ミッション クリティカルなワークロードに対するアプリケーション設計の考慮事項
ベースラインのミッション クリティカルなリファレンス アーキテクチャは、シンプルなオンライン カタログ アプリケーションによる信頼性の高いワークロードについて説明しています。 エンド ユーザーは、項目のカタログを参照する、項目の詳細を表示する、項目の評価やコメントを投稿することができます。 この記事では、要求の非同期処理やソリューション内で高スループットを実現する方法など、ミッション クリティカルなアプリケーションの信頼性と回復性の側面について説明します。
重要
 このガイダンスは、Azure でのミッション クリティカルなアプリケーション開発を紹介する実稼働グレードのリファレンス実装によって裏付けられています。 この実装は、実稼働に向けた最初のステップにおけるさらなるソリューション開発の基礎として使用できます。
このガイダンスは、Azure でのミッション クリティカルなアプリケーション開発を紹介する実稼働グレードのリファレンス実装によって裏付けられています。 この実装は、実稼働に向けた最初のステップにおけるさらなるソリューション開発の基礎として使用できます。
アプリケーションの構成
大規模でミッション クリティカルなアプリケーションでは、エンドツーエンドのスケーラビリティと回復性のためにアーキテクチャを最適化することが不可欠です。 この状態は、コンポーネントを独立して動作可能な機能ユニットに分離することで実現できます。 アプリケーション スタックのすべてのレベルでこの分離を適用して、システムの各部分を独立してスケーリングし、需要の変化に対応できるようにします。
そのアプローチの例を実装に示します。 アプリケーションでステートレス API エンドポイントを使用すると、実行時間の長い書き込み要求がメッセージング ブローカーを介して非同期的に分離されます。 ワークロードは、AKS クラスター全体とスタンプ内の他の依存関係をいつでも削除して再作成できるように構成されます。 主要なコンポーネントは次のとおりです。
- ユーザー インターフェイス (UI): エンド ユーザーがアクセスするシングルページの Web アプリは、Azure Storage アカウントの静的 Web サイト ホスティングでホストされます。
- API (
CatalogService): UI アプリケーションによって呼び出される REST API。ただし、他の潜在的なクライアント アプリケーションでも使用できます。 - worker (
BackgroundProcessor): バックグラウンド worker。メッセージ バスで新しいイベントをリッスンして、データベースへの書き込み要求を処理します。 このコンポーネントの API は公開されません。 - 正常性サービス API (
HealthService): 重要コンポーネント (データベース、メッセージング バス) が動作しているかどうかをチェックして、アプリケーションの正常性を報告するために使用されます。

API、worker、正常性チェック アプリケーションはワークロードと呼ばれ、専用の AKS 名前空間 (workload と呼ばれる) 内のコンテナーとしてホストされます。 ポッド間の直接通信はありません。 ポッドはステートレスであり、独立してスケーリングできます。
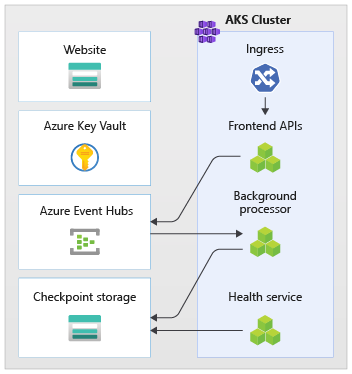
クラスターで実行されているサポート コンポーネントは他にもあります。
- イングレス コントローラー: Nginx イングレス コントローラーは、受信要求をワークロードにルーティングし、ポッド間で負荷分散するために使用されます。 パブリック IP アドレスを持つ Azure Load Balancer を介して公開されます (ただし、Azure Front Door 経由でのみアクセスされます)。
- 証明書マネージャー: Jetstack の
cert-managerは、イングレス ルールに SSL/TLS 証明書を自動プロビジョニングするために使用されます (Let's Encrypt を使用)。 - CSI シークレット ドライバー: Azure Key Vault Provider for Secrets Store CSI は、Azure Key Vault から接続文字列などのシークレットを安全に読み取るために使用されます。
- 監視エージェント: 既定の OMSAgent 構成は、Log Analytics ワークスペースに送信される監視データの量を減らすために調整されます。
データベース接続
デプロイ スタンプは一時的なものであるため、状態をスタンプ内に保持することはできるだけ避けます。 状態は、外部化されたデータ ストアに保持してください。 信頼性の SLO をサポートするには、そのデータ ストアに回復性が必要です。 マネージド (PaaS) サービスを、タイムアウト、切断、その他の障害状態を自動的に処理するネイティブ SDK ライブラリと組み合わせて使用することをお勧めします。
このリファレンス実装では、Azure Cosmos DB がアプリケーションのメイン データ ストアとして機能します。 複数リージョンの書き込みが提供されているため、Azure Cosmos DB が選択されました。 各スタンプは、同じリージョン内の Azure Cosmos DB レプリカに書き込むことができ、リージョン間のデータ レプリケーションと同期が Azure Cosmos DB によって内部的に処理されます。 データベース エンジンのすべての機能をサポートしているため、Azure Cosmos DB for NoSQL が使用されています。
詳細については、「ミッション クリティカルなワークロードのデータ プラットフォーム」を参照してください。
注意
新しいアプリケーションでは、Azure Cosmos DB for NoSQL を使用する必要があります。 別の NoSQL プロトコルを使用するレガシ アプリケーションの場合は、Azure Cosmos DB への移行パスを評価します。
ヒント
パフォーマンスよりも可用性を優先するミッション クリティカルなアプリケーションの場合は、"厳密な整合性" レベルの単一リージョンの書き込みと複数リージョンの読み取りをお勧めします。
このアーキテクチャでは、Event Hubs チェックポイント設定のために、スタンプに状態を一時的に格納する必要があります。 その目的のために、Azure Storage が使用されています。
ワークロード コンポーネントはすべて、Azure Cosmos DB .NET Core SDK を使用して、データベースと通信します。 SDK には、データベース接続を維持し、障害を処理するための堅牢なロジックが用意されています。 次に、主要な構成設定をいくつか示します。
- 直接接続モードを使用します。 パフォーマンスが向上するため、これは .NET SDK v3 の既定の設定です。 HTTP を使用するゲートウェイ モードと比較して、ネットワーク ホップが少なくなります。
- Azure Cosmos DB クライアントで Create、Upsert、Patch、Replace の操作からドキュメントを返さないようにして、ネットワーク トラフィックを削減するために、書き込み時にコンテンツの応答を返す機能が無効になっています。 また、これはクライアントでの以降の処理に必要ありません。
- カスタム シリアル化は、JSON プロパティの名前付けポリシーを
JsonNamingPolicy.CamelCaseに設定して、.NET スタイルのプロパティを標準の JSON スタイルに、またはその逆に変換するのに使用されます。 既定の無視条件により、null 値を持つプロパティはシリアル化中に無視されます (JsonIgnoreCondition.WhenWritingNull)。 - アプリケーション リージョンはスタンプのリージョンに設定されます。これにより、SDK を使用して、最も近い接続エンドポイント (できれば同じリージョン内) を見つけることができます。
//
// /src/app/AlwaysOn.Shared/Services/CosmosDbService.cs
//
CosmosClientBuilder clientBuilder = new CosmosClientBuilder(sysConfig.CosmosEndpointUri, sysConfig.CosmosApiKey)
.WithConnectionModeDirect()
.WithContentResponseOnWrite(false)
.WithRequestTimeout(TimeSpan.FromSeconds(sysConfig.ComsosRequestTimeoutSeconds))
.WithThrottlingRetryOptions(TimeSpan.FromSeconds(sysConfig.ComsosRetryWaitSeconds), sysConfig.ComsosMaxRetryCount)
.WithCustomSerializer(new CosmosNetSerializer(Globals.JsonSerializerOptions));
if (sysConfig.AzureRegion != "unknown")
{
clientBuilder = clientBuilder.WithApplicationRegion(sysConfig.AzureRegion);
}
_dbClient = clientBuilder.Build();
非同期メッセージング
疎結合を使用すると、サービスが他のサービスに依存しないようにサービスを設計できます。 疎の側面により、サービスは独立して動作できます。 結合の側面により、明確に定義されたインターフェイスを介したサービス間通信が可能になります。 ミッション クリティカルなアプリケーションのコンテキストでは、ダウンストリームの障害がフロントエンドや異なるデプロイ スタンプにカスケードされないようにすることで、高可用性を促進します。
主な特性:
- サービスは、同じコンピューティング プラットフォーム、プログラミング言語、またはオペレーティング システムを使用するという制約がありません。
- サービスは独立してスケーリングします。
- ダウンストリームの障害がクライアント トランザクションに影響しません。
- データの作成と永続化が別々のサービスで行われるため、トランザクションの整合性を維持することはより困難です。 これは、べき等メッセージ処理に関するこのガイダンスで説明されているように、メッセージング サービスと永続化サービス全体の課題でもあります。
- エンドツーエンドのトレースには、より複雑なオーケストレーションが必要です。
キュー ベースの負荷平準化パターンや競合コンシューマー パターンなど、よく知られている設計パターンを使用することを強くお勧めします。 これらのパターンは、プロデューサーからコンシューマーへの負荷分散、コンシューマーによる非同期処理に役立ちます。 たとえば、worker では、データベースの書き込み操作を個別に処理しながら、API で要求を受け入れて呼び出し元にすばやく戻ることができます。
Azure Event Hubs は、API と worker の間のメッセージ ブローカーとして使用されます。
重要
メッセージ ブローカーは、長期間にわたる永続的なデータ ストアとして使用されることは想定されていません。 Event Hubs サービスは、イベント ハブが、リンクされた Azure Storage アカウントにメッセージのコピーを自動的に書き込むためのキャプチャ機能をサポートしています。 これにより、使用率を抑えるだけでなく、メッセージをバックアップするメカニズムとしても機能します。
書き込み操作の実装の詳細
"評価の投稿やコメントの投稿" などの書き込み操作は非同期的に処理されます。 最初に、API から、アクションの種類やコメント データなど、すべての関連情報を含むメッセージがメッセージ キューに送信され、作成するオブジェクトの Location ヘッダーを HTTP 202 (Accepted) に追加してすぐに返されます。
次に、キュー内のメッセージが、書き込み操作の実際のデータベース通信を処理する BackgroundProcessor インスタンスによって処理されます。 BackgroundProcessor が、キュー上のメッセージ ボリュームに基づいて動的にスケールインおよびスケールアウトします。 プロセッサ インスタンスのスケールアウト制限は、Event Hubs パーティションの最大数 (Basic および Standard レベルは 32、Premium レベルは 100、Dedicated レベルは 1024) で定義されます。

BackgroundProcessor の Azure EventHub プロセッサ ライブラリで、Azure Blob Storage を使用して、パーティションの所有権の管理、異なる worker インスタンス間の負荷分散、チェックポイントを使用した進行状況の追跡が行われます。 BLOB ストレージへのチェックポイントの書き込みは、毎回イベント後に発生するのではありません。メッセージごとに法外な遅延料金が加算されてしまうからです。 代わりに、チェックポイントの書き込みはタイマーループで行われます (期間を構成可能で、現在の設定は 10 秒)。
while (!stoppingToken.IsCancellationRequested)
{
await Task.Delay(TimeSpan.FromSeconds(_sysConfig.BackendCheckpointLoopSeconds), stoppingToken);
if (!stoppingToken.IsCancellationRequested && !checkpointEvents.IsEmpty)
{
string lastPartition = null;
try
{
foreach (var partition in checkpointEvents.Keys)
{
lastPartition = partition;
if (checkpointEvents.TryRemove(partition, out ProcessEventArgs lastProcessEventArgs))
{
if (lastProcessEventArgs.HasEvent)
{
_logger.LogDebug("Scheduled checkpointing for partition {partition}. Offset={offset}", partition, lastProcessEventArgs.Data.Offset);
await lastProcessEventArgs.UpdateCheckpointAsync();
}
}
}
}
catch (Exception e)
{
_logger.LogError(e, "Exception during checkpointing loop for partition={lastPartition}", lastPartition);
}
}
}
プロセッサ アプリケーションでエラーが発生した場合や、メッセージを処理する前に停止した場合は、次のようになります。
- 別のインスタンスが再処理のためにメッセージを取得します。これは、ストレージ内にチェックポイントが適切に設定されなかったためです。
- 障害が発生する前に、先行 worker でドキュメントをデータベースに永続化できた場合は、(同じ ID とパーティション キーが使用されているため) 競合が発生しますが、既に永続化されているため、プロセッサでメッセージを無視しても問題ありません。
- データベースに書き込む前に先行 worker が終了した場合は、新しいインスタンスによってステップが繰り返され、永続化が確定します。
読み取り操作の実装の詳細
読み取り操作は API によって直接処理され、データをすぐにユーザーに返します。

操作が正常に完了した場合、クライアントと通信するバック チャネルはありません。 クライアント アプリケーションから、Location HTTP ヘッダーに指定された項目の更新に対して API を事前にポーリングする必要があります。
スケーラビリティ
個々のワークロード コンポーネントは、それぞれロード パターンが異なるため、独立してスケールアウトする必要があります。 スケーリング要件は、サービスの機能によって異なります。 一部のサービスはエンド ユーザーに直接影響を与え、積極的にスケールアウトして、いつでも肯定的なユーザー エクスペリエンスとパフォーマンスに迅速に対応できることが期待されています。
実装では、サービスは Docker コンテナーとしてパッケージ化され、各スタンプに Helm チャートを使用してデプロイされます。 予想される Kubernetes の要求と制限、事前構成済みの自動スケーリング規則が適用されるように構成されます。 CatalogService と BackgroundProcessor のワークロード コンポーネントは、個別にスケールインおよびスケールアウトでき、どちらのサービスもステートレスです。
エンド ユーザーが直接 CatalogService を操作するため、ワークロードのこの部分はどのような負荷でも応答する必要があります。 Azure リージョン内の 3 つの Availability Zones に分散するインスタンスは、クラスターあたり少なくとも 3 つあります。 AKS 水平ポッド自動スケーラー (HPA) は、必要に応じてポッドを自動的に追加します。Azure Cosmos DB の自動スケールは、コレクションに使用できる RU を動的に増減できます。 CatalogService と Azure Cosmos DB を合わせて、スタンプ内にスケール ユニットを形成します。
HPA は、レプリカの最大数と最小数を構成可能な Helm チャートを使ってデプロイされます。 値は次のように構成されます。
ロード テスト中に、各インスタンスが標準の使用パターンで約 250 要求/秒を処理することが期待されていることが確認されました。
BackgroundProcessor サービスには非常に異なる要件があり、ユーザー エクスペリエンスへの影響が限られているバックグラウンド worker と見なされます。 そのため、BackgroundProcessor の自動スケーリング構成は CatalogService と異なり、2 から 32 個のインスタンスの間でスケーリングできます (この制限は、Event Hubs で使用されているパーティションの数に基づく必要があります。パーティションより多くの worker があってもメリットはありません)。
| コンポーネント | minReplicas |
maxReplicas |
|---|---|---|
| CatalogService | 3 | 20 |
| BackgroundProcessor | 2 | 32 |
それに加えて、ingress-nginx のような依存関係を含むワークロードの各コンポーネントには、変更がクラスターでロールアウトされたときに常に最小数のインスタンスを使用できるようにポッド中断バジェット (PDB) が構成されています。
#
# /src/app/charts/healthservice/templates/pdb.yaml
# Example pod distribution budget configuration.
#
apiVersion: policy/v1
kind: PodDisruptionBudget
metadata:
name: {{ .Chart.Name }}-pdb
spec:
minAvailable: 1
selector:
matchLabels:
app: {{ .Chart.Name }}
注意
各コンポーネントのポッドの実際の最小数と最大数は、ロード テストを通じて決定する必要があり、ワークロードごとに異なってもかまいません。
インストルメンテーション
インストルメンテーションは、ワークロード コンポーネントがシステムに導入できるパフォーマンスのボトル ネックと正常性の問題を評価する際の重要なメカニズムです。 各コンポーネントは、決定を定量化するのに役立つメトリックとトレース ログを通じて十分な情報を出力する必要があります。 アプリケーションのインストルメント化に関する重要な考慮事項を次に示します。
- ログ、メトリック、追加のテレメトリをスタンプのログ システムに送信します。
- 情報を照会できるように、プレーン テキストではなく、構造化ログを使用します。
- イベントの相関関係を実装して、エンドツーエンドのトランザクション ビューを保証します。 RI では、すべての API 応答に、追跡可能性のための HTTP ヘッダーとして操作 ID が含まれています。
- stdout (コンソール) のログだけに頼らないようにしてください。 ただし、このログは、ポッドで障害が発生した場合のトラブルシューティングに即座に使用できます。
このアーキテクチャでは、すべてのアプリケーション監視データに対して Log Analytics ワークスペースによってサポートされる Application Insights を使用して分散トレースを実装します。 Azure Log Analytics は、すべてのワークロードとインフラストラクチャ コンポーネントのログとメトリックに使用されます。 このワークロードで、API から Event Hubs 経由で Azure Cosmos DB に送信される要求の完全なエンドツーエンドのトレースが実装されます。
重要
スタンプ監視リソースは、別の監視リソース グループにデプロイされ、ライフサイクルはスタンプ自体とは異なります。 詳細については、「スタンプ リソースのデータの監視」を参照してください。

アプリケーション監視の実装の詳細
BackgroundProcessor コンポーネントでは、Microsoft.ApplicationInsights.WorkerService NuGet パッケージを使用して、すぐに使用できるインストルメンテーションをアプリケーションから取得します。 また、Serilog がアプリケーション内のすべてのログに使用され、Azure Application Insights がシンク (コンソール シンクの横) として構成されます。 追加のメトリックを追跡する必要がある場合のみ、Application Insights の TelemetryClient インスタンスが直接使用されます。
//
// /src/app/AlwaysOn.BackgroundProcessor/Program.cs
//
public static IHostBuilder CreateHostBuilder(string[] args) =>
Host.CreateDefaultBuilder(args)
.ConfigureServices((hostContext, services) =>
{
Log.Logger = new LoggerConfiguration()
.ReadFrom.Configuration(hostContext.Configuration)
.Enrich.FromLogContext()
.WriteTo.Console(outputTemplate: "[{Timestamp:yyyy-MM-dd HH:mm:ss.fff zzz} {Level:u3}] {Message:lj} {Properties:j}{NewLine}{Exception}")
.WriteTo.ApplicationInsights(hostContext.Configuration[SysConfiguration.ApplicationInsightsConnStringKeyName], TelemetryConverter.Traces)
.CreateLogger();
}
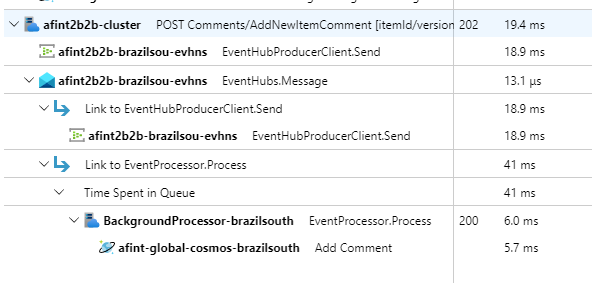
実行可能な要求の追跡可能性を示すために、すべての API 要求 (成功したかどうかにかかわらず) で、相関関係 ID ヘッダーが呼び出し元に返されます。 この識別子を使用して、アプリケーション サポート チームは Application Insights を検索し、完全なトランザクションの詳細ビューを取得できます。
//
// /src/app/AlwaysOn.CatalogService/Startup.cs
//
app.Use(async (context, next) =>
{
context.Response.OnStarting(o =>
{
if (o is HttpContext ctx)
{
// ... code omitted for brevity
context.Response.Headers.Add("X-Server-Location", sysConfig.AzureRegion);
context.Response.Headers.Add("X-Correlation-ID", Activity.Current?.RootId);
context.Response.Headers.Add("X-Requested-Api-Version", ctx.GetRequestedApiVersion()?.ToString());
}
return Task.CompletedTask;
}, context);
await next();
});
注意
Application Insights SDK のアダプティブ サンプリングが既定で有効になっています。 これは、すべての要求が、クラウドに送信され、ID で検索可能であるのではないことを意味します。 ミッション クリティカルなアプリケーション チームはすべての要求を確実にトレースできる必要があるため、このリファレンス実装では、運用環境のアダプティブ サンプリングが無効になっています。
Kubernetes 監視の実装の詳細
AKS のログとメトリックを Log Analytics に送信するために診断設定を使用するほかに、AKS は Container Insights を使用するように構成されています。 Container Insights を有効にすると、AKS クラスター内の各ノードに Kubernetes DaemonSet を介して OMSAgentForLinux がデプロイされます。 OMSAgentForLinux は、Kubernetes クラスター内から追加のログとメトリックを収集することができ、それらを対応する Log Analytics ワークスペースに送信します。 これには、ポッド、デプロイ、サービス、およびクラスターの全体的な正常性に関するより詳細なデータが含まれます。
広範囲に及ぶログはコストに悪影響を与え、メリットはありません。 このため、Container Insights 構成のワークロード ポッドでは、stdout ログ収集と Prometheus スクレイピングが無効になっています。これは、すべてのトレースが Application Insights を通じて既にキャプチャされており、重複レコードが生成されるからです。
#
# /src/config/monitoring/container-azm-ms-agentconfig.yaml
# This is just a snippet showing the relevant part.
#
[log_collection_settings]
[log_collection_settings.stdout]
enabled = false
exclude_namespaces = ["kube-system"]
完全な構成ファイルを参照してください。
正常性の監視
アプリケーションの監視は、通常、システムの問題をすばやく特定し、現在のアプリケーション状態について正常性モデルに通知するために使用されます。 稼働状況の監視は、"正常性エンドポイント" を介して表示され、"正常性プローブ" によって使用され、すぐに実行可能な情報を提供し、通常は、異常なコンポーネントをローテーションから外すようにメイン ロード バランサーに指示します。
このアーキテクチャでは、稼働状況の監視は次のレベルで適用されます。
- AKS で実行されているワークロード ポッド。 これらのポッドには正常性プローブと liveness probe があるため、AKS はそれらのライフサイクルを管理できます。
- 正常性サービスは、クラスター上の専用コンポーネントです。 Azure Front Door は、各スタンプの正常性サービスをプローブし、異常なスタンプを負荷分散から自動的に削除するように構成されています。
正常性サービスの実装の詳細
HealthService は、コンピューティング クラスター上の他のコンポーネント (CatalogService と BackgroundProcessor) と共に実行されているワークロード コンポーネントです。 スタンプの可用性を判断するために Azure Front Door 正常性チェックから呼び出される REST API を提供します。 基本的な liveness probe とは異なり、正常性サービスはより複雑なコンポーネントで、それ自体に加えて依存関係の状態を追加します。
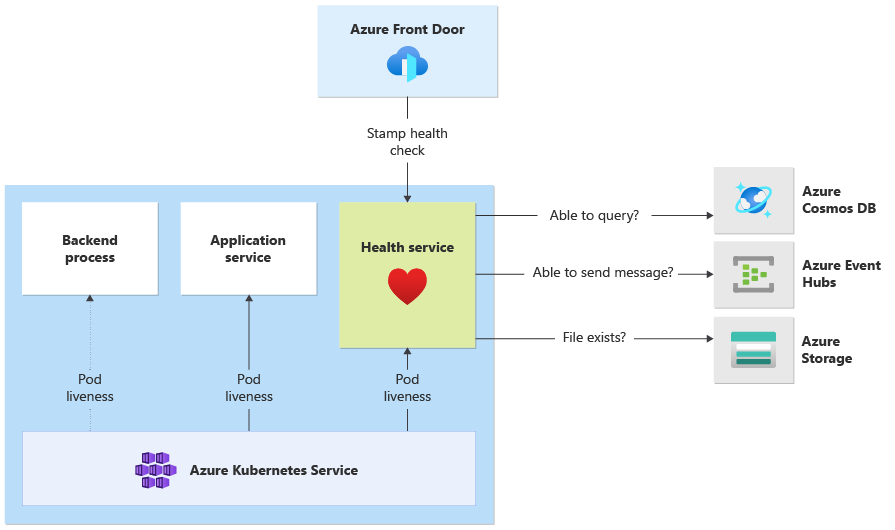
AKS クラスターがダウンしている場合、正常性サービスは応答せず、ワークロードを異常状態にします。 サービスが実行されている場合、ソリューションの重要コンポーネントに対して定期的なチェックを実行します。 すべてのチェックが非同期的かつ並列に行われます。 いずれかの障害が発生した場合、スタンプ全体が使用不可と見なされます。
警告
Azure Front Door 正常性プローブは、要求が複数の PoP の場所から送信されるため、正常性サービスに大きな負荷が発生する可能性があります。 ダウンストリーム コンポーネントのオーバーロードを防ぐには、適切なキャッシュを行う必要があります。
正常性サービスは、各スタンプの Application Insights リソースで明示的に構成された URL ping テストにも使用されます。
HealthService 実装の詳細については、「アプリケーション ヘルス サービス」を参照してください。
フィードバック
以下は間もなく提供いたします。2024 年を通じて、コンテンツのフィードバック メカニズムとして GitHub の issue を段階的に廃止し、新しいフィードバック システムに置き換えます。 詳細については、「https://aka.ms/ContentUserFeedback」を参照してください。
フィードバックの送信と表示