフトウェア/運用エンジニアリング、データ サイエンス) を組み合わせるという課題が出てきます。
実際の実稼働環境での MLOps の実装には、克服する必要がある固有の課題があります。 チームは、Azure を使用して、MLOps パターンをサポートできます。 Azure では、資産管理とオーケストレーション サービスをクライアントに提供して、効果的な機械学習ライフサイクル管理を実現することもできます。 Azure サービスは、この記事で説明する MLOps ソリューションの基礎です。
機械学習モデルの要件
フェーズ 1 パイロット フィールド調査中の作業の多くは、CSE チームが 1 つの地域の大規模および小規模の小売店に適用する機械学習モデルを作成することでした。 モデルに関して注目すべき要件は次のとおりでした。
Azure Machine Learning サービスの使用。
Jupyter ノートブックで開発され、Python で実装された初期の試験的なモデル。
注意
チームは大規模店舗と小規模店舗に対して同じ機械学習アプローチを使用しましたが、トレーニング データとスコアリング データは店舗のサイズによって異なりました。
モデルの使用の準備が必要なデータ。
リアルタイムではなくバッチ単位で処理されるデータ。
コードやデータが変更されたり、モデルが古くなるたびに行うモデルの再トレーニング。
Power BI ダッシュボードでのモデルのパフォーマンスの表示。
履歴平均ベースライン モデルと比較した場合、MAPE <= 45% のときに、スコアリングにおけるモデル パフォーマンスは有意と見なされます。
MLOps の要件
チームは、フェーズ 1 パイロット フィールド調査からソリューションをスケールアップするためにいくつかの重要な要件を満たす必要がありました。この調査では、1 つの販売地域に対して少数のモデルしか開発されませんでした。 フェーズ 2 では、複数の地域にカスタム機械学習モデルを実装しました。 実装には次のものが含まれます。
新しいデータセットでモデルの再トレーニングをするための、各地域にある大規模および小規模店舗向けの週次バッチ処理。
機械学習モデルの継続的な改良。
DevOps に類似した MLOps 用の処理環境における CI/CD に共通する開発、テスト、パッケージ、テスト、デプロイ プロセスの統合。
注意
これは、データ サイエンティストとデータ エンジニアが過去に一般的に作業していた方法の変化を表しています。
店舗の履歴、人口統計、その他の重要な変数に基づいて、大規模および小規模店舗の各地域を表す一意のモデル。 そのモデルでは、処理エラーのリスクを最小限に抑えるために、データセット全体を処理する必要がありました。
さらにスケールアップする計画をしたうえで、 14 の販売地域をサポートするために最初にスケールアップする機能。
地域や他の店舗クラスターの長期的な予測を行うための追加モデルの計画。
機械学習モデル ソリューション
機械学習のライフサイクルは、データ サイエンスのライフサイクルとも呼ばれ、次の大まかなプロセス フローにほぼ適合します。
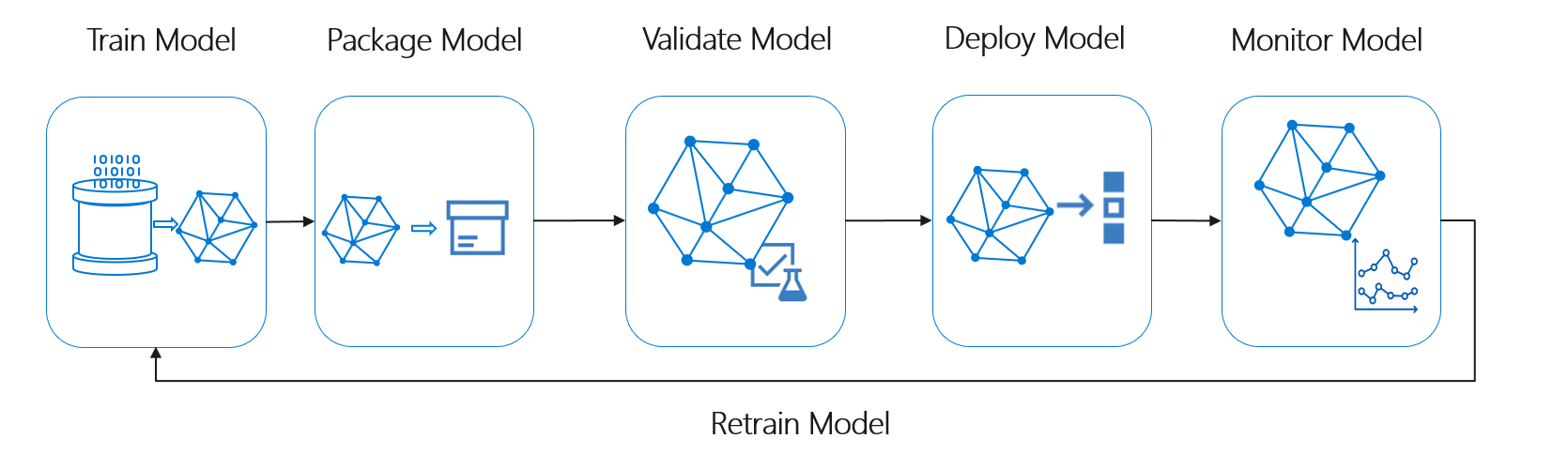
ここで、"デプロイ モデル" は、検証済みの機械学習モデルの運用上の使用を表すことができます。 DevOps と比較すると、 MLOps には、この機械学習ライフサイクルを一般的な CI/CD プロセスに統合するという、追加の課題があります。
このデータ サイエンス ライフサイクルは、一般的なソフトウェア開発ライフサイクルには従いません。 これには、モデルのトレーニングとスコア付けに Azure Machine Learning の使用が含まれているため、CI/CD オートメーションに、これらの手順を含める必要がありました。
データのバッチ処理がアーキテクチャの基礎となります。 2 つの Azure Machine Learning パイプラインが、プロセスの中心となります。1 つはトレーニング用で、もう 1 つはスコアリング用です。 次の図は、クライアント プロジェクトの最初のフェーズで使用されたデータ サイエンス手法を示しています。

チームは複数のアルゴリズムをテストしました。 最終的には、LASSO 線形回帰モデルと、カテゴリ埋め込みを使用するニューラル ネットワークのアンサンブル設計を選択しました。 このチームは、大規模店舗と小規模店舗の両方に、クライアントがサイトに格納できる製品のレベルによって定義した同じモデルを使用しました。 チームは、モデルをさらに動きが速い製品と動きが遅い製品に再分割しました。
データ サイエンティストは、チームが新しいコードをリリースしたときと、新しいデータが利用可能になったときに、機械学習モデルをトレーニングします。 トレーニングは通常、週次で実行されます。 このため、それぞれの処理の実行に大量のデータが含まれます。 チームはさまざまな形式で多くのソースからデータを収集するため、データ サイエンティストが処理できるように、データを使用可能な形式にするためのコンディショニングが必要です。 データ コンディショニングは、多大な手作業が必要であり、CSE チームは、それを自動化の主要な候補として特定しました。
前述のように、データ サイエンティストは実験的な Azure Machine Learning モデルを開発し、フェーズ 1 パイロット フィールド調査の 1 つの販売地域に適用し、この予測アプローチの有用性を評価しました。 CSE チームは、パイロット調査での店舗の売上増加が重要であると判断しました。 この成功は、14 の地理的地域と数千の店舗から始まるフェーズ 2 の完全な生産レベルにソリューションを適用することを正当化しました。 チームはその後、同じパターンを使用して地域を追加することができます。
パイロット モデルはスケールアップされたソリューションの基礎として機能しましたが、CSE チームは、モデルのパフォーマンスを向上させるために、モデルをさらに継続的に改良する必要があることを認識していました。
MLOps ソリューション
MLOps の概念が成熟するにつれて、チームはデータ サイエンスと DevOps 規範を結び付ける上での課題を発見することがよくあります。 その理由は、規範、ソフトウェア エンジニア、データ サイエンティストの主要なプレーヤーが、異なるスキル セットと優先順位で運用しているためです。
しかし、構築するための類似点があります。 MLOps は、DevOps と同様にツールチェーンによって実装される開発プロセスです。 MLOps ツールチェーンには、次のようなものが含まれます。
- バージョン コントロール
- コード分析
- ビルド オートメーション
- 継続的インテグレーション
- テストのフレームワークとオートメーション
- CI/CD パイプラインに統合されたコンプライアンス ポリシー
- デプロイのオートメーション
- 監視
- 障害復旧と高可用性
- パッケージおよびコンテナー管理
前述のように、このソリューションは既存の DevOps ガイダンスを利用しますが、クライアントとデータ サイエンス コミュニティのニーズを満たす、より成熟した MLOps 実装を作成するように強化されています。 MLOps は DevOps ガイダンスに基づいて構築し、次の追加の要件があります。
- コードのバージョン管理とは異なるデータおよびモデルのバージョン管理: スキーマと元のデータが変更されたときに、データセットのバージョン管理が必要になります。
- デジタル監査証跡の要件: コードとクライアント データを処理するときに、すべての変更を追跡します。
- 一般化: データ サイエンティストが入力データとシナリオに基づいてモデルを調整する必要があるため、モデルは再利用するためのコードとは異なります。 新しいシナリオ用にモデルを再利用するには、モデルの微調整、転送、学習が必要になる場合があります。 トレーニング パイプラインが必要です。
- 古いモデル: モデルは時間の経過と共に陳腐化しやすく、実稼働環境での関連性を維持するために、必要に応じて再トレーニングできる必要があります。
MLOps の課題
未成熟な MLOps の標準
MLOps の標準パターンはまだ進化中です。 ソリューションは、通常は一から新規に作成し、特定のクライアントまたはユーザーのニーズに合うように作成されます。 CSE チームはこのギャップを認識し、このプロジェクトで DevOps のベスト プラクティスを使用することを模索しました。 DevOps プロセスを、MLOps の追加要件に適合するように強化しました。 チームが開発したプロセスは、MLOps 標準パターンがどのようなものであるかを示す実用的な例です。
スキル セットの違い
ソフトウェア エンジニアとデータ サイエンティストは、固有のスキル セットをチームに持ち込みます。 これらの様々なスキル セットが、すべてのユーザーのニーズに合ったソリューションを見つけることを難しくしています。 実験から実稼働環境へのモデルのデリバリーのためには、よく理解されたワークフローを構築することが重要です。 チーム メンバーは、MLOps プロセスを中断することなく、システムに変更を統合する方法についての解釈を共有する必要があります。
複数モデルの管理
多くの場合、難しい機械学習シナリオを解決するために、複数のモデルが必要になります。 MLOps の課題の 1 つは、以下を含むこのようなモデルを管理することです。
- 一貫性のあるバージョン管理スキームを持つ。
- すべてのモデルを継続的に評価および監視します。
モデルの問題を診断し、再現可能なモデルを作成するには、コードとデータの両方についてトレース可能な系列も必要です。 カスタム ダッシュボードは、デプロイされたモデルのパフォーマンスを理解し、介入時期を示すことができます。 チームはこのプロジェクト用にこのようなダッシュボードを作成しました。
データ コンディショニングの必要性
これらのモデルで使用されるデータは、多くのプライベートおよびパブリック ソースから取得されます。 元のデータは整理されていないため、機械学習モデルが生の状態でデータを使用することはできません。 データ サイエンティストは、機械学習モデルで使用できるように、データを標準形式にコンディショニングする必要があります。
パイロット フィールド テストの多くは、機械学習モデルで処理できるように生データをコンディショニングすることに重点が置かれました。 MLOps システムでは、チームはこのプロセスを自動化し、出力を追跡する必要があります。
MLOps 成熟度モデル
MLOps 成熟度モデルの目的は、原則と実践を明確にし、 MLOps 実装のギャップを特定することです。 また、一度にすべてを実行しようとするのではなく、MLOps 機能をどのようにして段階的に拡張するかをクライアントに示す方法でもあります。 クライアントは、それを次のためのガイドとして使用する必要があります。
- プロジェクトの作業範囲の見積もり。
- 成功の基準の確立。
- 成果物を特定します。
MLOps 成熟度モデルは、次の 5 つのレベルの技術的機能を定義します。
| Level | 説明 |
|---|---|
| 0 | Ops なし |
| 1 | DevOps (MLOps なし) |
| 2 | 自動化されたトレーニング |
| 3 | 自動化されたモデル デプロイ |
| 4 | 自動化された運用 (完全な MLOps) |
MLOps 成熟度モデルの現在のバージョンについては、MLOps 成熟度モデルに関する記事を参照してください。
MLOps プロセスの定義
MLOps には、生データの取得からモデル出力の配信まで、すべてのアクティビティ (スコアリングとも呼ばれます) が含まれます。
- データ コンディショニング
- モデル トレーニング
- モデルのテストと評価
- 定義とパイプラインの構築
- リリース パイプライン
- デプロイ
- ポイントの計算
基本的な機械学習プロセス
基本的な機械学習プロセスは、従来のソフトウェア開発に似ていますが、大きな違いがあります。 次の図は、機械学習プロセスの主要なステップを示しています。
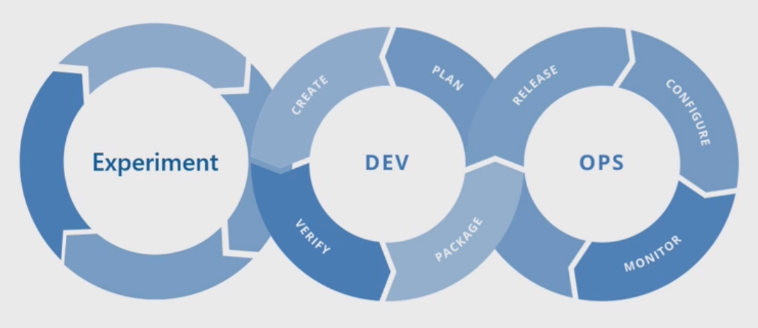
実験フェーズは、データ サイエンス ライフサイクルに固有のものであり、データ サイエンティストが従来どのように作業を行っているかを反映しています。 コード開発者の作業方法とは異なります。 次の図にこのライフサイクルを詳細に示します。
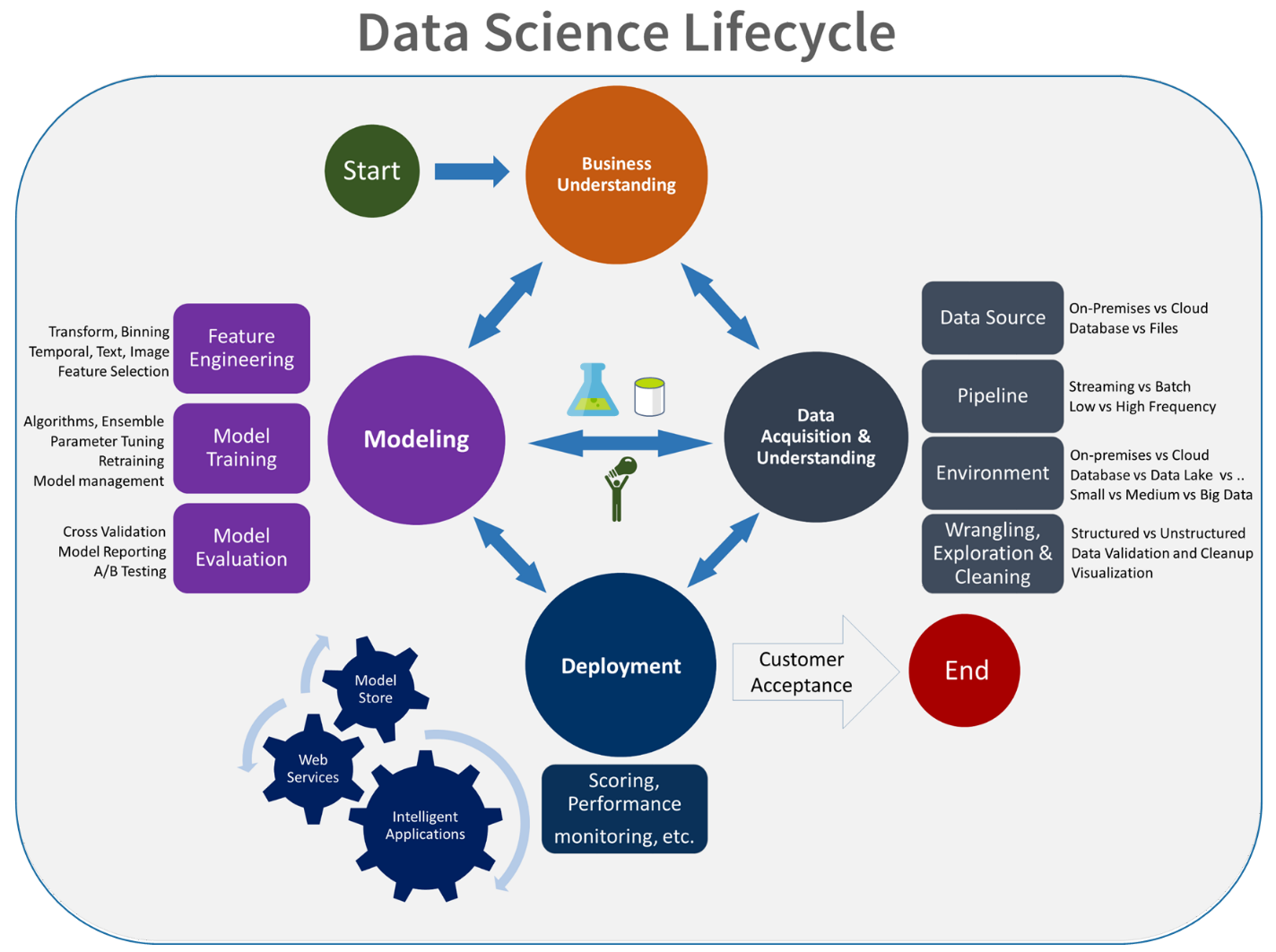
このデータ開発プロセスを MLOps に統合することには、課題が伴います。 ここで、プロセスを MLOps でのサポート形式に統合するためにチームが使用したパターンを示します。

MLOps の役割は、実稼働レベル システムで一般的な、大規模な CI/CD 環境を効率的にサポートできる連携したプロセスを作成することです。 概念的には、MLOps モデルには、実験からスコアリングまでのすべてのプロセス要件が含まれている必要があります。
CSE チームは、MLOps プロセスをクライアント固有のニーズに合わせて改良しました。 最も注目すべきニーズは、リアルタイム処理ではなくバッチ処理でした。 チームがスケールアップされたシステムを開発したとき、いくつかの不備を特定し、解決しました。 これらの不備のうち最も重要なものは、Azure Data Factory と Azure Machine Learning の間のブリッジの開発につながりました。これは、チームが Azure Data Factory の組み込みコネクタを使用して実装したものです。 彼らは、プロセスのオートメーションを機能させるために必要なトリガー起動とステータス監視を容易にするために、このコンポーネント セットを作成しました。
もう 1 つの根本的な変更は、データ サイエンティストは、トレーニングやスコアリングを直接トリガーするのではなく、 Jupyter ノートブックから MLOps デプロイ プロセスに実験的なコードをエクスポートする機能を必要としていたことです。
最終的な MLOps プロセス モデルの概念は次のとおりです。

重要
スコアリングは最後のステップです。 このプロセスでは、機械学習モデルを実行して予測を行います。 これは、"需要予測" の基本的なビジネスのユース ケース要件に対応しています。 チームは、MAPE を使用して予測の品質を評価します。これは、統計的予測方法の予測精度の尺度であり、機械学習の回帰問題の損失関数です。 このプロジェクトでは、チームは <= 45% の有意な MAPE を考慮しました。
MLOps プロセス フロー
次の図は、機械学習ライフサイクルに CI/CD の開発とリリースのワークフローを適用する方法を示しています。
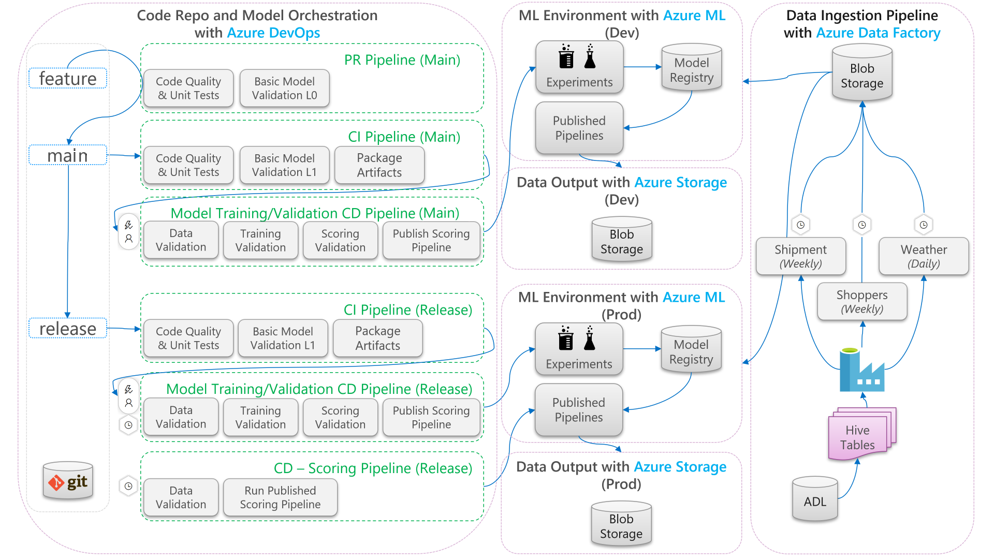
- 機能分岐から pull request(PR) が作成されると、パイプラインはコード検証テストを実行して、単体テストおよびコード品質テストを通してコードの品質を検証します。 品質アップストリームを検証するために、パイプラインでは基本モデル検証テストも実行され、モック データのサンプル セットを使用してエンドツーエンドのトレーニングとスコアリングのステップが検証されます。
- PR がメイン ブランチにマージされると、CI パイプラインで同じコード検証テストと、エポックを増やした基本モデル検証テストが実行されます。 次にパイプラインでは、"成果物" がパッケージ化されます。これには、機械学習環境で実行するコードとバイナリが含まれます。
- アーティファクトが使用可能になると、モデル検証 CD パイプラインがトリガーされます。 それによって開発用の機械学習環境でエンドツーエンドの検証が実行されます。 スコアリング メカニズムが発行されます。 バッチ スコアリング シナリオでは、スコアリング パイプラインが機械学習環境に発行され、結果を生成するためにトリガーされます。 リアルタイム スコアリング シナリオを使用する場合は、Web アプリを発行するか、コンテナーをデプロイできます。
- マイルストーンが作成され、リリース ブランチにマージされると、同じ CI パイプラインとモデル検証 CD パイプラインがトリガーされます。 今回は、リリース ブランチのコードに対して実行されます。
上記の MLOps プロセス データ フローは、同様のアーキテクチャを選択するプロジェクトの原型フレームワークとみなすことができます。
コード検証テスト
機械学習のコード検証テストは、コード ベースの品質の検証に重点を置いています。 これは、コード品質テスト (リンティング)、単体テスト、コード カバレッジ測定を行うエンジニアリング プロジェクトと同じ概念です。
基本モデル検証テスト
モデルの検証とは、一般に、有効な機械学習モデルを作成するために必要とされる、完全なエンドツーエンドのプロセスのステップを検証することを意味します。 これには、次のような手順が含まれます。
- データの検証: 入力データが有効であることを確認します。
- トレーニングの検証: モデルを正常にトレーニングできることを確認します。
- スコアリングの検証: チームがトレーニング済みのモデルを正常に使用して入力データでスコアリングできることを確認します。
この一連のステップを機械学習環境に対して実行すると、コストが高く、時間がかかります。 その結果、チームは開発マシン上でローカルに基本的なモデル検証テストを行いました。 上記の手順を実行し、次を使用しました。
- ローカル テスト データセット: リポジトリにチェックインされ、入力データ ソースとして使用される小さなデータセット (多くの場合、難読化されたデータセット)。
- ローカル フラグ: コードでデータセットをローカルに実行する意図を示す、モデルのコード内のフラグまたは引数。 そのフラグは、機械学習環境への任意の呼び出しをバイパスするようにコードに指示します。
これらの検証テストのこの目的は、トレーニング済みのモデルのパフォーマンスを評価することではありません。 むしろ、エンドツーエンド プロセスのコードの品質の高さを検証することです。 PR および CI ビルドにモデル検証テストを組み込むなど、アップストリームにプッシュされるコードの品質を保証します。 また、エンジニアやデータ サイエンティストが、デバッグ目的でコードにブレークポイントを設定することもできます。
モデル検証 CD パイプライン
モデル検証パイプラインの目的は、実際のデータを使用して、機械学習環境でエンドツーエンド モデルのトレーニングとスコアリングのステップを検証することです。 生成された任意のトレーニング済みモデルは、検証が完了した後に昇格を待機するために、モデル レジストリに追加され、タグ付けされます。 バッチ予測の場合、昇格は、このバージョンのモデルを使用するスコアリング パイプラインの発行にできます。 リアルタイムのスコアリングでは、モデルにタグを付けて、それが昇格されたことを示すことができます。
スコアリング CD パイプライン
スコアリング CD パイプラインは、モデル検証に使用されたものと同じモデル オーケストレーターが、発行されたスコアリング パイプラインをトリガーするバッチ推論シナリオに適用できます。
開発環境と実稼働環境
開発 (dev) 環境を実稼働 (prod) 環境から分離することをお勧めします。 分離により、システムは、モデル検証 CD パイプラインとスコアリング CD パイプラインを異なるスケジュールでトリガーできます。 説明されている MLOps フローでは、メイン ブランチをターゲットとするパイプラインが開発環境で実行され、リリース ブランチをターゲットとするパイプラインが実稼働環境で実行されます。
コードの変更とデータの変更
前のセクションでは主に、開発からリリースまでのコード変更を処理する方法を扱います。 ただし、データの変更は、実稼働環境において同じ検証品質と一貫性を提供するために、コードの変更と同じ厳格さに従う必要があります。 データ変更トリガーまたはタイマー トリガーを使用する場合、システムは、モデル検証 CD パイプラインとスコアリング CD パイプラインをモデル オーケストレーターからトリガーし、リリース ブランチ実稼働環境でのコード変更に対して実行されるのと同じプロセスを実行できます。
MLOps のペルソナとロール
あらゆる MLOps プロセスの重要な要件は、プロセスの多くのユーザーのニーズを満たすことです。 設計目的では、これらのユーザーを個々のペルソナと見なします。 このプロジェクトの場合、チームは次のようなユーザー ペルソナを識別しました。
- データ サイエンティスト: 機械学習モデルとそのアルゴリズムを作成します。
- エンジニア
- データ エンジニア: データ コンディショニングを処理します。
- ソフトウェア エンジニア: 資産パッケージと CI/CD ワークフローへのモデルの統合を処理します。
- 運用または IT: システムの運用を監視します。
- ビジネス利害関係者: 機械学習モデルによって行われた予測と、それがビジネスにどのように役立つかを検討します。
- データのエンド ユーザー: ビジネス上の意思決定を支援する何らかの方法でモデル出力を使用します。
チームは、ペルソナおよびロール調査の主要な 3 つの発見に対処する必要がありました。
- データ サイエンティストとエンジニアは、作業におけるアプローチとスキルが一致していません。 データ サイエンティストとエンジニアが容易にコラボレーションできるようにすることは、MLOps プロセス フローの設計における主要な考慮事項です。 すべてのチーム メンバーが新しいスキルを獲得する必要があります。
- だれも疎外せずに、すべての主要なペルソナを統合する必要があります。 これを行うには、次の方法があります。
- MLOps の概念モデルについての解釈を確認してください。
- 共に働くチーム メンバーについて合意します。
- 共通の目標を達成するため作業ガイドラインを確立します。
- ビジネスの利害関係者とデータ エンド ユーザーがモデルからのデータ出力を操作する方法が必要な場合は、わかりやすい UI が標準ソリューションです。
他のチームが実稼働環境での使用に合わせてスケールアップする際、他の機械学習プロジェクトで同様の問題が間違いなく発生します。
MLOps ソリューションのアーキテクチャ
論理アーキテクチャ

データはさまざまな形式の多くのソースから取得されるため、データ レイクに挿入される前にコンディショニングされます。 コンディショニングは、Azure Functions として動作するマイクロサービスを使用して行われます。 クライアントは、マイクロサービスをデータ ソースに合わせてカスタマイズしたうえで、トレーニングおよびスコアリング パイプラインで使用できる標準化された csv 形式に変換します。
システム アーキテクチャ
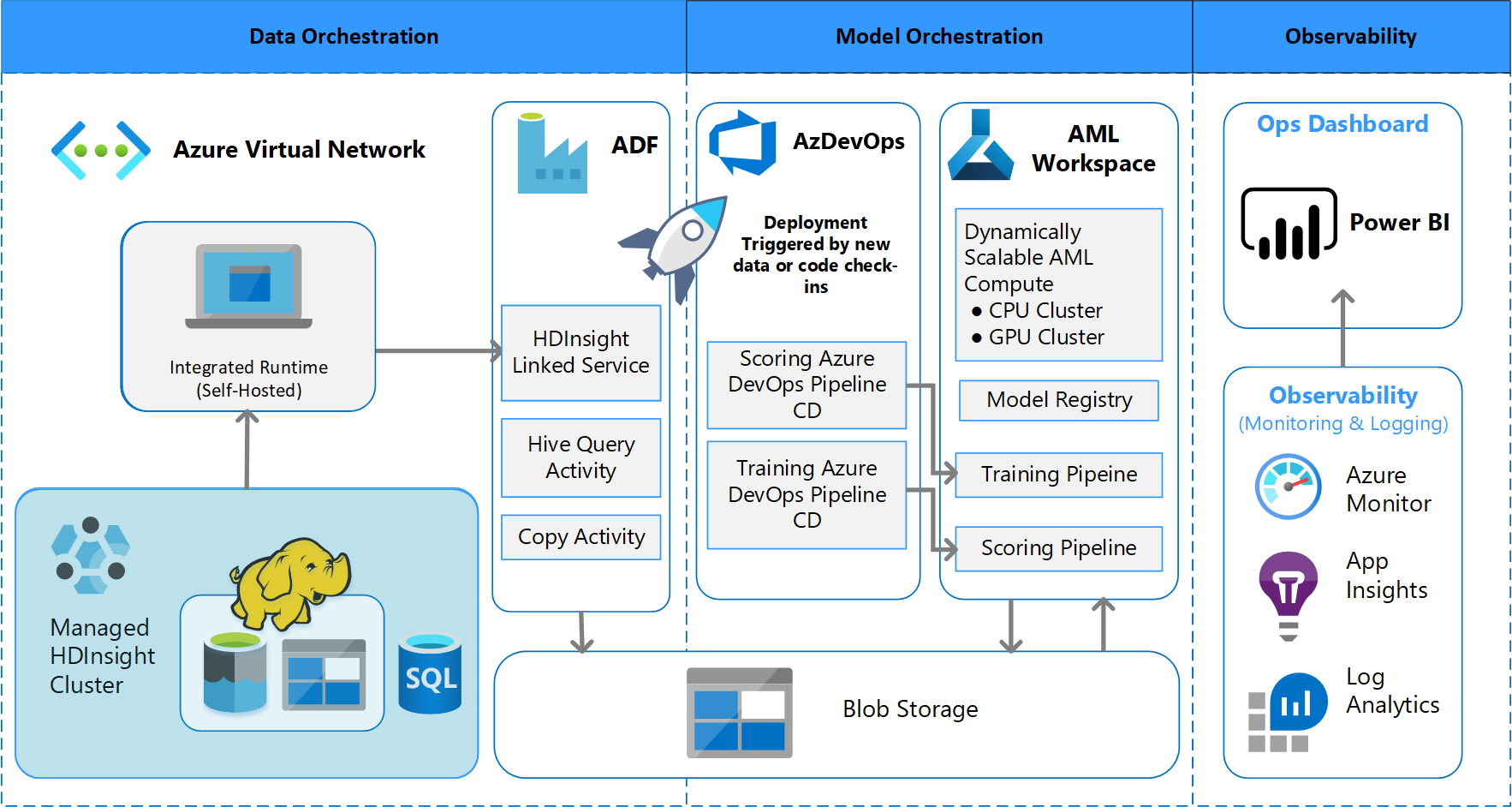
バッチ処理のアーキテクチャ
チームは、バッチ データ処理スキームをサポートするためのアーキテクチャ設計を考案しました。 別の方法もありますが、使用するものは MLOps プロセスをサポートする必要があります。 使用可能な Azure サービスを全面的に使用することは、設計の要件でした。 このアーキテクチャを次の図に示します。

ソリューションの概要
Azure Data Factory では、次の処理が行われます。
- Azure 関数をトリガーして、データ インジェストと Azure Machine Learning パイプラインの実行を開始します。
- Azure Machine Learning パイプラインの完了をポーリングするための持続的関数を起動します。
Power BI のカスタム ダッシュボードに結果が表示されます。 OpenCensus Python SDK を介して SQL Azure、Azure Monitor、App Insights に接続されている他の Azure ダッシュボードで、Azure リソースを追跡します。 これらのダッシュボードには、機械学習システムの正常性に関する情報が提供されます。 また、クライアントが製品の注文予測に使用するデータも表示されます。
モデルのオーケストレーション
モデルのオーケストレーションは、次のステップに従います。
- PR が送信されると、DevOps によってコード検証パイプラインがトリガーされます。
- そのパイプラインでは、単体テスト、コード品質テスト、モデル検証テストが実行されます。
- メイン ブランチにマージされると、同じコード検証テストが実行され、DevOps によって成果物がパッケージ化されます。
- 成果物の DevOps 収集は、Azure Machine Learning が次のことを実行するようにトリガーします:
- データの検証。
- トレーニングの検証。
- スコアリングの検証。
- 検証完了後に、最終的なスコアリング パイプラインが実行されます。
- データを変更して新しい PR を送信すると、検証パイプラインが再度トリガーされ、その後に最終的なスコアリング パイプラインがトリガーされます。
実験の有効化
前述のように、従来のデータ サイエンスの機械学習ライフサイクルでは、変更を加えなければ MLOps プロセスはサポートされません。 さまざまな種類の手動ツールと実験、検証、パッケージ化、モデルのハンドオフを使用しますが、これらは効果的な CI/CD プロセスとなるように簡単にスケーリングすることはできません。 MLOps には、高いレベルのプロセス オートメーションが要求されます。 新しい機械学習モデルが開発されている場合でも、古いモデルが変更されている場合でも、機械学習モデルのライフサイクルは自動化する必要があります。 フェーズ 2 のプロジェクトでは、チームは Azure DevOps を使用して、トレーニング タスク用の Azure Machine Learning パイプラインを調整および再発行します。 実行時間の長いメイン ブランチで、モデルの基本的なテストを実行し、長時間実行されるリリース ブランチを通じて安定版リリースをプッシュします。
ソース管理がこのプロセスの重要な部分になります。 Git は、ノートブックおよびモデル コードの追跡に使用するバージョン管理システムです。 プロセス オートメーションもサポートされています。 ソース管理のために実装する基本的なワークフローには、次の原則が適用されます。
- コードとデータセットには正式なバージョン管理を使用します。
- 新しいコード開発では、コードの開発と検証が完全に済むまでブランチを使用します。
- 新しいコードが検証されたら、メイン ブランチにマージできます。
- リリースでは、メイン ブランチとは別の永続的なバージョン管理されたブランチが作成されます。
- 各データセットの整合性を維持できるように、トレーニングまたは使用するためにコンディショニングしたデータセットに対してバージョンとソース管理を使用します。
- ソース管理を使用して、Jupyter Notebook の実験を追跡します。
データ ソースとの統合
データ サイエンティストは、多くの生データ ソースと処理されたデータセットを使用して、さまざまな機械学習モデルを試します。 実稼働環境内のデータの量は膨大になる可能性があります。 データ サイエンティストがさまざまなモデルを試してみるためには、Azure Data Lake などの管理ツールを使用する必要があります。 正式な ID およびバージョン管理の要件が、すべての生データ、準備されたデータセット、機械学習モデルに適用されます。
このプロジェクトでは、データ サイエンティストがモデルへの入力用に次のデータのコンディショニングをしました。
- 2017 年 1 月以降の週次出荷履歴データ
- 郵便番号ごとの履歴および予測の日次気象データ
- 各ストア ID の買い物客データ
ソース管理との統合
データ サイエンティストにエンジニアリングのベスト プラクティスを適用させるには、使用するツールと GitHub などのソース管理システムとの統合が簡単である必要があります。 このプラクティスにより、機械学習モデルのバージョン管理、チーム メンバー間のコラボレーション、およびチームでデータの損失やシステムの停止が発生した場合のディザスター リカバリーが可能になります。
モデル アンサンブルのサポート
このプロジェクトでのモデル設計は、アンサンブル モデルでした。 つまり、データ サイエンティストは、最終的なモデル設計において多くのアルゴリズムを使用しました。 この場合、モデルに同じ基本的なアルゴリズム設計が使用されています。 唯一の違いは、それらに異なるトレーニング データとスコアリング データが使用されたことです。 モデルでは、LASSO 線形回帰アルゴリズムとニューラル ネットワークの組み合わせが使用されました。
チームは、特定の要求に対応するために、実稼働環境で多数のリアルタイム モデルの実行をサポートするところまでプロセスを進めるオプションを検討しましたが、実装はしませんでした。 このオプションは、A/B テストおよびインターリーブ実験でのアンサンブル モデルの使用に対応できます。
エンドユーザー インターフェイス
チームは、観察、監視、インストルメンテーション用のエンドユーザー UI を開発しました。 前述のように、ダッシュボードには機械学習モデルのデータが視覚的に表示されます。 これらのダッシュボードには、わかりやすい形式で次のデータが表示されます。
- 入力データの前処理を含むパイプライン ステップ。
- 機械学習モデル処理の正常性を監視するには、次のようにします。
- デプロイしたモデルからどのようなメトリックを収集しますか?
- MAPE: 平均絶対誤差率、全体的なパフォーマンスを追跡するための主要なメトリック。 (ターゲットとする各モデルの MAPE 値は、 <= 0.45)。
- RMSE 0: 実際のターゲット値 = 0 の場合の二乗平均平方根誤差 (RMSE)。
- RMSE すべて: データセット全体での RMSE。
- 使用しているモデルの実稼働環境でのパフォーマンスが予想どおりかどうかを評価するには、どうすればよいでしょうか?
- 実稼働データが予想した値から過度に逸脱しているかどうかを確認する方法はありますか?
- 実稼働環境でのモデルのパフォーマンスが低いですか?
- フェールオーバーの状態になっていますか?
- デプロイしたモデルからどのようなメトリックを収集しますか?
- 処理されたデータの品質を追跡します。
- 機械学習モデルによって生成されたスコアリングまたは予測を表示します。
データの性質およびデータの処理と分析の方法に応じて、アプリケーションによってダッシュボードが設定されます。 そのため、チームは各ユースケースのダッシュボードの正確なレイアウトを設計する必要があります。 サンプル ダッシュボードを 2 つ示します。
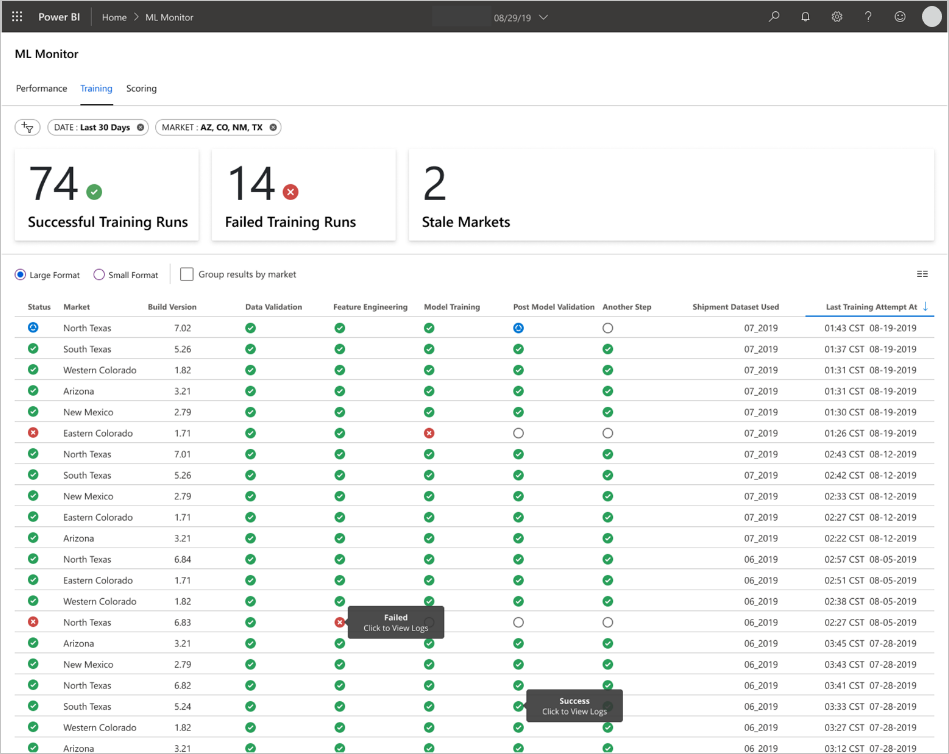

ダッシュボードは、機械学習モデルの予測をエンド ユーザーが利用できるように、すぐに利用できる情報を提供するように設計されています。
注意
古いモデルとは、データ サイエンティストがスコアリングに使用されるモデルをトレーニングしたスコアリング実行のうち、スコアリングが行われてから 60 日以上経過したものを言います。 ML モニター ダッシュボードの [スコアリング] ページに、この正常性メトリックが表示されます。
コンポーネント
- Azure Machine Learning
- Azure Blob Storage
- Azure Data Lake Storage
- Azure Pipelines
- Azure Data Factory
- Python 向け Azure Functions
- Azure Monitor
- Azure SQL Database
- Azure のダッシュ ボード
- Power BI
考慮事項
ここでは、調査する必要がある考慮事項の一覧を紹介します。 これらは、プロジェクト中に CSE チームが学んだ教訓に基づいています。
環境に関する考慮事項
- データ サイエンティストは、ほとんどの機械学習モデルを Python を使って開発します。多くの場合、Jupyter ノートブックから始めます。 これらのノートブックを実稼働コードとして実装することは困難な場合があります。 Jupyter Notebook は実験的なツールに近く、Python スクリプトの方が実稼働環境に適しています。 多くの場合、チームはモデル作成コードを Python スクリプトにリファクタリングするために時間を費やす必要があります。
- DevOps と機械学習に不慣れなクライアントに、実験環境と実稼働環境には異なる厳格さが必要であることを認識させるため、2 つを分離することをお勧めします。
- Azure Machine Learning ビジュアル デザイナーや AutoML などのツールは、クライアントが標準の DevOps プラクティスを強化して残りのソリューションに適用している間に、基本的なモデルを立ち上げるのに効果的です。
- Azure DevOps には、Azure Machine Learning と統合して、パイプライン ステップのトリガーに役立つプラグインがあります。 MLOpsPython リポジトリには、このようなパイプラインの例がいくつかあります。
- 機械学習には、多くの場合、トレーニング用の強力な GPU マシンが必要です。 クライアントがそのようなハードウェアをまだ利用できない場合、Azure Machine Learning コンピューティング クラスターは、自動スケーリングする費用対効果の高い強力なハードウェアを迅速にプロビジョニングするための効果的なパスを提供できます。 クライアントで高度なセキュリティまたは監視のニーズがある場合は、標準 VM、Databricks、ローカル コンピューティングなどの他のオプションがあります。
- クライアントが成功するためには、彼らのモデル構築チーム (データ サイエンティスト) とデプロイ チーム (DevOps エンジニア) が、強力なコミュニケーションのチャネルを持っている必要があります。 毎日のスタンドアップ ミーティングまたは正式なオンライン チャット サービスでこれを実現できます。 どちらのアプローチも、開発作業を MLOps フレームワークに統合するのに役立ちます。
データ準備に関する考慮事項
Azure Machine Learning を使用するための最も簡単なソリューションは、サポートされているデータ ストレージ ソリューションにデータを格納することです。 Azure Data Factory などのツールは、スケジュールに従ってこれらの場所との間でデータをパイプ処理するのに効果的です。
モデルを最新状態に保つため、クライアントでは、追加の再トレーニング データを頻繁にキャプチャすることが重要です。 彼らにデータ パイプラインがまだない場合は、それを作成することがソリューション全体の重要になります。 Azure Machine Learning の Datasets などのソリューションを使用すると、モデルの追跡可能性を高めるためにデータをバージョン管理するのに役立ちます。
モデルのトレーニングと評価に関する考慮事項
機械学習の体験を始めたばかりのクライアントが完全な MLOps パイプラインを実装しようとすることは大きな負担です。 必要に応じて、Azure Machine Learning を使用して実験の実行を追跡し、Azure Machine Learning コンピューティングをトレーニングのターゲットとして使用すると、それを容易にすることができます。 これらのオプションを使用すると、Azure サービスの統合を開始するためのエントリ ソリューションの障壁が下がる可能性があります。
ノートブックの実験から反復可能なスクリプトへの移行は、多くのデータ サイエンティストにとっては大まかな移行です。 Python スクリプトでトレーニング コードを記述できるようになるのが早ければ早いほど、トレーニング コードのバージョン管理と再トレーニングの有効化を始めやすくなります。
それは可能な唯一の方法ではありません。 Databricks では、ノートブックをジョブとしてスケジュール設定できます。 しかし、現在のクライアント エクスペリエンスに基づくと、テストの制限により、このアプローチを完全な DevOps プラクティスでインストルメント化することは困難です。
また、モデルを成功と見なすメトリックとしてどのようなものが使用されているかを理解することも重要です。 多くの場合、精度だけでは、あるモデルと別のモデルの全体的なパフォーマンスを判断するのに十分ではありません。
コンピューティングに関する考慮事項
- お客様は、コンテナーを使用してコンピューティング環境を標準化することを検討する必要があります。 ほとんどすべての Azure Machine Learning コンピューティング ターゲットでは、Docker の使用がサポートされています。 コンテナーに依存関係を処理させることで、特にチームが多くのコンピューティング ターゲットを使用する場合に、摩擦を大幅に減らすことができます。
モデルの処理に関する考慮事項
- Azure Machine Learning SDK には、登録済みのモデルから Azure Kubernetes Service に直接デプロイするオプションが用意されています。これにより、適用されるセキュリティまたはメトリックに関する制限が発生します。 クライアントがモデルをテストするためのより簡単なソリューションの発見を試行できますが、実稼働環境のワークロードに対しては、AKS へのより堅牢なデプロイを開発するのが最善です。
次のステップ
- MLOps についての詳細情報
- Azure 上の MLOps
- Azure Monitor の視覚化
- Machine Learning のライフサイクル
- Azure DevOps Machine Learning 拡張機能
- Azure Machine Learning CLI
- Azure Machine Learning イベントに基づいてアプリケーション、プロセス、または CI/CD ワークフローをトリガーする
- Azure DevOps を使用してモデルのトレーニングとデプロイを設定する