マルチテナント SaaS アプリの Azure SQL Database のパフォーマンスを監視および管理する
適用対象:![]() Azure SQL Database
Azure SQL Database
このチュートリアルでは、SaaS アプリケーションで使用されるいくつかの主要なパフォーマンス管理シナリオを説明します。 ロード ジェネレーターを使用して、すべてのテナント データベース間でのアクティビティをシミュレートし、SQL Database およびエラスティック プールに組み込まれている監視機能およびアラート機能を示します。
Wingtip Tickets SaaS Database Per Tenant アプリでは、会場 (テナント) ごとに独自のデータベースを持つシングル テナント データ モデルが採用されています。 多くの SaaS アプリケーションと同様、テナントのワークロード パターンは予測不能で、かつ散発的であることが予想されます。 つまり、チケット販売は常に発生する可能性があります。 この一般的なデータベース使用パターンを利用するには、テナント データベースをエラスティック プールにデプロイします。 エラスティック プールでは、多くのデータベース間でリソースを共有することで、ソリューションのコストが最適化されます。 このタイプのパターンでは、データベースとプールのリソース使用を監視して、プール全体で負荷を適切かつ確実に分散させることが重要です。 また、各データベースに十分なリソースがあることと、プールが eDTU 制限に達していないことを確認する必要もあります。 このチュートリアルでは、データベースとプールを監視および管理し、ワークロードの変化に応じて是正措置を講じる方法について説明します。
このチュートリアルで学習する内容は次のとおりです。
- 指定されたロード ジェネレーターを実行して、テナント データベースの使用をシミュレートする
- テナント データベースによる負荷の増加への対応を監視する
- データベースの負荷の増加に応じてエラスティック プールをスケールアップする
- データベース アクティビティの負荷を分散するために、2 つ目のエラスティック プールをプロビジョニングする
このチュートリアルを完了するには、次の前提条件を満たしておく必要があります。
- Wingtip Tickets SaaS Database Per Tenant アプリをデプロイします。 5 分未満でデプロイするには、「Deploy and explore the Wingtip Tickets SaaS Multi-tenant Database application (Wingtip Tickets SaaS Database Per Tenant アプリケーションのデプロイと探索)」を参照してください
- Azure PowerShell がインストールされている。 詳しくは、「Azure PowerShell を使ってみる」をご覧ください。
SaaS パフォーマンス管理パターンの概要
データベース パフォーマンスを管理するには、まずパフォーマンス データをコンパイルして分析し、その後、このデータに基づいて、アプリケーションの許容応答時間を維持できるようパラメーターを調整します。 複数のテナントをホストしている場合、エラスティック プールを使用すると、ワークロードが予測できないデータベース グループのリソースを、コスト効率に優れた方法で提供し、管理できます。 特定のワークロード パターンでは、S3 データベースが 2 つだけでも、プールで管理するというメリットを利用できます。

プール、およびプール内のデータベースは、パフォーマンスが許容範囲内で維持されるよう監視する必要があります。 プール構成は、すべてのデータベースの集計ワークロードのニーズを満たすように調整し、ワークロード全体に適したプールの eDTU を確保します。 データベースあたりの eDTU の最小値と最大値を、特定のアプリケーション要件に応じて適切な値に調整してください。
パフォーマンス管理戦略
- 手動でのパフォーマンス監視を避けるため、データベースまたはプールが正常範囲から外れたときにアラートがトリガーされるように設定すると最も効果的です。
- プールの集計コンピューティング サイズで発生する短期的変動に対応するために、プールの eDTU レベルをスケールアップまたはスケールダウンできます。 こうした変動が定期的に発生する場合、または変動を予測できる場合は、プールが自動的にスケールされるようにスケジュール設定します。 たとえば、ワークロードが少なくなることがわかっている夜間や週末は、スケールダウンします。
- 長期的変動や複数のデータベースの変更に対応するには、データベースを個別に他のプールに移動します。
- 個別のデータベース負荷の短期的な増加に対応するには、データベースを個別にプールから取得し、それぞれにコンピューティング サイズを割り当てます。 負荷が減少すると、データベースはプールに戻すことができます。 これが事前にわかっている場合は、データベースをあらかじめ移動してデータベースに常に必要なだけのリソースが確保されるようにすることで、プール内の他のデータベースへの影響を避けることができます。 たとえば、ある会場における人気イベントのにチケット販売にアクセスが殺到する、といった予測可能な要件に対しては、この管理動作をアプリケーションに組み込むことができます。
Azure Portal には、ほとんどのリソースに監視とアラートが組み込まれています。 データベースとプールで監視とアラートを利用できます。 この組み込みの監視とアラートはリソース固有であるため、リソースが少数の場合は便利ですが、リソースの数が多くなると、それほど便利とは言えません。
多くのリソースを処理する大規模なシナリオの場合は、Azure Monitor ログを使用できます。 これは、Log Analytics ワークスペースで収集されたログに対する分析を提供する別の Azure サービスです。 Azure Monitor ログは、多くのサービスからテレメトリを収集できます。また、このサービスを使用して、クエリを実行し、アラートを設定することもできます。
Wingtip Tickets SaaS Database Per Tenant アプリケーション スクリプトを入手する
Wingtip Tickets SaaS マルチテナント データベースのスクリプトとアプリケーション ソース コードは、WingtipTicketsSaaS-DbPerTenant GitHub リポジトリで入手できます。 Wingtip Tickets SaaS スクリプトをダウンロードし、ブロックを解除する手順については、一般的なガイダンスに関する記事をご覧ください。
その他のテナントのプロビジョニング
S3 データベースが 2 つだけでもプールはコスト効率よく動作しますが、プール内のデータベースが多くなると、平均的な効果のコスト効率はさらに向上します。 大規模環境でのパフォーマンスの監視と管理のしくみを十分に理解するために、このチュートリアルでは、少なくとも 20 のデータベースをデプロイする必要があります。
前のチュートリアルで既にテナントのバッチをプロビジョニングした場合は、「すべてのテナント データベースの使用をシミュレート」に進んでください。
- PowerShell ISE で、…\Learning Modules\Performance Monitoring and Management\Demo-PerformanceMonitoringAndManagement.ps1 を開きます。 このスクリプトを開いたまま、このチュートリアルのシナリオをいくつか実行します。
- $DemoScenario = 1 ("テナントのバッチのプロビジョニング") を設定します
- F5 キーを押して、スクリプトを実行します。
スクリプトによって、17 のテナントが 5 分以内でデプロイされます。
New-TenantBatch スクリプトでは、入れ子になった、またはリンクされている Resource Manager テンプレート セットを使用して、テナントのバッチが作成されます。これにより、既定では、basetenantdb データベースがカタログ サーバーにコピーされ、新しいテナント データベースが作成されます。その後、そのデータベースがカタログに登録され、最後にテナント名と会場の種類で初期化されます。 これは、アプリが新しいテナントをプロビジョニングする方法と一致します。 basetenantdb に対するすべての変更が、その後プロビジョニングされた新しいテナントすべてに適用されます。 既存のテナント データベース (basetenantdb データベースを含む) に対してスキーマの変更を行う方法については、スキーマ管理のチュートリアルをご覧ください。
すべてのテナント データベースの使用をシミュレート
すべてのテナント データベースに対して実行されるワークロードをシミュレートする Demo-PerformanceMonitoringAndManagement.ps1 スクリプトが用意されています。 使用可能な負荷のシナリオの 1 つを使用して、負荷が生成されます。
| デモ | シナリオ |
|---|---|
| 2 | 標準強度の負荷 (約 40 DTU) を生成する |
| 3 | 各データベースにバーストが長く、かつ頻繁に発生する負荷を生成 |
| 4 | 各データベースに高 DTU バースト (約 80 DTU) の負荷を生成 |
| 5 | 通常の負荷のほか、シングル テナントに高負荷 (約 95 DTU) を生成 |
| 6 | 複数のプールに不均衡な負荷を生成 |
ロード ジェネレーターは、"合成" CPU のみの負荷を、すべてのテナント データベースに適用します。 ジェネレーターはテナント データベースごとにジョブを開始し、これにより負荷を生成するストアド プロシージャが定期的に呼び出されます。 負荷レベル (eDTU 単位)、期間、および間隔はすべてのデータベースで異なり、予測不可能なテナントのアクティビティをシミュレートします。
- PowerShell ISE で、…\Learning Modules\Performance Monitoring and Management\Demo-PerformanceMonitoringAndManagement.ps1 を開きます。 このスクリプトを開いたまま、このチュートリアルのシナリオをいくつか実行します。
- $DemoScenario = 2 (標準強度の負荷を生成) を設定します。
- F5 キーを押して、負荷をすべてのテナント データベースに適用します。
Wingtip Tickets SaaS Database Per Tenant は SaaS アプリであり、SaaS アプリに対する実際の負荷は通常、散発的かつ予測不可能です。 これをシミュレートするために、ロード ジェネレーターはすべてのテナントに分散されるランダムな負荷を生成します。 負荷パターンが出現するまで数分かかるため、ロード ジェネレーターを 3 ~ 5 分実行してから、負荷を監視する次のセクションに進んでください。
重要
ロード ジェネレーターは、ローカル PowerShell セッションで一連のジョブとして実行されています。 [Demo-PerformanceMonitoringAndManagement.ps1] タブは開いたままにしておいてください。 タブを閉じるか、コンピューターを中断すると、ロード ジェネレーターは停止します。 ロード ジェネレーターは、ジェネレーターの開始後にプロビジョニングされた新しいテナントの負荷を生成するジョブ呼び出し状態のままです。 CTRL + C を使用して新しいジョブの呼び出しを停止し、スクリプトを終了します。 既存のテナントに対してのみロード ジェネレーターの実行が続行されます。
Azure ポータルを使用したリソース使用の監視
負荷を適用した結果、リソースがどのように使用されているかを監視するには、テナント データベースを含むプールに対してポータルを開きます。
- Azure Portal を開いて、tenants1-dpt-<USER> サーバーを参照します。
- 下にスクロールし、エラスティック プールを検索して、[Pool1] をクリックします。 このプールには、これまでに作成されたすべてのテナント データベースが含まれています。
エラスティック プールの監視とエラスティック データベースの監視のグラフを確認します。
プールのリソース使用は、プール内のすべてのデータベースのデータベース使用の集計を示しています。 データベースのグラフは、5 つの最新のデータベースを示しています。
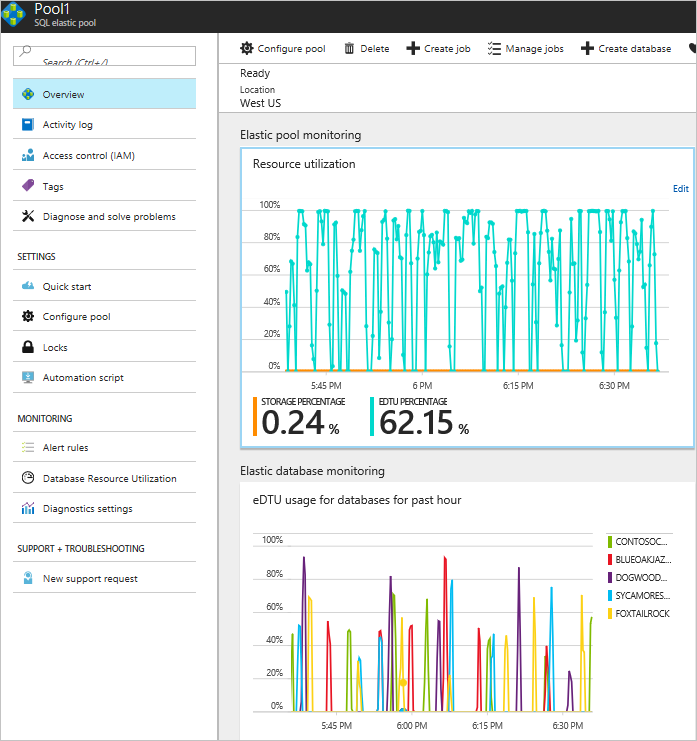
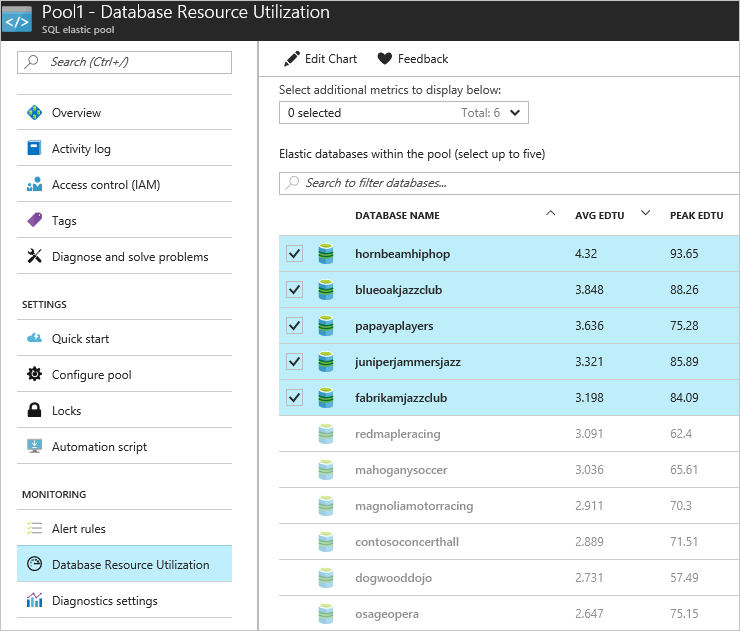
使用率の高い 5 つのデータベース以外にもプールにはデータベースは存在するため、プール使用率は、使用率の高い 5 つのデータベース グラフに反映されていないアクティビティを示しています。 詳細を確認するには、[データベース リソースの使用率] をクリックします。
プールでのパフォーマンス アラートの設定
>75% の使用率のときに、プールでアラートがトリガーされるように設定する手順を次に示します。
Azure Portal で、(tenants1-dpt-<user> サーバーにある) Pool1 を開きます。
[アラート ルール]、[+ アラートの追加] の順にクリックします。
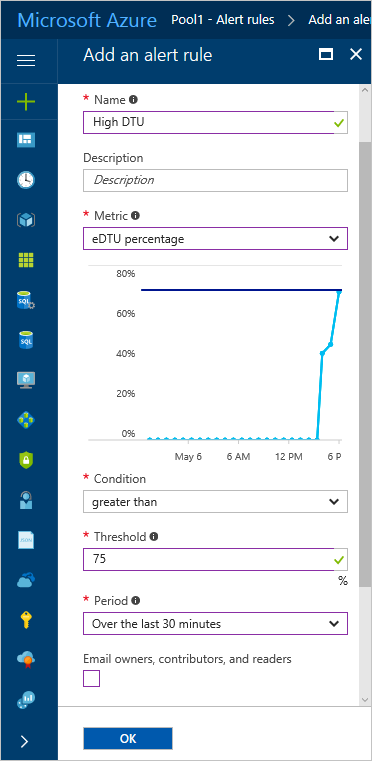
名前 (高 DTU など) を付けます。
次の値を設定します。
- メトリック = eDTU の割合
- 条件 = より大きい
- しきい値 = 75
- 期間 = 過去 30 分間
[追加する管理者の電子メール] ボックスに電子メール アドレスを追加し、[OK] をクリックします。
ビジー状態のプールのスケールアップ
プールの集計負荷レベルが、プールを使い切り、eDTU 使用率が 100% に達すると、各データベースのパフォーマンスが影響を受け、プール内のすべてのデータベースのクエリ応答時間が遅くなる可能性があります。
短期的には、プールをスケールアップしてリソースを追加するか、プールからデータベースを削除すること、たとえばデータベースを他のプールに移動したり、プールからスタンドアロン サービス レベルに移動したりすることを検討してください。
長期的には、クエリやインデックスの使用を最適化して、データベース パフォーマンスを向上させることを検討します。 パフォーマンスの問題がアプリケーションにどの程度影響するかによっては、eDTU 使用率が 100% に達する前に、プールをスケールアップすることをお勧めします。 アラートを使用して、事前に警告するよう設定できます。
ビジー状態のプールをシミュレートするには、ジェネレーターによって生成される負荷を増やします。 データベースのバーストの頻度を上げ、時間を長くすることで、プールの集計負荷が増加します。その際、個別のデータベースの要件を変更する必要はありません。 プールのスケールアップは、ポータルまたは PowerShell で簡単に行うことができます。 ここでは、ポータルを使用します。
$DemoScenario = 3 ("各データベースにバーストが長く、かつ頻繁に発生する負荷を生成") を設定し、各データベースに必要なピーク負荷を変えずにプールの集計負荷の強度を上げます。
F5 キーを押して、負荷をすべてのテナント データベースに適用します。
Azure ポータルの Pool1 に移動します。
上部のグラフでプールの eDTU 使用の増加を監視します。 高負荷が反映されるまで数分かかりますが、プールの使用率はすぐに最大に達します。そして、負荷が新しいパターンで安定すると、迅速にプールをオーバーロードします。
- プールをスケールアップするには、Pool1 ページの上部にある [プールの構成] をクリックします。
- [プールの eDTU] の設定を 100 に調整します。 プール の eDTU を変更しても、データベースごとの設定は変わりません (データベースあたり最大 50 eDTU)。 データベースごとの設定は、[プールの構成] ページの右側で確認できます。
- [保存] をクリックして、プールのスケール要求を送信します。
[Pool1]>[概要] に戻って、監視グラフを表示します。 プールのリソースを増やした効果を監視してください (ただし、少しのデータベースと、ランダムな負荷を追加しただけでは、しばらく実行するまでその効果を確認するのは必ずしも容易ではありません)。 グラフを見るときは、上部のグラフの 100% は 100 eDTU を表していますが、下部のグラフの 100% は 50 eDTU を表すことに注意してください。これはデータベースあたりの最大値がまだ 50 eDTU であるためです。
データベースはオンラインのままで、プロセス全体で完全に使用できます。 新しいプールの eDTU で各データベースが有効になる間際に、アクティブなすべての接続が切断されます。 切断された接続を再試行するためのアプリケーション コードが常に記述されており、これによりスケールアップ プール内のデータベースに再接続されます。
プール間での負荷分散
プールをスケールアップするもう 1 つの方法として、2 つ目のプールを作成してデータベースを移動し、2 つのプール間で負荷を分散させます。 これを行うには、1 つ目のプールと同じサーバーに新しいプールを作成する必要があります。
Azure Portal で tenants1-dpt-<USER> サーバーを開きます。
[+ 新しいプール] をクリックして、現在のサーバーにプールを作成します。
エラスティック プール テンプレートで次の操作を行います。
[名前] を Pool2 に設定します。
価格レベルは Standard プールのままにします。
[プールの構成] をクリックします。
プールの eDTU を 50 eDTU に設定します。
[データベースの追加] をクリックして、Pool2 に追加できるサーバーのデータベースの一覧を表示します。
10 個のデータベースを選択し、新しいプールに移動し、[選択] をクリックします。 ロード ジェネレーターを実行している場合、サービスは、パフォーマンス プロファイルが既定の 50 eDTU より大きいプールを必要としていることを既に認識していて、100 eDTU 設定で始めることを推奨します。
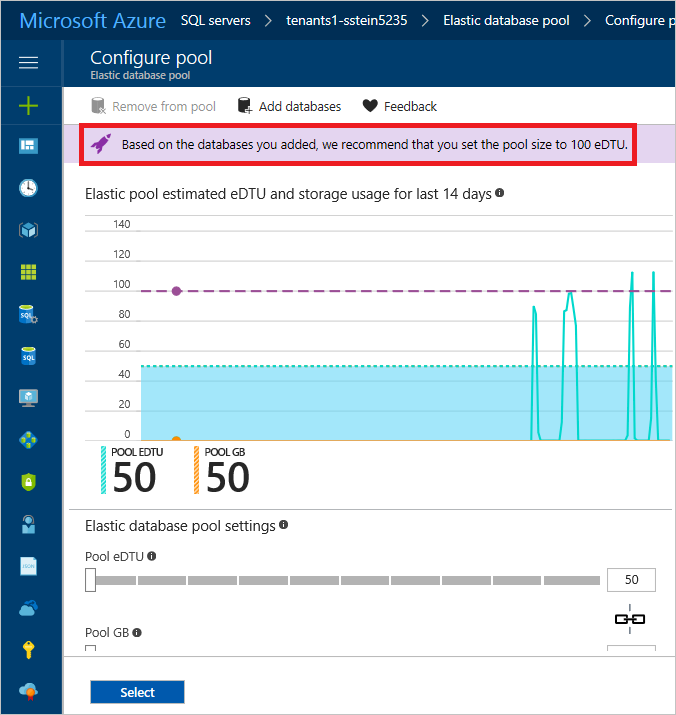
このチュートリアルでは、既定値の 50 eDTU のままにし、もう一度 [選択] をクリックします。
[OK] を選択して新しいプールを作成し、選択したデータベースを移動します。
プールを作成して、データベースを移動するには数分かかります。 移動中のデータベースはそれぞれオンライン状態が維持され、オープンな接続すべてが閉じる最後の時点まで完全にアクセスできます。 いくつか再試行ロジックがある限り、クライアントは、新しいプール内のデータベースに接続します。
Pool2 (tenants1-dpt-<user> サーバーの上) を参照してプールを開き、パフォーマンスを監視します。 表示されない場合、新しいプールのプロビジョニングが完了するのを待機します。
Pool1 のリソース使用が削除され、Pool2 が同じように読み込まれていることがわかります。
個々のデータベースのパフォーマンス管理
プール内の個々のデータベースの負荷が継続して高い場合、プールの構成によっては、プール内のリソースを使用し、他のデータベースに影響を与えている可能性があります。 このようなアクティビティがしばらく続く可能性が高い場合は、そのデータベースをプールから一時的に移動できます。 これにより、データベースが必要な追加リソースを確保でき、他のデータベースから分離できます。
ここでは、人気の高いコンサートのチケット発売時に高負荷が発生する Contoso コンサート ホールの状況をシミュレートします。
PowerShell ISE で、…\Demo-PerformanceMonitoringAndManagement.ps1 スクリプトを開きます。
$DemoScenario = 5 ("1 つのテナントに標準負荷に加えて高負荷 (約 95 DTU) を生成") を設定します。
$SingleTenantDatabaseName = contosoconcerthall を設定します
F5 を使用して、スクリプトを実行します。
Azure portal で、tenants1-dpt-<user> サーバー上のデータベースの一覧を参照します。
contosoconcerthall データベースをクリックします。
contosoconcerthall が含まれるプールをクリックします。 [エラスティック プール] セクションでプールを検索します。
エラスティック プールの監視グラフを検査し、プールの eDTU 使用の増加を探します。 数分後にさらに高い負荷が発生し、プール使用率がすぐに 100% に達します。
[弾力性データベースの監視] を検査します。これは、過去 1 時間で最も使用率が高いデータベースを示しています。 すぐに contosoconcerthall データベースが最も使用率が高い 5 つのデータベースの 1 つとして表示されます。
[弾力性データベースの監視]グラフをクリックすると、[データベース リソースの使用率] ページが開きます。このページでは、データベースを監視できます。 これにより、contosoconcerthall データベースの表示を切り離すことができます。
データベースの一覧から contosoconcerthall をクリックします。
[価格レベル (DTU のスケール)] をクリックして [パフォーマンスの構成] ページを開きます。ここでは、データベースのスタンドアロンのコンピューティング サイズを設定できます。
[Standard] タブをクリックして、Standard レベルのスケール オプションを開きます。
DTU スライダーを右に移動して、100 DTU を選択します。 これは、サービス目標 S3 に対応します。
[適用] をクリックして、プールからデータベースを移動し、Standard S3 データベースに設定します。
スケーリングが完了したら、contosoconcerthall データベースに対する効果と、エラスティック プールとデータベース ブレード上の Pool1 に対する効果を監視します。
contosoconcerthall データベースの高い負荷が落ち着いたら、コストを削減するためにすぐにプールに戻す必要があります。 そのタイミングがはっきりしない場合は、プールで DTU の使用率がデータベースあたりの最大値を下回ったときに、データベースでアラートがトリガーされるように設定できます。 プールへのデータベースの移動については、演習 5 で説明しています。
その他のパフォーマンス管理パターン
プリエンプティブなスケーリング: 上記の演習では、目的のデータベースがわかっている場合に、データベースを切り離してスケールする方法を説明しました。 Contoso コンサート ホールの運営者によって、間もなくチケットが発売されることが Wingtip に知らされていれば、データベースを事前にプールから移動することもできるでしょう。 しかし、そうでない場合は、プールまたはデータベースでアラートを設定して、何が起こっているかを把握しなければならない可能性があります。 プール内の他のテナントからのパフォーマンス低下に関する苦情によって、このことを知りたくはありません。 また、追加リソースが必要となる期間をテナントが予測できれば、Azure Automation Runbook を設定することで、プールからデータベースを移動する作業、そしてプールに戻す作業を決められたスケジュールで行うことができます。
テナント セルフサービス スケーリング: スケーリング タスクは管理 API 経由で簡単に呼び出されます。このため、テナント接続アプリケーションにテナント データベースをスケールする機能は簡単に作成できます。作成した機能は、SaaS サービスの機能として提供できます。 たとえば、テナントによるスケールアップ/スケールダウンの自己管理が可能で、場合によっては、これが請求に直接リンクされます。
使用パターンに合わせてプールのスケールアップ/スケールダウンをスケジュール設定
予測可能な使用パターンに従って集計テナントが使用されている場合は、Azure Automation を使用して、スケジュールに従ってプールをスケールアップ/スケールダウンできます。 たとえば、平日午後 6 時以降に必要なリソースが減ることがわかっている場合、その時間帯はプールをスケールダウンし、午前 6 時前に再度スケールアップします。
次のステップ
このチュートリアルで学習する内容は次のとおりです。
- 指定されたロード ジェネレーターを実行して、テナント データベースの使用をシミュレートする
- テナント データベースによる負荷の増加への対応を監視する
- データベースの負荷の増加に応じてエラスティック プールをスケールアップする
- データベース アクティビティの負荷を分散するために、2 つ目のエラスティック プールをプロビジョニングする
その他のリソース
- Wingtip Tickets SaaS Database Per Tenant アプリケーションのデプロイに基づく作業のための追加のチュートリアル
- SQL エラスティック プール
- Azure Automation
- Azure Monitor ログ - Azure Monitor ログ チュートリアルの設定と使用
フィードバック
以下は間もなく提供いたします。2024 年を通じて、コンテンツのフィードバック メカニズムとして GitHub の issue を段階的に廃止し、新しいフィードバック システムに置き換えます。 詳細については、「https://aka.ms/ContentUserFeedback」を参照してください。
フィードバックの送信と表示