マッピング データ フロー内の列パターンを使用する
適用対象: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
ヒント
企業向けのオールインワン分析ソリューション、Microsoft Fabric の Data Factory をお試しください。 Microsoft Fabric は、データ移動からデータ サイエンス、リアルタイム分析、ビジネス インテリジェンス、レポートまで、あらゆるものをカバーしています。 無料で新しい試用版を開始する方法について説明します。
複数のマッピング データ フローの変換によって、ハードコーディングされた列名ではなく、パターンに基づいてテンプレート列を参照できるようになります。 このマッチングは、"列パターン" と呼ばれます。 正確なフィールド名を必要とするのではなく、パターンを定義して名前、データ、型、ストリーム、発生元、位置に基づいて列を照合できます。 列パターンが役立つシナリオが 2 つあります。
- 受信ソース フィールドが頻繁に変更される場合。テキスト ファイルや NoSQL データベースの列が変更されるケースなどです。 このシナリオは、スキーマの誤差と呼ばれます。
- 大規模な列グループに対して共通の操作を実行したい場合。 列名に ' total ' が含まれているすべての列を double 型にキャストするなどです。
派生列および集計の列パターン
派生列、集計、またはウィンドウ変換における列パターンを追加するには、列リストの上にある [追加] か、既存の派生列の横にあるプラス記号をクリックします。 [列パターンの追加] を選択します。
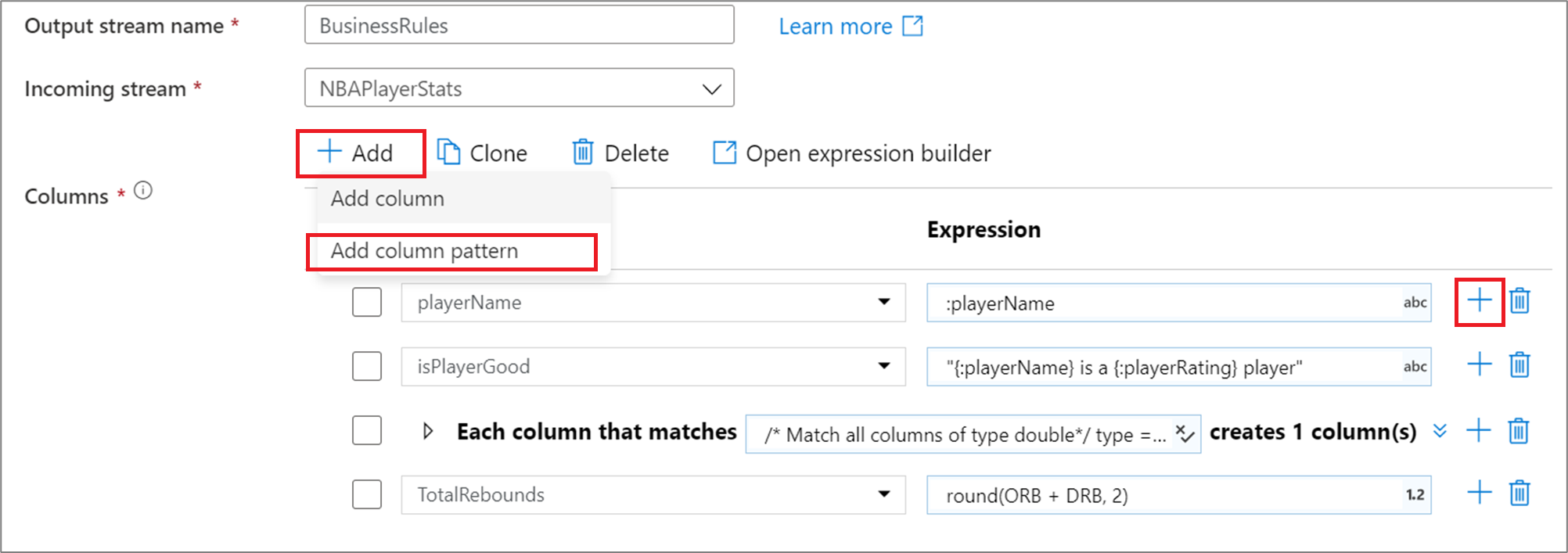
式ビルダーを使用して、一致条件を入力します。 列の name、type、stream、origin、position を基に列と照合するブール式を作成します。 パターンは、条件から true が返される任意の列 (誤差または定義) に影響を及ぼします。
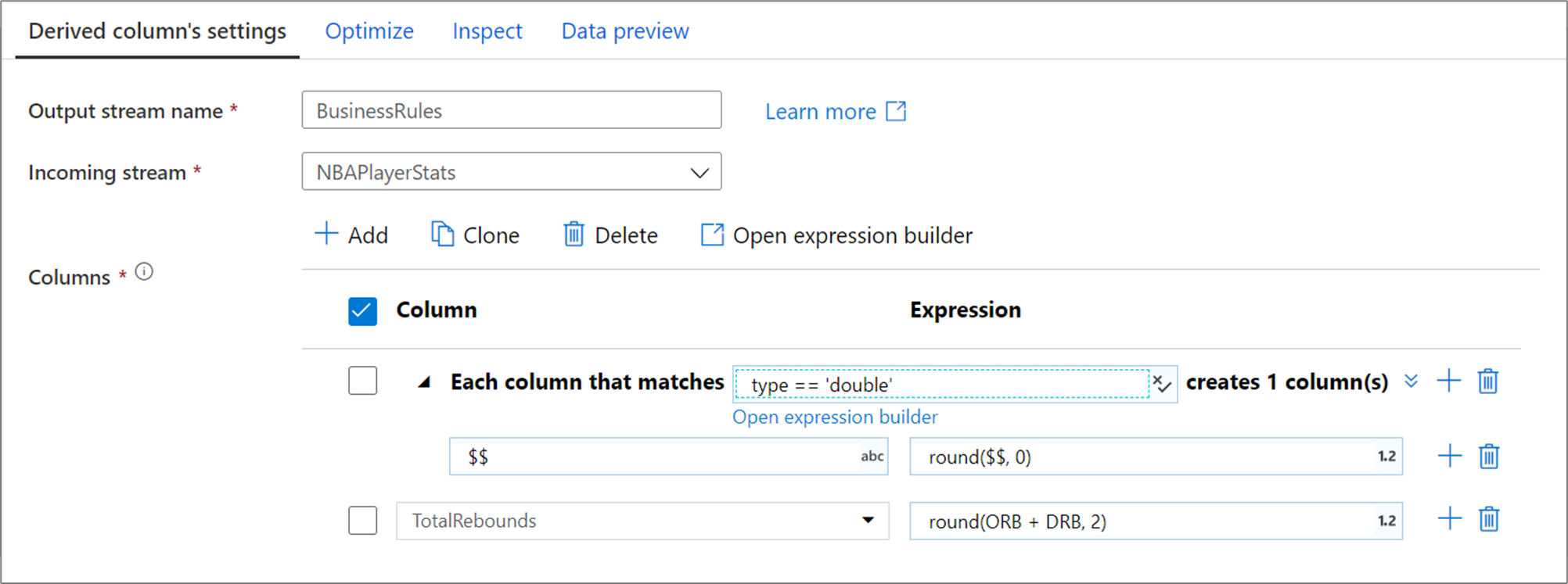
上の列パターンでは、double 型のすべての列と照合して、一致ごとに 1 つの派生列を作成します。 列名フィールドとして $$ を記すことによって、一致した各列が同じ名前で更新されます。 各列の値は、小数点以下第 3 位を四捨五入した既存の値です。
一致条件が正しいことを確認するには、 [検査] タブ内にある定義列の出力スキーマを検証するか、または [データのプレビュー] タブ内にあるデータのスナップショットを取得できます。
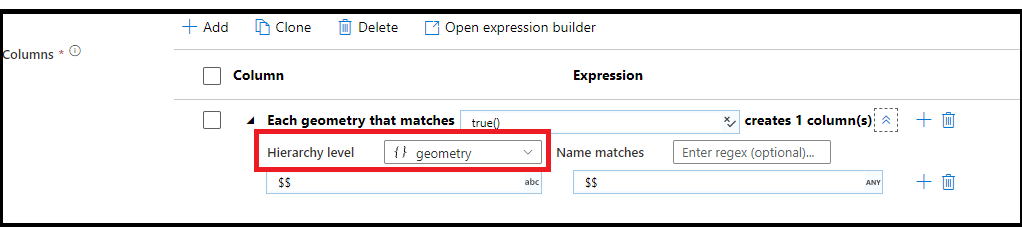
階層型のパターン マッチング
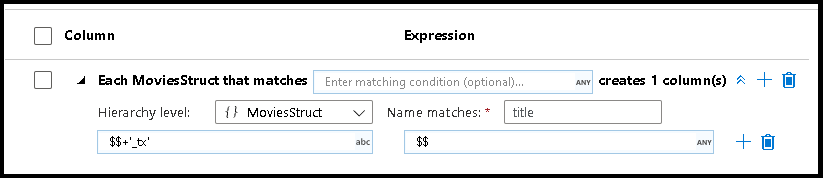
複雑な階層構造内でも、パターン マッチングを作成できます。 セクション Each MoviesStruct that matches を展開すると、データ ストリーム内の各階層の内容が表示されます。 その後、選択した階層内のプロパティに関するマッチング パターンを作成できます。
構造体のフラット化
データに配列、階層構造、マップのような複雑な構造がある場合は、フラット化変換を使用して配列のロールを解除し、データを非正規化できます。 構造体とマップの場合は、列パターンを含む派生列変換を使用して、階層からフラット化されたリレーショナル テーブルを形成します。 次のサンプルのような列パターンを使用できます。これにより、geography 階層がリレーショナル テーブル形式にフラット化されます。
選択とシンクにおけるルールベースのマッピング
ソース変換および選択変換の中で列をマッピングする場合、固定マッピングまたはルールベースのマッピングのどちらかを追加できます。 列の name、type、stream、origin、position に基づいて照合されます。 フィールドとルールベースの両方のマッピングを任意に組み合わせることもできます。 既定では、50 列を超えるすべてのプロジェクションは、既定ではルールベースのマッピングになり、すべての列に対して照合され、入力された名前が出力されます。
ルールベースのマッピングを追加するには、 [マッピングの追加] をクリックし、 [ルールベースのマッピング] を選択します。

各ルールベースのマッピングには、2 つの入力が必要となります。照合の基準となる条件、およびマップされた各列に付ける名前です。 どちらの値も式ビルダーを使用して入力ます。 左側の式ボックスに、ブール値の一致条件を入力します。 右側の式ボックスに、一致した列のマップ先を指定します。

一致した列の入力名を参照するには、$$ 構文を使用します。 上の図を例として使用します。ユーザーは、名前が 6 文字より短いすべての文字列型の列に対して照合したいとします。 ある入力列に test という名前が付けられていた場合、式 $$ + '_short' によりその列の名前が test_short に変更されます。 これが唯一のマッピングの場合、条件を満たしていないすべての列が、出力されるデータから削除されます。
パターンにより、誤差の列と定義された列の両方が照合されます。 どの定義された列がルールによってマップされたかを確認するには、ルールの横にある眼鏡アイコンをクリックします。 データ プレビューを使用して出力を確認します。
正規表現マッピング
下向きのシェブロン アイコンをクリックすると、正規表現のマッピング条件を指定できます。 正規表現のマッピング条件により、指定された正規表現の条件に一致するすべての列名が照合されます。 これは、標準のルールベースのマッピングと組み合わせて使用できます。

上記の例では、正規表現パターン (r)、つまり小文字の r を含むすべての列名と照合されます。 標準のルールベースのマッピングと同様に、一致したすべての列は、$$ 構文を使用した右側の条件によって変更されます。
ルールベースの階層
定義されたプロジェクションに階層がある場合は、ルールベースのマッピングを使用して、階層のサブ列をマップできます。 一致条件と、マップ対象のサブ列が含まれる複合列を指定します。 一致したすべてのサブ列は、右側に指定された [Name as](付ける名前) ルールを使用して出力されます。
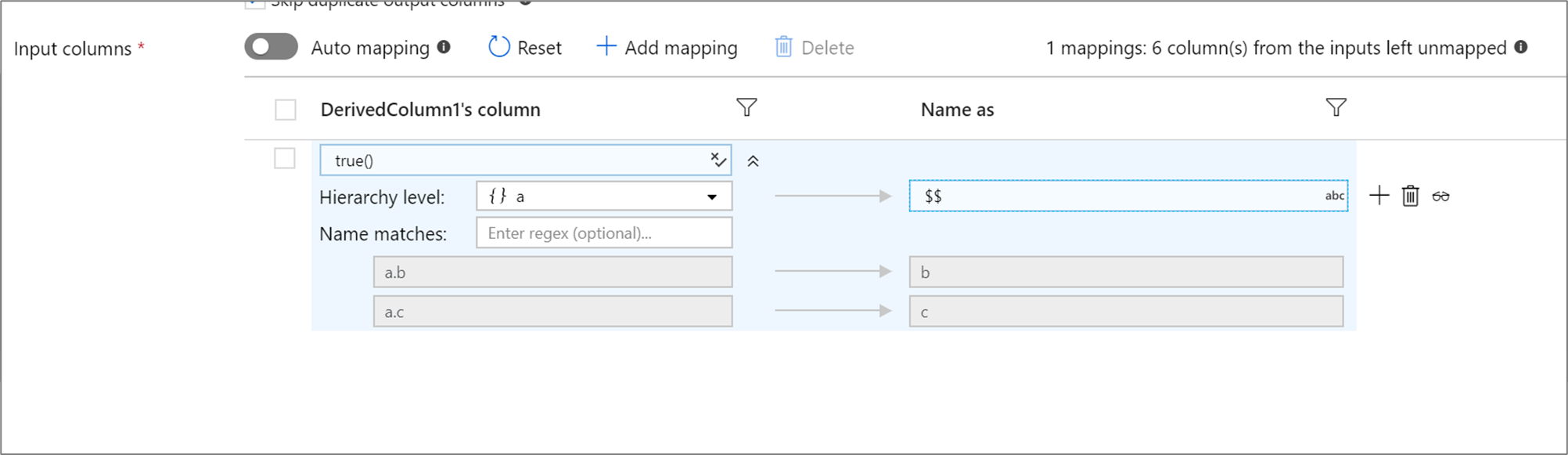
上記の例では、複合列 a のすべてのサブ列に対して照合されます。 a には 2 つのサブ列 b と c が含まれています。 [Name as](付ける名前) 条件が $$ であるため、出力スキーマには 2 つの列 b と c が含まれす。
パターン マッチングの式の値
$$は、実行時に各一致の名前または値に変換されます。$$はthisと同等と見なされます$0は、スカラー型の実行時に現在の列名と一致するものに変換されます。 階層型の場合、$0は現在一致している列階層パスを表します。nameは、受信した各列の名前を表しますtypeは、受信した各列のデータ型を表します。 データ フロー型システムのデータ型の一覧については、こちらを参照してください。streamは、フロー内の各ストリームまたは変換に関連付けられた名前を表しますpositionは、データ フロー内の列の序数位置ですoriginは、列の発生元であるか、最後に更新された場所となる変換です。