Azure Data Factory または Azure Synapse Analytics を使用して Amazon RDS for Oracle からデータをコピーする
適用対象: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
ヒント
企業向けのオールインワン分析ソリューション、Microsoft Fabric の Data Factory をお試しください。 Microsoft Fabric は、データ移動からデータ サイエンス、リアルタイム分析、ビジネス インテリジェンス、レポートまで、あらゆるものをカバーしています。 無料で新しい試用版を開始する方法についてはこちらでご確認ください。
この記事では、Azure Data Factory のコピー アクティビティを使用して、Amazon RDS for Oracle データベースからデータをコピーする方法について説明します。 これは、コピー アクティビティの概要に関する記事に基づいています。
サポートされる機能
この Amazon RDS for Oracle コネクタは、次の機能でサポートされます。
| サポートされる機能 | IR |
|---|---|
| Copy アクティビティ (ソース/-) | 1.1 |
| Lookup アクティビティ | 1.1 |
① Azure 統合ランタイム ② セルフホステッド統合ランタイム
コピー アクティビティによってソースまたはシンクとしてサポートされるデータ ストアの一覧については、サポートされるデータ ストアに関する記事の表をご覧ください。
具体的には、この Amazon RDS for Oracle コネクタでは以下がサポートされています。
- Amazon RDS for Oracle データベースの次のバージョン:
- Amazon RDS for Oracle 19c R1 (19.1) 以降
- Amazon RDS for Oracle 18c R1 (18.1) 以降
- Amazon RDS for Oracle 12c R1 (12.1) 以降
- Amazon RDS for Oracle 11g R1 (11.1) 以降
- Amazon RDS for Oracle ソースからの並列コピー。 詳細については、「Amazon RDS for Oracle からの並列コピー」を参照してください。
注意
Amazon RDS for Oracle プロキシ サーバーはサポートされていません。
前提条件
データ ストアがオンプレ ミスネットワーク、Azure 仮想ネットワーク、または Amazon Virtual Private Cloud 内にある場合は、それに接続するようセルフホステッド統合ランタイムを構成する必要があります。
データ ストアがマネージド クラウド データ サービスである場合は、Azure Integration Runtime を使用できます。 ファイアウォール規則で承認されている IP にアクセスが制限されている場合は、Azure Integration Runtime の IP を許可リストに追加できます。
また、Azure Data Factory のマネージド仮想ネットワーク統合ランタイム機能を使用すれば、セルフホステッド統合ランタイムをインストールして構成しなくても、オンプレミス ネットワークにアクセスすることができます。
Data Factory によってサポートされるネットワーク セキュリティ メカニズムやオプションの詳細については、「データ アクセス戦略」を参照してください。
統合ランタイムには、組み込みの Amazon RDS for Oracle ドライバーがあります。 そのため、Amazon RDS for Oracle からデータをコピーするときに、ドライバーを手動でインストールする必要はありません。
はじめに
パイプラインでコピー アクティビティを実行するには、次のいずれかのツールまたは SDK を使用します。
UI を使用して Amazon RDS for Oracle のリンク サービスを作成する
次の手順を使用して、Azure portal UI で Amazon RDS for Oracle のリンク サービスを作成します。
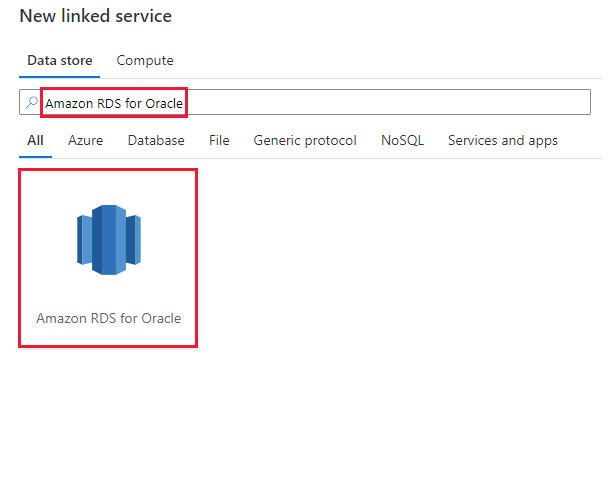
Azure Data Factory または Synapse ワークスペースの [管理] タブに移動し、[リンクされたサービス] を選択して、[新規] をクリックします。
Amazon RDS for Oracle を検索し、Amazon RDS for Oracle コネクタを選択します。
サービスの詳細を構成し、接続をテストして、新しいリンク サービスを作成します。

コネクタの構成の詳細
以下のセクションでは、Amazon RDS for Oracle コネクタに固有のエンティティの定義に使用されるプロパティについて詳しく説明します。
リンクされたサービスのプロパティ
Amazon RDS for Oracle のリンク サービスでは、次のプロパティがサポートされています。
| プロパティ | Description | 必須 |
|---|---|---|
| type | type プロパティは、AmazonRdsForOracle に設定する必要があります。 | はい |
| connectionString | Amazon RDS for Oracle Database インスタンスに接続するために必要な情報を指定します。 パスワードを Azure Key Vault に格納して、接続文字列から password 構成をプルすることもできます。 詳細については、下記の例と、「Azure Key Vault への資格情報の格納」を参照してください。 サポートされる接続の種類: Amazon RDS for Oracle SID または Amazon RDS for Oracle サービス名を使用してデータベースを識別できます。 - SID を使用する場合: Host=<host>;Port=<port>;Sid=<sid>;User Id=<username>;Password=<password>;- サービス名を使用する場合: Host=<host>;Port=<port>;ServiceName=<servicename>;User Id=<username>;Password=<password>;高度な Amazon RDS for Oracle ネイティブ接続オプションでは、Amazon RDS for Oracle サーバー上の TNSNAMES.ORA ファイルにエントリを追加することを選択できます。また、Amazon RDS for Oracle のリンク サービスでは、Amazon RDS for Oracle サービス名の接続の種類を使用し、対応するサービス名を構成できます。 |
はい |
| connectVia | データ ストアに接続するために使用される統合ランタイム。 詳細については、「前提条件」セクションを参照してください。 指定されていない場合は、既定の Azure Integration Runtime が使用されます。 | いいえ |
フェールオーバー シナリオ用の Amazon RDS for Oracle インスタンスが複数ある場合は、Amazon RDS for Oracle のリンク サービスを作成して、プライマリ ホスト、ポート、ユーザー名、パスワードなどを入力し、プロパティ名として AlternateServers、値として (HostName=<secondary host>:PortNumber=<secondary port>:ServiceName=<secondary service name>) を指定した新しい "追加接続プロパティ" を追加できます。値には角かっこを忘れずに入力し、区切り文字としてコロン (:) を使用することに注意してください。 以下の例では、代替サーバーの値により、接続フェールオーバー用の代替データベース サーバーが 2 台定義されます。(HostName=AccountingAmazonRdsForOracleServer:PortNumber=1521:SID=Accounting,HostName=255.201.11.24:PortNumber=1522:ServiceName=ABackup.NA.MyCompany)
接続文字列には他にも、ケースに応じてさまざまな接続プロパティを設定できます。それらのプロパティを次に示します。
| プロパティ | 説明 | 使用できる値 |
|---|---|---|
| ArraySize | 1 回のネットワーク ラウンド トリップでコネクタがフェッチできるバイト数。 たとえば、「 ArraySize=10485760 」のように入力します。値を大きくすると、ネットワーク経由でデータをフェッチする回数が減り、スループットが向上します。 値を小さくすると、サーバーがデータを転送する際の待ち時間がわずかにあるため、応答時間が長くなります。 |
1 から 4294967296 (4 GB) の整数。 既定値は 60000 です。 この値が 1 である場合、バイト数は定義されません。ちょうど 1 行分のデータの領域を割り当てることを意味します。 |
Amazon RDS for Oracle の接続で暗号化を有効にする場合、2 つのオプションがあります。
Triple-DES Encryption (3DES) と Advanced Encryption Standard (AES) を使用するには、Amazon RDS for Oracle サーバー側で Oracle Advanced Security (OAS) に移動し、暗号化設定を構成します。 詳細については、こちらの Oracle のドキュメントを参照してください。 Amazon RDS for Oracle Application Development Framework (ADF) コネクタは暗号化方法を自動的にネゴシエートし、Amazon RDS for Oracle への接続を確立するときにユーザーが OAS で構成した方法を使用します。
TLS を使用するには以下の手順に従ってください。
TLS/SSL 証明書情報を取得します。 TLS/SSL 証明書の Distinguished Encoding Rules (DER) でエンコードされた証明書情報を取得し、出力 (----- Begin Certificate … End Certificate -----) をテキスト ファイルとして保存します。
openssl x509 -inform DER -in [Full Path to the DER Certificate including the name of the DER Certificate] -text例: DERcert.cer から証明書情報を抽出し、出力を cert.txt に保存します。
openssl x509 -inform DER -in DERcert.cer -text Output: -----BEGIN CERTIFICATE----- XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX XXXXXXXXX -----END CERTIFICATE-----keystoreまたはtruststoreをビルドします。 次のコマンドでは、PKCS-12 形式のパスワード含まれる、または含まれない、truststoreファイルが作成されます。openssl pkcs12 -in [Path to the file created in the previous step] -out [Path and name of TrustStore] -passout pass:[Keystore PWD] -nokeys -export例: パスワードを含む MyTrustStoreFile という名前の PKCS12
truststoreファイルを作成します。openssl pkcs12 -in cert.txt -out MyTrustStoreFile -passout pass:ThePWD -nokeys -exportセルフホステッド IR マシンに
truststoreファイルを配置します。 たとえば、C:\MyTrustStoreFile にファイルを配置します。サービスで、
EncryptionMethod=1および対応するTrustStore/TrustStorePassword値を含む Amazon RDS for Oracle 接続文字列を構成します。 たとえば、「Host=<host>;Port=<port>;Sid=<sid>;User Id=<username>;Password=<password>;EncryptionMethod=1;TrustStore=C:\\MyTrustStoreFile;TrustStorePassword=<trust_store_password>」のように入力します。
例:
{
"name": "AmazonRdsForOracleLinkedService",
"properties": {
"type": "AmazonRdsForOracle",
"typeProperties": {
"connectionString": "Host=<host>;Port=<port>;Sid=<sid>;User Id=<username>;Password=<password>;"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
例: パスワードを Azure Key Vault に格納する
{
"name": "AmazonRdsForOracleLinkedService",
"properties": {
"type": "AmazonRdsForOracle",
"typeProperties": {
"connectionString": "Host=<host>;Port=<port>;Sid=<sid>;User Id=<username>;",
"password": {
"type": "AzureKeyVaultSecret",
"store": {
"referenceName": "<Azure Key Vault linked service name>",
"type": "LinkedServiceReference"
},
"secretName": "<secretName>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
データセットのプロパティ
このセクションでは、Amazon RDS for Oracle データセットでサポートされるプロパティの一覧を示します。 データセットの定義に使用できるセクションとプロパティの一覧については、データセットに関する記事をご覧ください。
Amazon RDS for Oracle からデータをコピーするには、データセットの type プロパティを AmazonRdsForOracleTable に設定します。 次のプロパティがサポートされています。
| プロパティ | Description | 必須 |
|---|---|---|
| type | データセットの type プロパティは AmazonRdsForOracleTable に設定する必要があります。 |
はい |
| schema | スキーマの名前。 | いいえ |
| table | テーブル/ビューの名前。 | いいえ |
| tableName | スキーマがあるテーブル/ビューの名前。 このプロパティは下位互換性のためにサポートされています。 新しいワークロードでは、schema と table を使用します。 |
いいえ |
例:
{
"name": "AmazonRdsForOracleDataset",
"properties":
{
"type": "AmazonRdsForOracleTable",
"schema": [],
"typeProperties": {
"schema": "<schema_name>",
"table": "<table_name>"
},
"linkedServiceName": {
"referenceName": "<Amazon RDS for Oracle linked service name>",
"type": "LinkedServiceReference"
}
}
}
コピー アクティビティのプロパティ
このセクションでは、Amazon RDS for Oracle ソースでサポートされるプロパティの一覧を示します。 アクティビティの定義に利用できるセクションとプロパティの完全な一覧については、パイプラインに関するページを参照してください。
ソースとしての Amazon RDS for Oracle
ヒント
データ パーティション分割を使用して、Amazon RDS for Oracle からデータを効率的に読み込む方法の詳細については、「Amazon RDS for Oracle からの並列コピー」を参照してください。
Amazon RDS for Oracle からデータをコピーするには、コピー アクティビティのソースの種類を AmazonRdsForOracleSource に設定します。 コピー アクティビティの source セクションでは、次のプロパティがサポートされます。
| プロパティ | Description | 必須 |
|---|---|---|
| type | コピー アクティビティのソースの type プロパティは AmazonRdsForOracleSource に設定する必要があります。 |
はい |
| oracleReaderQuery | カスタム SQL クエリを使用してデータを読み取ります。 たとえば "SELECT * FROM MyTable" です。パーティション分割された読み込みを有効にするときは、クエリ内で対応する組み込みのパーティション パラメーターをすべてフックする必要があります。 例については、「Amazon RDS for Oracle からの並列コピー」を参照してください。 |
いいえ |
| partitionOptions | Amazon RDS for Oracle からのデータの読み込みに使用されるデータ パーティション分割オプションを指定します。 使用できる値は、以下のとおりです。None (既定値)、PhysicalPartitionsOfTable、および DynamicRange。 パーティション オプションが有効になっている場合 (つまり、 None ではない場合)、Amazon RDS for Oracle データベースから同時にデータを読み込む並列処理の次数は、コピー アクティビティの parallelCopies 設定によって制御されます。 |
いいえ |
| partitionSettings | データ パーティション分割の設定のグループを指定します。 パーティション オプションが None でない場合に適用されます。 |
いいえ |
| partitionNames | コピーする必要がある物理パーティションのリスト。 パーティション オプションが PhysicalPartitionsOfTable である場合に適用されます。 クエリを使用してソース データを取得する場合は、WHERE 句で ?AdfTabularPartitionName をフックします。 例については、「Amazon RDS for Oracle からの並列コピー」を参照してください。 |
いいえ |
| partitionColumnName | 並列コピーの範囲パーティション分割で使用される整数型のソース列の名前を指定します。 指定されていない場合は、テーブルの主キーが自動検出され、パーティション列として使用されます。 パーティション オプションが DynamicRange である場合に適用されます。 クエリを使用してソース データを取得する場合は、WHERE 句で ?AdfRangePartitionColumnName をフックします。 例については、「Amazon RDS for Oracle からの並列コピー」を参照してください。 |
いいえ |
| partitionUpperBound | データをコピーするパーティション列の最大値。 パーティション オプションが DynamicRange である場合に適用されます。 クエリを使用してソース データを取得する場合は、WHERE 句で ?AdfRangePartitionUpbound をフックします。 例については、「Amazon RDS for Oracle からの並列コピー」を参照してください。 |
いいえ |
| partitionLowerBound | データをコピーするパーティション列の最小値。 パーティション オプションが DynamicRange である場合に適用されます。 クエリを使用してソース データを取得する場合は、WHERE 句で ?AdfRangePartitionLowbound をフックします。 例については、「Amazon RDS for Oracle からの並列コピー」を参照してください。 |
いいえ |
例: パーティションなしで基本的なクエリを使用してデータをコピーする
"activities":[
{
"name": "CopyFromAmazonRdsForOracle",
"type": "Copy",
"inputs": [
{
"referenceName": "<Amazon RDS for Oracle input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "AmazonRdsForOracleSource",
"oracleReaderQuery": "SELECT * FROM MyTable"
},
"sink": {
"type": "<sink type>"
}
}
}
]
Amazon RDS for Oracle からの並列コピー
Amazon RDS for Oracle コネクタでは、Amazon RDS for Oracle からデータを並列コピーするために、組み込みのデータ パーティション分割を提供します。 データ パーティション分割オプションは、コピー アクティビティの [ソース] タブにあります。
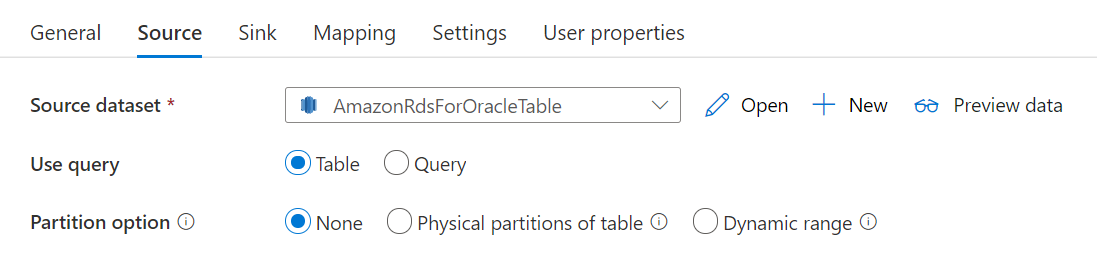
パーティション分割されたコピーを有効にすると、サービスによって Amazon RDS for Oracle ソースに対する並列クエリが実行され、パーティションごとにデータが読み込まれます。 並列度は、コピー アクティビティの parallelCopies 設定によって制御されます。 たとえば、parallelCopies を 4 に設定した場合、指定したパーティション オプションと設定に基づいて 4 つのクエリが同時に生成され、実行されます。各クエリでは、Amazon RDS for Oracle データベースからデータの一部を取得します。
特に、Amazon RDS for Oracle データベースから大量のデータを読み込む場合は、データ パーティション分割を使用した並列コピーを有効にすることをお勧めします。 さまざまなシナリオの推奨構成を以下に示します。 ファイルベースのデータ ストアにデータをコピーする場合は、複数のファイルとしてフォルダーに書き込む (フォルダー名のみを指定する) ことをお勧めします。この場合、1 つのファイルに書き込むよりもパフォーマンスが優れています。
| シナリオ | 推奨設定 |
|---|---|
| 物理パーティションに分割された大きなテーブル全体から読み込む。 | パーティション オプション: テーブルの物理パーティション。 実行中に、サービスによって物理パーティションが自動的に検出され、パーティションごとにデータがコピーされます。 |
| 物理パーティションがなく、データ パーティション分割用の整数列がある大きなテーブル全体から読み込む。 | パーティション オプション: 動的範囲パーティション。 パーティション列: データのパーティション分割に使用される列を指定します。 指定されていない場合は、主キー列が使用されます。 |
| カスタム クエリを使用して大量のデータを読み込む (物理パーティションがある場合)。 | パーティション オプション: テーブルの物理パーティション。 クエリ: SELECT * FROM <TABLENAME> PARTITION("?AdfTabularPartitionName") WHERE <your_additional_where_clause>パーティション名: データのコピー元のパーティション名を指定します。 指定されていない場合は、Amazon RDS for Oracle データセットで指定したテーブルの物理パーティションがサービスによって自動的に検出されます。 実行中に、サービスによって ?AdfTabularPartitionName が実際のパーティション名に置き換えられ、Amazon RDS for Oracle に送信されます。 |
| カスタム クエリを使用して大量のデータを読み込む (物理パーティションがなく、データ パーティション分割用の整数列がある場合)。 | パーティション オプション: 動的範囲パーティション。 クエリ: SELECT * FROM <TABLENAME> WHERE ?AdfRangePartitionColumnName <= ?AdfRangePartitionUpbound AND ?AdfRangePartitionColumnName >= ?AdfRangePartitionLowbound AND <your_additional_where_clause>パーティション列: データのパーティション分割に使用される列を指定します。 整数データ型の列に対してパーティション分割を実行できます。 パーティションの上限とパーティションの下限: パーティション列に対してフィルター処理を実行して、下限から上限までの範囲内のデータのみを取得する場合に指定します。 実行中に、サービスによって ?AdfRangePartitionColumnName、?AdfRangePartitionUpbound、?AdfRangePartitionLowbound が各パーティションの実際の列名および値の範囲に置き換えられ、Amazon RDS for Oracle に送信されます。 たとえば、パーティション列 "ID" で下限が 1、上限が 80 に設定され、並列コピーが 4 に設定されている場合、サービスは 4 つのパーティションでデータを取得します。 これらの ID の範囲はそれぞれ [1, 20]、[21, 40]、[41, 60]、[61, 80] です。 |
ヒント
パーティション分割されていないテーブルからデータをコピーするときは、"動的範囲" パーティション オプションを使用して、整数列に対してパーティション分割を行うことができます。 ソース データにこのような種類の列が含まれていない場合は、ソース クエリで ORA_HASH 関数を利用して列を生成し、それをパーティション列として使用できます。
例: 物理パーティションを使用してクエリを実行する
"source": {
"type": "AmazonRdsForOracleSource",
"query": "SELECT * FROM <TABLENAME> PARTITION(\"?AdfTabularPartitionName\") WHERE <your_additional_where_clause>",
"partitionOption": "PhysicalPartitionsOfTable",
"partitionSettings": {
"partitionNames": [
"<partitionA_name>",
"<partitionB_name>"
]
}
}
例: 動的範囲パーティションを使用してクエリを実行する
"source": {
"type": "AmazonRdsForOracleSource",
"query": "SELECT * FROM <TABLENAME> WHERE ?AdfRangePartitionColumnName <= ?AdfRangePartitionUpbound AND ?AdfRangePartitionColumnName >= ?AdfRangePartitionLowbound AND <your_additional_where_clause>",
"partitionOption": "DynamicRange",
"partitionSettings": {
"partitionColumnName": "<partition_column_name>",
"partitionUpperBound": "<upper_value_of_partition_column>",
"partitionLowerBound": "<lower_value_of_partition_column>"
}
}
Lookup アクティビティのプロパティ
プロパティの詳細については、Lookup アクティビティに関するページを参照してください。
関連するコンテンツ
コピー アクティビティによってソース、シンクとしてサポートされるデータ ストアの一覧については、サポートされるデータ ストアに関するセクションを参照してください。