Azure Cosmos DB でのグローバル データ分散 - 内部のしくみ
適用対象: ![]() NoSQL
NoSQL ![]() MongoDB
MongoDB ![]() Cassandra
Cassandra ![]() Gremlin
Gremlin ![]() Table
Table
Azure Cosmos DB は Azure の基本サービスであるため、パブリック クラウド、ソブリン クラウド、国防総省 (DoD) クラウド、政府機関クラウドを含む世界中のすべての Azure リージョンにわたってデプロイされています。
単純化していえば、Azure Cosmos DB コンテナー データは各リージョンの多数のレプリカセットに対して水平方向にパーティション分割され、レプリカセットによって書き込みがレプリケートされます。 レプリカセットは、マジョリティ クォーラムを使用して書き込みを永続的にコミットします。
各リージョンには Azure Cosmos DB コンテナーのすべてのデータ パーティションが含まれており、複数リージョンの書き込みが有効になっている場合は読み取りと書き込みの両方が可能です。 Azure Cosmos DB アカウントが N 個の Azure リージョンに分散している場合は、すべてのデータの少なくとも N x 4 個のコピーが存在します。
1 つのデータセンターで、専用のローカル ストレージをそれぞれのマシンで使用して大量のスタンプで Azure Cosmos DB をデプロイおよび管理します。 Azure Cosmos DB は 1 つのデータセンターの多数のクラスターでデプロイされます。各クラスターは、さまざまな世代のハードウェアを実行する可能性があります。 クラスター内のコンピューターは通常、リージョン内の高可用性のために 10 ~ 20 の障害ドメインに分散されます。 次の図は、Azure Cosmos DB グローバル分散システムのトポロジを示したものです。
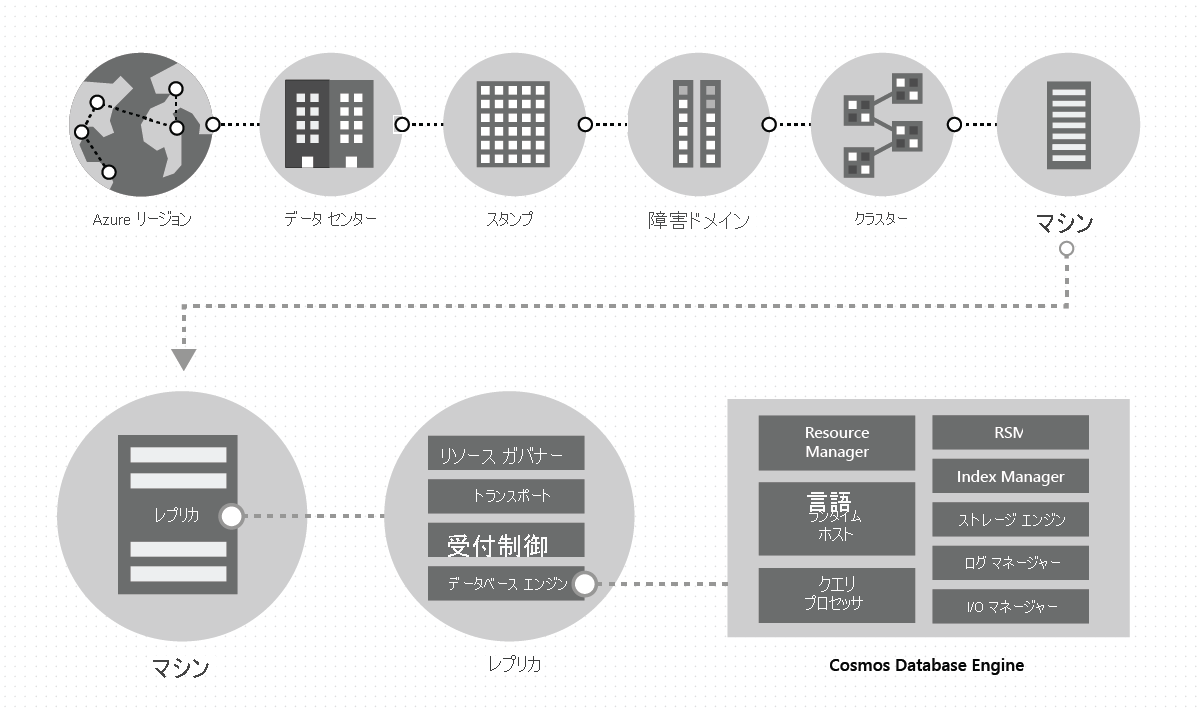
Azure Cosmos DB におけるグローバル分散はターンキー方式です。いつでも数回クリックするか、プログラムを使用して API を 1 回呼び出すだけで、ユーザーは自分の Azure Cosmos DB データベースに関連付けられている地理的リージョンを追加または削除することができます。 Azure Cosmos DB データベースはさらに、一連の Azure Cosmos DB コンテナーで構成されています。 Azure Cosmos DB では、コンテナーは分散とスケーラビリティの論理ユニットとしての役割を果たします。 作成するコレクション、テーブル、グラフは、単に Azure Cosmos DB コンテナーとして (内部的に) 示されます。 コンテナーは完全にスキーマから独立しており、クエリのスコープを提供します。 Azure Cosmos DB コンテナー内のデータはインジェスト時に自動的にインデックス作成されます。 自動インデックス作成を使用すると、特にグローバルに分散された設定で、ユーザーはスキーマやインデックスの管理という面倒な作業を行うことなくデータにクエリを実行できます。
特定のリージョンでは、コンテナー内のデータはパーティション キーを使用して分散されます。このキーは管理者が提供し、基になる物理パーティションによって透過的に管理されます (ローカル分散)。
各物理パーティションはまた、地理的リージョンにまたがってレプリケートされます (グローバル分散)。
Azure Cosmos DB を使用するアプリが Azure Cosmos DB コンテナーでスループットを柔軟にスケーリングしたり、さらに多くのストレージを消費したりする場合、Azure Cosmos DB は、すべてのリージョンにまたがってパーティション管理操作 (分割、複製、削除) を透過的に処理します。 このため、Azure Cosmos DB からはスケール、分散、障害とは関係なく常に、任意の数のリージョンにわたってグローバルに分散された、コンテナー内のデータのシステム イメージが 1 つだけ提供されます。
次の図に示すように、コンテナー内のデータは 2 つのディメンションに沿って (リージョン内および世界中のリージョンにまたがって) 分散されます。
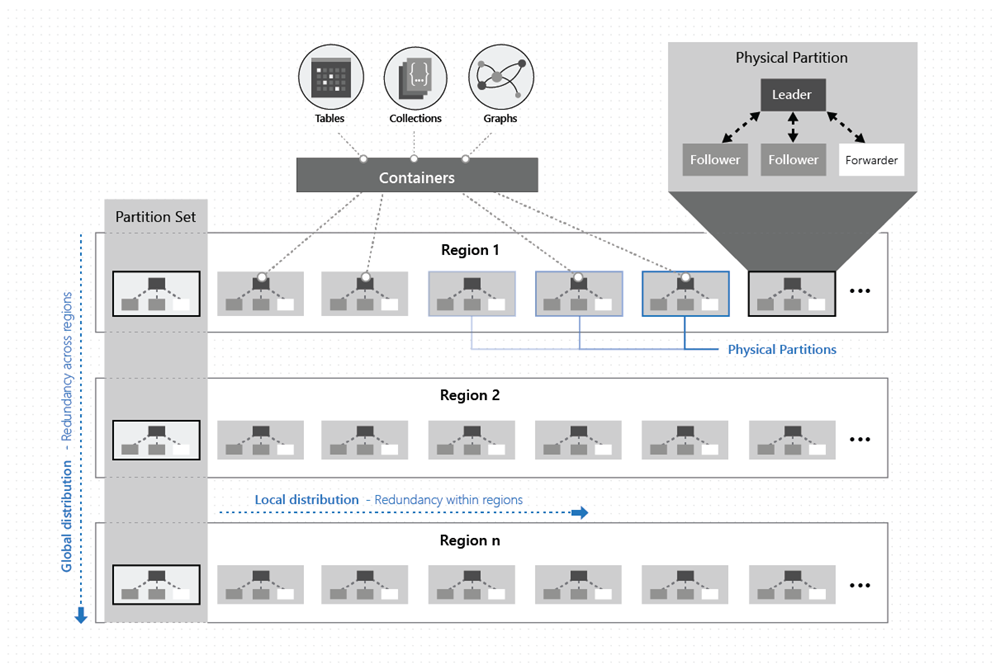
物理パーティションは、レプリカ セットと呼ばれるレプリカのグループによって実装されます。 上の図に示すように、各コンピューターは、固定された一連のプロセス内のさまざまな物理パーティションに対応する数百のレプリカをホストします。 物理パーティションに対応するレプリカは動的に配置されて、1 つのクラスター内の多数のマシンと 1 つのリージョン内の多数のデータセンター内で負荷を分散します。
レプリカは、特定の Azure Cosmos DB テナントに一意に属します。 各レプリカは Azure Cosmos DB のデータベース エンジン インスタンスをホストします。このインスタンスは、リソースおよび関連するインデックスを管理します。 Azure Cosmos DB データベース エンジンは、Atom-Record-Sequence (ARS) ベースの型システムで動作します。 このエンジンはスキーマの概念には依存せず、レコードの構造とインスタンス値の間の境界をあいまいにしています。 Azure Cosmos DB ではインジェスト時に自動的に効率的な方法ですべてをインデックス作成することにより、完全なスキーマ独立を実現しています。これにより、ユーザーはスキーマを処理したり、インデックス管理を行ったりすることなくグローバルに分散されたデータをクエリできます。
Azure Cosmos DB データベース エンジンは、いくつかの調整プリミティブ、言語ランタイム、クエリ プロセッサー、およびデータのトランザクション ストレージとインデックス作成を担うストレージ サブシステムとインデックス作成サブシステムなどを実装するいくつかのコンポーネントで構成されます。 耐久性と高可用性を提供するため、このデータベース エンジンは SSD 上にデータとインデックスを保持し、レプリカ セット内のデータベース エンジン インスタンス間でレプリケーションを行います。 より大きいテナントは、より大きいスケールのスループットとストレージに対応し、より大きい、またはより多くのレプリカを含んでいます。 システム内のすべてのコンポーネントは完全に非同期です。スレッドはブロックされることなく、各スレッドは、不要なスレッド切り替えが生じることなく短期間動作します。 レート制限とバック プレッシャが、管理制御からすべての I/O パスに至るまでスタック全体で組み込まれています。 Azure Cosmos DB データベース エンジンは、きめ細かなコンカレンシーを利用し、少量のシステム リソースで運用中に高スループットを提供するように設計されています。
Azure Cosmos DB のグローバル分散は、レプリカ セットとパーティション セットの 2 つの主要な抽象化に依存しています。 レプリカ セットはモジュール式の調整用レゴ ブロックで、パーティション セットは地理的に分散された 1 つ以上の物理パーティションの動的オーバーレイです。 グローバル分散のしくみを理解するには、これら 2 つの主要な抽象化について理解する必要があります。
レプリカセット
物理パーティションは、複数の障害ドメインにまたがっているセルフ マネージド方式で動的に負荷を分散するレプリカ グループ (別名、レプリカ セット) として実現します。 このセットは、レプリケートされたステート マシン プロトコルを集合的に実装し、物理パーティション内のデータの高可用性、耐久性、および整合性を確保します。 レプリカ セットのメンバーシップ N は動的です。これは、障害、管理操作、および障害が発生したレプリカが再生成/復旧される時間に基づいて NMin と NMax の間の変動を維持します。 メンバーシップが変更すると、レプリケーション プロトコルも読み取りと書き込みのクォーラムのサイズを再構成します。 特定の物理パーティションに割り当てられるスループットを均一に分散させるために、次の 2 つのアイデアを採用しています。
最初に、リーダーに関する書き込み要求を処理するコストは、フォロワーに関する更新を適用するコストより高くなります。 それに対応して、リーダーに割り当てられるシステム リソースはフォロワーよりも多くなっています。
2 番目に、可能な限り、指定の整合性レベルの読み取りクォーラムはフォロワー レプリカによってのみ構成されます。 必要な場合を除き、読み取りのためにリーダーにアクセスしないようにします。 ここでは、Azure Cosmos DB がサポートする 5 つの整合性モデルのクォーラム ベースのシステムにおける負荷と容量の関係に関して実行された研究から多くのアイデアを採用しています。
パーティション セット
物理パーティションのグループは、それぞれが Azure Cosmos DB データベース リージョンで構成されているパーティションから成り、構成されているすべてのリージョンでレプリケートされた同じキー セットを管理します。 この高度な調整プリミティブは、"パーティションセット" と呼ばれる、特定のキー セットを管理する物理パーティションの地理的に分散された動的オーバーレイです。 指定された物理パーティション (レプリカセット) は 1 つのクラスター内のものですが、パーティションセットの場合は、次の図に示すように、複数のクラスター、データ センター、地理的リージョンにまたがることができます。

パーティション セットは、同じキー セットを所有する複数のレプリカ セットで構成されている、地理的に分散している “スーパー レプリカ セット” と見なすことができます。 レプリカセットの場合と同様、パーティションセットのメンバーシップも動的です。暗黙的な物理パーティション管理処理に基づいて変動し、特定のパーティションセットで新しいパーティションが追加されたり、削除されたりします (たとえば、コンテナー上でスループットをスケールアウトする場合や、Azure Cosmos DB データベースでリージョンを追加/削除する場合、障害が発生した場合など)。 (パーティションセットの) 各パーティションでそれぞれのレプリカセット内のパーティションセットのメンバーシップを管理することにより、メンバーシップを完全に分散して、高可用性を実現できます。 パーティション セットを再構成する間に、物理パーティション間のオーバーレイのトポロジも確立されます。 トポロジは一貫性レベル、地理的距離、ソースとターゲットの物理パーティション間で利用できるネットワーク帯域幅に基づいて動的に選択されます。
このサービスを使用することによって、単一の書き込みリージョンと複数の書き込みリージョンのいずれかで Azure Cosmos DB データベースを構成できます。このどちらを選択するかに基づいて、パーティション セットで書き込みを行えるよう構成されるのが 1 つのリージョンのみかすべてのリージョンにおいてであるかが決まります。 システムでは 2 つのレベルの入れ子になったコンセンサス プロトコルが導入されています。1 つのレベルは、書き込みを承認する物理パーティションのレプリカ セットのレプリカで動作します。もう 1 つはパーティション セット レベルで動作して、パーティション セット内のコミットされたすべての書き込みが順序どおりに実行されることを保証します。 このマルチレイヤーの入れ子になったコンセンサスは、高可用性に関する当社の厳密な SLA の遂行や、Azure Cosmos DB がお客様に提供する整合性モデルの実装において重要となります。
競合の解決
更新の伝達、競合解決、因果関係の追跡に関する Microsoft の設計は、以前のエピデミック アルゴリズムと Bayou システムからヒントを得ています。 Azure Cosmos DB のシステム設計ではカーネルの概念が引き続き採用され、通信に便利な参照フレームが導入されていますが、Azure Cosmos DB システムに適用されるときに大幅な変更が加えられています。 以前のシステムには、Azure Cosmos DB が動作するために必要なリソース管理もスケールも備わっておらず、Azure Cosmos DB がお客様に提供するさまざまな機能 (有界整合性制約の一貫性など) や厳密で包括的な SLA も提供されていなかったので、このような変更が必要とされていました。
パーティション セットは複数のリージョンで分散され、Azure Cosmos DB の (マルチリージョン書き込み) レプリケーション プロトコルに従って、特定のパーティション セットを構成する物理パーティション間でデータをレプリケートするという点を思い出してください。 (パーティション セットの) それぞれの物理パーティションは書き込みを承諾し、対象リージョンに対してローカルなクライアントに対して通常読み取りを行います。 リージョン内の物理パーティションで承諾された書き込みは耐久性の高い状態でコミットされ、クライアントに対して確認応答する前に物理パーティションで高可用になります。 これらは仮の書き込みで、アンチエントロピ チャネルを使用してパーティション セットの他の物理パーティションに伝達されます。 クライアントは、要求ヘッダーを引き渡すことによって、仮の書き込みまたはコミット済みの書き込みを要求できます。 アンチエントロピ伝達 (伝達頻度も含む) は、パーティション セットのトポロジ、物理パーティション間のリージョンの近接度、構成されている整合性レベルに基づいて動的に行われます。 パーティション セット内では、Azure Cosmos DB は動的に選択されたアービター パーティションが含まれるプライマリ コミット スキーマに従います。 アービターの選択は動的で、オーバーレイのトポロジに基づくパーティション セットの再構成において不可欠な部分です。 コミット済み書き込み (複数行/バッチ更新を含む) は順序どおりに実行されることが保証されます。
因果関係の追跡とバージョン ベクターにおいて更新の競合を検出して解決するために、エンコードされたベクター クロックを導入しました (レプリカ セットとパーティション セットのそれぞれのレベルのコンセンサスに対応するリージョン ID と論理クロックが含まれます)。 このトポロジとピア選択アルゴリズムは、バージョン ベクターの固定の最小限のストレージと最小限のネットワーク オーバーヘッドを確保するよう設計されています。 このアルゴリズムによって、厳密な収束プロパティが保証されます。
複数の書き込みリージョンが構成されている Azure Cosmos DB データベースの場合、システムによって、開発者が選択できる多数の柔軟な自動競合解決ポリシーが提供されています。以下の選択肢が含まれます。
- [最後の書き込みが有効] 。既定では、ユーザーはシステム定義のタイムスタンプ プロパティを使用します (時刻同期クロック プロトコルに基づきます)。 また Azure Cosmos DB を使用することによって、競合解決に使用する他のカスタムの数値型プロパティを指定できます。
- [Application-defined (Custom) conflict resolution policy](アプリケーション定義の (カスタム) 競合解決ポリシー) (マージ プロシージャを通じて表現)。これは、競合に対するアプリケーション定義のセマンティクスの調整用に設計されています。 これらのプロシージャは、データベース トランザクションの支援によって書き込み間の競合が検出されると、サーバー側で呼び出されます。 システムにより、コミットメント プロトコルの一部としてのマージ プロシージャの実行が 1 回だけとなることが保証されます。 利用可能ないくつかの競合解決サンプルが用意されています。
整合性モデル
Azure Cosmos DB データベースを単一または複数の書き込みリージョンのどちらで構成した場合でも、明確に定義された 5 種類の一貫性モデルを選択できます。 書き込みリージョンが複数の場合、一貫性レベルの以下の側面に注目できます。
有界整合性制約の一貫性では、すべてのリージョンにおいて、読み取りすべてが最新の書き込みから K プレフィックス以内または T 秒以内になることが保証されます。 また、有界整合性制約の一貫性を使用した読み取りは、モノトニックで、プレフィックスの一貫性が保証されたものになります。 アンチエントロピ プロトコルはレートが制限された状態で実行され、プレフィックスが累積しないことと、書き込みのバックプレッシャを適用する必要がないことが保証されます。 セッション一貫性では、モノトニックな読み取り、モノトニックな書き込み、独自の書き込みの読み取り、読み取り後の書き込み、一貫性のあるプレフィックスが世界規模で保証されます。 強力な一貫性が構成されたデータベースの場合、リージョンをまたいで同期レプリケーションが行われるため、複数の書き込みリージョンの利点 (書き込みの低遅延、高い書き込み可用性) が適用されません。
Azure Cosmos DB の 5 つの一貫性モデルのセマンティクスについてはこちらで取り上げられています。また、高水準の TLA+ 仕様を使用した数学的観点からの説明は、こちらを参照してください。
次のステップ
次に、次の記事を使用してグローバル分散を構成する方法について説明します。
- データベース アカウントのリージョンの追加/削除
- カスタム競合解決ポリシーの作成方法
- Azure Cosmos DB への移行のための容量計画を実行しようとしていますか? 容量計画のために、既存のデータベース クラスターに関する情報を使用できます。
- 既存のデータベース クラスター内の仮想コアとサーバーの数のみがわかっている場合は、仮想コア数または仮想 CPU 数を使用した要求ユニットの見積もりに関するページを参照してください
- 現在のデータベース ワークロードに対する通常の要求レートがわかっている場合は、Azure Cosmos DB Capacity Planner を使用した要求ユニットの見積もりに関するページを参照してください