チュートリアル:Python API を使用して Azure Batch で並列ワークロードを実行する
Azure Batch を使用すると、大規模な並列コンピューティングやハイパフォーマンス コンピューティング (HPC) のバッチ ジョブを Azure で効率的に実行することができます。 このチュートリアルでは、Batch を使用して並列ワークロードを実行する Python の例を紹介します。 一般的な Batch アプリケーション ワークフローのほか、Batch および Storage のリソースをプログラムで操作する方法を学習します。
- Batch アカウントおよびストレージ アカウントで認証します。
- Storage に入力ファイルをアップロードします。
- アプリケーションを実行するコンピューティング ノードのプールを作成します。
- 入力ファイルを処理するジョブとタスクを作成します。
- タスクの実行を監視する。
- 出力ファイルを取得します。
このチュートリアルでは、ffmpeg オープンソース ツールを使用して複数の MP4 メディア ファイルを並行して MP3 形式に変換します。
Azure サブスクリプションをお持ちでない場合は、開始する前に Azure 無料アカウントを作成してください。
前提条件
Azure Batch アカウントおよびリンクされた Azure ストレージ アカウント。 これらのアカウントを作成するには、Azure Portal または Azure CLI 用の Batch クイック スタート ガイドを参照してください。
Azure へのサインイン
Azure portal にサインインします。
アカウントの資格情報を取得する
この例では、Batch アカウントと Storage アカウントの資格情報を指定する必要があります。 Azure Portal を使用すると、必要な資格情報を簡単に取得できます (Azure API やコマンドライン ツールを使用してこれらの資格情報を取得することもできます)。
[すべてのサービス]>[Batch アカウント] の順に選択し、Batch アカウントの名前を選択します。
Batch 資格情報を表示するには、 [キー] を選択します。 [Batch アカウント] 、 [URL] 、 [プライマリ アクセス キー] の値をテキスト エディターにコピーします。
Storage アカウント名とキーを表示するには、 [ストレージ アカウント] を選択します。 [ストレージ アカウント名] と [Key1] の値をテキスト エディターにコピーします。
サンプル アプリケーションのダウンロードと実行
サンプル アプリ をダウンロードする
GitHub からサンプル アプリをダウンロードまたは複製します。 Git クライアントを使用してサンプル アプリ リポジトリを複製するには、次のコマンドを使用します。
git clone https://github.com/Azure-Samples/batch-python-ffmpeg-tutorial.git
batch_python_tutorial_ffmpeg.py ファイルが含まれているディレクトリに移動します。
ご利用の Python 環境で、pip を使用して必要なパッケージをインストールします。
pip install -r requirements.txt
コード エディターを使用して、ファイル config.py を開きます。 Batch アカウントとストレージ アカウントの資格情報文字列を、アカウントに固有の値で更新します。 次に例を示します。
_BATCH_ACCOUNT_NAME = 'yourbatchaccount'
_BATCH_ACCOUNT_KEY = 'xxxxxxxxxxxxxxxxE+yXrRvJAqT9BlXwwo1CwF+SwAYOxxxxxxxxxxxxxxxx43pXi/gdiATkvbpLRl3x14pcEQ=='
_BATCH_ACCOUNT_URL = 'https://yourbatchaccount.yourbatchregion.batch.azure.com'
_STORAGE_ACCOUNT_NAME = 'mystorageaccount'
_STORAGE_ACCOUNT_KEY = 'xxxxxxxxxxxxxxxxy4/xxxxxxxxxxxxxxxxfwpbIC5aAWA8wDu+AFXZB827Mt9lybZB1nUcQbQiUrkPtilK5BQ=='
アプリを実行する
スクリプトを実行するには、次の手順を実行します。
python batch_python_tutorial_ffmpeg.py
サンプル アプリケーションを実行すると、コンソールの出力は次のようになります。 実行中、プールのコンピューティング ノードを開始する際に、Monitoring all tasks for 'Completed' state, timeout in 00:30:00... で一時停止が発生します。
Sample start: 11/28/2018 3:20:21 PM
Container [input] created.
Container [output] created.
Uploading file LowPriVMs-1.mp4 to container [input]...
Uploading file LowPriVMs-2.mp4 to container [input]...
Uploading file LowPriVMs-3.mp4 to container [input]...
Uploading file LowPriVMs-4.mp4 to container [input]...
Uploading file LowPriVMs-5.mp4 to container [input]...
Creating pool [LinuxFFmpegPool]...
Creating job [LinuxFFmpegJob]...
Adding 5 tasks to job [LinuxFFmpegJob]...
Monitoring all tasks for 'Completed' state, timeout in 00:30:00...
Success! All tasks completed successfully within the specified timeout period.
Deleting container [input]....
Sample end: 11/28/2018 3:29:36 PM
Elapsed time: 00:09:14.3418742
プール、コンピューティング ノード、ジョブ、タスクを監視するには、Azure Portal で Batch アカウントに移動します。 たとえば、プール内のコンピューティング ノードのヒート マップを確認するには、[プール]>[LinuxFFmpegPool] の順に選択します。
タスクが実行されていると、ヒート マップは次のようになります。
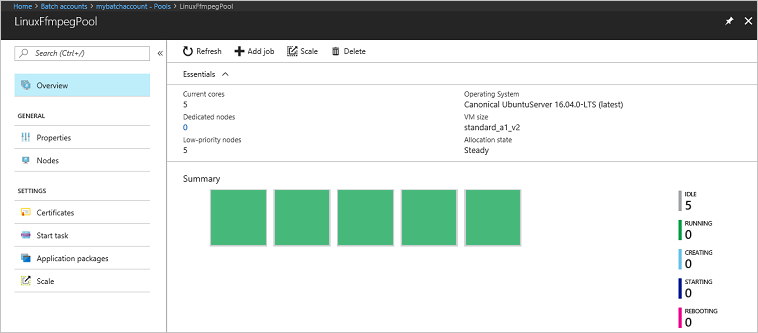
既定の構成でアプリケーションを実行する場合、通常の実行時間は約 5 分間です。 プールの作成に最も時間がかかります。
出力ファイルを取得する
Azure Portal を使用して、ffmpeg タスクによって生成された出力 MP3 ファイルをダウンロードすることができます。
- [すべてのサービス]>[ストレージ アカウント] の順にクリックし、ストレージ アカウントの名前をクリックします。
- [BLOB]>[出力] の順にクリックします。
- 出力 MP3 ファイルの 1 つを右クリックして、[ダウンロード] をクリックします。 ブラウザーのメッセージに従って、ファイルを開くか保存します。
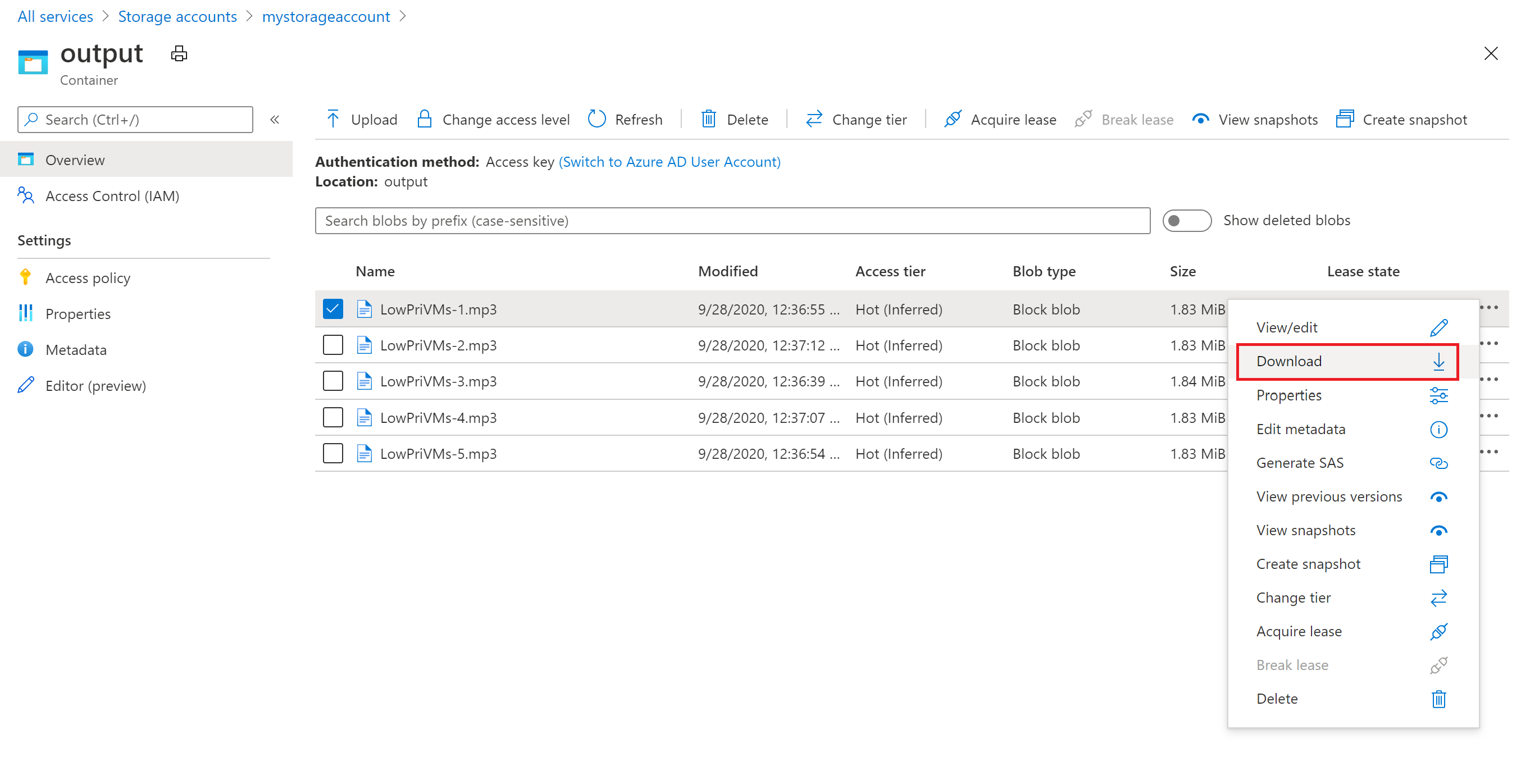
このサンプルには示されていませんが、コンピューティング ノードまたはストレージ コンテナーからプログラムでファイルをダウンロードすることもできます。
コードの確認
以降のセクションでは、サンプル アプリケーションを、Batch サービスでワークロードを処理するために実行する複数の手順に分けます。 サンプルのすべてのコード行について説明しているわけではないので、この記事の残りの部分を読む際は Python コードを参照してください。
BLOB クライアントと Batch クライアントの認証
ストレージ アカウントを操作するには、アプリで azure-storage-blob パッケージを使用して BlockBlobService オブジェクトを作成します。
blob_client = azureblob.BlockBlobService(
account_name=_STORAGE_ACCOUNT_NAME,
account_key=_STORAGE_ACCOUNT_KEY)
このアプリは BatchServiceClient オブジェクトを作成して、Batch サービスでプール、ジョブ、タスクを作成および管理します。 このサンプルの Batch クライアントでは共有キー認証を使用します。 Batch は、個々のユーザーまたは自動アプリケーションを認証するために、Microsoft Entra ID による認証もサポートしています。
credentials = batchauth.SharedKeyCredentials(_BATCH_ACCOUNT_NAME,
_BATCH_ACCOUNT_KEY)
batch_client = batch.BatchServiceClient(
credentials,
base_url=_BATCH_ACCOUNT_URL)
入力ファイルのアップロード
アプリは、blob_client 参照を使用して、入力 MP4 ファイル用のストレージ コンテナーとタスク出力用のコンテナーを作成します。 次に、upload_file_to_container 関数を呼び出し、ローカルの InputFiles ディレクトリ内の MP4 ファイルをコンテナーにアップロードします。 ストレージ内のファイルは、Batch の ResourceFile オブジェクトとして定義されており、Batch が後でコンピューティング ノードにダウンロードできます。
blob_client.create_container(input_container_name, fail_on_exist=False)
blob_client.create_container(output_container_name, fail_on_exist=False)
input_file_paths = []
for folder, subs, files in os.walk(os.path.join(sys.path[0], './InputFiles/')):
for filename in files:
if filename.endswith(".mp4"):
input_file_paths.append(os.path.abspath(
os.path.join(folder, filename)))
# Upload the input files. This is the collection of files that are to be processed by the tasks.
input_files = [
upload_file_to_container(blob_client, input_container_name, file_path)
for file_path in input_file_paths]
コンピューティング ノードのプールの作成
次に、create_pool が呼び出されて、コンピューティング ノードのプールが Batch アカウントに作成されます。 この定義済みの関数は、Batch の PoolAddParameter クラスを使用して、ノードの数、VM のサイズ、プールの構成を設定します。 ここでは、VirtualMachineConfiguration オブジェクトで ImageReference に、Azure Marketplace で公開されている Ubuntu Server 20.04 LTS イメージを指定します。 Batch は、Azure Marketplace のさまざまな VM イメージだけでなく、カスタム VM イメージもサポートしています。
ノードの数と VM のサイズは、定義済みの定数を使用して設定されます。 Batch では専用ノードとスポット ノードがサポートされているため、ご利用のプールではそのいずれかまたは両方を使用できます。 専用ノードは、プール用に予約されています。 スポット ノードは、Azure の VM の余剰容量から割引価格で提供されます。 スポット ノードは、Azure に十分な容量がない場合に使用できなくなります。 このサンプルは、既定で、サイズ Standard_A1_v2 のスポット ノードが 5 つだけ含まれているプールを作成します。
このプールの構成には、物理ノードのプロパティだけでなく、StartTask オブジェクトも含まれています。 各ノードがプールに参加するときと、ノードの再起動のたびに、各ノードで StartTask が実行されます。 この例では、StartTask は Bash シェル コマンドを実行して、ffmpeg パッケージと依存関係をノードにインストールします。
pool.add メソッドは、プールを Batch サービスを送信します。
new_pool = batch.models.PoolAddParameter(
id=pool_id,
virtual_machine_configuration=batchmodels.VirtualMachineConfiguration(
image_reference=batchmodels.ImageReference(
publisher="Canonical",
offer="UbuntuServer",
sku="20.04-LTS",
version="latest"
),
node_agent_sku_id="batch.node.ubuntu 20.04"),
vm_size=_POOL_VM_SIZE,
target_dedicated_nodes=_DEDICATED_POOL_NODE_COUNT,
target_low_priority_nodes=_LOW_PRIORITY_POOL_NODE_COUNT,
start_task=batchmodels.StartTask(
command_line="/bin/bash -c \"apt-get update && apt-get install -y ffmpeg\"",
wait_for_success=True,
user_identity=batchmodels.UserIdentity(
auto_user=batchmodels.AutoUserSpecification(
scope=batchmodels.AutoUserScope.pool,
elevation_level=batchmodels.ElevationLevel.admin)),
)
)
batch_service_client.pool.add(new_pool)
ジョブの作成
Batch ジョブでは、タスクの実行対象となるプールと、作業の優先順位やスケジュールなどのオプションの設定を指定します。 このサンプルでは、create_job の呼び出しを使用してジョブを作成します。 この定義済みの関数は、JobAddParameter クラスを使用して、プールにジョブを作成します。 job.add メソッドは、プールを Batch サービスに送信します。 最初、ジョブにはタスクがありません。
job = batch.models.JobAddParameter(
id=job_id,
pool_info=batch.models.PoolInformation(pool_id=pool_id))
batch_service_client.job.add(job)
タスクの作成
アプリは、add_tasks の呼び出しを使用してジョブにタスクを作成します。 この定義済みの関数は、TaskAddParameter クラスを使用して、タスク オブジェクトの一覧を作成します。 各タスクは、ffmpeg を実行して、command_line パラメーターを使用して入力の resource_files オブジェクトを処理します。 ffmpeg は、以前にプールが作成されたときに各ノードにインストールされています。 ここでは、コマンド ラインで ffmpeg を実行して、各入力 MP4 (ビデオ) ファイルを MP3 (オーディオ) ファイルに変換します。
このサンプルでは、コマンド ラインの実行後に MP3 ファイルの OutputFile オブジェクトを作成します。 各タスクの出力ファイル (この場合は 1 つ) は、タスクの output_files プロパティを使用して、リンクされているストレージ アカウントのコンテナーにアップロードされます。
その後、アプリは、task.add_collection メソッドを使用してジョブにタスクを追加します。これにより、タスクは、コンピューティング ノードで実行するためにキューに登録されます。
tasks = list()
for idx, input_file in enumerate(input_files):
input_file_path = input_file.file_path
output_file_path = "".join((input_file_path).split('.')[:-1]) + '.mp3'
command = "/bin/bash -c \"ffmpeg -i {} {} \"".format(
input_file_path, output_file_path)
tasks.append(batch.models.TaskAddParameter(
id='Task{}'.format(idx),
command_line=command,
resource_files=[input_file],
output_files=[batchmodels.OutputFile(
file_pattern=output_file_path,
destination=batchmodels.OutputFileDestination(
container=batchmodels.OutputFileBlobContainerDestination(
container_url=output_container_sas_url)),
upload_options=batchmodels.OutputFileUploadOptions(
upload_condition=batchmodels.OutputFileUploadCondition.task_success))]
)
)
batch_service_client.task.add_collection(job_id, tasks)
タスクの監視
タスクは、ジョブに追加されると、関連付けられたプール内のコンピューティング ノードで実行するために、Batch によって自動的にキューに登録され、スケジュールが設定されます。 指定した設定に基づいて、Batch は、タスクのキューへの登録、スケジュール設定、再試行など、タスク管理作業すべてを処理します。
タスクの実行を監視する方法は多数ありますが、 この例の wait_for_tasks_to_complete 関数は、TaskState オブジェクトを使用して、制限時間内で特定の状態 (この場合は完了した状態) についてタスクを監視します。
while datetime.datetime.now() < timeout_expiration:
print('.', end='')
sys.stdout.flush()
tasks = batch_service_client.task.list(job_id)
incomplete_tasks = [task for task in tasks if
task.state != batchmodels.TaskState.completed]
if not incomplete_tasks:
print()
return True
else:
time.sleep(1)
...
リソースをクリーンアップする
タスクの実行後、自動的に、作成された入力用ストレージ コンテナーが削除され、Batch プールとジョブを削除するためのオプションが表示されます。 BatchClient の JobOperations クラスと PoolOperations クラスの両方に削除メソッドがあります。このメソッドは、削除を確定すると呼び出されます。 ジョブとタスク自体は課金対象ではありませんが、コンピューティング ノードは課金対象です。 そのため、必要な場合にのみプールを割り当てることをお勧めします。 プールを削除すると、ノード上のタスク出力はすべて削除されます。 ただし、入力ファイルと出力ファイルはストレージ アカウントに残ります。
リソース グループ、Batch アカウント、ストレージ アカウントは、不要になったら削除します。 Azure portal でこれを行うには、Batch アカウントのリソース グループを選択し、[リソース グループの削除] を選択してください。
次の手順
このチュートリアルでは、以下の内容を学習しました。
- Batch アカウントおよびストレージ アカウントで認証します。
- Storage に入力ファイルをアップロードします。
- アプリケーションを実行するコンピューティング ノードのプールを作成します。
- 入力ファイルを処理するジョブとタスクを作成します。
- タスクの実行を監視する。
- 出力ファイルを取得します。
Python API を使用して Batch ワークロードのスケジュール設定と処理を行う他の例については、GitHub の Batch Python のサンプルを参照してください。