仮想コア購入モデル - Azure SQL Database
適用対象:![]() Azure SQL Database
Azure SQL Database
この記事では、Azure SQL Database 用の仮想コア購入モデルを確認します。
概要
仮想コア (vCore) は論理 CPU を表し、ハードウェアの物理特性 (コア数、メモリ、ストレージ サイズなど) を選択できるオプションを提供します。 仮想コア ベースの購入モデルでは、個々のリソース使用量において柔軟性、管理性、透明性が実現されており、オンプレミスのワークロード要件をクラウドに容易に移行する方法を提供しています。 このモデルでは、価格を最適化し、ワークロードの必要性に基づいて、コンピューティング、メモリ、ストレージのリソースを選択できます。
仮想コアベースの購入モデルでは、次のものの選択と使用量によってコストが異なります。
- サービス レベル
- ハードウェア構成
- コンピューティング リソース (仮想コアの数とメモリの量)
- 予約済みのデータベース ストレージ
- 実際のバックアップ ストレージ
重要
コンピューティング リソース、I/O、データとログのストレージは、データベースまたはエラスティック プールごとに課金されます。 バックアップ ストレージはデータベースごとに課金されます。 価格設定の詳細については、Azure SQL Database の価格に関するページを参照してください。
仮想コアと DTU の購入モデルの比較
Azure SQL Database によって使用される仮想コア購入モデルには、DTU ベースの購入モデルに比べていくつかのベネフィットがあります。
- コンピューティング、メモリ、I/O、およびストレージの上限が高くなります。
- ワークロードのコンピューティング要件とメモリ要件をより満たすようにハードウェア構成を選択します。
- Azure ハイブリッド特典 (AHB) の料金割引があります。
- コンピューティングを強化するハードウェア詳細における透明性の向上。それが、オンプレミスのデプロイからの移行計画を容易にします。
- 予約インスタンスの価格は、仮想コア購入モデルでのみ使用できます。
- スケーリング粒度が向上し、複数のコンピューティング サイズを利用できます。
仮想コアと DTU の購入モデルの選択については、仮想コアと DTU ベースの購入モデルの違いに関する記事を参照してください
Compute
仮想コアベースの購入モデルには、プロビジョニングされたコンピューティング レベルとサーバーレス コンピューティング レベルがあります。 プロビジョニングされたコンピューティング レベルでは、ワークロード アクティビティとは別に、アプリケーションに対して継続的にプロビジョニングされたコンピューティング容量の合計がコンピューティング コストに反映されます。 仮想コアとメモリの要件に基づいてビジネス ニーズに最適なリソース割り当てを選択し、ワークロードの必要に応じてリソースをスケールアップまたはスケールダウンします。 Azure SQL Database のサーバーレス コンピューティング レベルでは、コンピューティング リソースはワークロード容量に基づいて自動スケーリングされ、1 秒あたりのコンピューティング使用量に対して課金されます。
まとめ
- プロビジョニング済みコンピューティング レベルでは、ワークロード アクティビティとは関係なく継続的にプロビジョニングされる特定の量のコンピューティング リソースが提供されるのに対し、サーバーレス コンピューティング レベルでは、ワークロード アクティビティに基づいてコンピューティング リソースが自動スケーリングされます。
- プロビジョニングされたコンピューティング層は、1 時間あたりの固定価格でプロビジョニングされたコンピューティングの量に対して請求しますが、サーバーレス コンピューティング層は、1 秒あたりのコンピューティング使用量に対して請求されます。
コンピューティング レベルに関係なく、障害と高速フェールオーバーに対する高い回復性を提供するため、Business Critical サービス レベルでは 3 つの追加の高可用性セカンダリ レプリカが自動的に割り当てられます。 これらの追加レプリカにより、コストは General Purpose サービス レベルより約 2.7 倍高くなります。 同様に、Business Critical サービス レベルでは GB あたりのストレージ コストも高く、ローカル SSD ストレージの高い IO 制限と低待機時間が反映されています。
Hyperscale では、お客様が追加の高可用性レプリカの数を 0 から 4 の間で制御することで、コストを抑えながら、アプリケーションに必要な回復性のレベルを実現します。
Azure SQL Database でのコンピューティングの詳細については、「コンピューティング リソース (CPU とメモリ)」を参照してください。
リソース制限
仮想コアのリソースの制限については、使用可能なハードウェア構成を確認してから、次のリソース制限を確認してください。
データとログのストレージ
次の要因は、データ ファイルとログ ファイルに使用されるストレージの量に影響し、General Purpose レベルと Business Critical レベルに適用されます。
- 各コンピューティング サイズは、構成可能な最大データ サイズをサポートし、既定値は 32 GB です。
- 最大データ サイズを構成すると、請求対象ストレージの 30% に相当する量が、ログ ファイル用として自動的に追加されます。
- General Purpose サービス レベルでは、
tempdbによってローカル SSD が使用され、このストレージ コストは、仮想コアの価格に含まれます。 - Business Critical サービス レベルでは、
tempdbによって、データ ファイルやログ ファイルとローカル SSD が共有され、tempdbのストレージ コストは、仮想コアの価格に含まれます。 - General Purpose と Business Critical のレベルでは、データベースまたはエラスティック プール用に構成された最大ストレージ サイズに対して課金されます。
- SQL Database では、1 GB からサポートされているストレージ サイズの最大値まで、1 GB単位で任意の最大データ サイズを選択できます。
Hyperscale には、次のストレージに関する考慮事項が適用されます。
- データ ストレージの最大サイズは 100 TB に設定され、構成することはできません。
- 最大データ ストレージではなく、割り当てられたデータ ストレージに対してのみ課金されます。
- ログ ストレージには課金されません。
tempdbはローカル SSD ストレージを使用し、そのコストは仮想コアの価格に含まれています。 SQL Database で現在割り当てられ、使用されているデータ ストレージのサイズを監視するには、allocated_data_storage と ストレージの Azure Monitor メトリックをそれぞれ使用します。
T-SQL を使用して、データベース内の個々のデータ ファイルとログ ファイルの現在割り当てられ、使用されているストレージ サイズを監視するには、sys.database_files ビューと FILEPROPERTY(... , 'SpaceUsed') 関数を使用します。
ヒント
場合によっては、未使用領域を再利用できるようにデータベースを縮小する必要があります。 詳細については、「Manage file space in Azure SQL Database」(Azure SQL Database でファイル領域を管理する) を参照してください。
バックアップ ストレージ
データベース バックアップ用のストレージは、SQL Database のポイントインタイム リストア (PITR) および長期保有 (LTR) の機能をサポートするために割り当てられます。 このストレージは、データファイルとログファイルのストレージとは別に、別途請求されます。
- PITR: General Purpose レベルと Business Critical レベルでは、個々のデータベース バックアップは、Azure ストレージに自動的にコピーされます。 ストレージ サイズは、新しいバックアップが作成されるにつれて、動的に増大します。 ストレージは、完全バックアップ、差分バックアップ、およびトランザクション ログ バックアップで使われます。 ストレージの使用量は、データベースの変化率とバックアップに構成された保有期間に応じて異なります。 保有期間の範囲は、SQL Database のデータベースごとに 1 ~ 35 日の間で別々に構成できます。 構成済みの最大データ サイズに等しいバックアップ ストレージ容量が、追加料金なしで提供されます。
- 長期保有期間 (LTR): 長期間の完全バックアップは、最長で 10 年間まで構成できます。 LTR ポリシーを設定した場合、これらのバックアップは、Azure Blob ストレージに自動的に格納されますが、バックアップがコピーされる頻度は制御できます。 さまざまなコンプライアンス要件を満たすために、毎週、毎月、毎年のバックアップに対して異なるリテンション期間を選択することができます。 選択した構成によって、LTR バックアップに使われるストレージの量が決まります。 詳細については、「Long-term backup retention」(長期バックアップ リテンション) をご覧ください。
Hyperscale のバックアップ ストレージについては、「Hyperscale データベースの自動バックアップ」を参照してください。
サービス階層
仮想コア購入モデルのサービス レベルのオプションには、General Purpose、Business Critical、Hyperscale があります。 一般に、サービス レベルによって、ストレージの種類とパフォーマンス、高可用性とディザスター リカバリーのオプション、インメモリ OLTP などの特定の機能の可用性が決まります。
| ユース ケース | 汎用 | Business Critical | Hyperscale |
|---|---|---|---|
| 最適な用途 | ほとんどのビジネス ワークロード。 予算重視で、バランスのとれた、スケーラブルなコンピューティングおよびストレージ オプションを提供します。 | 複数の高可用性セカンダリ レプリカを使用して、障害に対する最大の回復性をビジネス アプリケーションに提供し、最大の I/O パフォーマンスを実現します。 | 高度にスケーラブルなストレージと読み取りスケールの要件を持つワークロードなど、さまざまなワークロードがあります。 複数の高可用性セカンダリ レプリカを構成できるようにして、障害に対するより高い回復性を提供します。 |
| コンピューティング サイズ | 2 - 128 の仮想コア | 2 - 128 の仮想コア | 2 - 128 の仮想コア |
| ストレージの種類 | Premium リモート ストレージ (インスタンスあたり) | 超高速ローカル SSD ストレージ (インスタンスあたり) | ローカル SSD キャッシュを使用して切り離されたストレージ (コンピューティング レプリカごと) |
| ストレージ サイズ | 1 GB – 4 TB | 1 GB – 4 TB | 10 GB – 100 TB |
| IOPS | 仮想コアあたり 320 IOPS (最大 16,000 IOPS) | 仮想コアあたり 4,000 IOPS (最大 327,680 IOPS) | 最大ローカル SSD で 327,680 IOPS Hyperscale は、複数のレベルのキャッシュが存在する複数レベル アーキテクチャです。 実際の IOPS はワークロードによって異なります。 |
| 仮想コアあたりのメモリ | 5.1 GB | 5.1 GB | 5.1 GB または 10.2 GB |
| バックアップ | geo 冗長、ゾーン冗長、ローカル冗長のバックアップストレージの選択肢、1 〜 35 日の保持期間(既定では 7 日) 最長 10 年間の長期保有期間 |
geo 冗長、ゾーン冗長、ローカル冗長のバックアップストレージの選択肢、1 〜 35 日の保持期間(既定では 7 日) 最長 10 年間の長期保有期間 |
ローカル冗長(LRS)、ゾーン冗長(ZRS)、geo 冗長(GRS)ストレージの選択肢 1 から 35 日 (既定では 7 日間) のデータ保有、最大 10 年間の長期保有が可能 |
| 可用性 | 1 レプリカ、読み取りスケールのレプリカなし、 ゾーン冗長高可用性 (HA) |
3 レプリカ、1 読み取りスケール レプリカ、 ゾーン冗長高可用性 (HA) |
ゾーン冗長高可用性 (HA) |
| 価格/課金 | 仮想コア、予約ストレージ、バックアップ ストレージに対して請求されます。 IOPS は課金されません。 |
仮想コア、予約ストレージ、バックアップ ストレージに対して請求されます。 IOPS は課金されません。 |
レプリカごとの仮想コアと使用されたストレージに対して請求されます。 IOPS は課金されません。 |
| 割引モデル | 予約インスタンス Azure ハイブリッド特典 (開発テスト サブスクリプションでは利用不可) Enterprise および Pay-As-You-Go (従量課金制) Dev/Test (開発テスト) サブスクリプション |
予約インスタンス Azure ハイブリッド特典 (開発テスト サブスクリプションでは利用不可) Enterprise および Pay-As-You-Go (従量課金制) Dev/Test (開発テスト) サブスクリプション |
Azure ハイブリッド特典 (Dev/Test サブスクリプションでは利用不可)1 Enterprise および Pay-As-You-Go (従量課金制) Dev/Test (開発テスト) サブスクリプション |
1 SQL Database Hyperscale の簡略化された価格は近日公開予定です。 詳細については、Hyperscale の価格に関するブログを参照してください。
詳細については、論理サーバー、単一データベース、プールされたデータベースのリソース制限に関するページを参照してください。
Note
サービス レベル アグリーメント (SLA) の詳細については、「Azure SQL Database の SLA」を参照してください。
General Purpose
General Purpose サービス レベルのアーキテクチャ モデルは、コンピューティングとストレージの分離に基づきます。 このアーキテクチャ モデルでは、データベース ファイルが透過的にレプリケートされ、基盤となるインフラストラクチャで障害が発生した場合にデータ損失が発生しないことが保証されている Azure Blob Storage の高可用性と信頼性に依存しています。
次の図は、計算レイヤーとストレージ レイヤーが分離されている Standard アーキテクチャ モデルの 4 ノードを示しています。
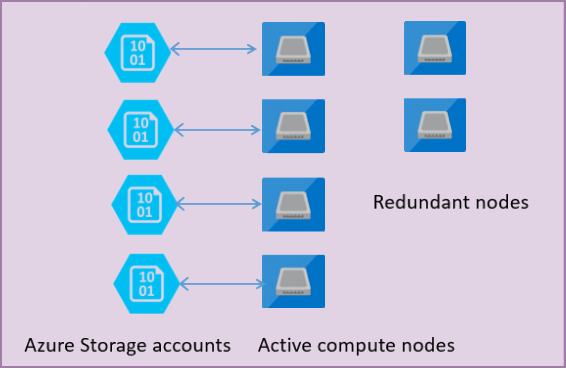
General Purpose サービス レベルのアーキテクチャ モデルには、2 つのレイヤーがあります。
- ステートレス計算レイヤー。
sqlservr.exeプロセスを実行しており、一時的なデータとキャッシュ データのみが含まれています (プラン キャッシュ、バッファー プール、列のストア プールなど)。 このステートレス ノードは、プロセスの初期化、ノードの正常性の制御、および他の場所へのフェールオーバーを必要に応じて実行する Azure Service Fabric によって操作されます。 - ステートフル データ レイヤー。データベース ファイル (.mdf/.ldf) は Azure Blob Storage に保存されています。 Azure Blob Storage では、すべてのデータベース ファイルに格納されたすべてのレコードでデータ損失が発生しないことが保証されています。 Azure Storage には、データの可用性と冗長性が組み込まれており、プロセスがクラッシュした場合でも、ログ ファイルのレコードやデータ ファイルのページがすべて確実に維持されます。
データベース エンジンまたはオペレーティング システムがアップグレードされるとき、基となるインフラストラクチャの一部で障害が発生した場合、または sqlservr.exe プロセスで重大な問題が検出された場合は常に、Azure Service Fabric によってステートレス プロセスが別のステートレス計算ノードに移動されます。 フェールオーバーの時間を最小限に抑えるため、プライマリ ノードのフェールオーバーが発生した場合に新しい計算サービスを実行できるよう待機している、一連の予備ノードがあります。 Azure のストレージ レイヤーのデータは影響を受けず、データとログのファイルは、新しく初期化されたプロセスにアタッチされます。 このプロセスでは、既定では 99.99% の可用性が保証され、ゾーン冗長が有効になっているときは 99.995% の可用性が保証されます。 移行時間や、新しいノードの起動にコールド キャッシュを使用することが原因で、処理中の大きなワークロードのパフォーマンスが影響を受ける可能性があります。
このサービス レベルを選択する場合
General Purpose サービス レベルは、ほとんどの一般的なワークロード向けに設計されている Azure SQL Database の既定のサービス レベルです。 既定の SLA が設定された、ストレージの待機時間が 5 ミリ秒から 10 ミリ秒のフル マネージド データベース エンジンが必要な場合は、General Purpose レベルをお勧めします。
Business Critical
Business Critical サービス レベル モデルは、データベース エンジン プロセスのクラスターに基づいています。 このアーキテクチャ モデルは、メンテナンス作業中でもワークロードに対するパフォーマンスの影響を最小限にするデータベース エンジン ノードのクォーラムに依存しています。 エンド ユーザーのダウンタイムを最小限に抑えて、基盤となるオペレーティング システム、ドライバー、データベース エンジンに対するアップグレードとパッチ適用が透過的に実行されます。
Business Critical モデルでは、コンピューティングとストレージが各ノードで統合されます。 高可用性は、4 つのノード クラスターの各ノード上のデータベース エンジン プロセス間でデータをレプリケーションし、ローカルに接続された SSD をデータ ストレージとして各ノードで使用することで達成されます。 次の図は、Business Critical サービス レベルが可用性グループ レプリカ内のデータベース エンジン ノードのクラスターを整理する方法を示しています。

データベース エンジン プロセスと基礎となる .mdf や .ldf のファイルはどちらも、ローカルに接続された SSD ストレージを備えた同じノードに配置され、ワークロードに低遅延を提供します。 高可用性は、SQL Server Always On 可用性グループと同様のテクノロジを使用して実装されます。 すべてのデータベースは、データベース ノードのクラスターになっています。1 つのプライマリ データベースは、顧客のワークロード用にアクセスすることができ、3 つのセカンダリ プロセスには、データのコピーが格納されています。 プライマリ レプリカは、変更内容を絶えずセカンダリ レプリカにプッシュしています。これは、何らかの原因でプライマリに障害が発生した場合でも、セカンダリ レプリカでデータを確実に使用できるようにするためです。 フェールオーバーは、Service Fabric とデータベース エンジンで処理されます。つまり、あるセカンダリ レプリカがプライマリになると、クラスター内のノード数を十分に確保するために、新しいセカンダリ レプリカが作成されます。 ワークロードは、新しいプライマリ レプリカに自動的にリダイレクトされます。
さらに、Business Critical クラスターには、プライマリ レプリカのワークロードのパフォーマンスに影響を与えない読み取り専用クエリ (レポートなど) を実行するために使用される無料の読み取り専用レプリカを提供する、読み取りスケールアウト機能が組み込まれています。
このサービス レベルを選択する場合
Business Critical サービス レベルの対象となるアプリケーションは、基盤となる SSD ストレージからの応答の待機時間が短い (平均 1 - 2 ミリ秒) か、基盤となるインフラストラクチャに障害が発生した場合に迅速に復旧するという要件があるか、またはレポート、分析、および読み取り専用のクエリをプライマリ データベースの無料で読み取り可能なセカンダリ レプリカにオフロードする必要があります。
General Purpose レベルではなく、Business Critical サービス レベルを選択すべき主な理由は、次のとおりです。
- 短い I/O 待機時間の要件。ストレージ レイヤーから継続して迅速な応答 (平均 1 - 2 ミリ秒) が必要なワークロードでは、Business Critical レベルを使用する必要があります。
- レポートと分析クエリを使用したワークロード。無料の読み取り専用のセカンダリ レプリカが 1 つあれば十分です。
- 障害からのより高い回復性とより早い復旧。 システムで障害が発生した場合、プライマリ インスタンス上のデータベースは無効になり、セカンダリ レプリカの 1 つがただちに新しい読み書きプライマリ データベースになって、クエリを処理できる状態になります。
- データの破損からの高度な保護。 Business Critical レベルのバックグラウンドではデータベース レプリカが使われているため、サービスはミラーリングと可用性グループで利用できる自動ページ修復を使って、データの破損を軽減します。 データの整合性の問題が原因で、レプリカがページを読み取ることができない場合、読み取り不可能なページは、データの損失や顧客のダウンタイムなしで、別のレプリカから新しいコピーが取得され、置き換えられます。 この機能は、データベースに geo セカンダリ レプリカがある場合、General Purpose レベルで使用できます。
- 高可用性 - マルチ可用性ゾーン構成内の Business Critical レベルは、ゾーン障害に対する回復性と、高可用性 SLA を提供します。
- 高速 geo リカバリー - アクティブ geo レプリケーションが構成された Business Critical レベルでは、100% のデプロイ時間に対して、5 秒の回復ポイントの目標 (RPO) と 30 秒の回復時間の目標 (RTO) が保証されています。
Hyperscale
Hyperscale サービス レベルは、すべてのワークロードの種類に適しています。 そのクラウド ネイティブなアーキテクチャにより、従来および最新のさまざまなアプリケーションをサポートするための、独立してスケーラブルなコンピューティングとストレージが提供されます。 Hyperscale のコンピューティングとストレージのリソースは、General Purpose と Business Critical のレベルで使用可能なリソースを大幅に超えています。
詳細については、Azure SQL Database の Hyperscale サービス レベルを確認してください。
このサービス レベルを選択する場合
Hyperscale サービス レベルでは、クラウド データベースにおいて従来見られた実質的な制限の多くが取り除かれます。 他のほとんどのデータベースは 1 つのノードで使用可能なリソースによって制限されますが、Hyperscale サービス レベルのデータベースにはそのような制限はありません。 その柔軟なストレージ アーキテクチャにより、Hyperscale データベースは必要に応じて拡張し、使用したストレージ容量に対してのみ課金されます。
Hyperscale は、高度なスケーリング機能に加えて、大規模なデータベースだけでなく、あらゆるワークロードに最適なオプションです。 Hyperscale では、次のことが可能です。
- 高可用性レプリカの数を 0 から 4 の間で選択することで、コストを抑えながら、高い回復性と迅速な障害復旧を実現します。
- コンピューティングとストレージのゾーン冗長性を有効にすることで、高可用性がさらに向上します。
- データベースの頻繁にアクセスされる部分に対して低い I/O 待機時間 (平均 1 - 2 ミリ秒) を実現します。 小規模なデータベースの場合、これはデータベース全体に適用される場合があります。
- 名前付きレプリカを使用して、さまざまな読み取りスケールアウト シナリオが実装されます。
- 新しいノード上のローカル ストレージにデータがコピーされるのを待たずに、高速スケーリングを利用できます。
- 影響ゼロの継続的なデータベース バックアップと高速復元を享受できます。
- フェールオーバー グループと geo レプリケーションを使用して、ビジネス継続性の要件をサポートします。
ハードウェア構成
仮想コア モデルの一般的なハードウェア構成オプションには、標準シリーズ (Gen5)、Fsv2 シリーズ、DC シリーズがあります。 Hyperscale には、Premium シリーズと Premium シリーズのメモリ最適化ハードウェアのオプションも用意されています。 ハードウェア構成では、ワークロードのパフォーマンスに影響を与えるコンピューティングおよびメモリの制限とその他の特性を定義します。
Standard シリーズ (Gen5) などの特定のハードウェア構成では、「コンピューティング リソース (CPU とメモリ)」の説明に従って、複数の種類のプロセッサ (CPU) を使用することができます。 特定のデータベースまたはエラスティック プールは、同じ CPU の種類のハードウェア上に長時間 (通常は数か月間) 存在する傾向がありますが、データベースまたはプールが別の CPU の種類を使用するハードウェアに移動される可能性がある特定のイベントがあります。 たとえば、別のサービス目標にスケールアップまたはスケールダウンする場合、データ センターにある現在のインフラストラクチャがその容量制限に近づいている場合、または現在使用されているハードウェアが耐用年数終了により使用停止になる場合には、データベースまたはプールを移動できます。
一部のワークロードでは、別の CPU の種類に移行するとパフォーマンスが変わる可能性があります。 SQL Database では、CPU の種類が変化しても予測可能なワークロード パフォーマンスを提供し、パフォーマンスの変化を狭い帯域内に維持することを目的としてハードウェアを構成します。 ただし、SQL Database でのお客様のワークロードは多岐にわたり、新しい種類の CPU を利用できるようになるため、データベースまたはプールが異なる CPU の種類に移動した場合、パフォーマンスがはっきりわかるほど変化することがあります。
使用されている CPU の種類に関係なく、データベースまたはエラスティック プールのリソース制限は (コア数、メモリ、最大データ IOPS、最大ログ レート、最大同時ワーカー数など)、データベースが同じサービス目標にとどまっている限り同じままです。
コンピューティング リソース (CPU とメモリ)
次の表では、さまざまなハードウェア構成とコンピューティング レベルのコンピューティング リソースを比較しています。
| ハードウェア構成 | CPU | メモリ |
|---|---|---|
| Standard シリーズ (Gen5) | プロビジョニング済みコンピューティング - Intel® E5-2673 v4(Broadwell)2.3 GHz、Intel® SP-8160(Skylake)*、Intel® 8272CL(Cascade Lake)2.5 GHz*、Intel® Xeon® Platinum 8370C(Ice Lake)*、AMD EPYC 7763v(Milan)プロセッサ - 最大 128 個の仮想コアをプロビジョニング (ハイパースレッド) サーバーレス コンピューティング - Intel® E5-2673 v4(Broadwell)2.3 GHz、Intel® SP-8160(Skylake)*、Intel® 8272CL(Cascade Lake)2.5 GHz*、Intel® Xeon® Platinum 8370C(Ice Lake)*、AMD EPYC 7763v(Milan)プロセッサ - 最大 80 個の仮想コアを自動スケーリング (ハイパースレッド) - メモリと仮想コアの比率は、ワークロードの需要に基づくメモリと CPU の使用率に動的に適合し、仮想コアあたり最大 24 GB まで使用できます。 たとえば、あるワークロードは特定の時点で、240 GB のメモリと 10 個のみの仮想コアを使用し、それらに対して課金される場合があります。 |
プロビジョニング済みコンピューティング - 仮想コアあたり 5.1 GB - 最大 625 GB をプロビジョニング サーバーレス コンピューティング - 仮想コアあたり最大 24 GB を自動スケーリング - 最大 240 GB を自動スケーリング |
| Fsv2 シリーズ | - Intel® 8168 (Skylake) プロセッサ - すべての主要なターボ クロック速度 (3.4 GHz) と、最大 1 コアのターボ クロック速度 (3.7 GHz) を実現します。 - 最大 72 個の仮想コアをプロビジョニング (ハイパースレッド) |
- 仮想コアあたり 1.9 GB - 最大 136 GB をプロビジョニング |
| DC シリーズ | - Intel® Xeon® E-2288G プロセッサ - Intel Software Guard Extension (Intel SGX) を搭載 - 最大 8 個の仮想コアをプロビジョニングする (物理) |
仮想コアあたり 4.5 GB |
* 「sys.dm_user_db_resource_governance」の動的管理ビューでは、Intel® SP-8160(Skylake)プロセッサを使用するデータベースのハードウェア世代は Gen6、Intel® 8272CL(Cascade Lake)を使用するデータベースのハードウェア世代は Gen7、Intel® Xeon® Platinum 8370C(Ice Lake)または AMD® EPYC® 7763v(Milan)を使用したデータベースのハードウェア世代は Gen8 として表示されます。 特定のコンピューティング サイズとハードウェア構成では、リソースの制限は、CPU の種類 (Intel Broadwell、Skylake、Ice Lake、Cascade Lake、または AMD Milan) に関係なく同じです。
詳細については、単一データベースおよびエラスティック プールのリソース制限に関するページをご覧ください。
Hyperscale データベースのコンピューティング リソースと仕様については、Hyperscale コンピューティング リソースに関するページをご覧ください。
Standard シリーズ (Gen5)
- Standard シリーズ (Gen5) ハードウェアは、バランスの取れたコンピューティングおよびメモリ リソースを提供し、ほとんどのデータベース ワークロードに適しています。
Standard シリーズ (Gen5) のハードウェアは、世界中のすべてのパブリック リージョンで利用できます。
Hyperscale Premium シリーズ
- Premium シリーズのハードウェア オプションでは、Intel と AMD の最新の CPU とメモリ テクノロジが使われます。 Premium シリーズは、Standard シリーズ ハードウェアに比べてコンピューティング パフォーマンスを向上させます。
- Premium シリーズ オプションを使用すると、Standard シリーズと比較して CPU パフォーマンスが向上し、仮想コアの最大数が多くなります。
- Premium シリーズのメモリ最適化オプションにより、Standard シリーズと比べて 2 倍のメモリ量が提供されます。
- Hyperscale エラスティック プール (プレビュー) では、Standard シリーズ、Premium シリーズ、Premium シリーズのメモリ最適化を利用できます。
詳細については、Hyperscale Premium シリーズのブログのお知らせをご覧ください。
利用できるリージョンについては、Hyperscale Premium シリーズの利用可能状況に関するセクションをご覧ください。
Fsv2 シリーズ
- Fsv2 シリーズは、CPU を大量に要求するワークロードに対して、CPU の低待機時間と高クロック速度を実現するコンピューティング最適化のハードウェア構成です。 Hyperscale Premium シリーズのハードウェア構成と同様に、Fsv2 シリーズには Intel と AMD の最新の CPU とメモリ テクノロジが搭載されており、お客様は General Purpose サービス レベルのデータベースとエラスティック プールを使いながら、最新のハードウェアを利用できます。
- ワークロードによっては、Fsv2 シリーズは他の種類のハードウェアよりも仮想コアあたりの CPU パフォーマンスを向上させることができます。 たとえば、72 仮想コアの Fsv2 コンピューティング サイズは、Standard シリーズ (Gen5) の 80 仮想コアよりも高い CPU パフォーマンスを、より低コストで実現できます。
- Fsv2 を使用すると、他のハードウェアよりも仮想コアあたりのメモリと
tempdbが少なくなります。そのため、これらの制限の影響を受けるワークロードでは、標準シリーズ (Gen5) シリーズでパフォーマンスが向上する場合があります。
Fsv2 シリーズは、General Purpose レベルでのみサポートされています。 Fsv2 シリーズが利用可能なリージョンについては、Fsv2 シリーズの可用性に関するセクションを参照してください。
DC シリーズ
- DC シリーズのハードウェアでは、Software Guard Extensions (Intel SGX) テクノロジを搭載した Intel プロセッサが使用されています。
- DC シリーズは、エンクレーブで Always Encrypted のワークロードに必要であり、仮想化ベースのセキュリティ(VBS)エンクレーブと比較して、ハードウェアエンクレーブの強力なセキュリティ保護を必要とします。
- DC シリーズは、セキュリティで保護されたエンクレーブが設定された Always Encrypted によって提供される、機密データを処理して機密クエリ処理機能を必要とするワークロード用に設計されています。
- DC シリーズのハードウェアでは、バランスの取れたコンピューティングおよびメモリ リソースが提供されます。
DC シリーズは、プロビジョニング済みコンピューティングでのみサポートされており (サーバーレスはサポートされていません)、ゾーン冗長性はサポートしていません。 DC シリーズが利用可能なリージョンについては、DC シリーズの可用性に関するセクションを参照してください。
DC シリーズでサポートされている Azure オファーの種類
DC シリーズのハードウェアでデータベースまたはエラスティック プールを作成するには、サブスクリプションの種類を、従量課金制やマイクロソフト エンタープライズ契約 (EA) を含む有料のオファーにする必要があります。 DC シリーズでサポートされている Azure オファーの種類の一覧については、使用制限のない現在のオファーを参照してください。
ハードウェア構成を選択
作成時に、SQL Database のデータベースまたはエラスティック プールのハードウェア構成を選択できます。 既存のデータベースまたはエラスティック プールのハードウェア構成を変更することもできます。
SQL Database またはプールを作成するときにハードウェア構成を選択するには
詳細については、SQL Database の作成に関するページを参照してください。
[基本] タブで、 [Compute + storage](コンピューティングとストレージ) セクションの [データベースの構成] リンクを選択し、 [構成の変更] リンクを選択します。
![Azure portal の [構成] ページの SQL Database 展開の作成を示すスクリーンショット。[構成の変更] ボタンが強調表示されています。](media/service-tiers-vcore/configure-sql-database.png?view=azuresql#lightbox)
目的のハードウェア構成を選択します。
![Azure SQL データベース の [SQL ハードウェア設定] ページが表示されている Azure portal のスクリーンショット。](media/service-tiers-vcore/select-hardware.png?view=azuresql#lightbox)
既存の SQL Database またはプールのハードウェア構成を変更するには
データベースの場合は、[概要] ページで、 [価格レベル] リンクを選択します。
![[概要] ページに Azure SQL データベース が表示されている Azure portal のスクリーンショット。価格レベル 「General Purpose: Standard シリーズ (Gen5)、2 仮想コア」が強調表示されています。](media/service-tiers-vcore/change-hardware.png?view=azuresql#lightbox)
プールの場合は、[概要] ページで [構成] を選択します。
手順に従って構成を変更し、前の手順で説明したようにハードウェア構成を選択します。
ハードウェアの可用性
前世代ハードウェアについては、この記事で後述する前世代ハードウェアの可用性に関するセクションをご覧ください。
Standard シリーズ (Gen5)
Standard シリーズ (Gen5) のハードウェアは、世界中のすべてのパブリック リージョンで利用できます。
Hyperscale Premium シリーズ
Hyperscale サービス レベルの Premium シリーズと Premium シリーズ メモリ最適化ハードウェアは、次のリージョンの単一データベースとエラスティック プールで利用できます。
- オーストラリア東部 **
- Australia Southeast
- ブラジル南部
- カナダ中部 **
- カナダ東部
- 東アジア
- 北ヨーロッパ **
- 西ヨーロッパ **
- フランス中部
- ドイツ中西部
- インド中部
- インド南部
- 東日本
- 西日本
- 東南アジア
- スイス北部
- 英国南部 **
- 英国西部*
- 米国中部 **
- 米国東部 **
- 米国東部 2
- 米国中北部
- 米国中南部
- 米国中西部
- 米国西部 1
- 米国西部 2 **
- 米国西部 3 **
* Premium シリーズのメモリ最適化ハードウェアは現在使用できません。
** ゾーン冗長のサポートが含まれています。
Fsv2 シリーズ
Fsv2 シリーズは、次のリージョンで使用できます:
- オーストラリア中部
- オーストラリア中部 2
- オーストラリア東部
- オーストラリア南東部
- ブラジル南部
- カナダ中部
- 東アジア
- 北ヨーロッパ
- 西ヨーロッパ
- フランス中部
- インド中部
- 韓国中部
- 韓国南部
- 南アフリカ北部
- 東南アジア
- 英国南部
- 英国西部
- 米国東部
- 米国西部 2
DC シリーズ
DC シリーズは、次のリージョンで使用できます:
- カナダ中部
- 西ヨーロッパ
- 北ヨーロッパ
- 東南アジア
- 英国南部
- 米国西部
- 米国東部
現在はサポートされていないリージョンで DC シリーズが必要な場合は、サポート リクエスト チケットを送信してください。 [基本] ページで、以下を設定します。
- [問題の種類] で、 [技術] を選択します。
- ハードウェアの目的のサブスクリプションを指定します。 [次へ] を選択します。
- [サービスの種類] で、 [SQL データベース] を選択します。
- [リソース] で、[一般的な質問] を選択します。
- [概要] には、目的のハードウェアの可用性とリージョンを指定します。
- [問題の種類] で、 [セキュリティ、プライバシー、およびコンプライアンス] を選択します。
- [問題のサブタイプ] で [Always Encrypted] を選択します。

前世代ハードウェア
Gen4
Gen4 ハードウェアは廃止されているため、プロビジョニング、アップスケーリング、ダウンスケーリングには使用できません。 サポートされているハードウェア世代にデータベースを移行すると、広範な仮想コアとストレージのスケーラビリティ、高速ネットワーク、最高の IO パフォーマンス、最小待機時間が実現します。 単一データベースのハードウェア オプションとエラスティック プールのハードウェア オプションを確認します。 詳細については、「Azure SQL Database での Gen 4 ハードウェアのサポートが終了しました」を参照してください。
次のステップ
関連するコンテンツ
フィードバック
以下は間もなく提供いたします。2024 年を通じて、コンテンツのフィードバック メカニズムとして GitHub の issue を段階的に廃止し、新しいフィードバック システムに置き換えます。 詳細については、「https://aka.ms/ContentUserFeedback」を参照してください。
フィードバックの送信と表示