Azure Cosmos DB の分析情報を使用した監視とデバッグ
適用対象: ![]() NoSQL
NoSQL ![]() MongoDB
MongoDB![]() Cassandra
Cassandra![]() Gremlin
Gremlin![]() Table
Table
Azure Cosmos DB には、スループット、ストレージ、整合性、可用性、および待機時間の分析情報が用意されています。 Azure portal では、これらのメトリックの集計ビューが提供されます。 Azure Monitor API から Azure Cosmos DB メトリックを表示することもできます。 メトリックのディメンション値 (コンテナー名など) は、大文字と小文字が区別されません。 そのため、これらのディメンション値に対して文字列比較を行う場合は、大文字と小文字を区別しない比較を使用する必要があります。 Azure Monitor から取得したメトリックを表示する方法については、「Azure Cosmos DB を監視する」を参照してください。
この記事では、一般的なユース ケースと、Azure Cosmos DB 分析情報を使用してこれらの問題を分析およびデバッグする手順について説明します。 既定では、メトリックの分析情報は 5 分ごとに収集され、7 日間保持されます。
Azure portal から分析情報を表示する
Azure Portal にサインインし、Azure Cosmos DB アカウントに移動します。
アカウントのメトリックは、 [メトリック] ペインまたは [分析情報] ペインのいずれかで表示できます。
メトリック: このペインには、一定の間隔で収集され、ある時点でのシステムのある側面を表す数値メトリックが表示されます。 たとえば、サーバー側の待機時間メトリック、正規化された要求ユニット使用率メトリックなどを表示し、監視できます。
分析情報: このペインでは、Azure Cosmos DB 用にカスタマイズされた監視エクスペリエンスを利用できます。 [分析情報] には Azure Monitor で収集されたものと同じメトリックとログが使用され、アカウントの集計されたビューが表示されます。
[分析情報] ペインを開きます。 [分析情報] ペインには、既定でアカウント内のすべてのコンテナーのスループット、要求、ストレージ、可用性、待機時間、システム、管理操作のメトリックが表示されます。 分析情報を表示する [時間範囲] 、 [データベース] 、 [コンテナー] を選択することができます。 [概要] タブには、選択したデータベースとコンテナーの RU/s 使用量、データ使用量、インデックス使用量、調整された要求数、正規化された RU/s 消費量が表示されます。
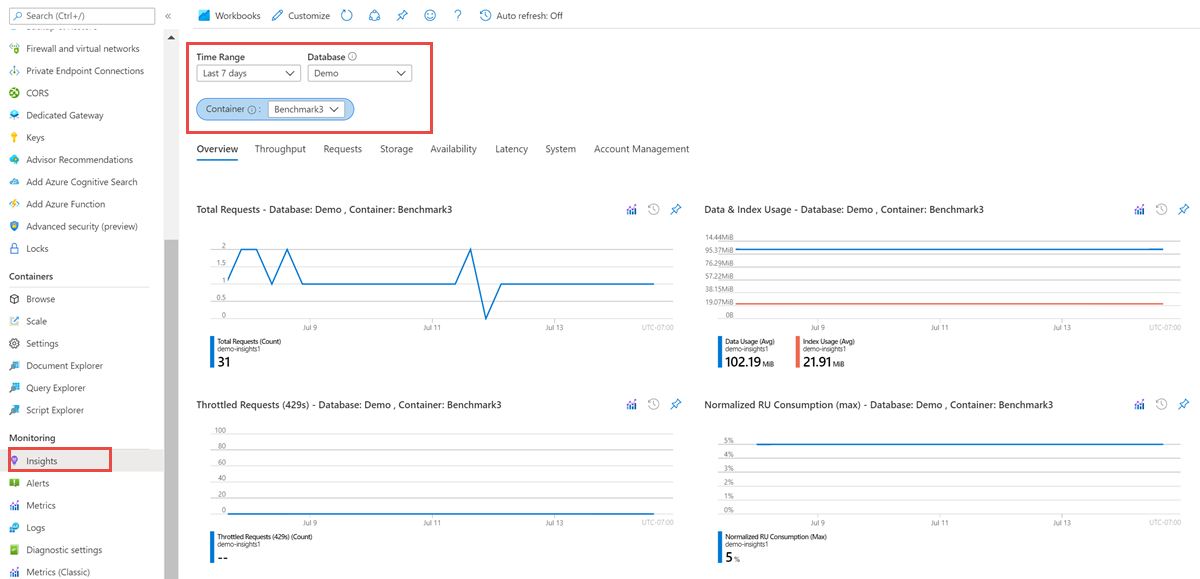
[分析情報] ペインから、次のメトリックを入手できます。
スループット。 このタブには、要求ユニットのうち、消費されたもの、またはコンテナーに対してプロビジョニングされたスループットまたはストレージ容量が超過したために失敗した (応答コード 429) ものの合計数が表示されます。
Requests このタブには、状態コードごと、操作の種類ごとの処理済み要求の合計数と、失敗した要求 (429 応答コード) の数が表示されます。 コンテナーにプロビジョニングされたスループットまたはストレージ容量を超過すると、要求は失敗します。
ストレージ。 このタブには、選択した期間のデータとインデックスの使用量のサイズが表示されます。
可用性。 このタブには、1 時間あたりの要求の合計に対する成功した要求の割合が表示されます。 Azure Cosmos DB の SLA に成功率が定義されています。
待機時間。 このタブには、アカウントが動作しているリージョンで Azure Cosmos DB によって観察された読み取りと書き込みの待機時間が表示されます。 Geo レプリケートされたアカウントのリージョン間での待機時間を視覚化することができます。 また、さまざまな操作別のサーバー側の待機時間も表示できます。 このメトリックでは、エンド ツー エンドの要求の待機時間は表されません。
システム。 このタブには、プライマリ パーティションによって処理されたメタデータ要求の数が表示されます。 スロットルされた要求を識別するためにも役立ちます。
管理操作。 このタブには、アカウントの作成、削除、キーの更新、ネットワークとレプリケーションの設定など、アカウント管理アクティビティのメトリックが表示されます。

次のセクションで、Azure Cosmos DB のメトリックを使用する一般的なシナリオについて説明します。
成功した要求数とエラーになった要求数の把握
まず Azure portal を開き、[分析情報] ペインに移動します。 このペインから [要求] タブを開きます。[要求] タブには、状態コードと操作の種類ごとに分けられた合計要求数を示すグラフが表示されます。 HTTP 状態コードの詳細については、「HTTP Status Codes for Azure Cosmos DB」(Azure Cosmos DB の HTTP 状態コード) を参照してください。
最も一般的なエラー状態コードは 429 (レート制限/調整) です。 このエラーは、Azure Cosmos DB への要求がプロビジョニングされたスループットを超えることを意味します。 この問題の最も一般的な解決策は、そのコレクションの RU をスケール アップすることです。 詳細については、「Azure Cosmos DB におけるスループットのプロビジョニングの概要」を参照してください

パーティション キーの範囲ごとにスループット消費量を判断する
適切なカーディナリティのパーティション キーを持つことは、スケーラブルなアプリケーションのために重要です。 パーティション キーの範囲の ID ごとに分けられたパーティション コンテナーのスループットの分散を判断するには、 [分析情報] ペインに移動します。 [スループット] タブを開きます。さまざまなパーティション キー範囲にわたる正規化された RU/秒の消費量がグラフに表示されます。
![RU/秒の消費量を示す [スループット] タブのスクリーンショット。](media/use-metrics/throughput-consumption-partition-key-range.png#lightbox)
このグラフを使用して、ホット パーティションがあるかどうかを特定できます。 スループット分散が不均一の場合、"ホット" パーティションが発生するおそれがあります。その結果、要求が調整され、パーティションの再分割が必要になる可能性があります。 分散の偏りの原因となっているパーティション キーを特定した後は、必要に応じて、より分散されたパーティション キーでコンテナーのパーティションの再分割を行います。 Azure Cosmos DB のパーティション分割の詳細については、「Azure Cosmos DB でのパーティション分割と水平スケーリング」を参照してください。
データとインデックスの使用量を判断する
データ使用量、インデックス使用量、ドキュメント使用量によってパーティション コンテナーのストレージの分散を判断することが重要です。 インデックス使用量を最小限に抑え、データ使用量を最大化し、クエリを最適化できます。 このデータを取得するには、[分析情報] ペインに移動し、[ストレージ] タブを開きます。
![[ストレージ] タブが強調表示されている [分析情報] ペインのスクリーンショット。](media/use-metrics/data-index-consumption.png#lightbox)
データ サイズとインデックス サイズを比較する
Azure Cosmos DB の合計使用ストレージは、データ サイズとインデックス サイズの両方を組み合わせた量です。 通常、インデックス サイズは、データ サイズよりもはるかに小さいサイズです。 詳細については、インデックス サイズに関する記事を参照してください。 Azure portal の [メトリック] ペインの [ストレージ] タブには、データとインデックスに基づくストレージ使用量の内訳が表示されます。
// Measure the document size usage (which includes the index size)
ResourceResponse<DocumentCollection> collectionInfo = await client.ReadDocumentCollectionAsync(UriFactory.CreateDocumentCollectionUri("db", "coll"));
Console.WriteLine("Document size quota: {0}, usage: {1}", collectionInfo.DocumentQuota, collectionInfo.DocumentUsage);
インデックス領域を節約するには、インデックス ポリシーを調整します。
低速クエリをデバッグする
NoSQL 用 API SDK の Azure Cosmos DB には、クエリ実行の統計情報が用意されています。
IDocumentQuery<dynamic> query = client.CreateDocumentQuery(
UriFactory.CreateDocumentCollectionUri(DatabaseName, CollectionName),
"SELECT * FROM c WHERE c.city = 'Seattle'",
new FeedOptions
{
PopulateQueryMetrics = true,
MaxItemCount = -1,
MaxDegreeOfParallelism = -1,
EnableCrossPartitionQuery = true
}).AsDocumentQuery();
FeedResponse<dynamic> result = await query.ExecuteNextAsync();
// Returns metrics by partition key range Id
IReadOnlyDictionary<string, QueryMetrics> metrics = result.QueryMetrics;
QueryMetrics は、クエリの各コンポーネントが実行にかかった時間について詳細情報を提供します。 クエリの時間が長くなる最も一般的な根本原因はスキャンです。つまり、クエリでインデックスを適用できなかったことを示します。 この問題は、フィルター条件を修正することで解決できます。
コントロール プレーンの要求を監視する
Azure Cosmos DB では、連続する 5 分間に実行できるメタデータ要求の数に制限が適用されます。 コントロール プレーン要求がこれらの制限を超えると、調整が発生する可能性があります。 ある場合に、メタデータ要求が、アカウントのすべてのメタデータを含む、アカウント内の master partition に対してスループットを消費することがあります。 コントロール プレーン要求がスループット量を超えると、レート制限 (429) が発生します。
まず Azure portal を開き、[分析情報] ペインに移動します。 このウィンドウから、[システム] タブを開きます。[システム] タブには、2 つのグラフが表示されます。 1 つには、アカウントのすべてのメタデータ要求が示されます。 もう 1 つには、アカウントのメタデータを格納するアカウントの master partition からのメタデータ要求のスループット消費量が示されます。
![[分析情報] ウィンドウを示すスクリーンショット。[システム] タブでメタデータ要求のグラフが強調表示されています。](media/use-metrics/metadata-requests-by-status-code.png#lightbox)
![[分析情報] ウィンドウを示すスクリーンショット。[システム] タブでメタデータ要求の 429 グラフが強調表示されています。](media/use-metrics/metadata-requests-429.png#lightbox)
上記の [状態コード別メタデータ要求] グラフでは、時間範囲を増やすと、より大きい細分性で要求が集計されます。 5 分間のビンに使用できる最大の時間範囲は 4 時間です。 特定の細分性を持つより大きな時間範囲でメタデータ要求を監視するには、Azure メトリックを使用します。 新しいグラフを作成し、メタデータ要求メトリックを選択します。 右上隅で、次に示すように [時間の細分性] に [5 分] を選択します。 また、[メトリック] を使用すると、ユーザーはそれらに対してアラートを作成できるため、[分析情報] よりも便利になります。
次のステップ
データベースのパフォーマンスを改善する方法については、次の記事を参照してください。