フェールオーバー グループの概要とベスト プラクティス (Azure SQL データベース)
適用対象:![]() Azure SQL Database
Azure SQL Database
フェールオーバー グループ機能を使うと、論理サーバー上の一部または全てのデータベースの、別のリージョンの論理サーバーへのレプリケーションやフェールオーバーを管理できます。 この記事では、フェールオーバー グループ機能の概要と、Azure SQL データベースで使用するためのベスト プラクティスと推奨事項について説明します。
この機能を使い始めるには、「フェールオーバー グループの構成」を確認してください。
Note
この記事では、Azure SQL データベースのフェールオーバー グループについて説明します。 Azure SQL Managed Instance については、「Azure SQL Managed Instance でフェールオーバー グループを構成する」を参照してください。
Azure SQL Database のディザスター リカバリーの詳細については、次のビデオをご覧ください。
概要
フェールオーバー グループ機能を使うと、別の Azure リージョンへのデータベースのレプリケーションやフェールオーバーを管理できます。 論理サーバ内のユーザデータベースのすべて、またはサブセットを別の論理サーバにレプリケー トするように選択できます。 これは、アクティブ geo レプリケーション機能に基づく宣言型の抽象化であり、geo レプリケーション対応データベースの大規模なデプロイと管理を簡素化するように設計されています。
geo フェールオーバー RPO と RTO については、「ビジネス継続性の 概要」を参照してください。
エンドポイント リダイレクト
フェールオーバー グループには、geo フェールオーバー中にそのまま残る読み取り/書き込みおよび読み取り専用リスナー エンドポイントが用意されています。 接続は現在のプライマリに自動的にルーティングされるので、geo フェールオーバー後にアプリケーションの接続文字列を変更する必要はありません。 geo フェールオーバーでは、グループ内のすべてのセカンダリ データベースがプライマリ ロールに切り替まれます。 geo フェールオーバーが完了すると、DNS レコードが自動的に更新され、エンドポイントが新しいリージョンにリダイレクトされます。
読み取り専用ワークロードをオフロードする
プライマリ データベースへのトラフィックを減らすために、フェールオーバー グループ内のセカンダリ データベースを使用して、読み取り専用ワークロードをオフロードすることもできます。 読み取り専用リスナーを使用して、読み取り専用のトラフィックを読み取り可能なセカンダリ データベースに送信します。
アプリケーションの回復
完全なビジネス継続性を実現するには、リージョン データベースの冗長性を追加する方法は、ソリューションの一部に限定されます。 致命的な障害の後にアプリケーション (サービス) をエンド ツー エンドで復旧するには、そのサービスと依存しているサービスを構成するすべてのコンポーネントを復旧する必要があります。 このようなコンポーネントの例には、クライアント ソフトウェア (カスタム JavaScript が設定されたブラウザーなど)、Web フロント エンド、ストレージ、DNS などがあります。 すべてのコンポーネントが同じ障害に耐性を持ち、アプリの復元時間目標(RTO)内で利用可能になることが重要です。 そのため、依存するサービスをすべて特定し、これらのサービスが提供する保証と機能について把握しておく必要があります。 そのうえで、依存するサービスのフェールオーバー中もサービスが確実に機能するように対策を講じる必要があります。
フェールオーバー ポリシー
フェールオーバー グループでは、次の 2 つのフェールオーバー ポリシーがサポートされています。
- カスタマー マネージド (推奨) - お客様は、フェールオーバー グループ内の 1 つ以上のデータベースに影響を与える予期しない停止に気付いたときに、グループのフェールオーバーを実行できます。 PowerShell、Azure CLI、Rest API などのコマンド ライン ツールを使用する場合、カスタマー マネージドのフェールオーバー ポリシー値は
manual. - マイクロソフトマネージド - プライマリ リージョンに影響を与える広範囲にわたる停止が発生した場合、マイクロソフトは、マイクロソフトが管理するように構成されたフェールオーバー ポリシーを持つ影響を受けるすべてのフェールオーバー グループのフェールオーバーを開始します。 マイクロソフトマネージド フェールオーバーは、個々のフェールオーバー グループまたはリージョン内のフェールオーバー グループのサブセットに対して開始されません。 PowerShell、Azure CLI、Rest API などのコマンド ライン ツールを使用する場合、マイクロソフトが管理するフェールオーバー ポリシーの値は
automatic.
次の表に示すように、各フェールオーバー ポリシーには、一意のユース ケースセットと、フェールオーバー スコープとデータ損失に対する対応する想定があります。
| フェールオーバー ポリシー | フェールオーバー スコープ | ユース ケース | データ損失の可能性 |
|---|---|---|---|
| お客様による管理 (おすすめ) |
フェールオーバー グループ | フェールオーバー グループ内の 1 つ以上のデータベースが停止の影響を受け、使用できなくなります。 フェールオーバーを選択できます。 | はい |
| Microsoft マネージド | リージョン内のすべてのフェールオーバー グループ | データセンター、可用性ゾーン、またはリージョンで広範囲にわたる障害が発生すると、データベースが使用できなくなり、Microsoft Azure SQL サービス チームは強制フェールオーバーをトリガーすることを決定します。 このオプションは、ディザスター リカバリーの責任をマイクロソフトに委任する必要があり、アプリケーションが少なくとも 1 時間以上の RTO (ダウンタイム) に耐えられる場合にのみ使用します。 |
はい |
お客様による管理
まれに、組み込みの 可用性または高可用性 だけでは停止を軽減できません。また、フェールオーバー グループ内のデータベースは、データベースを使用するアプリケーションのサービス レベル アグリーメント (SLA) に許容できない期間は使用できなくなる可能性があります。 データベースは、少数のデータベースのみに影響するローカライズされた問題が原因で使用できない場合があります。または、データセンター、可用性ゾーン、またはリージョン レベルにある可能性があります。 いずれの場合も、ビジネス継続性を復元するために、強制フェールオーバーを開始できます。
フェールオーバー ポリシーをカスタマー マネージドに設定することを強くお勧めします。フェールオーバーを開始してビジネス継続性を復元するタイミングを制御できます。 フェールオーバー グループ内の 1 つ以上のデータベースに影響を与える予期しない停止が発生した場合に、フェールオーバーを開始できます。
Microsoft マネージド
マイクロソフトマネージド フェールオーバー ポリシーでは、ディザスター リカバリーの責任が Azure SQL サービスに委任されます。 Azure SQL サービスで強制フェールオーバーを開始するには、次の条件を満たす必要があります。
- 自然災害イベント、構成の変更、ソフトウェアのバグまたはハードウェア コンポーネントの障害、およびリージョン内の多くのデータベースによって発生するデータセンター、可用性ゾーン、またはリージョン レベルの停止が影響を受けます。
- 猶予期間が切れています。 停電の規模を確認し、緩和するかどうかは人間の行動に依存するため、猶予期間を 1 時間以下に設定することはできません。
これらの条件が満たされると、Azure SQL サービスは、フェールオーバー ポリシーがマイクロソフトマネージドに設定されているリージョン内のすべてのフェールオーバー グループに対して強制フェールオーバーを開始します。
フェールオーバー ポリシーは、次の場合にのみマイクロソフトマネージドに設定します。
- ディザスター リカバリーの責任を Azure SQL サービスに委任する必要があります。
- アプリケーションは、データベースが少なくとも 1 時間以上使用できないことに耐えられます。
- 強制フェールオーバーの実際の時間は大きく異なる可能性があるため、猶予期間の有効期限が切れた後に強制フェールオーバーをトリガーすることは許容されます。
- ゾーンの冗長性の構成や可用性の状態に関係なく、フェールオーバー グループ内のすべてのデータベースがフェールオーバーしてもかまいません。 ゾーン冗長用に構成されたデータベースはゾーン障害に対する回復性があり、障害の影響を受ける可能性はありませんが、マイクロソフトマネージド フェールオーバー ポリシーを使用するフェールオーバー グループの一部である場合でもフェールオーバーされます。
- アプリケーションが使用する他の Azure サービスまたはコンポーネントに対するアプリケーションの依存関係を考慮せずに、フェールオーバー グループ内のデータベースを強制的にフェールオーバーすることは許容されます。これにより、アプリケーションのパフォーマンスの低下や使用不能が発生する可能性があります。
- 強制フェールオーバーの正確な時刻を制御できず、セカンダリ データベースの同期状態を無視するため、不明な量のデータ損失が発生してもかまいません。
- フェールオーバー グループ内のすべてのプライマリ データベースとセカンダリ データベースおよび任意の Geo レプリケーション関係は、同じサービス レベル、コンピューティング レベル (プロビジョニング済みまたはサーバーレス)、およびコンピューティング サイズ (DTU または仮想コア) で作成されます。 すべてのデータベースのサービス レベル目標 (SLO) が一致しない場合、フェールオーバー ポリシーは最終的に Microsoft マネージドから Azure SQL サービスによるカスタマー マネージドに更新されます。
マイクロソフトによってフェールオーバーがトリガーされると、操作名 Failover Azure SQL フェールオーバー グループのエントリが Azure Monitor アクティビティ ログに追加されます。 エントリには[リソース] の下のフェールオーバー グループの名前が含まれ、イベントによって開始されたイベントには、フェールオーバーが マイクロソフトによって開始されたことを示す 1 つのハイフン (-) が表示されます。 この情報は、Azure portal の 新しいプライマリ サーバーまたはインスタンスの [アクティビティ ログ] ページでも確認できます。
用語と機能
フェールオーバー グループ (FOG)
フェールオーバー グループは、プライマリ リージョンでの機能停止により、すべてまたは一部のプライマリ データベースが使用できなくなった場合に、1 つの単位として別の Azure リージョンにフェールオーバーできる単一のAzure の論理サーバーによって管理されるデータベースの名前付きグループです。
重要
フェールオーバー グループの名前は、
.database.windows.netドメイン内でグローバルに一意である必要があります。サーバー
論理サーバー上のユーザー データベースの一部またはすべてをフェールオーバー グループに配置できます。 また、サーバーでは、単一サーバー上の複数のフェールオーバー グループがサポートされます。
プライマリ
フェールオーバー グループのプライマリ データベースのホストとなる論理サーバー。
セカンダリ
フェールオーバー グループのセカンダリ データベースのホストとなる論理サーバー。 セカンダリをプライマリと同じ Azure リージョンに配置することはできません。
フェールオーバー (データ損失なし)
フェールオーバーでは、セカンダリがプライマリ ロールに切り替わる前に、プライマリ データベースとセカンダリ データベース間の完全なデータ同期が行われます。 これにより、データ損失が発生しないことが保証されます。 フェールオーバーは、プライマリにアクセスできる場合にのみ可能です。 フェールオーバーは、次のシナリオで使用されます。
- データ損失が許容されない場合は、運用環境でディザスター リカバリー (DR) ドリルを行います
- ワークロードを別のリージョンに再配置します
- 機能停止が軽減 (フェールバック) された後、ワークロードをプライマリ リージョンに返します
強制フェールオーバー (データ損失の可能性)
強制フェールオーバーの場合、最近の変更がプライマリから反映されるのを待たずに、直ちにセカンダリがプライマリに切り替わります。 この操作を実行するとデータが失われる可能性があります。 強制フェールオーバーは、機能停止時においてプライマリにアクセスできない場合に回復手段として使用されます。 停止が緩和されると、以前のプライマリは自動的に再接続され、新しいセカンダリになります。 フェールオーバーを実行してフェールバックし、レプリカを元のプライマリとセカンダリのロールに戻すこともできます。
データ消失の猶予期間
非同期レプリケーションを使用してデータがセカンダリにレプリケートされるため、マイクロソフトマネージド フェールオーバー ポリシーを使用してグループを強制フェールオーバーすると、データが失われる可能性があります。 アプリケーションのデータ損失の許容範囲が反映されるように、フェールオーバー ポリシーをカスタマイズできます。
GracePeriodWithDataLossHoursを構成することで、データ損失につながる可能性がある強制フェールオーバーの開始までに Azure SQLサービスが待機する時間を制御できます。
フェールオーバー グループへの単一データベースの追加
同じ論理サーバー上の複数の単一データベースを、同じフェールオーバー グループに配置できます。 フェイルオーバー・グループに 1 つのデータベースを追加すると、フェイルオーバー・グループの作成時に指定したセカンダリ・サーバ上に、同じエディションと計算サイズを使用するセカンダリ・データベースが自動的に作成されます。 セカンダリ サーバーにセカンダリ データベースが既に存在するデータベースを追加する場合、その geo レプリケーション リンクがグループに継承されます。 フェールオーバー グループの一部でないサーバーにセカンダリ データベースが既に存在するデータベースを追加すると、セカンダリ サーバーに新しいセカンダリデータベースが作成されます。
重要
- 既存のセカンダリ データベースである場合を除き、セカンダリ論理サーバーに同じ名前のデータベースがないことを確認してください。
- データベースにインメモリ OLTP オブジェクトが含まれている場合、インメモリ OLTP オブジェクトがメモリ内に存在するため、プライマリ データベースとターゲットセカンダリ geo レプリカ データベースには一致するサービス レベルが必要です。 geo レプリカ データベースのサービス レベルが低いと、メモリ不足の問題が発生する可能性があります。 この問題が発生すると、geo レプリカがデータベースの復旧に失敗し、セカンダリ データベースと geo セカンダリ上のインメモリ OLTP オブジェクトが使用できなくなる可能性があります。 これにより、フェールオーバーも失敗する可能性があります。 これを回避するには、geo セカンダリ データベースのサービス レベルがプライマリ データベースのサービス レベルと一致していることを確認します。 サービス レベルのアップグレードは、データサイズの操作になる場合があり、完了するまでに時間がかかる場合があります。
エラスティック プール内のデータベースをフェールオーバー グループに追加する
1 つのエラスティック プール内のすべてまたは複数のデータベースを同じフェールオーバー グループに置くことができます。 プライマリ データベースがエラスティック プール内にある場合、セカンダリは同じ名前のエラスティック プール (セカンダリ プール) に自動的に作成されます。 セカンダリ サーバーに全く同じ名前のエラスティック プールが含まれており、フェールオーバー グループによって作成されるセカンダリ データベースをホストするのに十分な空き容量があることを確認する必要があります。 セカンダリ プールにセカンダリ データベースが既に存在するプールにデータベースを追加する場合、その geo レプリケーション リンクがグループに継承されます。 フェールオーバー グループの一部でないサーバーにセカンダリ データベースが既に存在するデータベースを追加すると、セカンダリ プールに新しいセカンダリデータベースが作成されます。
フェールオーバー グループの読み取り/書き込みリスナー
現在のプライマリをポイントする DNS CNAME レコード。 フェールオーバー グループが作成されるときに自動的に作成され、フェールオーバー後にプライマリが変更された場合に、読み取り/書き込みワークロードがプライマリに透過的に再接続できるようにします。 サーバーでフェールオーバー グループが作成されたときに、リスナー URL の DNS CNAME レコードの形式は
<fog-name>.database.windows.netになります。 フェールオーバー後、DNS レコードが自動的に更新され、リスナーが新しいプライマリにリダイレクトされます。フェールオーバー グループの読み取り専用リスナー
現在のセカンダリをポイントする DNS CNAME レコード。 フェールオーバー グループが作成されるときに自動的に作成され、フェールオーバー後にセカンダリが変更された場合に、読み取り専用 SQL ワークロードがセカンダリに透過的に接続できるようにします。 サーバーでフェールオーバー グループが作成されたときに、リスナー URL の DNS CNAME レコードの形式は
<fog-name>.secondary.database.windows.netになります。 既定では、読み取り専用リスナーのフェールオーバーは無効になります。これにより、セカンダリがオフラインのときにプライマリのパフォーマンスに影響が及ばないようにします。 ただし、セカンダリが回復するまで、読み取り専用セッションは接続できません。 読み取り専用セッションのダウンタイムを許容できず、プライマリのパフォーマンスが下がる可能性があっても、読み取り専用と読み取り/書き込みの両方のトラフィックにプライマリを使用してもよければ、AllowReadOnlyFailoverToPrimaryプロパティを構成することによって、読み取り専用リスナーのフェールオーバーを有効にできます。 その場合、セカンダリが利用できないと、読み取り専用トラフィックがプライマリに自動的にリダイレクトされます。Note
AllowReadOnlyFailoverToPrimaryプロパティは、マイクロソフトマネージドフェールオーバー ポリシーが有効になっていて、強制フェールオーバーがトリガーされる場合にのみ有効です。 この場合、プロパティが True に設定されていると、新しいプライマリは読み取り/書き込みセッションと読み取り専用セッションの両方を提供します。複数のフェールオーバー グループ
同じサーバーのペアに対して複数のフェールオーバー グループを構成して、geo フェールオーバーのスコープを制御できます。 各グループは独立してフェールオーバーします。 データベースごとのテナント アプリケーションが複数のリージョンにデプロイされ、エラスティック プールを使用している場合は、この機能を使用して、各プール内のプライマリ データベースとセカンダリ データベースを混在できます。 これにより、一部のテナント データベースに対する停止の影響を軽減できる場合があります。
フェールオーバー グループのアーキテクチャ
Azure SQL Database のフェールオーバー グループには、通常同じアプリケーションによって使用される、1 つまたは複数のデータベースを含めることができます。 プライマリサーバーにフェイルオーバーグループを設定し、別の Azure リージョンにあるセカンダリサーバーに接続する必要があります。 フェイルオーバー・グループには、プライマリ・サーバのすべてのデータベースまたは一部のデータベースを含めることができます。 次の図は、フェイルオーバー・グループで複数のデータベースを使用する、地理冗長クラウド・アプリケーションの典型的な構成を示したものです:
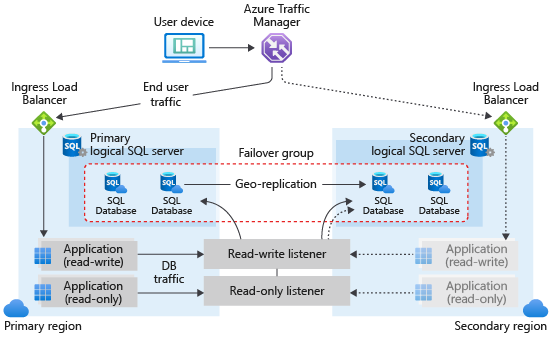
ビジネス継続性を念頭に置いてサービスを設計する場合は、この記事で説明されている一般的なガイドラインとベスト プラクティスに従ってください。 フェールオーバー グループを構成する場合は、geo フェールオーバー後に geo セカンダリが新しいプライマリになったときに、セカンダリの認証とネットワーク アクセスが正しく機能するように設定されていることを確認します。 詳細については、 障害復旧後の SQL Database のセキュリティに関するページを参照してください。 詳細については、「ディザスター リカバリーのためのクラウド ソリューションの設計」を参照してください。
ペアリージョンを使用する
プライマリ サーバーとセカンダリ サーバーの間でフェールオーバー グループを作成する場合は、ペアになっているリージョンのフェールオーバー グループの方が、ペアになっていないリージョンと比較してパフォーマンスが向上するため、ペアになっているリージョンを使用します。
安全なデプロイプラクティスに従って、Azure SQL データベースでは一般に、ペアになっているリージョンは同時に更新されません。 ただし、最初にアップグレードされるリージョンを予測することはできないため、デプロイの順序は保証されません。 プライマリ サーバーが最初にアップグレードされ、2 番目にアップグレードされる場合があります。
Azure リージョンのペアリングと一致しないデータベース用に geo レプリケーションまたはフェールオーバー グループが構成されている場合は、プライマリ データベースとセカンダリ データベースに対して異なるメンテナンス期間スケジュールを使用します。 たとえば、geo セカンダリ データベースのメンテナンス期間には [平日] を選択し、geo プライマリ データベースのメンテナンス期間には [週末] を選択できます。
初期シード処理
データベースまたはエラスティック プールをフェールオーバー グループに追加する場合、データ レプリケーションが開始される前に、初期シード処理フェーズがあります。 初期シード処理フェーズは、最も時間がかかり、最も負荷の高い操作です。 初期シード処理が完了すると、データは同期され、その後はそれ以降のデータ変更のみがレプリケートされます。 初期シード処理が完了するまでにかかる時間は、データのサイズ、レプリケートされたデータベースの数、プライマリ データベースにかかる負荷、プライマリとセカンダリデータベース間のリンクの速度によって異なります。 通常の環境において可能なシード処理の速度は、SQL Database では最大 500 GB/時になります。 シード処理は、すべてのデータベースに対して並列で実行されます。
複数のフェールオーバー グループを使用して、複数のデータベースをフェールオーバーする
1 つまたは複数のフェールオーバー グループを異なるリージョンの 2 つのサーバー (プライマリおよびセカンダリ サーバー) 間に作成できます。 各グループには、プライマリ リージョンに発生した機能停止によりすべてまたは一部のプライマリ データベースが使用できなくなった際にユニットとして復元できる、1 つまたは複数のデータベースを含めることができます。 フェールオーバー グループを作成すると、プライマリと同じサービス目標を持つ geo セカンダリ データベースが作成されます。 既存の geo レプリケーション関係をフェールオーバー グループに追加する場合は、geo セカンダリがプライマリと同じサービス レベルとコンピューティング サイズで構成されていることを確認します。
読み取り/書き込みリスナーを使用する (プライマリ)
読み取り/書き込みワークロードの場合は、接続文字列 <fog-name>.database.windows.net のサーバー名として を使用します。 接続は自動的にプライマリに向けられる。 この名前はフェールオーバー後に変更されません。 フェールオーバーでは DNS レコードの更新が行われるため、クライアントの接続は、クライアント DNS キャッシュが最新の情報に更新された後にのみ新しいプライマリにリダイレクトされます。 プライマリおよびセカンダリ リスナーの DNS レコードの有効期限 (TTL) は 30 秒です。
読み取りリスナーを使用する (セカンダリ)
データ待機時間に耐える読み取り専用ワークロードを論理的に分離している場合は、geo セカンダリで実行できます。 読み取り専用セッションの場合は<fog-name>.secondary.database.windows.net、接続文字列のサーバー名として を使用します。 接続は自動的に geo セカンダリに向けられる。 ApplicationIntent=ReadOnly を使用して、接続文字列で読み取りの意図を示すこともお勧めします。
Premium、Business Critical、Hyperscale の各サービス レベルの SQL Database では、読み取り専用クエリのワークロードを軽減するために、読み取り専用レプリカの使用がサポートされています。この場合、接続文字列に ApplicationIntent=ReadOnly パラメーターが使用されます。 geo セカンダリを構成した場合は、この機能を使用して、プライマリの場所または geo セカンダリの場所の読み取り専用レプリカに接続できます。
セカンダリ ロケーションの読み取り専用レプリカに接続するには、ApplicationIntent=ReadOnly と <fog-name>.secondary.database.windows.net を使用します。
フェールオーバー後のパフォーマンス低下の可能性
一般的な Azure アプリケーションでは、複数の Azure サービスを使用し、複数のコンポーネントで構成されます。 グループのフェールオーバーは、Azure SQL データベースの状態だけに基づいてトリガーされます。 プライマリ リージョンのその他の Azure サービスは機能停止の影響を受けない場合があり、それらのコンポーネントを引き続きそのリージョンで利用できる可能性があります。 プライマリ データベースがセカンダリ リージョンに切り替えられると、依存コンポーネント間の待機時間が長くなる場合があります。 アプリケーションのパフォーマンスに対する待機時間の長い影響を回避するには、DR リージョン内のすべてのアプリケーションコンポーネントの冗長性を確保し、次のネットワーク セキュリティガイドラインに従い、関連するアプリケーション コンポーネントの geo フェールオーバーをデータベースと共に調整します。
強制フェールオーバー後のデータ損失の可能性
プライマリ リージョンで障害が発生した場合、最近のトランザクションが geo セカンダリにレプリケートされていない可能性があり、強制フェールオーバーが実行されるとデータが失われる可能性があります。
重要
DTC が 800 以下、仮想コア数が 8 以下、データベース数が 250 を超えるエラスティック プールでは、計画された geo フェールオーバーの時間の長さやパフォーマンスの低下などの問題が発生する可能性があります。 これらの問題は、書き込み集中型のワークロード、geo レプリカが地理的に広く分離されている場合、またはデータベースごとに複数のセカンダリ geo レプリカが使用されている場合に発生する可能性が高い。 これらの問題の症状は、時間の過ぎた geo レプリケーションのラグが増加し、停止中のデータ損失が拡大する可能性があります。 このラグは、sys.dm_geo_replication_link_status を使用して監視できます。 これらの問題が発生した場合の軽減策には、DTU または仮想コアを増やしたり、プール内の geo レプリケートされたデータベースの数を減らしたりするために、プールをスケールアップする作業が含まれます。
フェールバック
フェールオーバー グループが自動マイクロソフトマネージドフェールオーバー ポリシーを使って構成されていると、障害シナリオの間に、定義された猶予期間に従って、geo セカンダリ サーバーへのフェールオーバーが開始されます。 古いプライマリへのフェールバックは、手動で開始する必要があります。
アクセス許可と制限
アクセス許可と制限事項の一覧については、フェールオーバー グループの構成ガイドを参照してください。
フェールオーバーグループをプログラムで管理する
フェールオーバー グループは、Azure PowerShell、Azure CLI、および REST API を使用してプログラムで管理することもできます。 詳細については、「フェールオーバー グループを構成する」を参照してください。
関連するコンテンツ
- サンプル スクリプトは、次をご覧ください:
- ビジネス継続性の概要およびシナリオについては、ビジネス継続性の概要を参照してください。
- Azure SQL Database 自動バックアップの詳細については、「 SQL Database 自動バックアップ」を参照してください
- 自動バックアップを使用して復旧する方法については、 サービス主導のバックアップからのデータベース復元に関する記事を参照してください。
- 新しいプライマリ サーバーとデータベースの認証要件については、 障害復旧後の SQL Database のセキュリティに関する記事を参照してください。
フィードバック
以下は間もなく提供いたします。2024 年を通じて、コンテンツのフィードバック メカニズムとして GitHub の issue を段階的に廃止し、新しいフィードバック システムに置き換えます。 詳細については、「https://aka.ms/ContentUserFeedback」を参照してください。
フィードバックの送信と表示