口形素を使用して顔の位置を取得する
Note
口形素 ID とブレンド シェイプでサポートされているロケールを調べるには、「サポートされているすべてのロケールの一覧」を参照してください。 スケーラブル ベクター グラフィックス (SVG) は、en-US ロケールでのみサポートされています。
"口形素" は、音声言語での音素を視覚的に描写したものです。 人が言葉を話すときの顔と口の位置を定義します。 各口形素は、音素の特定のセットに対する主要な頭部姿勢を表します。
顔の位置が合成音声と最もよく一致するように、口形素を使用して 2D および 3D のアバター モデルの動きを制御できます。 たとえば、次のように操作できます。
- インテリジェント キオスク用のアニメーション化された仮想音声アシスタントを作成し、顧客向けのマルチモード統合サービスを構築します。
- イマーシブなニュース放送を構築し、自然な顔と口の動きで視聴者体験を向上させます。
- 動的な内容を話すことができる対話的なゲーム アバターおよびマンガのキャラクターを生成します。
- 言語学習者が各単語と音素の口の動作を理解するのに役立つ、より効果的な言語教育動画を作成します。
- 聴覚障碍のある方も、音を視覚的に認識し、アニメーション化された顔で口形素を表した音声コンテンツを "読唇" できます。
口形素の詳細については、この紹介ビデオを参照してください。
音声を使用して口形素を生成する全体的なワークフロー
ニューラル テキスト読み上げ (ニューラル TTS) では、入力テキストまたは SSML (音声合成マークアップ言語) がリアルな合成音声に変換されます。 音声オーディオ出力には、口形素 ID、スケーラブル ベクター グラフィックス (SVG)、またはブレンド シェイプを付けることができます。 2D または3D レンダリング エンジンを使用すると、これらの口形素イベントを使用してアバターをアニメーション化できます。
口形素の全体的なワークフローを次のフローチャートに示します。
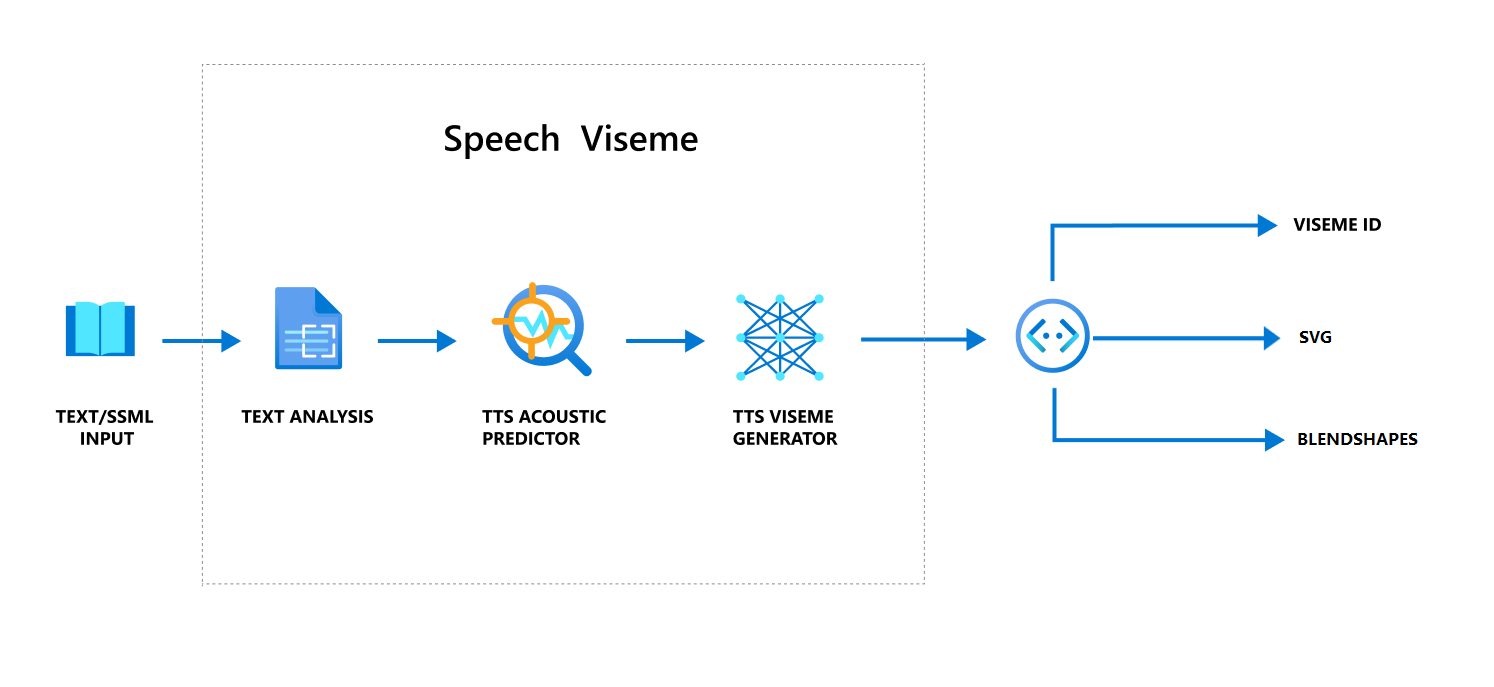
口形素 ID
口形素 ID は、口形素を指定する整数を指します。 22 種類の口形素が提供されており、それぞれが、音素の特定のセットに対する口の位置を表しています。 口形素と音素の間に 1 対 1 対応の関係はありません。 多くの場合、複数の音素に対応する口形素は 1 つです。これは、s や z などの音素が生成されるとき話者の顔は同じように見えるためです。 詳細な情報については、「音素を口形素 ID にマッピングする」の表を参照してください。
音声オーディオ出力には、口形素 ID と Audio offset を付けることができます。 Audio offset は、各口形素の開始時間を表すオフセット タイムスタンプを、ティック数 (100 ナノ秒) で示します。
音素を口形素にマップする
口形素は言語およびロケールによって異なります。 各ロケールには、特定の音素に対応する一連の口形素があります。 SSML 発音アルファベットのドキュメントでは、口形素 ID を対応する国際音標文字 (IPA) 音素にマップしています。 このセクションの表には、口形素 ID と口の位置の間のマッピング関係が示されており、各口形素 ID の一般的な IPA 音素が一覧表示されています。
| 口形素 ID | IPA | 口の位置 |
|---|---|---|
| 0 | 無音 |  |
| 1 | æ、ə、ʌ |
 |
| 2 | ɑ |
 |
| 3 | ɔ |
 |
| 4 | ɛ、ʊ |
 |
| 5 | ɝ |
 |
| 6 | j、i、ɪ |
 |
| 7 | w、u |
 |
| 8 | o |
 |
| 9 | aʊ |
 |
| 10 | ɔɪ |
 |
| 11 | aɪ |
 |
| 12 | h |
 |
| 13 | ɹ |
 |
| 14 | l |
 |
| 15 | s、z |
 |
| 16 | ʃ、tʃ、dʒ, ʒ |
 |
| 17 | ð |
 |
| 18 | f、v |
 |
| 19 | d、t、n, θ |
 |
| 20 | k、g、ŋ |
 |
| 21 | p、b、m |
 |
2D SVG アニメーション
2D キャラクターの場合、シナリオに適したキャラクターを設計し、口形素 ID ごとにスケーラブル ベクター グラフィックス (SVG) を使用して、時間ベースの顔の位置を取得できます。
口形素イベントに含まれるテンポラル タグを使用すると、これらの適切に設計された SVG はスムージング変更によって処理され、途切れのないアニメーションがユーザーに提供されます。 たとえば、次の図は、言語学習用に設計された赤い唇のキャラクターを示しています。

3D ブレンド シェイプのアニメーション
ブレンド シェイプを使って、デザインした 3D キャラクターの顔を動かすことができます。
ブレンド シェイプの JSON 文字列は、2 次元行列として表されます。 各行はフレームを表します。 各フレーム (60 FPS) には、55 個の顔の位置の配列が含まれています。
Speech SDK を使用して口形素イベントを取得する
合成音声を使用して口形素を取得するには、Speech SDK で VisemeReceived イベントをサブスクライブします。
注意
SVG またはブレンド シェイプの出力を要求するには、SSML の mstts:viseme 要素を使う必要があります。 詳細については、SSML で口形素要素を使用する方法を参照してください。
次のスニペットは、口形素イベントをサブスクライブする方法を示しています。
using (var synthesizer = new SpeechSynthesizer(speechConfig, audioConfig))
{
// Subscribes to viseme received event
synthesizer.VisemeReceived += (s, e) =>
{
Console.WriteLine($"Viseme event received. Audio offset: " +
$"{e.AudioOffset / 10000}ms, viseme id: {e.VisemeId}.");
// `Animation` is an xml string for SVG or a json string for blend shapes
var animation = e.Animation;
};
// If VisemeID is the only thing you want, you can also use `SpeakTextAsync()`
var result = await synthesizer.SpeakSsmlAsync(ssml);
}
auto synthesizer = SpeechSynthesizer::FromConfig(speechConfig, audioConfig);
// Subscribes to viseme received event
synthesizer->VisemeReceived += [](const SpeechSynthesisVisemeEventArgs& e)
{
cout << "viseme event received. "
// The unit of e.AudioOffset is tick (1 tick = 100 nanoseconds), divide by 10,000 to convert to milliseconds.
<< "Audio offset: " << e.AudioOffset / 10000 << "ms, "
<< "viseme id: " << e.VisemeId << "." << endl;
// `Animation` is an xml string for SVG or a json string for blend shapes
auto animation = e.Animation;
};
// If VisemeID is the only thing you want, you can also use `SpeakTextAsync()`
auto result = synthesizer->SpeakSsmlAsync(ssml).get();
SpeechSynthesizer synthesizer = new SpeechSynthesizer(speechConfig, audioConfig);
// Subscribes to viseme received event
synthesizer.VisemeReceived.addEventListener((o, e) -> {
// The unit of e.AudioOffset is tick (1 tick = 100 nanoseconds), divide by 10,000 to convert to milliseconds.
System.out.print("Viseme event received. Audio offset: " + e.getAudioOffset() / 10000 + "ms, ");
System.out.println("viseme id: " + e.getVisemeId() + ".");
// `Animation` is an xml string for SVG or a json string for blend shapes
String animation = e.getAnimation();
});
// If VisemeID is the only thing you want, you can also use `SpeakTextAsync()`
SpeechSynthesisResult result = synthesizer.SpeakSsmlAsync(ssml).get();
speech_synthesizer = speechsdk.SpeechSynthesizer(speech_config=speech_config, audio_config=audio_config)
def viseme_cb(evt):
print("Viseme event received: audio offset: {}ms, viseme id: {}.".format(
evt.audio_offset / 10000, evt.viseme_id))
# `Animation` is an xml string for SVG or a json string for blend shapes
animation = evt.animation
# Subscribes to viseme received event
speech_synthesizer.viseme_received.connect(viseme_cb)
# If VisemeID is the only thing you want, you can also use `speak_text_async()`
result = speech_synthesizer.speak_ssml_async(ssml).get()
var synthesizer = new SpeechSDK.SpeechSynthesizer(speechConfig, audioConfig);
// Subscribes to viseme received event
synthesizer.visemeReceived = function (s, e) {
window.console.log("(Viseme), Audio offset: " + e.audioOffset / 10000 + "ms. Viseme ID: " + e.visemeId);
// `Animation` is an xml string for SVG or a json string for blend shapes
var animation = e.animation;
}
// If VisemeID is the only thing you want, you can also use `speakTextAsync()`
synthesizer.speakSsmlAsync(ssml);
SPXSpeechSynthesizer *synthesizer =
[[SPXSpeechSynthesizer alloc] initWithSpeechConfiguration:speechConfig
audioConfiguration:audioConfig];
// Subscribes to viseme received event
[synthesizer addVisemeReceivedEventHandler: ^ (SPXSpeechSynthesizer *synthesizer, SPXSpeechSynthesisVisemeEventArgs *eventArgs) {
NSLog(@"Viseme event received. Audio offset: %fms, viseme id: %lu.", eventArgs.audioOffset/10000., eventArgs.visemeId);
// `Animation` is an xml string for SVG or a json string for blend shapes
NSString *animation = eventArgs.Animation;
}];
// If VisemeID is the only thing you want, you can also use `SpeakText`
[synthesizer speakSsml:ssml];
口形素の出力の例を以下に示します。
(Viseme), Viseme ID: 1, Audio offset: 200ms.
(Viseme), Viseme ID: 5, Audio offset: 850ms.
……
(Viseme), Viseme ID: 13, Audio offset: 2350ms.
口形素の出力を取得したら、これらのイベントを使用してキャラクター アニメーションを作成できます。 独自のキャラクターを作成し、自動的にアニメーション化することができます。