デュアル書き込みプロキシ と Apache Spark を使用して、Apache Cassandra から Azure Cosmos DB for Apache Cassandra にデータをライブ マイグレーションする
Azure Cosmos DB の Cassandra 用 API は、次のようなさまざまな理由により、Apache Cassandra 上で実行されているエンタープライズ ワークロードに適した選択肢になりました。
管理と監視のオーバーヘッドなし: OS、JVM、および yaml ファイルやそれらの相互作用での無数の設定を管理および監視する際のオーバーヘッドが解消されます。
大幅なコスト削減: Azure Cosmos DB によってコストを節約できます。これには、VM、帯域幅、適用されるすべてのライセンスのコストが含まれます。 さらに、データ センター、サーバー、SSD ストレージ、ネットワーク、電気代を管理する必要がありません。
既存のコードとツールを使用可能: Azure Cosmos DB では、既存の Cassandra SDK およびツールとのワイヤ プロトコル レベルの互換性が提供されます。 この互換性により、Azure Cosmos DB for Apache Cassandra を少し変更するだけで、既存のコードベースを使用できることが保証されます。
Azure Cosmos DB では、レプリケーション用のネイティブ Apache Cassandra ゴシップ プロトコルはサポートされていません。 このため、ゼロ ダウンタイムが移行要件である場合は、別のアプローチが必要です。 このチュートリアルでは、デュアル書き込みプロキシと Apache Spark を使用して、ネイティブ Apache Cassandra クラスターから Azure Cosmos DB for Apache Cassandra にデータをライブ マイグレーションする方法について説明します。
次の図はパターンを示したものです。 ライブ変更はデュアル書き込みプロキシを使用してキャプチャされ、履歴データは Apache Spark を使用して一括コピーされます。 構成をほとんど、またはまったく変更することなく、プロキシでアプリケーション コードからの接続を受け入れることができます。 一括コピー中、すべての要求がソース データベースにルーティングされ、書き込みが Cassandra 用 API に非同期的にルーティングされます。

前提条件
互換性を確保するために Azure Cosmos DB for Apache Cassandra でサポートされる機能を確認する。
ソース クラスターとターゲット Cassandra 用 API エンドポイントの間にネットワーク接続が確立されていることを確認する。
キースペースまたはテーブル スキームをソース Cassandra データベースからターゲット Cassandra 用 API アカウントに既に移行していることを確認する。
重要
移行中に Apache Cassandra
writetimeを保持する必要がある場合は、テーブルの作成時に次のフラグを設定する必要があります。with cosmosdb_cell_level_timestamp=true and cosmosdb_cell_level_timestamp_tombstones=true and cosmosdb_cell_level_timetolive=true次に例を示します。
CREATE KEYSPACE IF NOT EXISTS migrationkeyspace WITH REPLICATION= {'class': 'org.apache.> cassandra.locator.SimpleStrategy', 'replication_factor' : '1'};CREATE TABLE IF NOT EXISTS migrationkeyspace.users ( name text, userID int, address text, phone int, PRIMARY KEY ((name), userID)) with cosmosdb_cell_level_timestamp=true and > cosmosdb_cell_level_timestamp_tombstones=true and cosmosdb_cell_level_timetolive=true;
Spark クラスターをプロビジョニングする
Azure Databricks をお勧めします。 Spark 3.0 以上をサポートするランタイムを使用します。
重要
Azure Databricks アカウントがソース Apache Cassandra クラスターとネットワーク接続されていることを確認する必要があります。 これは VNet インジェクションを必要とする場合があります。 詳細については、こちらの記事をご覧ください。
Spark の依存関係を追加する
Apache Spark Cassandra コネクタ ライブラリをクラスターに追加して、ネイティブと Azure Cosmos DB Cassandra 両方のエンドポイントに接続する必要があります。 自分のクラスターで、 [ライブラリ]>[新規インストール]>[Maven] の順に選択し、Maven 座標に com.datastax.spark:spark-cassandra-connector-assembly_2.12:3.0.0 を追加します。
重要
移行中に行ごとに Apache Cassandra writetime を保持する必要がある場合は、こちらのサンプルを使用することをお勧めします。 このサンプルの依存関係 jar には Spark コネクタも含まれているので、上記のコネクタ アセンブリの代わりにこれをインストールする必要があります。 このサンプルは、履歴データの読み込み後にソースとターゲット間の行比較検証を実行する場合にも便利です。 詳細については、以下の「履歴データの読み込みを実行する」と「ソースとターゲットを検証する」を参照してください。
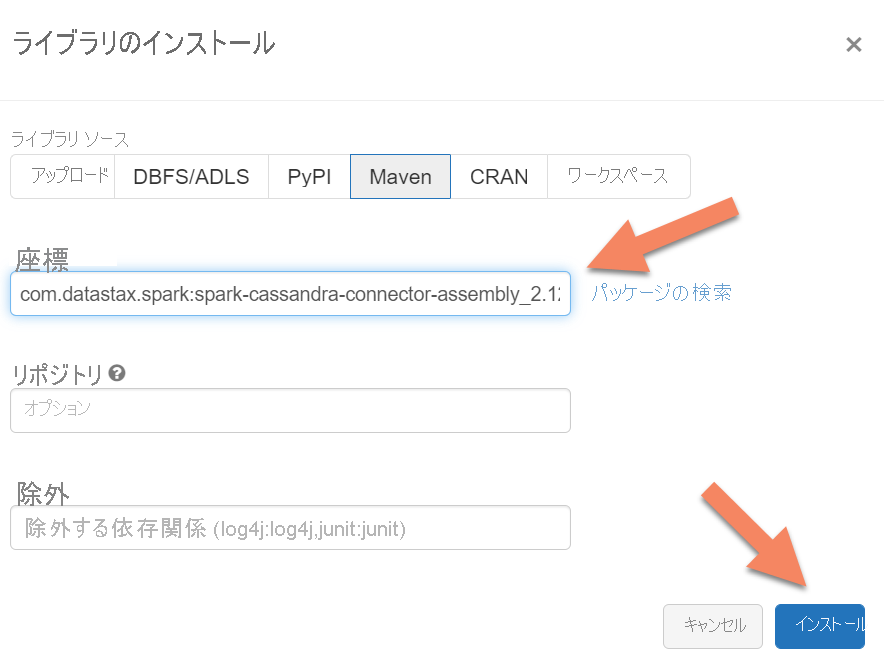
[インストール] を選択し、インストールが完了したらクラスターを再起動します。
Note
Cassandra コネクタ ライブラリがインストールされた後で、必ず Azure Databricks クラスターを再起動してください。
デュアル書き込みプロキシをインストールする
デュアル書き込み時のパフォーマンスを最適化するために、ソース Cassandra クラスター内のすべてのノードにプロキシをインストールすることをお勧めします。
#assuming you do not have git already installed
sudo apt-get install git
#assuming you do not have maven already installed
sudo apt install maven
#clone repo for dual-write proxy
git clone https://github.com/Azure-Samples/cassandra-proxy.git
#change directory
cd cassandra-proxy
#compile the proxy
mvn package
デュアル書き込みプロキシを開始する
ソース Cassandra クラスターのすべてのノードにプロキシをインストールすることをお勧めします。 少なくとも、各ノード上で次のコマンドを実行してプロキシを開始します。 <target-server> をターゲット クラスターのいずれかのノードの IP またはサーバー アドレスに置き換えます。 <path to JKS file> をローカル環境の .jks ファイルへのパスに置き換え、<keystore password> を対応するパスワードに置き換えます。
java -jar target/cassandra-proxy-1.0-SNAPSHOT-fat.jar localhost <target-server> --proxy-jks-file <path to JKS file> --proxy-jks-password <keystore password>
この方法でプロキシを開始する場合は、次の条件を満たすことが前提となります。
- ソースとターゲットのエンドポイントで、ユーザー名とパスワードが同じである。
- ソースとターゲットのエンドポイントに、Secure Sockets Layer (SSL) が実装されている。
ソースとターゲットのエンドポイントでこれらの条件が満たされない場合は、詳細な構成オプションを参照してください。
SSL の構成
SSL については、既存のキーストア (ソース クラスターで使用されているものなど) を実装するか、keytool を使用して自己署名証明書を作成することができます。
keytool -genkey -keyalg RSA -alias selfsigned -keystore keystore.jks -storepass password -validity 360 -keysize 2048
また、ソースまたはターゲットのエンドポイントに SSL が実装されていない場合は、SSL を無効にすることができます。 --disable-source-tls または --disable-target-tls のフラグを使用します。
java -jar target/cassandra-proxy-1.0-SNAPSHOT-fat.jar localhost <target-server> --source-port 9042 --target-port 10350 --proxy-jks-file <path to JKS file> --proxy-jks-password <keystore password> --target-username <username> --target-password <password> --disable-source-tls true --disable-target-tls true
注意
データベースへのプロキシ経由の SSL 接続を構築する場合は、必ずデュアル書き込みプロキシに使用したものと同じキーストアとパスワードをクライアント アプリケーションに使用してください。
資格情報とポートを構成する
既定では、ソースの資格情報がクライアント アプリから渡されます。 プロキシにより、ソースとターゲットのクラスターに対する接続を確立するためにその資格情報が使用されます。 前に説明したように、このプロセスでは、ソースとターゲットの資格情報が同じであることを前提としています。 プロキシを開始するとき、ターゲット Cassandra 用 API エンドポイントに対して、ユーザー名とパスワードを別に指定する必要があります。
java -jar target/cassandra-proxy-1.0-SNAPSHOT-fat.jar localhost <target-server> --proxy-jks-file <path to JKS file> --proxy-jks-password <keystore password> --target-username <username> --target-password <password>
指定されていない場合、ソースとターゲットの既定のポートは 9042 になります。 この場合、Cassandra 用 API はポート 10350 で実行されるため、--source-port または --target-port を使用してポート番号を指定する必要があります。
java -jar target/cassandra-proxy-1.0-SNAPSHOT-fat.jar localhost <target-server> --source-port 9042 --target-port 10350 --proxy-jks-file <path to JKS file> --proxy-jks-password <keystore password> --target-username <username> --target-password <password>
プロキシをリモートでデプロイする
クラスター ノード自体にプロキシをインストールせず、別のマシンにインストールしたい場合があります。 そのようなシナリオでは、<source-server> の IP アドレスを指定する必要があります。
java -jar target/cassandra-proxy-1.0-SNAPSHOT-fat.jar <source-server> <destination-server>
警告
(ソース Apache Cassandra クラスター内のすべてのノードで実行するのではなく) 別のマシンにプロキシをインストールしてリモートで実行すると、ライブ マイグレーションの実行中のパフォーマンスに影響します。 機能的には可能ですが、クライアント ドライバーはクラスター内のすべてのノードへの接続を開くことができるわけではなくなるため、接続を行う単一のコーディネーター ノード (プロキシがインストールされている場所) に依存することになります。
アプリケーションのコードを変更しなくてよいようにする
既定では、プロキシにより、ポート 29042 がリッスンされます。 このポートを指すように、アプリケーションのコードを変更する必要があります。 ただし、プロキシによりリッスンされるポートを変更することができます。 次の方法によりアプリケーション レベルでコードを変更しなくて済むようにしたい場合、これを行うことがあります。
- ソース Cassandra サーバーを別のポートで実行する。
- プロキシを Cassandra の標準ポート 9042 で実行する。
java -jar target/cassandra-proxy-1.0-SNAPSHOT-fat.jar source-server destination-server --proxy-port 9042
Note
クラスター ノードにプロキシをインストールした場合、ノードを再起動する必要はありません。 ただし、多数のアプリケーション クライアントがあり、アプリケーション レベルのコード変更を不要にするために、プロキシを Cassandra の標準ポート 9042 で実行したい場合は、Apache Cassandra の既定のポートを変更する必要があります。 その後、クラスター内のノードを再起動し、ソース Cassandra クラスターに対して定義した新しいポートに、ソース ポートを構成する必要があります。
次の例では、ポート 3074 で実行するようにソース Cassandra クラスターを変更し、ポート 9042 でクラスターを起動します。
java -jar target/cassandra-proxy-1.0-SNAPSHOT-fat.jar source-server destination-server --proxy-port 9042 --source-port 3074
プロトコルを強制する
このプロキシにはプロトコルを強制する機能があります。これは、ソース エンドポイントがターゲットよりも高度な場合、またはそうしないとサポートされない場合に、必要になることがあります。 その場合は、--protocol-version と --cql-version を指定して、プロトコルをターゲットに準拠させることができます。
java -jar target/cassandra-proxy-1.0-SNAPSHOT-fat.jar source-server destination-server --protocol-version 4 --cql-version 3.11
デュアル書き込みプロキシが実行されるようになった後、アプリケーション クライアントでポートを変更し、再起動する必要があります。 (または、その方法を選択した場合は、Cassandra のポートを変更してクラスターを再起動します)。その後、プロキシによるターゲット エンドポイントへの書き込みの転送が開始されます。 プロキシ ツールで使用できる監視とメトリックについてはこちらを参照してください。
履歴データの読み込みを実行する
データを読み込むには、Azure Databricks アカウントで Scala ノートブックを作成します。 ソースとターゲットの Cassandra 構成を対応する資格情報に置き換え、ソースとターゲットのキースペースとテーブルを置き換えます。 次のサンプルのように、必要に応じて各テーブルに変数を追加し、実行します。 アプリケーションによってデュアル書き込みプロキシへの要求送信が開始されたら、履歴データを移行する準備は完了です。
重要
データを移行する前に、コンテナーのスループットを、お使いのアプリケーションで迅速に移行するために必要な量に引き上げます。 移行を開始する前にスループットをスケーリングすると、データの移行にかかる時間を短縮するのに役立ちます。 履歴データの読み込み中のレート制限を防ぐために、Cassandra 用 API でサーバー側の再試行 (SSR) を有効にすることができます。 詳細情報および SSR を有効 にする方法については、こちらの記事を参照してください。
import com.datastax.spark.connector._
import com.datastax.spark.connector.cql._
import org.apache.spark.SparkContext
// source cassandra configs
val sourceCassandra = Map(
"spark.cassandra.connection.host" -> "<Source Cassandra Host>",
"spark.cassandra.connection.port" -> "9042",
"spark.cassandra.auth.username" -> "<USERNAME>",
"spark.cassandra.auth.password" -> "<PASSWORD>",
"spark.cassandra.connection.ssl.enabled" -> "true",
"keyspace" -> "<KEYSPACE>",
"table" -> "<TABLE>"
)
//target cassandra configs
val targetCassandra = Map(
"spark.cassandra.connection.host" -> "<Source Cassandra Host>",
"spark.cassandra.connection.port" -> "10350",
"spark.cassandra.auth.username" -> "<USERNAME>",
"spark.cassandra.auth.password" -> "<PASSWORD>",
"spark.cassandra.connection.ssl.enabled" -> "true",
"keyspace" -> "<KEYSPACE>",
"table" -> "<TABLE>",
//throughput related settings below - tweak these depending on data volumes.
"spark.cassandra.output.batch.size.rows"-> "1",
"spark.cassandra.output.concurrent.writes" -> "1000",
"spark.cassandra.connection.remoteConnectionsPerExecutor" -> "1",
"spark.cassandra.concurrent.reads" -> "512",
"spark.cassandra.output.batch.grouping.buffer.size" -> "1000",
"spark.cassandra.connection.keep_alive_ms" -> "600000000"
)
//set timestamp to ensure it is before read job starts
val timestamp: Long = System.currentTimeMillis / 1000
//Read from source Cassandra
val DFfromSourceCassandra = sqlContext
.read
.format("org.apache.spark.sql.cassandra")
.options(sourceCassandra)
.load
//Write to target Cassandra
DFfromSourceCassandra
.write
.format("org.apache.spark.sql.cassandra")
.options(targetCassandra)
.option("writetime", timestamp)
.mode(SaveMode.Append)
.save
Note
前の Scala サンプルを見ると、ソース テーブル内のすべてのデータが読み取られる前に、timestamp が現在の時刻に設定されていることがわかります。 その後、writetime がこの過去のタイムスタンプに設定されます。 これは、履歴データが読み込まれている間に、履歴データの読み込みからターゲット エンドポイントに書き込まれたレコードによって、後のタイム スタンプでデュアル書き込みプロキシから送られた更新が上書きされないようにするためです。
重要
何らかの理由で "正確な" タイムスタンプを保持する必要がある場合は、こちらのサンプルのような、タイムスタンプを保持する履歴データの移行アプローチを採用する必要があります。 サンプルの依存関係 jar には Spark コネクタも含まれているので、前の前提条件で説明した Spark コネクタ アセンブリをインストールする必要はありません。Spark クラスターに両方ともインストールすると競合が発生します。
ソースとターゲットを検証する
履歴データの読み込みが完了すると、データベースは同期され、切り替えの準備が整います。 ただし、最終的なカットオーバーの前に、ソースとターゲットを検証してそれらが一致することを確認することをお勧めします。
注意
writetime を保持するために上記の cassandra migrationor サンプルを使用した場合、このサンプルには、特定の許容値に基づいてソースとターゲットの行を比較して移行を検証する機能が含まれています。