チュートリアル: Azure Cosmos DB エンドポイントを使用して Azure Databricks を構築する
このチュートリアルでは、Azure Cosmos DB に対して有効なサービス エンドポイントを使用して、VNet インジェクションされた Databricks 環境を構築する方法について説明します。
このチュートリアルで学習する内容は次のとおりです。
- 仮想ネットワーク内に Azure Databricks ワークスペースを作成する
- Azure Cosmos DB サービス エンドポイントを作成する
- Azure Cosmos DB アカウントを作成してデータをインポートする
- Azure Databricks クラスターを作成する
- Azure Databricks ノートブックから Azure Cosmos DB にクエリを実行する
前提条件
開始する前に、以下を行います。
Spark コネクタをダウンロードします。
NOAA National Centers for Environmental Information からサンプル データをダウンロードします。 州または地区を選択して [Search](検索) を選択します。 次のページで、既定値をそのまま使用して [Search](検索) を選択します。 次に、ページの左側にある [CSV Download](CSV ダウンロード) を選択すると、結果がダウンロードされます。
Azure Cosmos DB データ移行ツールのプリコンパイル済みバイナリをダウンロードします。
Azure Cosmos DB サービス エンドポイントを作成する
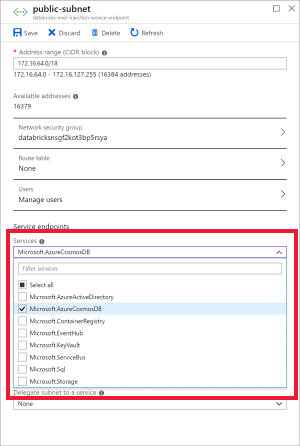
Azure Databricks ワークスペースを仮想ネットワークにデプロイしたら、Azure portal でその仮想ネットワークに移動します。 Databricks のデプロイを通じて作成されたパブリックおよびプライベート サブネットに注目してください。
public-subnet を選択し、Azure Cosmos DB サービス エンドポイントを作成します。 その後、 [保存] を選択します。
Azure Cosmos DB アカウントを作成する
Azure Portal を開きます。 画面の左上で、[リソースの作成]> > [データベース]> > [Azure Cosmos DB] の順に選択します。
[基本] タブの [インスタンスの詳細] に次の設定を入力します。
Setting 値 サブスクリプション 該当するサブスクリプション リソース グループ <該当するリソース グループ> アカウント名 db-vnet-service-endpoint API コア (SQL) Location 米国西部 geo 冗長性 Disable マルチリージョン書き込み 有効化 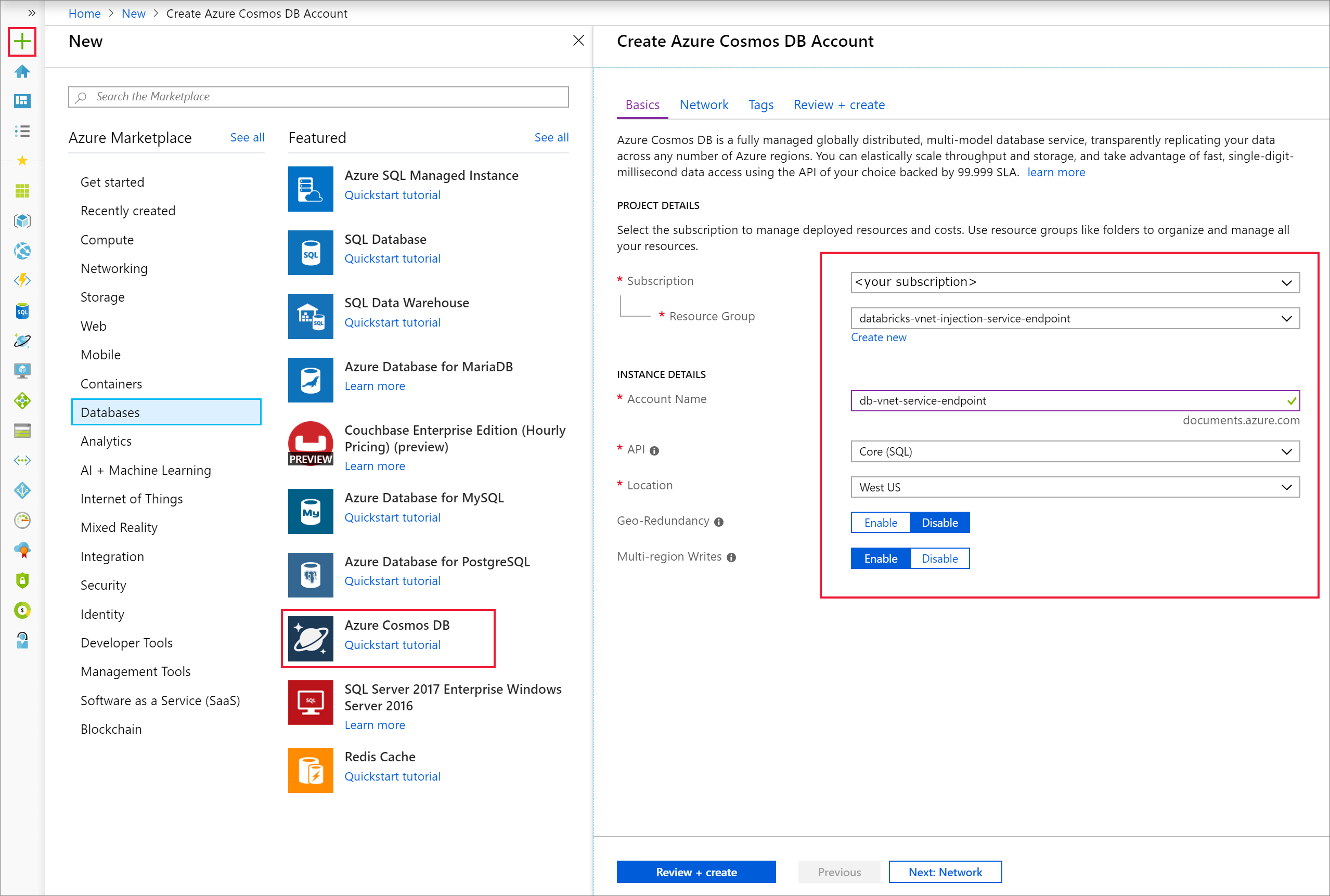
[ネットワーク] タブを選択し、仮想ネットワークを構成します。
a. 前提条件として作成した仮想ネットワークを選択し、public-subnet を選択します。 private-subnet には "Microsoft AzureCosmosDB のエンドポイントが存在しません" というメッセージが表示されていることに注意してください。 これは、public-subnet のみで Azure Cosmos DB サービス エンドポイントを有効にしたためです。
b. [Azure portal からのアクセスを許可する] が有効になっていることを確認します。 この設定により、Azure portal から Azure Cosmos DB アカウントにアクセスできるようになります。 このオプションが [拒否] に設定されている場合は、ご利用のアカウントにアクセスしようとしたときにエラーが発生します。
注意
このチュートリアルでは必要ありませんが、ローカル コンピューターから Azure Cosmos DB アカウントにアクセスできるようにしたい場合は、[自分の IP からのアクセスを許可する] を有効にすることもできます。 たとえば、Azure Cosmos DB SDK を使用してご利用のアカウントに接続する場合は、この設定を有効にする必要があります。 これが無効になっていると、"アクセスが拒否されました" エラーが発生します。
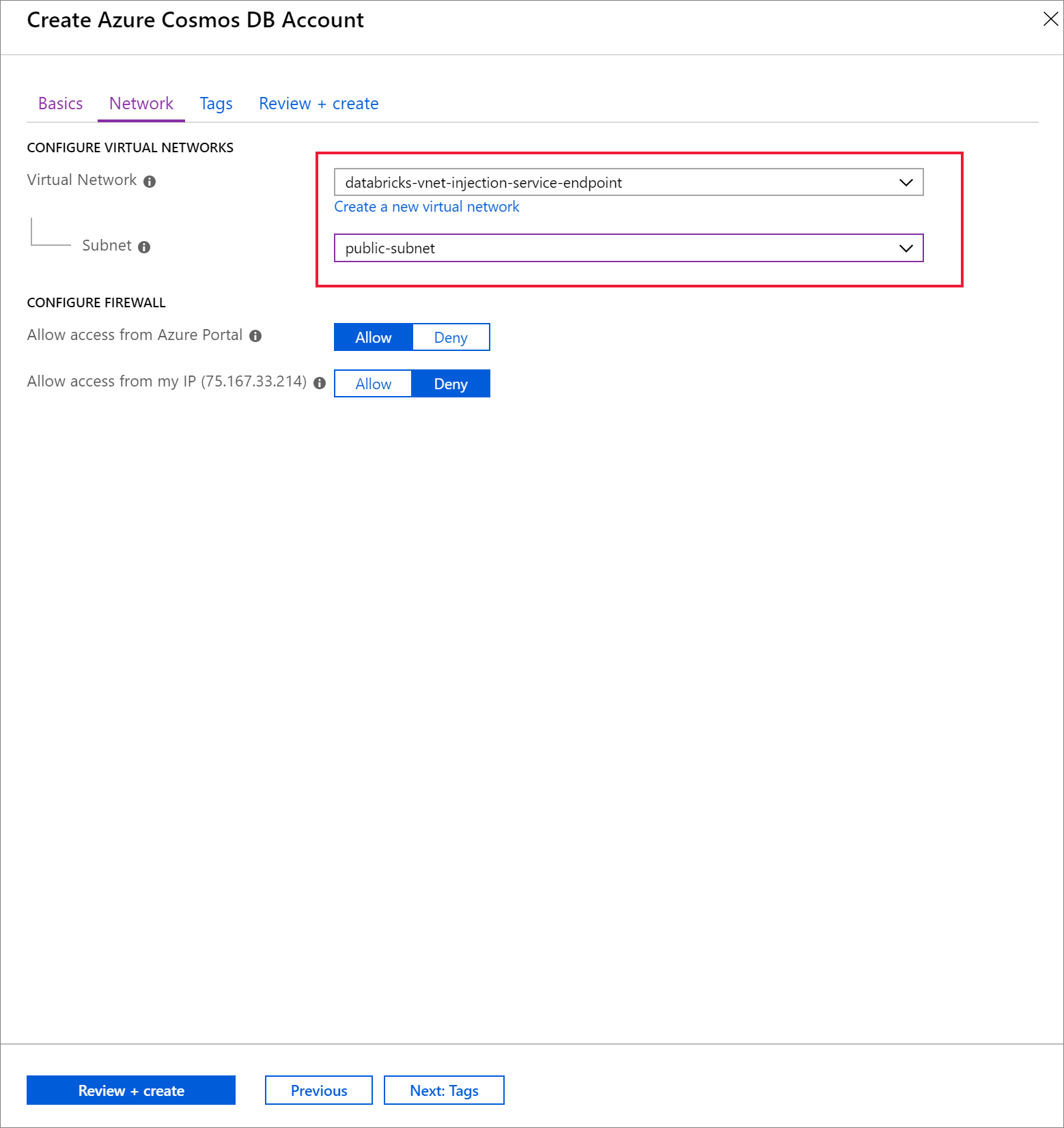
[確認と作成] を選択した後、[作成] を選択して仮想ネットワーク内に Azure Cosmos DB アカウントを作成します。
Azure Cosmos DB アカウントが作成されたら、[設定] の [キー] に移動します。 プライマリ接続文字列をコピーし、後で使用できるようテキスト エディターに保存します。
![Cosmos DB アカウントの [キー] ページ](media/service-endpoint-cosmosdb/cosmos-keys.png)
[データ エクスプローラー] と [新しいコンテナー] を選択して、ご利用の Azure Cosmos DB アカウントに新しいデータベースとコンテナーを追加します。
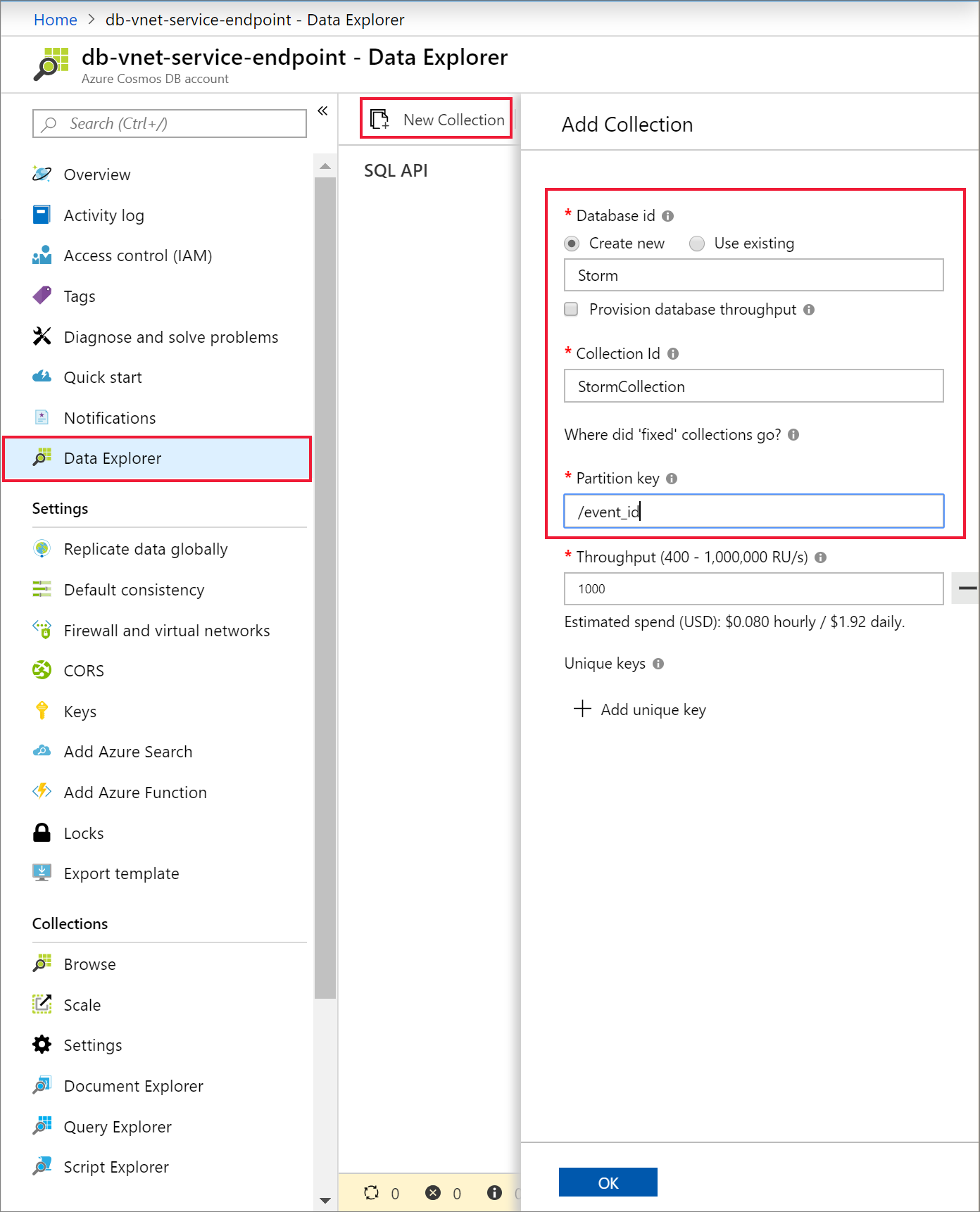
Azure Cosmos DB にデータをアップロードする
Azure Cosmos DB のデータ移行ツールのグラフィカル インターフェイス バージョン (Dtui.exe) を開きます。
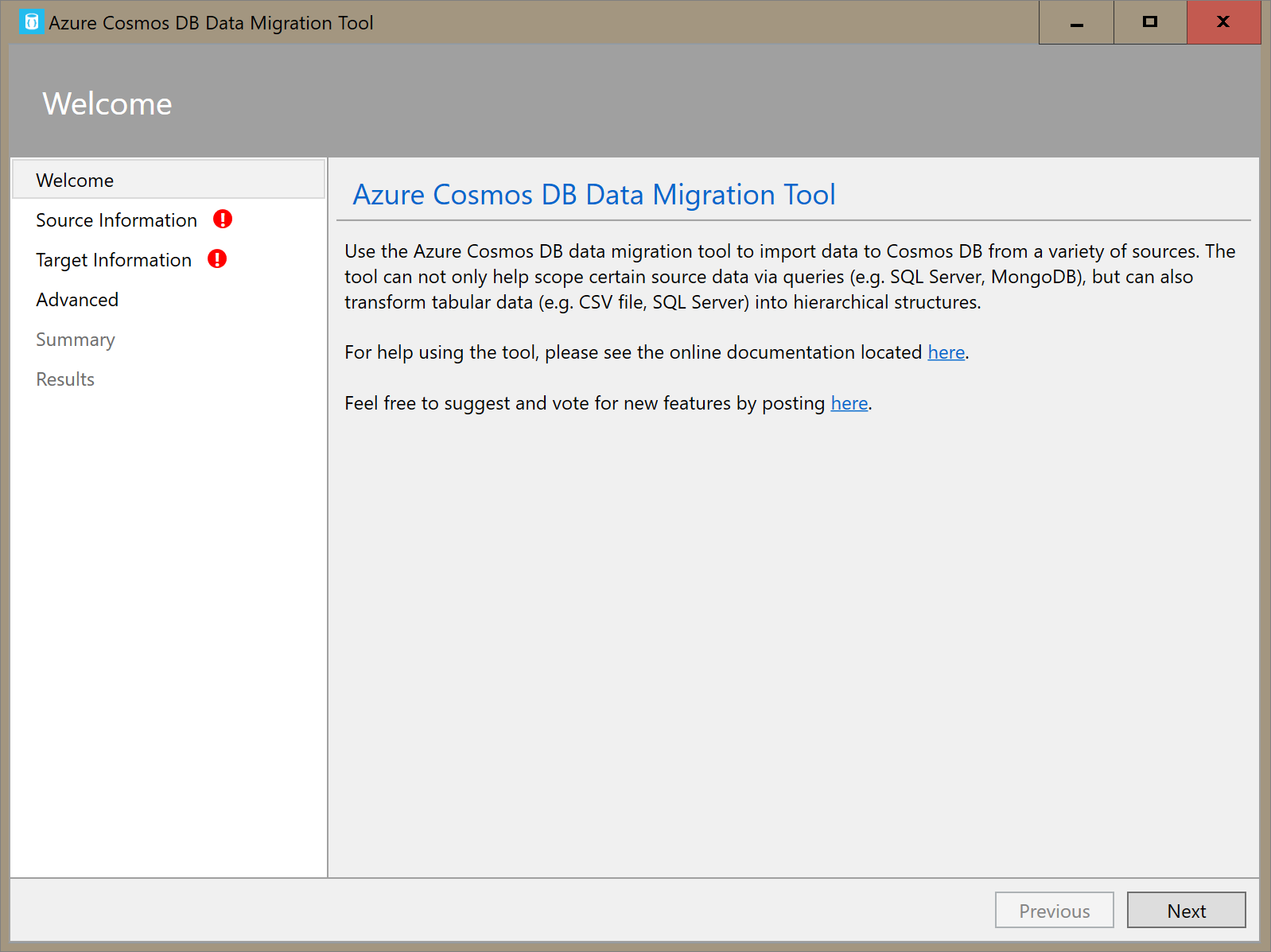
[ソース情報] タブで、 [インポート元] ドロップダウンから [CSV ファイル] を選択します。 次に、 [ファイルの追加] を選択し、前提条件としてダウンロードした暴風雨データの CSV を追加します。
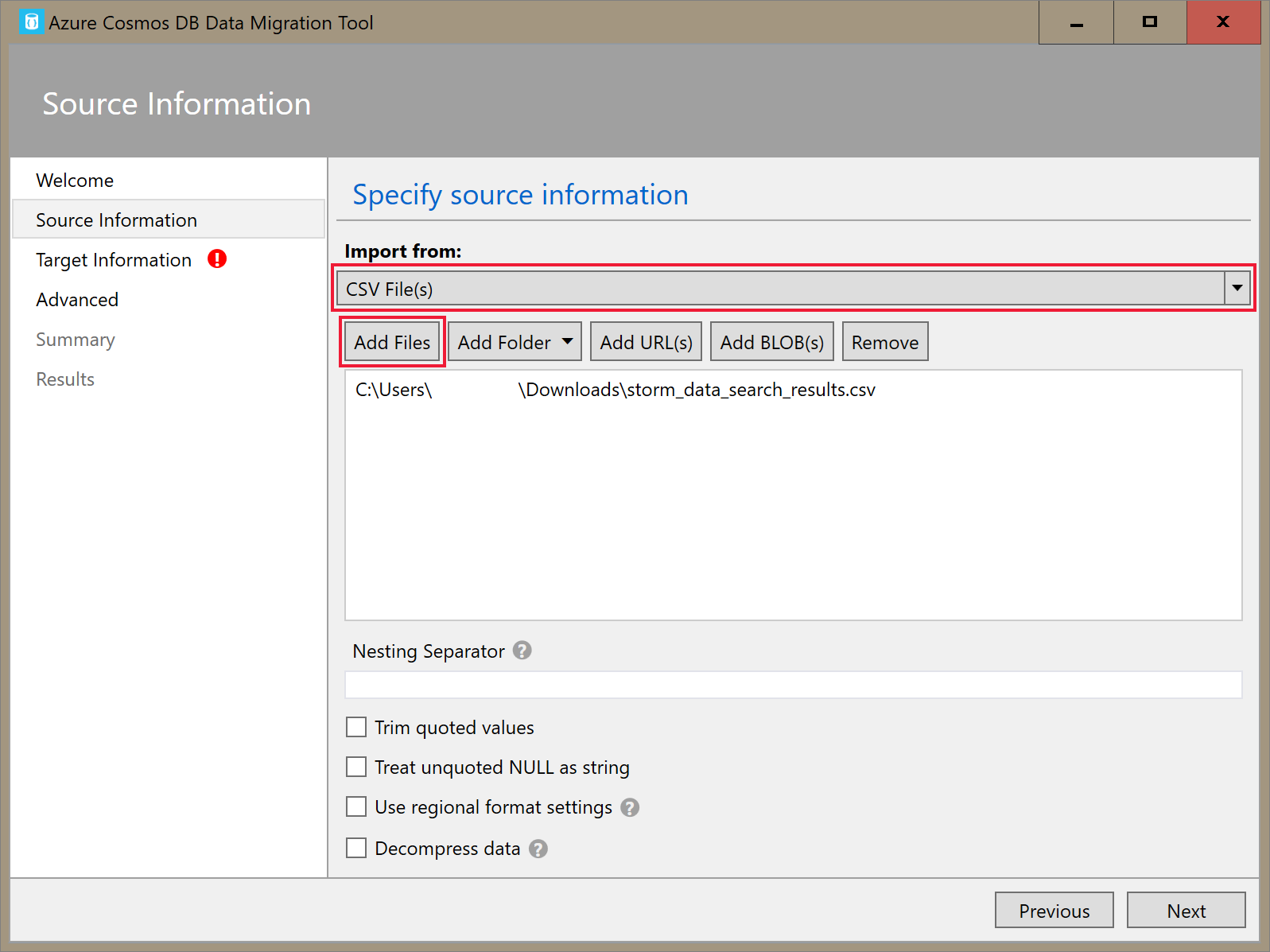
[ターゲット情報] タブで、実際の接続文字列を入力します。 接続文字列の形式は
AccountEndpoint=<URL>;AccountKey=<key>;Database=<database>です。 前のセクションで保存したプライマリ接続文字列には AccountEndpoint と AccountKey が含まれています。 接続文字列の末尾にDatabase=<your database name>を追加して、 [確認] を選択します。 次に、コンテナー名とパーティション キーを追加します。
概要ページが表示されるまで [次へ] を選択します。 その後、 [インポート] を選択します。
クラスターを作成してライブラリを追加する
Azure portal で Azure Databricks サービスに移動し、 [ワークスペースの起動] を選択します。
新しいクラスターを作成します。 クラスター名を選択し、それ以外は既定の設定のままにしてください。
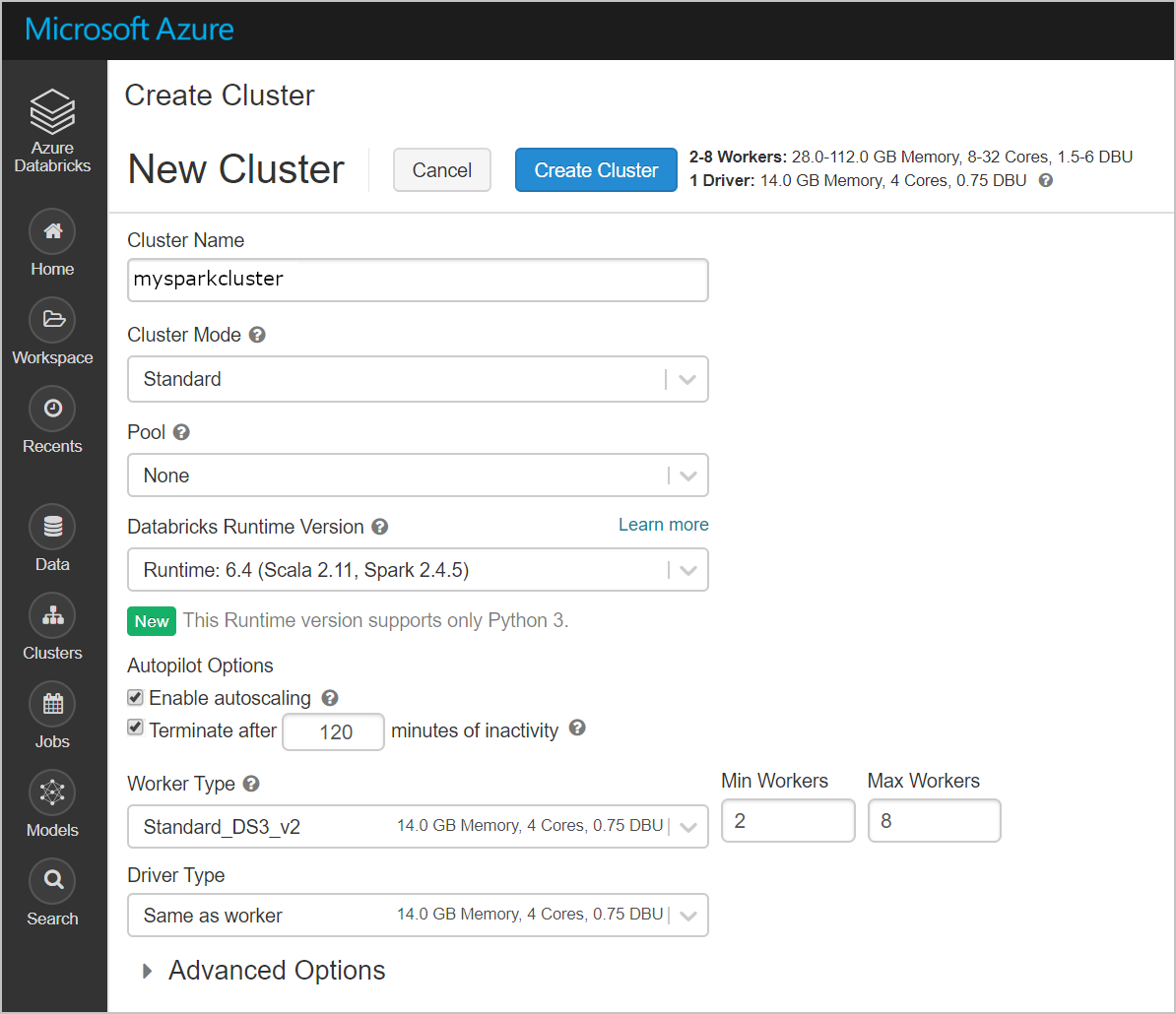
クラスターの作成後、そのクラスターのページに移動し、 [ライブラリ] タブを選択します。 [新規インストール] を選択し、Spark コネクタの jar ファイルをアップロードしてライブラリをインストールします。
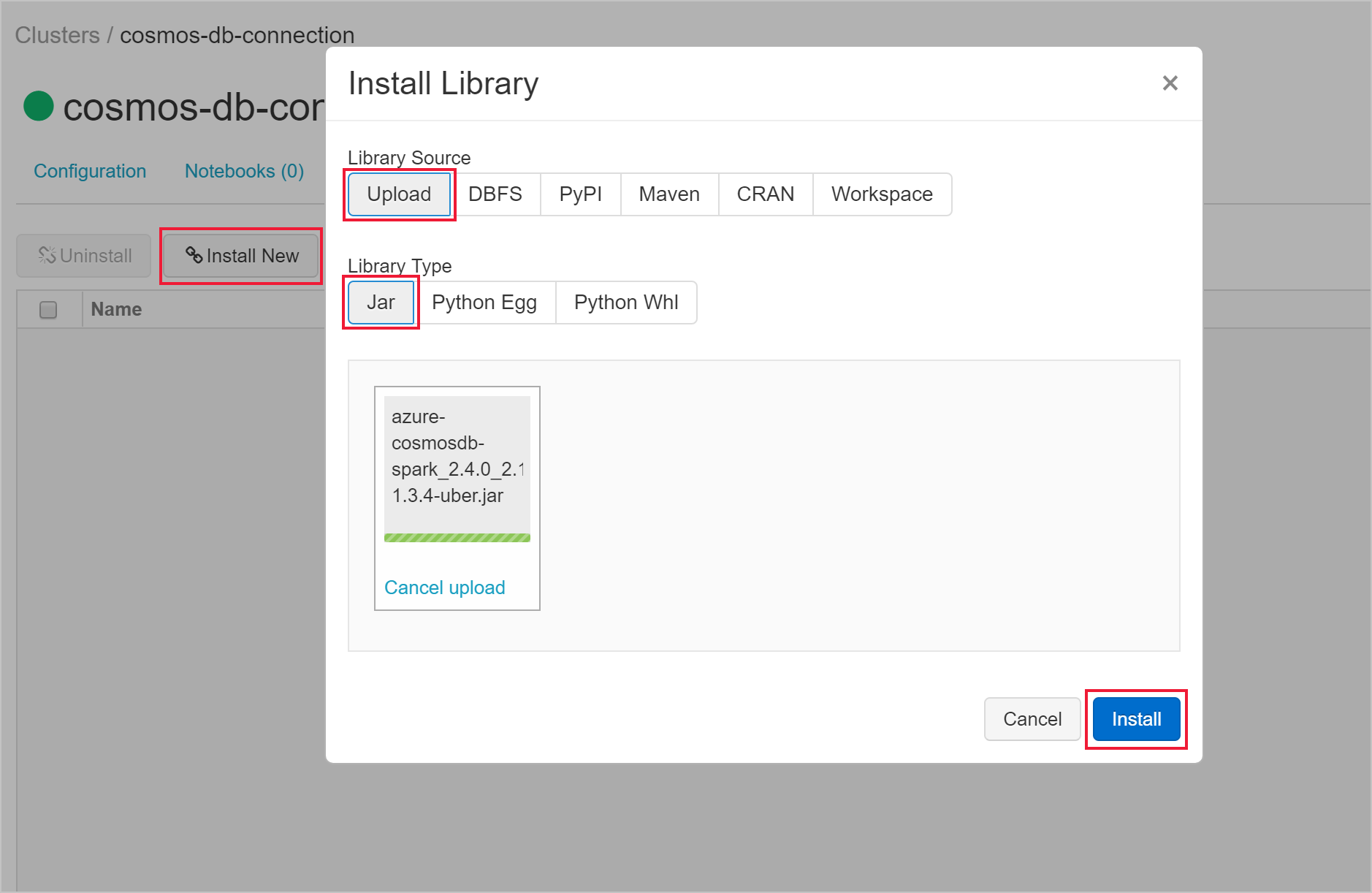
ライブラリがインストールされたことは、 [ライブラリ] タブで確認できます。
![Databricks クラスターの [ライブラリ] タブ](media/service-endpoint-cosmosdb/installed-library.png)
Databricks ノートブックから Azure Cosmos DB にクエリを実行する
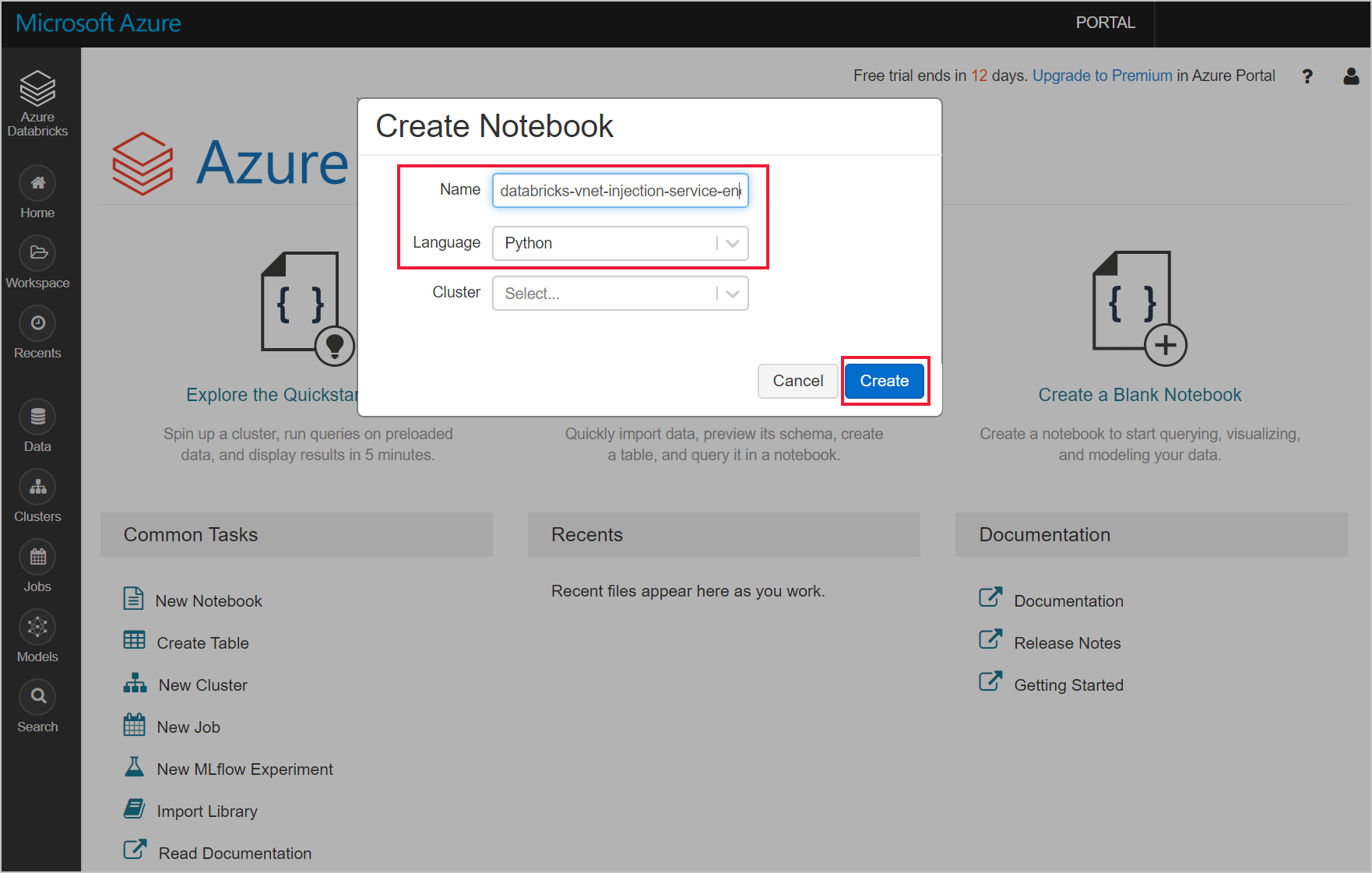
Azure Databricks ワークスペースに移動して新しい Python ノートブックを作成します。
次の Python コードを実行して Azure Cosmos DB の接続構成を設定します。 Endpoint、Masterkey、Database、Container を適宜変更します。
connectionConfig = { "Endpoint" : "https://<your Azure Cosmos DB account name.documents.azure.com:443/", "Masterkey" : "<your Azure Cosmos DB primary key>", "Database" : "<your database name>", "preferredRegions" : "West US 2", "Container": "<your container name>", "schema_samplesize" : "1000", "query_pagesize" : "200000", "query_custom" : "SELECT * FROM c" }次の Python コードを使用してデータを読み込み、一時ビューを作成します。
users = spark.read.format("com.microsoft.azure.cosmosdb.spark").options(**connectionConfig).load() users.createOrReplaceTempView("storm")次のマジック コマンドを使用して、データが返される SQL ステートメントを実行します。
%sql select * from stormVNet インジェクションされた Databricks ワークスペースを、サービス エンドポイントに対応した Azure Cosmos DB リソースに正常に接続することができました。 Azure Cosmos DB への接続方法の詳細については、Azure Cosmos DB Connector for Apache Spark に関するページを参照してください。
リソースのクリーンアップ
リソース グループ、Azure Databricks ワークスペース、および関連するすべてのリソースは、不要になったら削除します。 ジョブを削除すると、不必要な課金を回避できます。 Azure Databricks ワークスペースを後で使用する予定がある場合は、クラスターを停止し、後で再起動することができます。 この Azure Databricks ワークスペースの使用を続けない場合は、以下の手順に従って、このチュートリアルで作成したすべてのリソースを削除してください。
Azure Portal の左側のメニューで、 [リソース グループ] をクリックしてから、作成したリソース グループの名前をクリックします。
リソース グループのページで [削除] を選択し、削除するリソースの名前をテキスト ボックスに入力してから [削除] を再度選択します。
次の手順
このチュートリアルでは、仮想ネットワークに Azure Databricks ワークスペースをデプロイし、Azure Cosmos DB Spark コネクタを使用して Databricks から Azure Cosmos DB データにクエリを実行しました。 仮想ネットワークでの Azure Databricks の操作の詳細については、Azure Databricks での SQL Server の使用に関するチュートリアルに進んでください。