Personalizer の学習ループを構成する
重要
2023 年 9 月 20 日以降は、新しい Personalizer リソースを作成できなくなります。 Personalizer サービスは、2026 年 10 月 1 日に廃止されます。
サービス構成には、サービスによる報酬の処理方法、サービスによる探索の頻度、モデルの再トレーニング頻度、格納するデータ量などがあります。
Azure portal で、その Personalizer リソースの [構成] ページで学習ループを構成します。
構成の変更の計画
構成の変更によってはモデルのリセットが行われるため、構成の変更を計画する必要があります。
見習いモードの使用を計画している場合は、見習いモードに切り替える前に、お使いの Personalizer の構成を確認してください。
モデルのリセットを含む設定
次のアクションを実行すると、過去 2 日間の利用可能なデータを使用して、モデルの再トレーニングがトリガーされます。
- 報酬
- 探索
すべてのデータをクリアするには、 [モデルと学習設定] ページを使用します。
フィードバック ループの報酬を構成する
学習ループの報酬を使用するようにサービスを構成します。 以下の値を変更すると、現在の Personalizer モデルがリセットされ、過去 2 日分のデータで再トレーニングされます。
| 値 | 目的 |
|---|---|
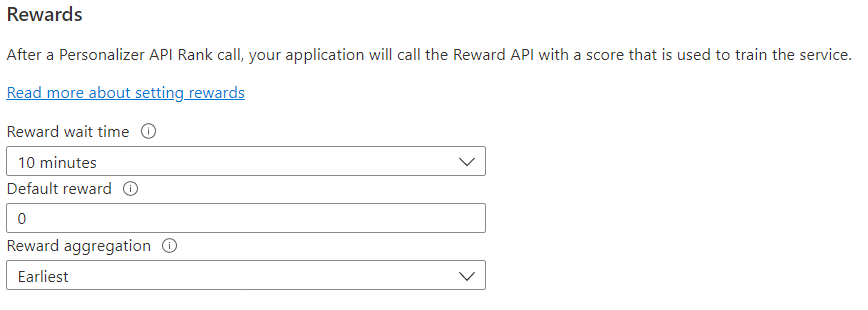
| Reward wait time (報酬の待機時間) | Personalizer が、Rank 呼び出しに対する報酬値を収集する時間 (Rank 呼び出しの時点から) を設定します。 この値は、"Personalizer が報酬の呼び出しを待つ時間はどのくらいですか?" という質問をすることによって設定されます。このウィンドウの後に到着した報酬はログに記録されますが、学習には使用されません。 |
| Default reward (既定の報酬) | Rank 呼び出しに関連付けられた報酬の待機時間ウィンドウ中に Personalizer が報酬呼び出しを受信しなかった場合、Personalizer は既定の報酬を割り当てます。 既定では、またほとんどのシナリオでは、既定の報酬はゼロ (0) です。 |
| Reward aggregation (報酬の集計) | 同じ Rank API 呼び出しに対して複数の報酬を受信した場合は、集計方式として [Sum](合計) または [Earliest](最も早い) が使用されます。 [Earliest](最も早い) の場合、最も早く受信したスコアが採用され、残りは破棄されます。 これは、重複する可能性がある呼び出しの中から一意の報酬を選択する場合に便利です。 |
これらの値を変更した後は、必ず [保存] を選択してください。
学習ループを調整できるように探索を構成する
パーソナル化では、トレーニングされたモデルの予測を使用する代わりに代替手段を探ることによって、新しいパターンを検出し、時間の経過に伴うユーザーの行動の変化に適応できます。 [探索] の値は、Rank 呼び出しの何パーセントが探索で応答されるかを決定します。
この値を変更すると、現在の Personalizer モデルはリセットされ、過去 2 日分のデータで再トレーニングされます。

この値を変更した後は、必ず [保存] を選択してください。
モデル トレーニングのためのモデル更新頻度を構成する
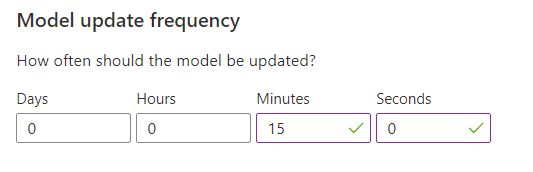
[Model update frequency](モデルの更新頻度) は、モデルがトレーニングされる頻度を設定します。
| 頻度の設定 | 目的 |
|---|---|
| 1 分 | 1 分間の更新頻度は、Personalizer を使用してアプリケーションのコードをデバッグするとき、デモを実行するとき、または機械学習の側面を対話形式でテストするときに有用です。 |
| 約 15 分 | モデルの更新頻度を高くすると、ユーザー動作の変化を詳細に追跡したい場合に便利です。 例としては、ライブ ニュース、バイラル コンテンツ、またはライブ商品入札で実行されるサイトがあります。 これらのシナリオでは、15 分間の頻度を使用できます。 |
| 1 時間 | ほとんどのユース ケースでは、更新頻度が低い方が効果的です。 |
この値を変更した後は、必ず [保存] を選択してください。
データの保持
[Data retention period](データ保持期間) により、Personalizer がデータのログを保持する日数を設定します。 Personalizer の効果を測定し、学習ポリシーを最適化するために使用するオフライン評価を実行するには、過去のデータ ログが必要です。
この値を変更した後は、必ず [保存] を選択してください。