Web SDK でのポイント データのクラスタリング
多数のデータ ポイントがマップ上にある場合、いくつかは互いに重なり合うことがあります。 重なり合うと、マップが読み取れなくなり、使用が困難になる可能性があります。 ポイント データのクラスタリングは、互いに近いポイント データを結合し、単一のクラスター化されたデータ ポイントとしてマップ上に表現するプロセスです。 ユーザーがマップにズーム インすると、クラスターは個々のデータ ポイントに分解します。 大量のデータ ポイントを操作する場合、クラスタリング プロセスによってユーザー エクスペリエンスを向上させることができます。
データ ソースでのクラスタリングの有効化
cluster オプションを true に設定することにより、DataSource クラスでクラスタリングを簡単に有効化できます。 近くのポイントを選択し、それらをクラスターに結合するように、clusterRadius を設定します。 clusterRadius の値はピクセル単位です。 clusterMaxZoom を使用して、クラスタリング ロジックを無効にするズーム レベルを指定します。 次に示すのは、データ ソースでクラスタリングを有効化する方法の例です。
//Create a data source and enable clustering.
var datasource = new atlas.source.DataSource(null, {
//Tell the data source to cluster point data.
cluster: true,
//The radius in pixels to cluster points together.
clusterRadius: 45,
//The maximum zoom level in which clustering occurs.
//If you zoom in more than this, all points are rendered as symbols.
clusterMaxZoom: 15
});
ヒント
2 つのデータ ポイントがきわめて近い場合、ユーザーがどれだけ近くまでズーム インしてもクラスターが分解しない可能性があります。 これに対処するには、clusterMaxZoom オプションを設定し、クラスタリング ロジックを無効化して単純にすべてを表示することができます。
DataSource クラスには、クラスタリングに関連する以下のメソッドも用意されています。
| Method | の戻り値の型 : | 説明 |
|---|---|---|
| getClusterChildren(clusterId: number) | Promise<Array<Feature<Geometry, any> | Shape>> | 次のズーム レベルで指定されたクラスターの子を取得します。 これらの子はシェイプとサブクラスターの組み合わせの場合があります。 サブクラスターは、ClusteredProperties と一致するプロパティを備えた機能です。 |
| getClusterExpansionZoom(clusterId: number) | Promise<number> | クラスターが拡大し始めるか、または分解するズーム レベルを計算します。 |
| getClusterLeaves(clusterId: number, limit: number, offset: number) | Promise<Array<Feature<Geometry, any> | Shape>> | クラスター内のポイントを取得します。 既定では、最初の 10 ポイントが返されます。 ポイントをページングするには、limit を使用して返すポイントの数を指定し、offset を使用してポイントのインデックスをステップ実行します。 すべてのポイントを返すには、limit を Infinity に設定し、offset は設定しないでください。 |
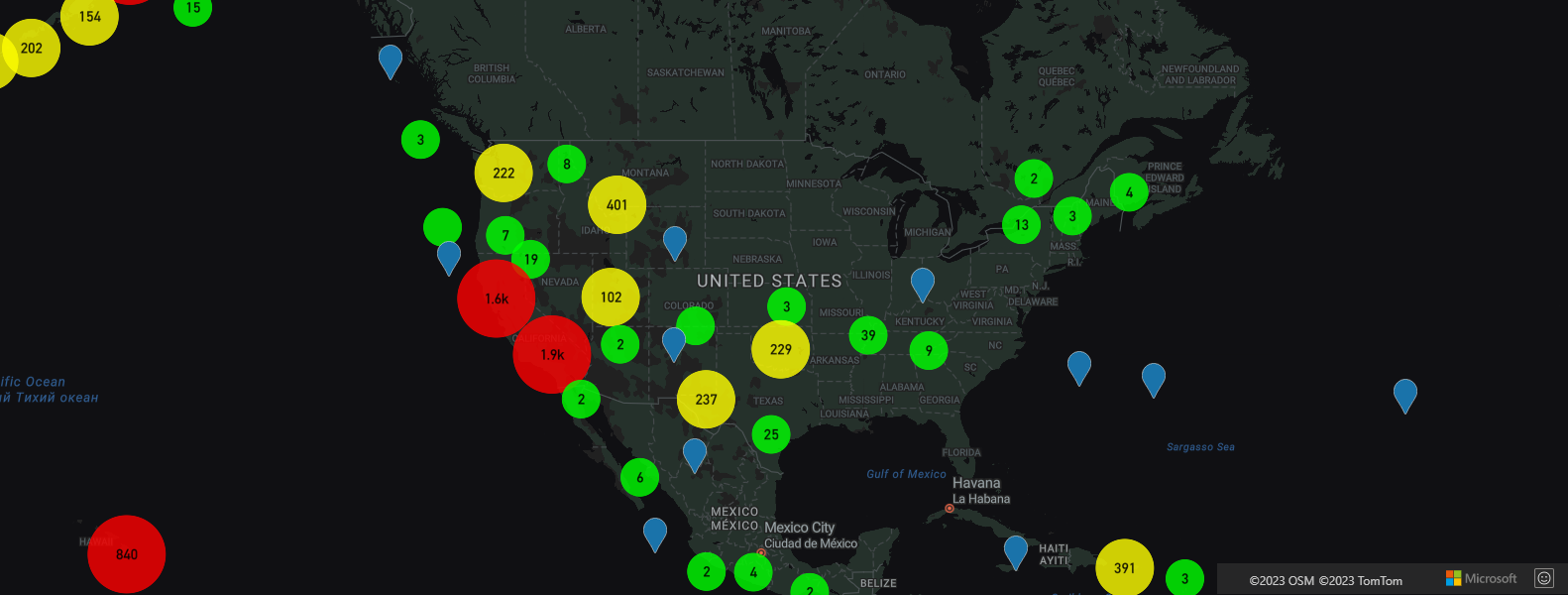
バブル レイヤーを使用してクラスターを表示する
バブルレイヤーは、クラスター化されたポイントをレンダリングするための優れた方法です。 クラスター内のポイントの数に基づき、式を使用して半径を拡大し、色を変更します。 バブル レイヤーを使用してクラスターを表示する場合、クラスター化されていないデータ ポイントをレンダリングするための別のレイヤーを使用することをお勧めします。
バブルの上にクラスターのサイズを表示するには、テキスト付きのシンボル レイヤーを使用し、アイコンを使用しないようにします。
バブル レイヤーを使用してクラスターの表示を実装する方法の完全な作業サンプルについては、「Azure Maps サンプル」の「バブル レイヤーのポイント クラスター」を参照してください。 このサンプルのソース コードについては、Point Clusters in Bubble Layer のソース コードを参照してください。
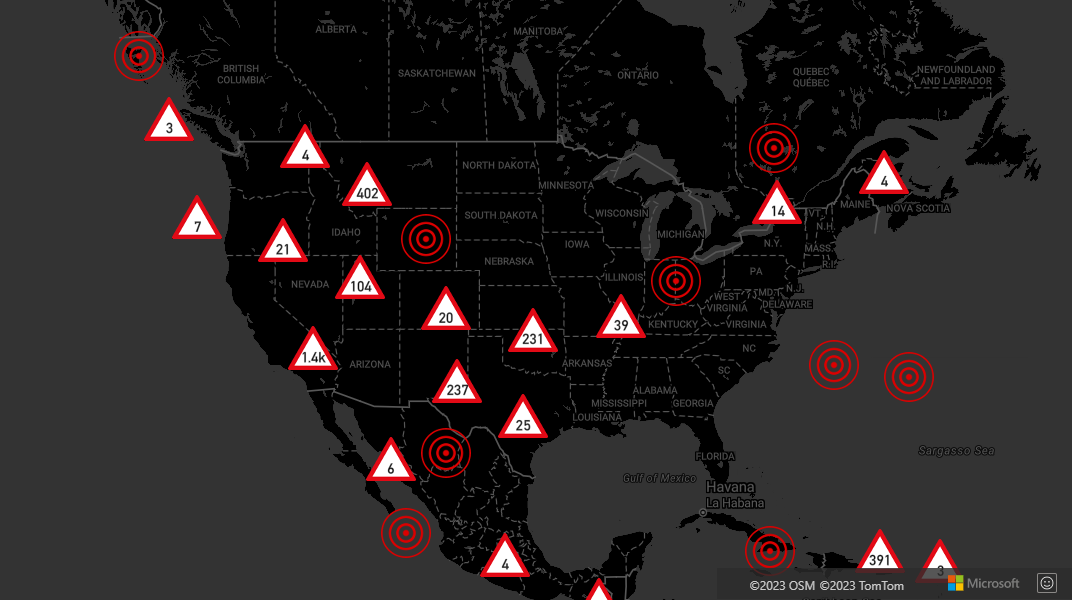
シンボル レイヤーを使用してクラスターを表示する
データ ポイントを視覚化すると、シンボル レイヤーは互いに重なり合うシンボルを自動的に非表示にして、ユーザー インターフェイスをすっきりさせることができます。 マップにデータ ポイントの密度を表示する場合、この既定の動作は望ましくないことがあります。 ただし、これらの設定は変更できます。 すべてのシンボルを表示するには、シンボル レイヤー iconOptions プロパティの allowOverlap オプションを true に設定します。
クラスタリングを使用して、ユーザー インターフェイスをすっきりとした状態に維持しながらデータ ポイントの密度を表示します。 次のサンプルは、カスタム シンボルを追加し、シンボル レイヤーを使用して、クラスターと個々のデータ ポイントを表示する方法を示しています。
シンボル レイヤーを使用してクラスターの表示を実装する方法の完全な作業サンプルについては、「Azure Maps サンプル」の「シンボル レイヤーを使用してクラスターを表示する」を参照してください。 このサンプルのソース コードについては、Display clusters with a Symbol Layer のソース コードを参照してください。
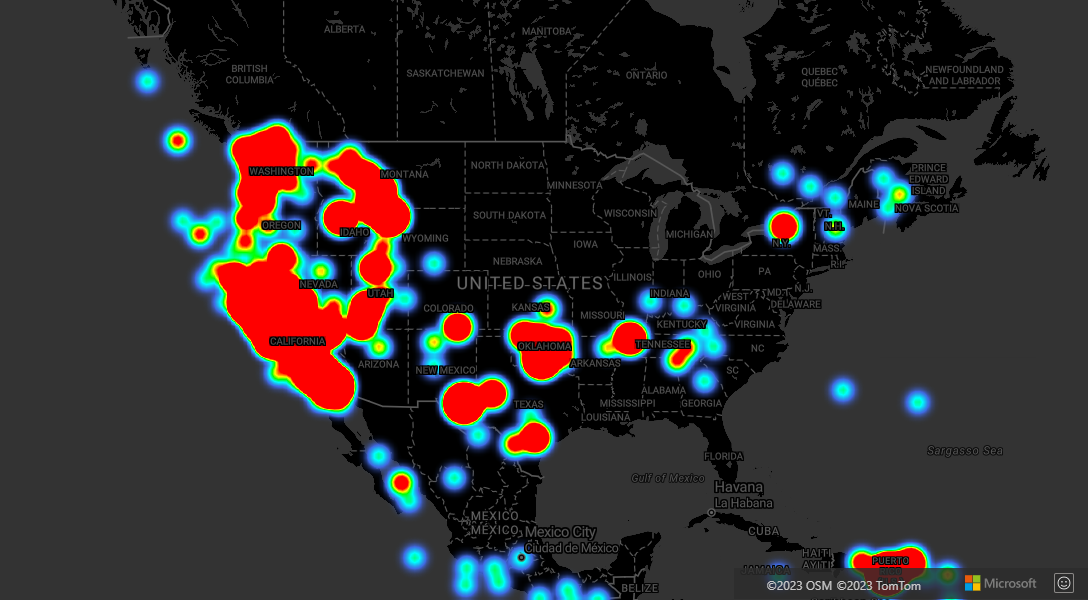
クラスタリングとヒート マップ レイヤー
ヒート マップは、データの密度をマップ上に表示するための優れた方法です。 この視覚化方法では、多数のデータ ポイントを自然に処理できます。 データ ポイントがクラスター化されており、クラスター サイズがヒート マップの重みとして使用されている場合、ヒート マップはさらに多くのデータを処理できます。 このオプションを実現するには、ヒート マップ レイヤーの weight オプションを ['get', 'point_count'] に設定します。 クラスターの半径が小さい場合、クラスター化しないデータ ポイントを使用したヒート マップと比べてヒート マップの見た目はほぼ同じですが、パフォーマンスは向上します。 ただし、クラスターの半径が小さいほどヒート マップは正確になりますが、パフォーマンスの利点は少なくなります。
データ ソースについてクラスタリングを使用するヒート マップを作成する方法を示す完全な作業サンプルについては、「Azure Maps サンプル」の「クラスター加重ヒート マップ」を参照してください。 このサンプルのソース コードについては、Cluster weighted Heat Map のソース コードを参照してください。
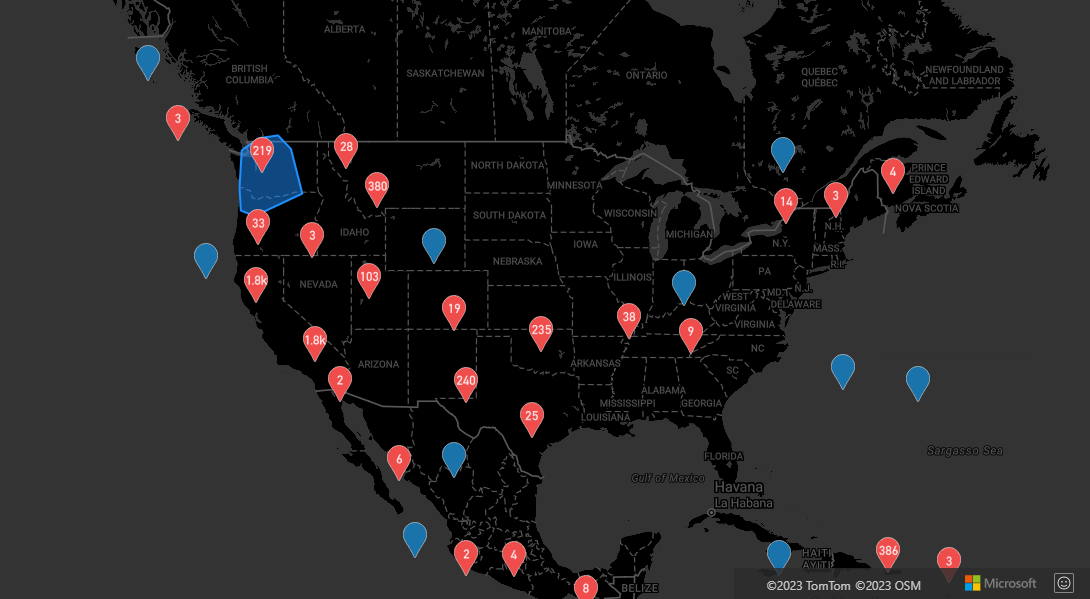
クラスター化されたデータ ポイントでのマウス イベント
クラスター化されたデータ ポイントを含むレイヤーでマウス イベントが発生すると、クラスター化されたデータ ポイントは GeoJSON ポイント フィーチャー オブジェクトとしてイベントに返されます。 このポイント フィーチャーには次のプロパティがあります。
| プロパティ名 | Type | 説明 |
|---|---|---|
cluster |
boolean | フィーチャーがクラスターを表すかどうかを示します。 |
cluster_id |
string | DataSource の getClusterExpansionZoom、getClusterChildren、および getClusterLeaves メソッドで使用できるクラスターの一意な ID。 |
point_count |
number | クラスターに含まれているポイントの数。 |
point_count_abbreviated |
string | point_count の値が長い場合にその値を省略形にした文字列。 (たとえば、4,000 が 4K になります) |
バブル レイヤーでのポイント クラスターの例では、クラスター ポイントをレンダリングし、クリック イベントを追加したバブル レイヤーを使用します。 クリック イベントがトリガーされると、コードによってマップが計算され、クラスターが分割されている次のズーム レベルにズームされます。 この機能は、DataSource クラスの getClusterExpansionZoom メソッドと、クリックされたクラスター化されたデータ ポイントの cluster_id プロパティを使用して実装されます。
次のコード スニペットでは、クラスター化されたデータ ポイントにクリック イベント機能を追加する、バブル レイヤーでのポイント クラスターの例のコードを示しています。
//Add a click event to the layer so we can zoom in when a user clicks a cluster.
map.events.add('click', clusterBubbleLayer, clusterClicked);
//Add mouse events to change the mouse cursor when hovering over a cluster.
map.events.add('mouseenter', clusterBubbleLayer, function () {
map.getCanvasContainer().style.cursor = 'pointer';
});
map.events.add('mouseleave', clusterBubbleLayer, function () {
map.getCanvasContainer().style.cursor = 'grab';
});
function clusterClicked(e) {
if (e && e.shapes && e.shapes.length > 0 && e.shapes[0].properties.cluster) {
//Get the clustered point from the event.
var cluster = e.shapes[0];
//Get the cluster expansion zoom level. This is the zoom level at which the cluster starts to break apart.
datasource.getClusterExpansionZoom(cluster.properties.cluster_id).then(function (zoom) {
//Update the map camera to be centered over the cluster.
map.setCamera({
center: cluster.geometry.coordinates,
zoom: zoom,
type: 'ease',
duration: 200
});
});
}
}
クラスター領域を表示する
クラスターが表すポイント データは領域に分散しています。 このサンプルでは、マウスがクラスター上に置かれたとき、主に 2 つの動作が行われます。 まず、クラスターに含まれている個々のデータ ポイントを使用して、凸包を計算します。 次に、領域を表示するために凸包がマップに表示されます。 凸包は輪ゴムのように一連のポイントを囲む多角形であり、atlas.math.getConvexHull メソッドを使用して計算できます。 クラスターに含まれるすべてのポイントは、getClusterLeaves メソッドを使用してデータソースから取得できます。
これを行う方法を示す完全な作業サンプルについては、「Azure Maps サンプル」の「凸包を使用してクラスター領域を表示する」を参照してください。 このサンプルのソース コードについては、Display cluster area with Convex Hull のソース コードを参照してください。
クラスター内のデータの集計
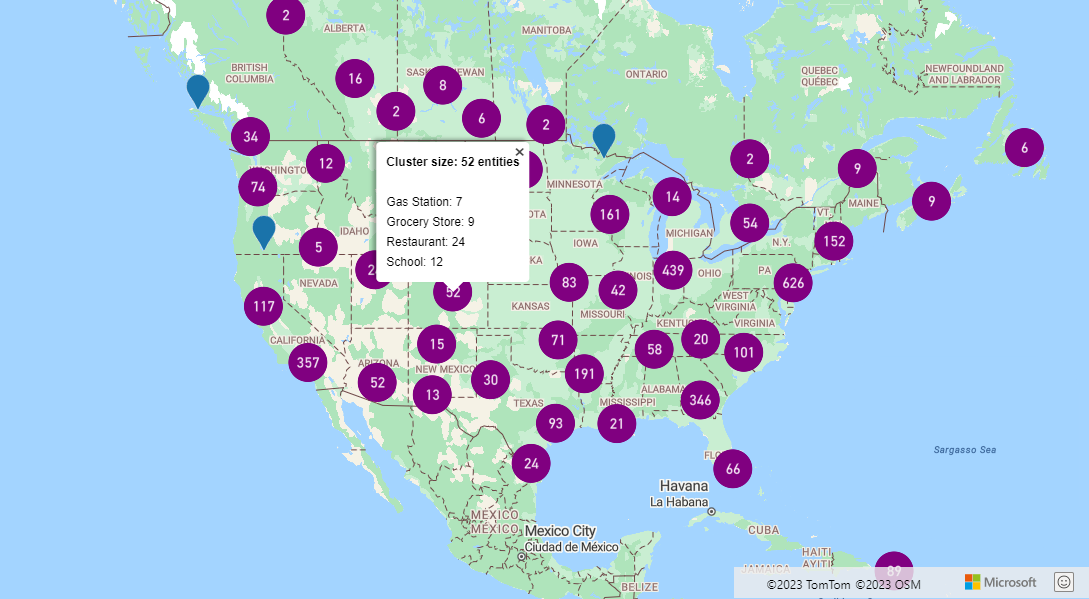
クラスターは多くの場合、クラスター内のポイントの数を示すシンボルを使用して表現されます。 ただし、より多くのメトリックを使用して、クラスターのスタイルをカスタマイズすることが望ましい場合もあります。 クラスター集計では、集計式の計算を使用してカスタム プロパティを作成および設定できます。 クラスター集計は、DataSource の clusterProperties オプションで定義できます。
クラスター集計の例では集計式が使用されています。 このコードでは、クラスター内の各データ ポイントのエンティティ型プロパティに基づいて、カウントを計算します。 ユーザーがクラスターを選択すると、クラスターに関する追加情報を示すポップアップが表示されます。 このサンプルのソース コードについては、Cluster aggregates のソース コードを参照してください。
次のステップ
この記事で使われているクラスとメソッドの詳細については、次を参照してください。
ご利用のアプリに機能を追加するには、次のコード例を参照してください。