Azure Cosmos DB コンテナーまたはアカウントの正規化された RU/秒を監視する方法
適用対象: ![]() NoSQL
NoSQL ![]() MongoDB
MongoDB ![]() Cassandra
Cassandra ![]() Gremlin
Gremlin ![]() Table
Table
Azure Monitor for Azure Cosmos DB では、アカウントを監視したり、ダッシュボードを作成したりするためのメトリック ビューが提供されています。 Azure Cosmos DB のメトリックは既定で収集されるので、この機能を使用するために何かを明示的に有効にしたり構成したりする必要はありません。
メトリックの定義
正規化された RU 消費量メトリックは、データベースまたはコンテナーでのプロビジョニング済みスループットの使用率を測定するために使われる 0% から 100% の間のメトリックです。 このメトリックは 1 分間隔で出力され、その時間間隔内でのすべてのパーティション キー範囲に関する最大 RU/s 使用率と定義されます。 各パーティション キー範囲は 1 つの物理パーティションにマップされ、指定可能なハッシュ値の範囲のデータを保持するように割り当てられます。 一般に、正規化された RU のパーセンテージが高いほど、プロビジョニング済みスループットを多く利用しています。 このメトリックを使うと、データベースまたはコンテナーの個々のパーティション キー範囲の使用率を見ることもできます。
たとえば、コンテナーで自動スケーリングの最大スループットを 20,000 RU/s (2,000 から 20,000 RU/s のスケール) に設定してあり、2 つのパーティション キー範囲 (物理パーティション) P1 と P2 があるとします。 Azure Cosmos DB はプロビジョニング済みスループットをすべてのパーティション キー範囲に均等に分散させるので、P1 と P2 はそれぞれ 1,000 から 10,000 RU/s の間でスケーリングできます。 間隔を 1 分とし、ある秒では P1 が 6000 要求ユニットを消費し、P2 が 8000 要求ユニットを消費したとします。 P1 の正規化された RU 消費量は 60%、P2 は 80% です。 コンテナー全体の正規化された RU 消費量全体は MAX(60%, 80%) = 80% です。
操作の種類と共に、要求ユニットの消費量を 1 秒間隔で見たい場合は、オプトイン機能である診断ログを使用し、PartitionKeyRUConsumption テーブルのクエリを実行します。 アプリケーションが Azure Cosmos DB リソースで実行している操作と状態コードの概要を取得するには、組み込みの Azure Monitor の合計要求数 (NoSQL 用 API)、Mongo 要求数、Gremlin 要求数、または Cassandra 要求数 メトリックを使います。 後で、429 状態コードによってこれらの要求をフィルターし、操作の種類別に分割することができます。
正規化された RU/秒が高い場合に想定して実行する内容
特定のパーティション キーの範囲で正規化された RU の消費量が 100% に達したときに、クライアントが 1 秒間の時間枠内に、その特定のパーティション キー範囲への要求をまだ行っている場合は、レート制限エラー (429) が発生します。
これは必ずしもリソースに問題があることを意味するとは限りません。 Azure Cosmos DB クライアント SDK とデータ インポート ツール (Azure Data Factory、バルク エグゼキューター ライブラリなど) は、429 が発生すると、既定では要求を自動的に再試行します。 通常、再試行は最大で 9 回です。 このため、メトリックで 429 が表示されている一方で、これらのエラーがアプリケーションに返されていない場合もあります。
一般的に、運用ワークロードで、要求の 1 から 5% で 429 が発生し、エンド ツー エンドの待機時間が許容範囲内である場合、これは RU/秒が完全に利用されているという正常な兆候です。 この場合、正規化された RU 消費量メトリックが 100% に達するということは、特定の 1 秒において、少なくとも 1 つのパーティション キー範囲でそのプロビジョニング済みスループットがすべて使われたことを意味します。 429 の全体的なレートがまだ低いため、これは許容されます。 これ以上操作は必要ありません。
429 の原因になったデータベースまたはコンテナーに対する要求の割合を確認するには、Azure Cosmos DB アカウントのブレードから、[分析情報]>[要求]>[状態コードごとの要求の合計数] に移動します。 フィルター処理して、特定のデータベースとコンテナーを表示します。 Gremlin 用 API の場合は、Gremlin 要求数メトリックを使います。

正規化された RU 消費量メトリックが複数のパーティション キー範囲で一貫して 100% であり、429 のレートが 5% を超える場合は、スループットを増やすことをお勧めします。 負荷の大きい操作とそのピーク使用率を確認するには、Azure Monitor のメトリックと Azure Monitor の診断ログを使います。 「プロビジョニングされたスループット (RU/s) のスケーリングに関するベスト プラクティス」に従ってください。
正規化された RU が 100% に達したという理由だけで、429 のレート制限エラーが発生するとは限りません。 これは、正規化された RU がすべてのパーティション キー範囲にわたる最大使用量を表す 1 つの値であるためです。 あるパーティション キー範囲がビジー状態でも、他のパーティション キー範囲で問題なく要求に対応できます。 たとえば、パーティション キー範囲のすべての RU/s を消費するストアド プロシージャなどの 1 回の操作によって、正規化された RU 消費量メトリックの短時間のスパイクが発生します。 このような場合、全体的な要求レートが低い場合や、別のパーティション キー範囲で他のパーティションへの要求が行われている場合は、即時にレート制限エラーは発生しません。
429 レート制限エラーを解釈してデバッグする方法の詳細を確認してください。
ホット パーティションを監視する方法
正規化された RU 消費量メトリックを使って、ワークロードにホット パーティションがあるかどうかを監視できます。 ホット パーティションが発生するのは、要求量の多さが原因で、1 つ以上の論理パーティション キーによって消費される RU/秒の合計量が不均衡な場合です。 この原因として考えられるのは、要求を均等に分散させないパーティション キーの設計です。 この結果、多くの要求が論理パーティション (パーティション キー範囲を意味します) の小さなサブセットに送信され、それらが "ホット" になります。論理パーティションのすべてのデータは 1 つのパーティション キー範囲に存在し、すべてのパーティション キー範囲間で RU/s の合計量が均等に分配されます。このため、ホット パーティションで 429 が発生し、スループットが非効率的に使用されることになります。
ホット パーティションがあるかどうかを識別する方法
ホット パーティションがあるかどうかを確認するには、[分析情報]>[スループット]>[Normalized RU Consumption (%) By PartitionKeyRangeID](PartitionKeyRangeID ごとの正規化された RU 消費量 (%)) に移動します。 フィルター処理して、特定のデータベースとコンテナーを表示します。
各 PartitionKeyRangeId は、1 つの物理パーティションにマップされます。 ある PartitionKeyRangeId の正規化された RU 消費量が他のものよりも大幅に高い場合 (たとえば、一方が常に 100% で、他方が 30% 未満の場合)、これは、ホット パーティションの兆候と考えることができます。
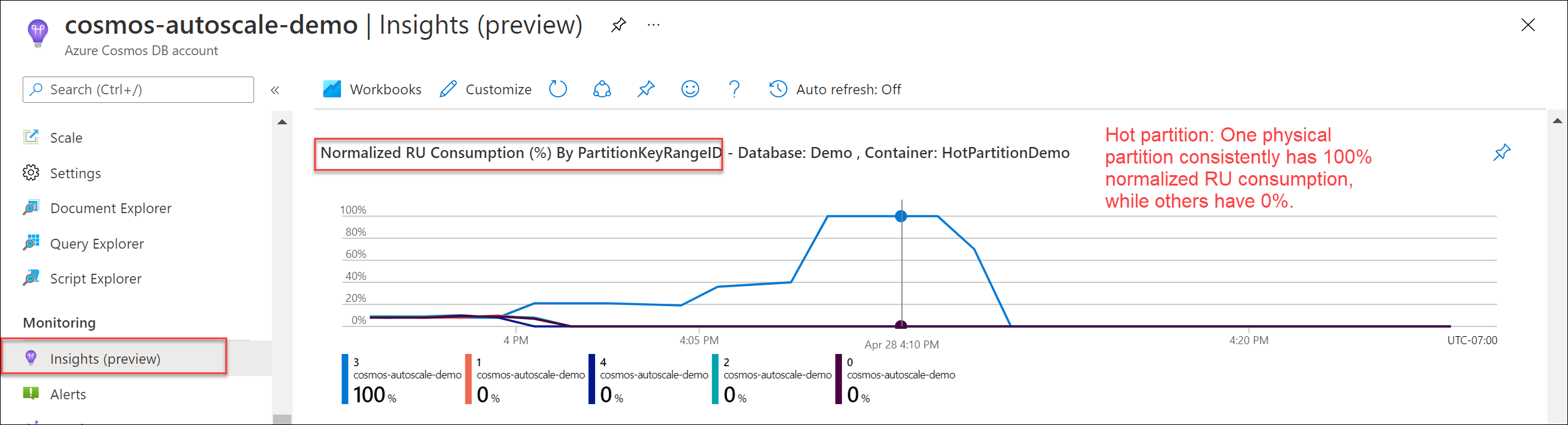
最も RU/s を消費している論理パーティションと推奨される解決策を確認するには、「Azure Cosmos DB の要求率が大きすぎる (429) 例外を診断してトラブルシューティングする」をご覧ください。
正規化された RU 消費量と自動スケーリング
少なくとも 1 つのパーティション キー範囲で、割り当てられたすべての RU/s が時間間隔内のいずれかの 1 秒で使用された場合、正規化された RU 消費量メトリックは 100% として表示されます。 よくある質問の 1 つは、正規化された RU 消費量が 100% であるのに、Azure Cosmos DB の自動スケーリングで RU/s が最大スループットにスケーリングされなかったのはなぜか、というものです。
注意
以下の情報は、自動スケーリングの現在の実装についての説明であり、今後変更される可能性があります。
自動スケーリングを使用すると、5 秒間隔で、継続して連続した期間だけ、正規化された RU 消費量が 100% になる場合に、Azure Cosmos DB で RU/秒が最大スループットにスケーリングされます。 これは、ユーザーにとってコスト効率の高いスケーリング ロジックとなるように行われます。これによって、瞬間的な 1 回の急増による、不要なスケーリングの実行と、コストの増加が防止されるためです。 瞬間的な急増が発生した場合は、通常、以前にスケーリングされた RU/秒より大きく、最大 RU/秒より小さい値にスケールアップされます。
たとえば、自動スケーリングの最大スループットが 20,000 RU/s (2,000 から 20,000 RU/s のスケール) で、パーティション キー範囲が 2 つのコンテナーがあるとします。 各パーティション キー範囲は、1,000 から 10,000 RU/s の範囲でスケーリングできます。 自動スケーリングでは必要なすべてのリソースが事前にプロビジョニングされるため、いつでも最大 20,000 RU/s を使用できます。 たとえば、トラフィックで間欠的にスパイクが発生し、ある 1 秒で、パーティション キー範囲の 1 つの使用量が 10,000 RU/s になります。 その後の秒の使用量は 1,000 RU/s に戻ります。 正規化された RU 消費量メトリックでは、すべてのパーティションについて期間内で最も高い使用率が示されるため、100% が表示されます。 しかし、使用率が 100% になったのは 1 秒だけなので、自動スケーリングが自動的に最大までスケーリングすることはありません。
その結果、自動スケーリングが最大までスケーリングしなくても、使用可能な合計 RU/s を使用できました。 RU/s の消費量を確認するには、オプトイン機能の診断ログを使って、すべてのパーティション キー範囲について 1 秒ごとの RU 使用量全体を照会できます。
CDBPartitionKeyRUConsumption
| where TimeGenerated >= (todatetime('2022-01-28T20:35:00Z')) and TimeGenerated <= todatetime('2022-01-28T20:40:00Z')
| where DatabaseName == "MyDatabase" and CollectionName == "MyContainer"
| summarize sum(RequestCharge) by bin(TimeGenerated, 1sec), PartitionKeyRangeId
| render timechart
一般的に、自動スケーリングを使う運用ワークロードでは、要求の 1% から 5% で 429 が発生し、エンド ツー エンドの待機時間が許容範囲内である場合、これは RU/s が完全に利用されているという正常な兆候です。 正規化された RU 消費量がときどき 100% に達し、自動スケーリングが最大 RU/s にスケールアップしない場合でも、429 の全体的なレートが低いため問題ありません。 必要な操作はありません。
ヒント
自動スケーリングを使っていて、正規化された RU 消費量が一貫して 100% であり、常に最大 RU/s にスケーリングされている場合は、手動スループットを使う方がコスト効率が高い可能性があることを示しています。 自動スケーリングと手動スループットのどちらがワークロードに最適かを判断するには、「標準 (手動) および自動スケーリングのプロビジョニング スループットから選択する方法」をご覧ください。 また、Azure Cosmos DB では、ワークロードのパターンに基づいて Azure Advisor の推奨事項が送信され、手動または自動スケーリングのスループットが推奨されます。
正規化された要求ユニット消費量メトリックを表示する
Azure portal にサインインします。
左側のナビゲーション バーから [監視] を選択し、 [メトリック] を選択します。
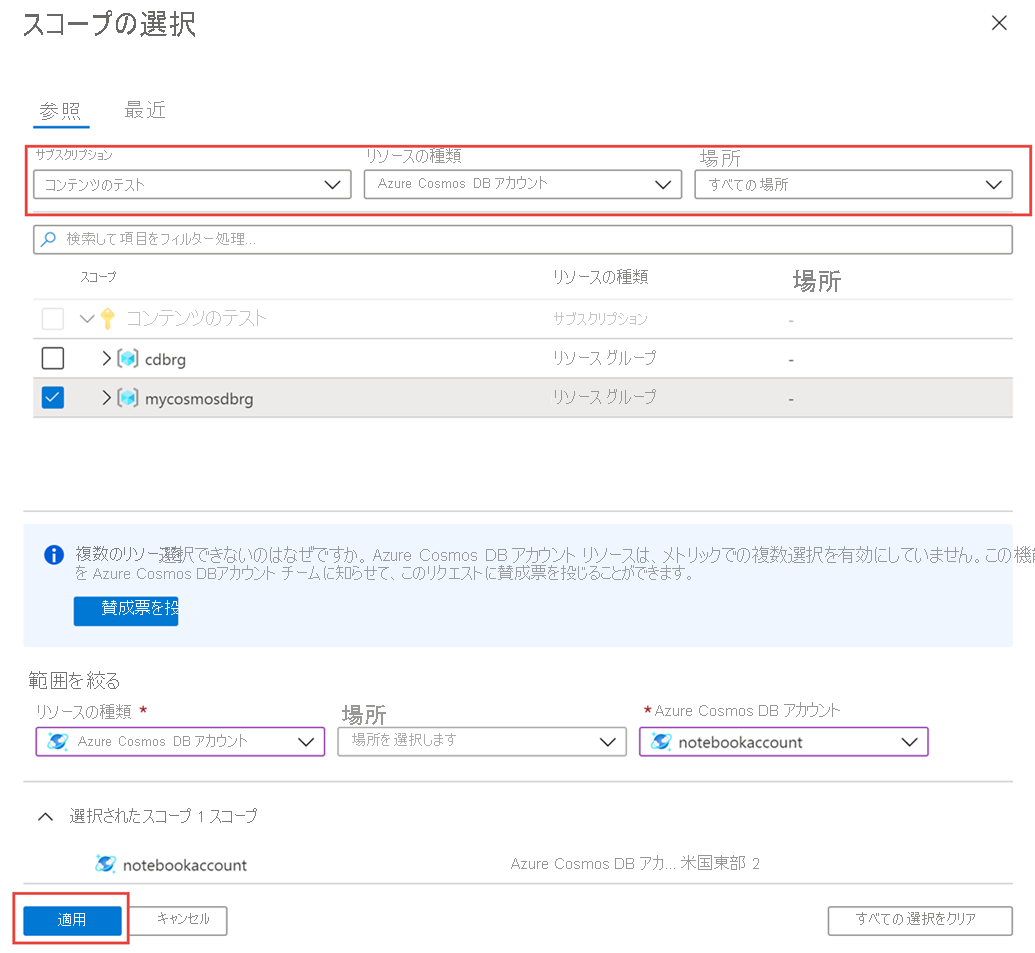
[メトリック] ウィンドウから、[リソースの選択] を選択し、必要なサブスクリプションとリソース グループを選択します。 [リソースの種類] では、[Azure Cosmos DB accounts](Azure Cosmos DB アカウント) を選択し、既存の Azure Cosmos DB アカウントの一つを選択し、[適用] を選択します。
次に、使用可能なメトリックの一覧からメトリックを選択できます。 要求ユニット、ストレージ、待機時間、可用性、Cassandra などに固有のメトリックを選択できます。 この一覧で使用可能なすべてのメトリックの詳細については、「カテゴリ別のメトリック」の記事を参照してください。 この例では、 [Normalized RU Consumption](正規化された RU 消費量) メトリックを選択し、集計値として [最大] を選択します。
これらの詳細に加えて、メトリックの [時間の範囲] と [時間の粒度] を選択することもできます。 最大で、過去 30 日間のメトリックを表示できます。 フィルターを適用すると、そのフィルターに基づいてグラフが表示されます。

正規化された RU 消費量メトリックのフィルター
メトリックと、特定の CollectionName、DatabaseName、PartitionKeyRangeID、Region によって表示されるグラフをフィルターすることもできます。 メトリックをフィルターするには [フィルターの追加] を選択し、調べたい CollectionName などの必要なプロパティと対応する値を選択します。 これで、グラフには、選択した期間中のコンテナーの正規化された RU 消費量メトリックが表示されます。
[Apply splitting](分割の適用) オプションを使用すると、メトリックをグループ化できます。 共有スループット データベースの場合、正規化された RU メトリックではデータベースの粒度でのみデータが表示され、コレクションごとのデータは表示されません。 そのため、共有スループット データベースでは、コレクション名による分割を適用してもデータは表示されません。
次の図に示すように、各コンテナーの正規化された要求ユニット消費量のメトリックが表示されます。

次のステップ
- Azure の診断設定を使用して Azure Cosmos DB データを監視する
- Azure Cosmos DB コントロール プレーン操作を監査する
- Azure Cosmos DB の要求率が大きすぎる (429) 例外を診断してトラブルシューティングする