複数言語のコンテンツを自動的に識別および文字起こしする
重要
Azure Media Services の 提供終了の発表により、Azure AI Video Indexer は Azure AI Video Indexer の 機能の調整を発表します。 Azure AI Video Indexer アカウントの意味を理解するには、Azure Media Service (AMS) の提供終了に関連する変更に関するページを参照してください。 AMS 提供 終了の準備: VI の更新と移行に関するガイドを参照してください。
Azure AI Video Indexer では、複数言語のコンテンツ内の自動的な言語識別と文字起こしがサポートされています。 このプロセスでは、音声から異なるセグメントにある音声言語を自動的に識別し、メディア ファイルの各セグメントを送信して文字起こしし、文字起こしを結合して元の 1 つの統合された文字起こしを作成する必要があります。
ポータルを使用してインデックス作成時に多言語識別を選択
ビデオをアップロードしてインデックスを作成するときに、複数言語の検出を選択することができます。 または、ビデオのインデックスを再作成するときに、複数言語の検出を選択することもできます。 次の手順では、インデックスを再作成する方法について説明します。
Azure AI Video Indexer の Web サイトに移動してサインインします。
[ライブラリ] ページに移動し、インデックスを再作成するビデオの名前にカーソルを合わせます。
右下隅にある [ビデオのインデックスを再作成] ボタンを選択します。
[ビデオのインデックスの再作成] ダイアログで、[ビデオのソース言語] ドロップダウン ボックスから [複数言語の検出] を選択します。
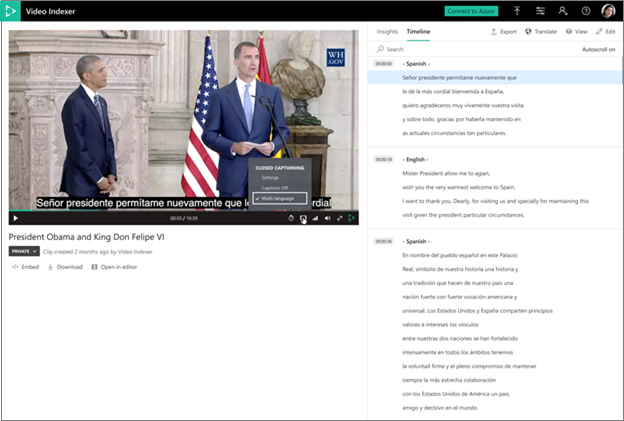
- ビデオが複数言語としてインデックス付けされている場合、ユーザーはどのセグメントがどの言語で文字起こしされているかを表示します。
- すべての言語への翻訳は、複数言語のトランスクリプトから完全に利用できます。
- 他のすべての分析情報は、オーディオで最も多く検出された言語で表示されます。
- プレーヤー上のクローズド キャプションも、複数言語で利用できます。
API を使用してインデックス作成時に多言語識別を選択
API を使用してビデオのインデックスを作成するとき、またはインデックスを再作成するときは、sourceLanguage パラメーターで multi-language detection オプションを選択します。
モデルの出力
モデルは、ビデオで検出されたすべての言語を 1 つのリストで取得します
"sourceLanguage": null,
"sourceLanguages": [
"es-ES",
"en-US"
],
さらに、文字起こしセクションの各インスタンスには、文字起こしされた言語が含まれています
{
"id": 136,
"text": "I remember well when my youth Minister took me to hear Doctor King I was a teenager.",
"confidence": 0.9343,
"speakerId": 1,
"language": "en-US",
"instances": [
{
"adjustedStart": "0:21:10.42",
"adjustedEnd": "0:21:17.48",
"start": "0:21:10.42",
"end": "0:21:17.48"
}
]
},
ガイドラインと制限
- 選択した言語以外の言語を含むオーディオでは、予期しない結果が生成されます。
- 各言語を検出するための最小セグメント長は 15 秒です。
- 言語検出オフセットは、平均で 3 秒です。
- 音声は継続的であることが期待されます。 言語間の頻繁な代替は、モデルのパフォーマンスに影響する可能性があります。
- 非ネイティブ スピーカーの音声は、モデルのパフォーマンスに影響する可能性があります (たとえば、話者が第 1 言語を使用し、別の言語に切り替える場合など)。
- このモデルは、(音声コマンドや歌声などではなく) 妥当な音声音響で自然な会話音声を認識するように設計されています。
- プロジェクトの作成と編集は、複数言語のビデオでは使用できません。
- 複数言語の検出を使用する場合、カスタム言語モデルは使用できません。
- キーワード (keyword)の追加はサポートされていません。
- 言語表示は、エクスポートされた閉じたキャプション ファイルには含まれません。
- API の更新トランスクリプトは、複数の言語ファイルをサポートしていません。
フィードバック
以下は間もなく提供いたします。2024 年を通じて、コンテンツのフィードバック メカニズムとして GitHub の issue を段階的に廃止し、新しいフィードバック システムに置き換えます。 詳細については、「https://aka.ms/ContentUserFeedback」を参照してください。
フィードバックの送信と表示