責任ある信頼された AI
Microsoft では、責任ある AI における 6 つの基本原則として、アカウンタビリティ、包括性、信頼性と安全性、公平性、透明性、プライバシーとセキュリティを挙げています。 これらの原則は、AI が主流な製品やサービスに活用されていく中で、責任があり、信頼できる AI を生み出すために不可欠です。 これらは、倫理と説明可能性という 2 つの視点から構成されています。

倫理
倫理の視点からは、AI は次のようであるべきです。
- 公平でインクルーシブなアサーションを持っている。
- 自身の決定に対して説明責任がある。
- 人種、障害、生い立ちの違いを差別したり阻害したりしない。
Microsoft は、2017 年にエンジニアリングと研究における AI、倫理、および影響に関する倫理委員会 (Aether) を設置しました。 この委員会の主な責任は、責任ある AI の問題、テクノロジ、プロセス、ベスト プラクティスについて、助言を行うことです。 詳しくは、「Microsoft のガバナンス モデルを理解する - AETHER + 責任ある AI オフィス」を参照してください。
アカウンタビリティ
アカウンタビリティは、責任ある AI の重要な柱です。 AI システムを設計して展開する担当者には、システムがより自律的に進歩している中では特に、その行動や決定に対するアカウンタビリティが求められます。
組織は、AI システムの開発と展開に関する監視、分析情報、およびガイダンスを提供する内部の審査機関を設置することを検討する必要があります。 このガイダンスは、会社や地域によって異なる場合がありますが、これには組織の AI ジャーニーを反映させるべきです。
包括性
インクルーシブネスにより、あらゆる人種と経験を考慮することが AI に義務付けられます。 インクルーシブ デザインの手法を用いることで、システム開発者が意図せずに人々を排除してしまう可能性のある潜在的な障壁を理解し、それに対処するのに役立ちます。 聴覚、視覚、およびその他の障碍を持つ人々を支援するため、組織は可能な限り、音声テキスト変換、テキスト読み上げ、および画像認識テクノロジを使用すべきです。
信頼性と安全性
AI システムが信頼されるためには、信頼性が高く安全である必要があります。 システムが本来設計されたとおりに動作し、新しい状況にも安全に対応できるようにすることが重要です。 独自の復元力により、意図的または意図しない操作を防ぐ必要があります。
組織は、システムがエッジ ケースに安全に対応できるように、動作条件に対する厳格なテストと検証を確立しなければなりません。 A/B テストとチャンピオン/チャレンジャー メソッドを評価プロセスに組み込むべきです。
AI システムのパフォーマンスは、時間の経過と共に低下する可能性があります。 組織は、モデルのパフォーマンスを事後および事前に測定 (そして、必要に応じて最新化のために再トレーニング) するための堅牢な監視とモデル追跡プロセスを確立する必要があります。
説明可能性
説明可能性は、データ サイエンティスト、監査担当者、およびビジネスの意思決定者が行った意思決定について、およびその結果にどのように到達したかを、AI システムによって正当化するのに役立ちます。 説明可能性は、会社のポリシー、業界標準、政府の規制へのコンプライアンスの確保にも役立ちます。
データ サイエンティストは、どのようにして一定レベルの精度を達成したのか、そして何がこの結果に影響を与えたのかを利害関係者に説明できなければなりません。 同様に、会社のポリシーに従うために、監査担当者にはこのモデルを検証するツールが必要です。 ビジネスの意思決定者は、透明性のあるモデルを提供することで信頼を得る必要があります。
説明可能性のためのツール
Microsoft は、モデルの説明可能性を実現するのに役立つオープンソースのツールキットである InterpretML を開発しました。 これは、グラスボックスとブラックボックスのモデルをサポートしています。
グラスボックス モデルは、その構造により解釈可能となっています。 このモデルについては、Explainable Boosting Machine (EBM) がデシジョン ツリーまたは線形モデルに基づくアルゴリズムの状態を提供します。 EBM は、無損失の説明を提供するものであり、領域専門家が編集できます。
ブラックボックス モデルの内部構造 (ニューラル ネットワーク) は複雑であるため、解釈が困難になっています。 LIME (local interpretable model-agnostic explanations) や SHapley Additive exPlanations (SHAP) のような Explainer は、入力と出力の関係を分析することで、これらのモデルの解釈を行っています。
Fairlearn は、SDK および AutoML グラフィカル ユーザー インターフェイス用のオープンソース ツールキットである Azure Machine Learning 統合です。 主に何がモデルに影響を与えるのかを理解するために Explainer を使用し、このような影響を検証するために領域専門家を使用します。
説明可能性の詳細については、Azure Machine Learning におけるモデルの解釈可能性に関するページを参照してください。
公平性
公平性は、すべての人間が理解し、適用することを目指す、核となる倫理原則です。 この原則は、AI システムの開発時にはさらに重要になります。 システムによる決定が、性別、人種、性的指向、宗教に基づいてグループまたは個人を差別したり、不公平な優遇を示したりすることがないように、主要なチェック アンド バランスが必要になります。
Microsoft では、AI システム向けのガイダンスとソリューションを提供する AI 公平性チェックリストを提供しています。 これらのソリューションは、構想、プロトタイプ、構築、始動、進化という 5 つのステージに大まかに分類されています。 ステージごとに、システムにおける不公平性の影響を最小限に抑えるために推奨されるデュー デリジェンス活動が一覧で示されています。
Fairlearn は、Azure Machine Learning と統合することで、データ サイエンティストや開発者が AI システムの公平性を評価、改善するために使用できます。 不公平性緩和アルゴリズムと、モデルの公平性を視覚化する対話型ダッシュボードが用意されています。 組織は、このツールキットを使用して、モデルの構築中にその公平性を詳しく評価することが推奨されます。 このアクティビティは、データ サイエンス プロセスの不可欠な部分となるものです。
機械学習モデルでの不公平性を軽減する方法については、こちらをご覧ください。
透明性
透明性を実現することで、チームが次のことを理解するのに役立ちます。
- モデルのトレーニングに使用されたデータとアルゴリズム。
- データに適用された変換ロジック。
- 生成された最終的なモデル。
- モデルに関連付けられている資産。
この情報により、モデルがどのように作成されたかについての分析情報が得られるため、チームは透明性の高い方法でそれを再現できるようになります。 Azure Machine Learning ワークスペース内のスナップショットでは、実験に関係するすべてのトレーニング関連の資産とメトリックを記録または再トレーニングすることで、透明性を実現しています。
プライバシーとセキュリティ
データ保有者は、AI システム内のデータを保護する義務があります。 プライバシーとセキュリティは、このシステムの不可欠な部分です。
個人データは、セキュリティで保護する必要があり、それに対するアクセスによって個人のプライバシーが損なわれるべきではありません。 Azure の差分プライバシーでは、データをランダム化し、ノイズを加えることで、データ サイエンティストから個人情報を隠し、プライバシーを保護および維持しています。
人間と AI のガイドライン
人間と AI の設計ガイドラインは、最初、対話中、間違っている場合、および経時的という 4 つの期間にわたって発生する 18 の原則で構成されています。 これらの原則は、よりインクルーシブで人間中心の AI システムを構築するのに役立ちます。
最初
システムで実行できることを明確にする。 その AI システムでメトリックを使用する、または生成する場合は、それらすべてと、その追跡方法を示すことが重要です。
システムが実行していることをどの程度うまく行えるかを明確にする。 AI が完璧に正確というわけではないことをユーザーが理解できるように支援します。 AI システムが間違いを犯す可能性がある場合の期待水準を設定します。
対話中
文脈に関連する情報を表示する。 近くのホテルなど、ユーザーの現在の状況と環境に関連する視覚的な情報を提供します。 目的地と日付に近い詳細を返します。
社会的バイアスを軽減する。 言葉や行動で、意図しないステレオタイプやバイアスを示唆しないようにします。 たとえば、オートコンプリート機能には、ジェンダー アイデンティティを含める必要があります。
間違っている場合
- 効率的に無視できるようにする。 望ましくない機能やサービスを無視したり、却下したりするための簡単なメカニズムを提供します。
- 効率的に訂正できるようにする。 編集、調整、または復旧を容易にするための直感的な方法を提供します。
- システムが行った特定の行動の理由を明確にする。 説明可能な AI を最適化し、AI システムの主張に関する分析情報を提供します。
経時的に
- 直近の対話を記憶する。 後で参照できるように、対話の履歴を保持します。
- ユーザーの行動から学習する。 ユーザーの行動に基づいて対話をカスタマイズします。
- 更新と適応は慎重に行う。 混乱を招くような変更は制限し、ユーザーのプロファイルに基づいて更新を行います。
- 詳細なフィードバックを奨励する。 AI システムとの対話からのユーザー フィードバックを収集します。
信頼できる AI フレームワーク
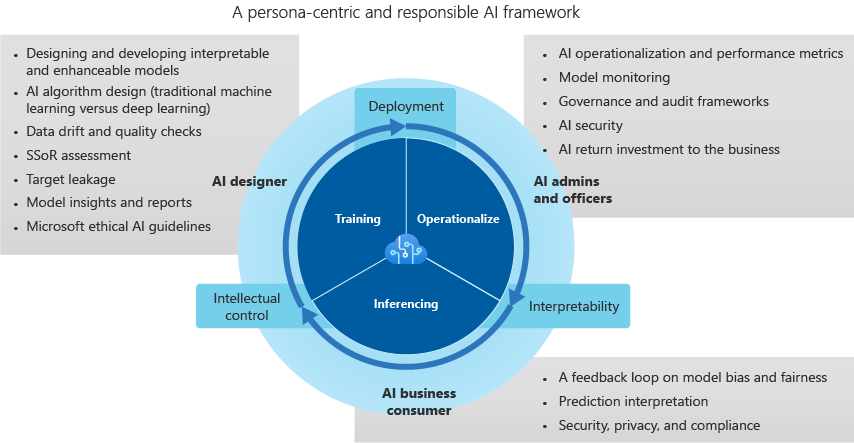
AI 設計者
AI 設計者は、モデルを構築し、以下を担当します。
データ ドリフトと品質チェック。 設計者は外れ値を検出し、データ品質チェックを実行して欠損値を特定します。 また、配布を標準化し、データを調査し、ユース ケースとプロジェクトのレポートを生成します。
システムのソースのデータを評価して、潜在的なバイアスを特定します。
データの偏りを最小限に抑えるための AI アルゴリズムの設計。 この作業には、ビン分割、グループ化、正規化 (特に、ツリーベースなどの従来の機械学習モデルにおいて) によってデータからどのようにしてマイノリティ グループが排除され得るのかを発見することが含まれます。 カテゴリ別の AI 設計では、業種内の保護医療情報 (PHI) や個人情報に依存する社会、人種、性別の分類をグループ化することで、データの偏りを再確認します。
監視とアラートを最適化して、ターゲットの漏れを特定し、モデルの開発を強化します。
モデルをより詳細に理解できるようにするレポートと分析情報のためのベスト プラクティスの確立。 設計者は、特徴量またはベクトルの重要度、均一多様体近似および投影 (UMAP) クラスタリング、フリードマンの H 統計量、特徴量の影響、および関連する手法を使用するブラックボックス的なアプローチを回避します。 ID メトリックを使用すると、複雑および最新のデータセットの予測的影響、関係、および相関関係間の依存関係を定義できます。
AI 管理者と責任者
AI 管理者と責任者は、AI、ガバナンス、監査フレームワークの運用とパフォーマンス メトリックを監視します。 また、AI セキュリティの実装方法と、ビジネスの投資収益率も監視します。 担当するタスクは次のとおりです。
モデルの監視を支援する追跡ダッシュボードを監視します。これには、実稼働モデルの複数のモデル メトリックが統合されています。 このダッシュボードは、精度、モデルの劣化、データ ドリフト、偏差、推論の速度と誤差の変化に焦点を合わせています。
モデルをオープンで依存性のないアーキテクチャとして実装できるようにする柔軟なデプロイと再デプロイ (REST API の使用を推奨) を実装します。 このアーキテクチャは、モデルをビジネス プロセスと統合し、フィードバック ループのための価値を生み出します。
モデルのガバナンスとアクセスの構築に取り組むことで、境界線を設定し、ビジネスおよび運用への悪影響を緩和します。 ロールベースのアクセス制御 (RBAC) の標準によってセキュリティ制御を定義し、これによって制限された運用環境と IP を保持します。
AI 監査とコンプライアンス フレームワークを使用して、業界独自の標準を維持するためにモデルがどのように開発、変化しているかを追跡します。 解釈可能で責任ある AI は、説明可能な手段、簡潔な機能、モデルの可視化、および業界特有の言語の上に成り立っています。
AI ビジネス コンシューマー
AI ビジネス コンシューマー (ビジネス エキスパート) は、フィードバック ループを閉じ、AI 設計者向けのインプットを提供します。 予測的な意思決定と、公平性や倫理的措置、プライバシーとコンプライアンス、ビジネスの効率性などの潜在的なバイアスの影響は、AI システムの評価に役立ちます。 ビジネス コンシューマーに関する考慮事項をこちらに示します。
フィードバック ループは、ビジネスのエコシステムの一部です。 モデルの偏り、誤差、予測速度、および公平性を示すデータは、AI 設計者、管理者、および責任者の間の信頼を生み出し、バランスを確立します。 人間中心の評価により、時間の経過と共に AI が徐々に改善されていきます。
多次元の複雑なデータからの AI 学習を最小限に抑えることで、偏りのある学習を防ぐことができます。 この手法は、ワンショット未満 (LO ショット) 学習と呼ばれます。
解釈可能性の設計とツールを使用することで、AI システムは潜在的なバイアスに対応できるようになります。 モデルの偏りと公平性の問題にフラグを立て、この動作から学習して偏りに自動的に対処するアラートおよび異常検出システムに渡す必要があります。
各予測値は、重要度や影響度に応じて個々の特徴またはベクトルに分類されます。 これは、監査やコンプライアンスのレビュー、顧客の透明性、ビジネスの準備態勢のためのビジネス レポートとしてエクスポート可能な詳細な予測の説明を提供できるものでなければなりません。
グローバルなセキュリティとプライバシーのリスクが増加しているため、推論中のデータ違反を解決するためのベスト プラクティスでは、各業界の規制に準拠している必要があります。 たとえば、PHI と個人データに関連するコンプライアンス違反に関するアラート、国/地域のセキュリティ法違反に関するアラートなどがあります。
次のステップ
責任ある AI の詳細については、人間と AI のガイドラインに関するページを参照してください。
フィードバック
以下は間もなく提供いたします。2024 年を通じて、コンテンツのフィードバック メカニズムとして GitHub の issue を段階的に廃止し、新しいフィードバック システムに置き換えます。 詳細については、「https://aka.ms/ContentUserFeedback」を参照してください。
フィードバックの送信と表示