方法: メトリック データを Metrics Advisor にオンボードする
重要
2023 年 9 月 20 日以降は、新しい Metrics Advisor リソースを作成できなくなります。 Metrics Advisor サービスは、2026 年 10 月 1 日に廃止されます。
この記事では、データを Metrics Advisor にオンボードする方法について説明します。
データ スキーマの要件と構成
Azure AI Metrics Advisor は、時系列の異常検出、診断、分析のためのサービスです。 AI を利用したサービスとして、ユーザーのデータを使用して、使用するモデルをトレーニングします。 このサービスは、次の列を含んだ集計データのテーブルを受け取ります。
- Measure (必須): メジャーは、単位固有の基本的な用語であり、メトリックの定量化可能な値です。 数値を格納する 1 つまたは複数の列を意味します。
- Timestamp (省略可): 型が
DateTimeまたはStringである、0 個または 1 個の列。 この列が設定されなかった場合は、タイムスタンプが各インジェスト期間の開始時刻として設定されます。 タイムスタンプをyyyy-MM-ddTHH:mm:ssZの形式で指定します。 - Dimension (省略可): ディメンションは、1 つまたは複数のカテゴリの値です。 これらの値を組み合わせることによって、特定の一変量時系列 (国やリージョン、言語、テナントなど) が識別されます。 ディメンション列のデータ型は任意です。 大量の列と値を扱う際は、処理の対象となるディメンションの数が多くなりすぎないように注意してください。
Azure Data Lake Storage や Azure Blob Storage などのデータ ソースを使用している場合は、予期されるメトリック スキーマに合わせてデータを集計できます。 これは、これらのデータ ソースがメトリック入力としてファイルを使用するためです。
Azure SQL や Azure Data Explorer などのデータ ソースを使用している場合は、集計関数を使用して、予期されるスキーマにデータを集計できます。 これは、これらのデータ ソースで、ソースからメトリック データを取得するためのクエリの実行がサポートされているためです。
一部の用語が分からない場合は、用語集を参照してください。
部分データの読み込みを回避する
部分データは、Metrics Advisor とデータ ソースに格納されているデータ間の不整合が原因で発生します。 これは、Metrics Advisor によるデータのプルが終了した後にデータ ソースが更新されたときに発生する可能性があります。 Metrics Advisor によるデータのプルは、指定したデータ ソースから 1 回のみ行われます。
たとえば、監視のためのメトリックが Metrics Advisor にオンボードされている場合などです。 Metrics Advisor で、メトリック データの取得がタイムスタンプ A に正常に行われ、それに対して異常検出が実行されます。 ところが、データが取り込まれた後に、その特定のタイムスタンプ A のメトリック データが更新された場合。 新しいデータ値は取得されません。
バックフィル 履歴データの (後で説明) を使用して不整合を軽減できますが、これらのタイム ポイントのアラートが既にトリガーされている場合、新しい異常アラートはトリガーされません。 このプロセスでは、システムにワークロードが追加される可能性があり、自動ではありません。
部分データの読み込みを回避するには、次の 2 つの方法をお勧めします。
データを 1 回のトランザクションで生成する:
タイムスタンプが同じすべてのディメンションの組み合わせのメトリック値が、確実に 1 回のトランザクションでデータ ソースに格納されるようにします。 上の例では、すべてのデータ ソースのデータの準備が整うまで待機してから、1 回のトランザクションで Metrics Advisor に読み込みます。 Metrics Advisor により、データが正常に (または部分的に) 取得されるまで、データ フィードを定期的にポーリングできます。
インジェストのタイム オフセット パラメーターに適切な値を設定して、データ インジェストを遅らせる:
データ フィードに対してインジェストのタイム オフセット パラメーターを設定して、データが完全に準備されるまでインジェストを遅らせます。 これは、Azure Table Storage など、トランザクションをサポートしていない一部のデータ ソースに役立ちます。 詳細については、「詳細設定」を参照してください。
データ フィードの追加から始める
Metrics Advisor ポータルにサインインしてワークスペースを選択したら、 [Get started](開始) をクリックします。 次に、ワークスペースのメイン ページで、左側のメニューから [Add data feed](データ フィードの追加) をクリックします。
接続設定の追加
1. 基本設定
次に、時系列データ ソースを接続するためのパラメーターのセットを入力します。
- ソースの種類:時系列データを格納するデータ ソースの種類。
- 細分性:時系列データ内の連続するデータ ポイントの間隔。 現在、Metrics Advisor では、毎年、毎月、毎週、毎日、毎時間、分あたり、カスタムがサポートされています。 カスタマイズ オプションでサポートされている最小間隔は 60 秒です。
- 秒:granularityName を Customize に設定したときの秒数。
- データ インジェスト開始 (UTC) :データ インジェストのベースラインの開始時刻。
startOffsetInSecondsは多くの場合、データの一貫性を確保できるようにオフセットを追加するのに使用します。
2. 接続文字列を指定する
次に、データ ソースの接続情報を指定する必要があります。 他のフィールドとさまざまな種類のデータ ソースの接続の詳細については、「方法: さまざまなデータ ソースを接続する」を参照してください。
3. 1 つのタイムスタンプのクエリを指定する
さまざまな種類のデータ ソースの詳細については、「方法: さまざまなデータ ソースを接続する」を参照してください。
データの読み込み
接続文字列とクエリ文字列を入力したら、 [Load data](データの読み込み) を選択します。 この操作の中で、Metrics Advisor により、データを読み込むための接続とアクセス許可の確認、クエリで使用する必要のあるパラメーター (@IntervalStart と @IntervalEnd)) の確認、データ ソースの列名の確認が行われます。
この手順でエラーが発生した場合:
- まず、接続文字列が有効かどうかを確認します。
- 次に、十分なアクセス許可があり、インジェスト ワーカーの IP アドレスにアクセス権が付与されていることを確認します。
- その後、必要なパラメーター (@IntervalStart と @IntervalEnd)) がクエリで使用されているかどうかを確認します。
スキーマの構成
データ スキーマが読み込まれたら、適切なフィールドを選択します。
データ ポイントのタイムスタンプが省略されている場合、代わりに、Metrics Advisor により、データ ポイントが取り込まれた時点のタイムスタンプが使用されます。 データ フィードごとに、最大 1 列をタイムスタンプとして指定できます。 列をタイムスタンプとして指定できないことを示すメッセージが表示された場合は、クエリまたはデータ ソースを確認し、プレビュー データ内だけでなく、クエリ結果内に複数のタイムスタンプがあるかどうかを確認します。 データ インジェストを実行する場合、Metrics Advisor によって使用できるチャンクは、指定したソースの時系列データを毎回 1 つ (細分性に従って、1 日、1 時間など) のみです。
| [選択] | 説明 | メモ |
|---|---|---|
| 表示名 | 元の列名の代わりに、ワークスペースに表示される名前。 | 省略可能。 |
| Timestamp | データ ポイントのタイムスタンプ。 省略されている場合、代わりに、Metrics Advisor により、データ ポイントが取り込まれた時点のタイムスタンプが使用されます。 データ フィードごとに、最大 1 列をタイムスタンプとして指定できます。 | 省略可能。 最大 1 列を指定する必要があります。 列をタイムスタンプとして指定できないというエラーが発生する場合は、クエリまたはデータ ソースで重複するタイムスタンプがあるかを確認します。 |
| 測定値 | データ フィード内の数値。 データ フィードごとに、複数のメジャーを指定できますが、少なくとも 1 列をメジャーとして選択する必要があります。 | 少なくとも 1 列を指定する必要があります。 |
| ディメンション | カテゴリ値。 異なる値を組み合わせることで、国/リージョン、言語、テナントなどの特定の 1 次元の時系列が識別されます。 0 個以上の列をディメンションとして選択できます。 注: 文字列以外の列をディメンションとして選択する場合は注意が必要です。 | 省略可能。 |
| 無視 | 選択した列を無視します。 | 省略可能。 クエリを使用してデータを取得することをサポートしているデータ ソースの場合、[無視] オプションはありません。 |
列を無視する場合は、クエリまたはデータ ソースを更新してこれらの列を除外することをお勧めします。 また、 [Ignore columns](列を無視する) を使用して列を無視してから、特定の列を無視することもできます。 列がディメンションである必要があるのに、誤って "無視" に設定されている場合、Metrics Advisor によって部分データが取り込まれる可能性があります。 たとえば、クエリのデータが次のようになっているとします。
| 行 ID | Timestamp | 国/地域 | Language | Income |
|---|---|---|---|---|
| 1 | 2019/11/10 | 中国 | ZH-CN | 10000 |
| 2 | 2019/11/10 | 中国 | EN-US | 1000 |
| 3 | 2019/11/10 | US | ZH-CN | 12000 |
| 4 | 2019/11/11 | US | EN-US | 23000 |
| ... | ... | ... | ... | ... |
"国" がディメンションであり、"言語" が "無視" に設定されている場合、1 番目と 2 番目の行では、タイムスタンプのディメンションは同じになります。 Metrics Advisor により、この 2 つの行の 1 つの値が任意に使用されます。 この場合、Metrics Advisor によって行が集計されません。
スキーマを構成したら、 [Verify schema](スキーマの確認) を選択します。 この操作の中で、Metrics Advisor によって以下の確認が行われます。
- クエリ対象のデータのタイムスタンプが 1 つの間隔に収まっているかどうか。
- 1 つのメトリック間隔内で、ディメンションの組み合わせが同じ重複した値が返されているかどうか。
自動ロール アップ設定
重要
根本原因分析およびその他の診断機能を有効にする場合は、自動ロール アップ設定を構成する必要があります。 有効にすると、自動ロールアップ設定を変更できなくなります。
Metrics Advisor は、インジェスト中に各ディメンションで集計 (SUM、MAX、MIN など) を自動的に実行でき、ルート ケース分析やその他の診断機能で使用される階層を構築します。
次のシナリオで考えてみましょう。
"データのロールアップ分析を含める必要はない。"
Metrics Advisor のロールアップを使用する必要はありません。
"データは既にロール アップされており、ディメンションの値は次によって表される: NULL または空 (既定値)、NULL のみ、その他。"
このオプションは、行が既に合計されているため、Metrics Advisor でデータをロール アップする必要がないことを意味します。 たとえば、 [NULL only](NULL のみ) を選択した場合、次の例の 2 番目のデータ行は、すべての国と言語 EN-US の集計として表示されます。ただし、"国" の値が空の 4 番目のデータ行は、不完全なデータを示す可能性のある通常の行として表示されます。
国/地域 Language Income 中国 ZH-CN 10000 (NULL) EN-US 999999 US EN-US 12000 EN-US 5000 "Metrics Advisor で、Sum/Max/Min/Avg/Count を計算してデータをロール アップし、それを {何らかの文字列} で表す必要がある"
Azure Cosmos DB や Azure Blob Storage などの一部のデータ ソースでは、group by や cube などの特定の計算はサポートされていません。 Metrics Advisor には、インジェスト中にデータ キューブを自動的に生成するためのロール アップ オプションが用意されています。 このオプションは、Metrics Advisor により、選択したアルゴリズムを使用してロールアップが計算され、指定した文字列を使用して Metrics Advisor 内にロールアップが表される必要があることを意味します。 これにより、データ ソース内のデータが変更されることはありません。 たとえば、ディメンション (国、地域) を持つ売上メトリックを表す一連の時系列があるとします。 特定のタイムスタンプについて、次のように表示されます。
Country Region 売上 Canada Alberta 100 Canada British Columbia 500 United States モンタナ 100 Sum を使用する自動ロール アップを有効にすると、Metrics Advisor によって、ディメンションの組み合わせが計算され、データ インジェスト中にメトリックが合計されます。 結果は次のようになります。
Country Region 売上 Canada Alberta 100 NULL Alberta 100 Canada British Columbia 500 NULL British Columbia 500 United States モンタナ 100 NULL モンタナ 100 NULL NULL 700 Canada NULL 600 United States NULL 100 (Country=Canada, Region=NULL, Sales=600)は、カナダ (すべての地域) の売上合計が 600 であることを意味します。SQL 言語における変換を次に示します。
SELECT dimension_1, dimension_2, ... dimension_n, sum (metrics_1) AS metrics_1, sum (metrics_2) AS metrics_2, ... sum (metrics_n) AS metrics_n FROM each_timestamp_data GROUP BY CUBE (dimension_1, dimension_2, ..., dimension_n);自動ロール アップ機能を使用する前に、次の点を考慮してください。
- SUM を使用してデータを集計する場合は、各ディメンションのメトリックが加算されることを確認してください。 次に、"非加法" メトリックの例を示します。
- 分数ベースのメトリック。 これには、比率、パーセンテージなどが含まれます。たとえば、国/リージョン全体の失業率を計算するのに、各州の失業率を加算してはいけませんせん。
- ディメンション内の重複。 たとえば、スポーツ好きの人数を計算するために、それぞれのスポーツの人数を加算してはいけません。両者の間に重複があり、1 人の人が複数のスポーツを好むことがあるからです。
- システム全体の正常性を確保するために、キューブのサイズは制限されています。 現時点では、制限は 100,000 です。 データがその制限を超えると、そのタイムスタンプのインジェストは失敗します。
- SUM を使用してデータを集計する場合は、各ディメンションのメトリックが加算されることを確認してください。 次に、"非加法" メトリックの例を示します。
詳細設定
インジェスト オフセットや同時実行の指定など、カスタマイズされた方法でデータを取り込めるようにするには、いくつかの詳細設定があります。 詳細については、データ フィード管理の記事の「詳細設定」セクションを参照してください。
データ フィードの名前を指定し、インジェストの進行状況を確認する
データ フィードのカスタム名を指定します。これは、ワークスペースに表示されます。 次に [送信] を選択します。 データ フィードの詳細ページで、インジェストの進行状況バーを使用してステータス情報を表示できます。

インジェスト エラーの詳細を確認するには:
- [詳細の表示] を選択します。
- [状態] をクリックして、[失敗] または [エラー] を選択します。
- 失敗したインジェストの上にマウス ポインターを移動し、表示される詳細メッセージを確認します。
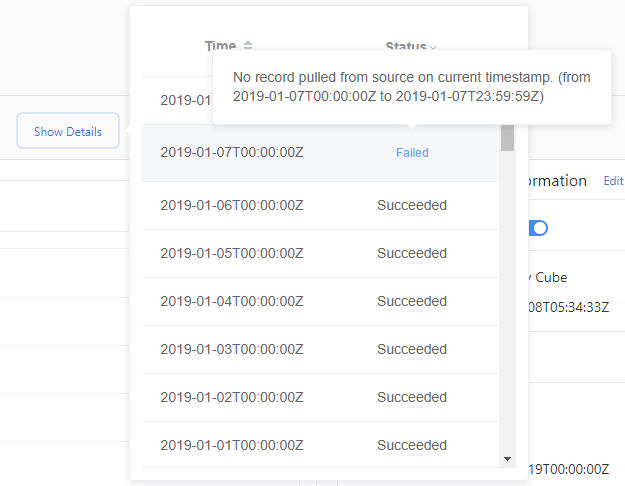
"失敗" 状態は、このデータ ソースのインジェストが後で再試行されることを示します。 "エラー" 状態は、Metrics Advisor によるデータ ソースの再試行が行われないことを示します。 データを再読み込みするには、バックフィルまたは再読み込みを手動でトリガーする必要があります。
また、 [Refresh Progress](進行状況の更新) をクリックして、インジェストの進行状況を再読み込みすることもできます。 データ インジェストが完了したら、メトリックをクリックして、異常検出の結果を確認することができます。