コピー アクティビティでのスキーマとデータ型のマッピング
適用対象: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
ヒント
企業向けのオールインワン分析ソリューション、Microsoft Fabric の Data Factory をお試しください。 Microsoft Fabric は、データ移動からデータ サイエンス、リアルタイム分析、ビジネス インテリジェンス、レポートまで、あらゆるものをカバーしています。 無料で新しい試用版を開始する方法について説明します。
この記事では、Azure Data Factory のコピー アクティビティによって、スキーマ マッピングとデータ型のソース データからシンク データへのマッピングがどのように行われるのかについて説明します。
スキーマ マッピング
既定のマッピング
既定では、アクティビティ マップ ソース データを列名で (大文字と小文字を区別して) シンクにコピーします。 ファイルへの書き込みなど、シンクが存在しない場合、ソース フィールド名はシンク名として保持されます。 シンクが既に存在する場合は、ソースからコピーされるすべての列が含まれている必要があります。 このような既定のマッピングでは、柔軟なスキーマがサポートされ、実行から実行へ、ソースからシンクへのスキーマ ドリフトが行われ、ソース データ ストアから返されるすべてのデータをシンクにコピーできます。
ソースが、ヘッダー行のないテキスト ファイルの場合は、ソースに列名が含まれていないため、明示的なマッピングが必要です。
明示的なマッピング
また、明示的なマッピングを指定して、必要に応じて、列とフィールドのソースからシンクへのマッピングをカスタマイズできます。 明示的なマッピングでは、ソース データの一部のみをシンクにコピーする、ソース データを名前の異なるシンクにマップする、表形式または階層構造のデータを再形成することができます。 コピー アクティビティによって、以下が行われます。
- ソースからデータが読み取られ、ソース スキーマが特定されます。
- 定義されたマッピングが適用されます。
- データがシンクに書き込まれます。
各項目の詳細情報
作成 UI -> コピー アクティビティ -> [マッピング] タブでマッピングを構成するか、コピー アクティビティ ->translator プロパティのマッピングをプログラムで指定します。 translator ->mappings array -> objects ->source と、データをマップする特定の列とフィールドを指す sink では、次のプロパティがサポートされています。
| プロパティ | 内容 | 必須 |
|---|---|---|
| name | ソースまたはシンクの列とフィードの名前。 表形式のソースおよびシンクに適用します。 | はい |
| ordinal | 列のインデックス。 1 から開始します。 ヘッダー行がない区切りテキストを使用するときに適用され、必須です。 |
いいえ |
| path | 抽出またはマップする各フィールドの JSON パス式。 階層構造のソースおよびシンク (Azure Cosmos DB、MongoDB、REST コネクタなど) に適用します。 ルート オブジェクトの下のフィールドでは、JSON パスはルート $ で始まり、collectionReference プロパティにより選択された配列内のフィールドでは、JSON パスは配列要素で始まり、$ は付きません。 |
いいえ |
| type | ソースまたはシンク列の中間データ型。 一般に、このプロパティを指定または変更する必要はありません。 詳細については、「データ型のマッピング」を参照してください。 | いいえ |
| culture | ソースまたはシンク列のカルチャ。 型が Datetime または Datetimeoffset の場合に適用します。 既定では、 en-usです。一般に、このプロパティを指定または変更する必要はありません。 詳細については、「データ型のマッピング」を参照してください。 |
いいえ |
| format | 種類が Datetime または Datetimeoffset のときに使用される書式文字列。 日時の書式を設定する方法については、「カスタム日時書式指定文字列」を参照してください。 一般に、このプロパティを指定または変更する必要はありません。 詳細については、「データ型のマッピング」を参照してください。 |
いいえ |
mappings に加えて、translator の下では、次のプロパティがサポートされています。
| プロパティ | 内容 | 必須 |
|---|---|---|
| collectionReference | 階層構造のソース (Azure Cosmos DB、MongoDB、REST コネクタなど) からデータをコピーするときに適用します。 同じパターンを持つ配列フィールド内のオブジェクトからのデータの反復処理と抽出を行って、オブジェクトごとの行ごとに変換する場合は、その配列の JSON のパスを指定してクロス適用を行います。 |
いいえ |
表形式のソースから表形式のシンクへ
たとえば、Salesforce から Azure SQL Database にデータをコピーし、3 つの列を明示的にマップするには、次のようにします。
コピー アクティビティ -> [マッピング] タブで、[スキーマのインポート] ボタンをクリックして、ソースおよびシンク スキーマの両方をインポートします。
必要なフィールドをマップし、残りを除外または削除します。

コピー アクティビティ ペイロードでは、同じマッピングを次のように構成できます (translator を参照してください)。
{
"name": "CopyActivityTabularToTabular",
"type": "Copy",
"typeProperties": {
"source": { "type": "SalesforceSource" },
"sink": { "type": "SqlSink" },
"translator": {
"type": "TabularTranslator",
"mappings": [
{
"source": { "name": "Id" },
"sink": { "name": "CustomerID" }
},
{
"source": { "name": "Name" },
"sink": { "name": "LastName" }
},
{
"source": { "name": "LastModifiedDate" },
"sink": { "name": "ModifiedDate" }
}
]
}
},
...
}
ヘッダー行なしの区切りテキスト ファイルからデータをコピーするには、列を名前ではなく序数で表します。
{
"name": "CopyActivityTabularToTabular",
"type": "Copy",
"typeProperties": {
"source": { "type": "DelimitedTextSource" },
"sink": { "type": "SqlSink" },
"translator": {
"type": "TabularTranslator",
"mappings": [
{
"source": { "ordinal": "1" },
"sink": { "name": "CustomerID" }
},
{
"source": { "ordinal": "2" },
"sink": { "name": "LastName" }
},
{
"source": { "ordinal": "3" },
"sink": { "name": "ModifiedDate" }
}
]
}
},
...
}
階層構造のソースから表形式のシンクへ
階層構造のソースから表形式のシンクにデータをコピーする場合、コピー アクティビティにより、次の機能がサポートされます。
- オブジェクトと配列からデータを抽出します。
- 1 つの配列から同じパターンを持つ複数のオブジェクトをクロス適用します。この場合、1 つの JSON オブジェクトを複数のレコードに変換して、表形式の結果を生成します。
階層構造から表形式のより高度な変換では、Data Flow を使用できます。
たとえば、次の内容が含まれるソース MongoDB ドキュメントがあるとします。
{
"id": {
"$oid": "592e07800000000000000000"
},
"number": "01",
"date": "20170122",
"orders": [
{
"prod": "p1",
"price": 23
},
{
"prod": "p2",
"price": 13
},
{
"prod": "p3",
"price": 231
}
],
"city": [ { "name": "Seattle" } ]
}
配列 (order_pd と order_price) 内のデータをフラット化して、ヘッダー行を含む次の形式のテキスト ファイルにコピーし、共通のルート情報 (number、date、city) とクロス結合します。
| orderNumber | orderDate | order_pd | order_price | city |
|---|---|---|---|---|
| 01 | 20170122 | P1 | 23 | Seattle |
| 01 | 20170122 | P2 | 13 | Seattle |
| 01 | 20170122 | P3 | 231 | Seattle |
このようなマッピングは Data Factory 作成 UI で定義できます。
コピー アクティビティ -> [マッピング] タブで、[スキーマのインポート] ボタンをクリックして、ソースおよびシンク スキーマの両方をインポートします。 スキーマのインポート時に、サービスにより、上位のいくつかのオブジェクトがサンプリングされるので、フィールドが表示されない場合は、階層内の適切なレイヤーに追加できます。既存のフィールド名をポイントし、ノード、オブジェクト、または配列の追加を選択します。
データの反復処理と抽出を行う配列を選択します。 コレクション参照として自動的に設定されます。 この操作では、1 つの配列のみがサポートされることにご注意ください。
必要なフィールドをシンクにマップします。 サービスによって、階層側の対応する JSON パスが自動的に決定されます。
注意
コレクション参照としてマークされた配列が空で、チェック ボックスがオンになっているレコードの場合、レコード全体がスキップされます。
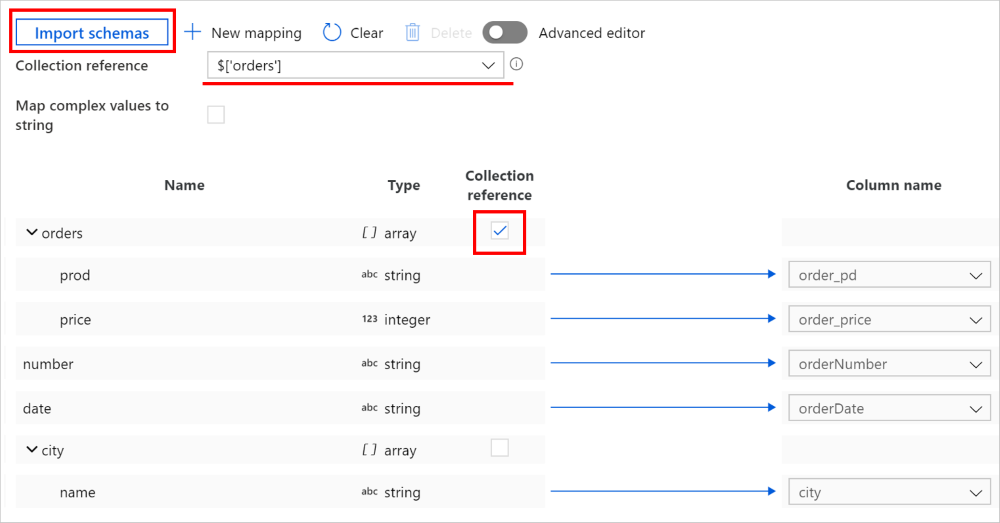
また、詳細エディターに切り替えることもでき、ここで、フィールドの JSON パスを直接表示および編集できます。 このビューに新しいマッピングを追加することを選択する場合は、JSON パスを指定します。
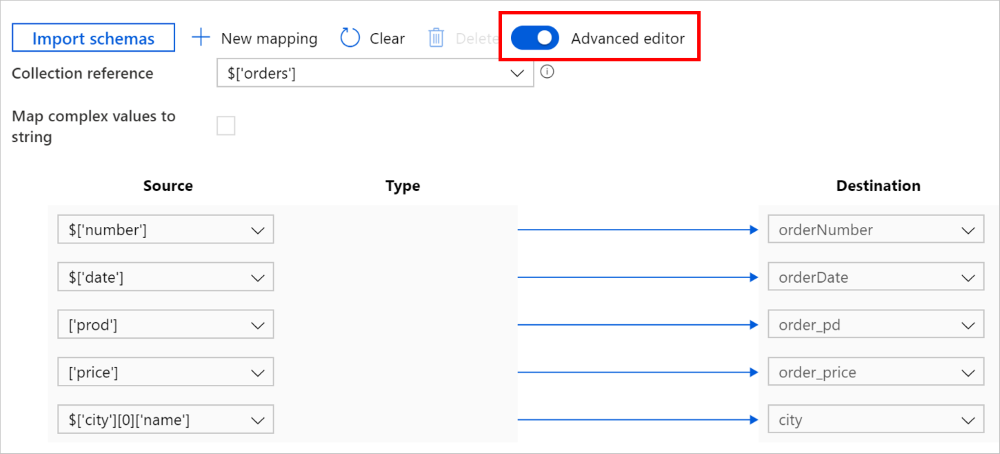
コピー アクティビティ ペイロードでは、同じマッピングを次のように構成できます (translator を参照してください)。
{
"name": "CopyActivityHierarchicalToTabular",
"type": "Copy",
"typeProperties": {
"source": { "type": "MongoDbV2Source" },
"sink": { "type": "DelimitedTextSink" },
"translator": {
"type": "TabularTranslator",
"mappings": [
{
"source": { "path": "$['number']" },
"sink": { "name": "orderNumber" }
},
{
"source": { "path": "$['date']" },
"sink": { "name": "orderDate" }
},
{
"source": { "path": "['prod']" },
"sink": { "name": "order_pd" }
},
{
"source": { "path": "['price']" },
"sink": { "name": "order_price" }
},
{
"source": { "path": "$['city'][0]['name']" },
"sink": { "name": "city" }
}
],
"collectionReference": "$['orders']"
}
},
...
}
表形式または階層構造のソースから階層構造のシンクへ
ユーザー エクスペリエンスのフローは、階層構造のソースから表形式のシンクの場合に似ています。
表形式のソースから階層構造のシンクにデータをコピーする場合は、オブジェクト内の配列への書き込みはサポートされません。
階層構造のソースから階層構造のシンクにデータをコピーする場合は、オブジェクトまたは配列を選択して、内部フィールドに触れることなくシンクにマップすることによって、レイヤー全体の階層をさらに保持できます。
より高度なデータ再形成変換には、Data Flow を使用できます。
マッピングのパラメーター化
テンプレート化パイプラインを作成して数の多いオブジェクトを動的にコピーする場合は、既定のマッピングを利用できるか、または各オブジェクトに対して明示的なマッピングを定義する必要があるかどうかを判断します。
明示的なマッピングが必要な場合は、次のようにできます。
パイプライン レベルでオブジェクト型を持つパラメーターを定義します (たとえば、
mapping)。マッピングのパラメーター化: コピー アクティビティ -> [マッピング] タブで、動的なコンテンツを追加することを選択し、上記のパラメーターを選択します。 アクティビティ ペイロードは次のようになります。
{ "name": "CopyActivityHierarchicalToTabular", "type": "Copy", "typeProperties": { "source": {...}, "sink": {...}, "translator": { "value": "@pipeline().parameters.mapping", "type": "Expression" }, ... } }マッピング パラメーターに渡す値を構築します。 これは、
translator定義のオブジェクト全体である必要があります。「明示的なマッピング」セクションのサンプルを参照してください。 たとえば、表形式のソースから表形式のシンクへのコピーでは、値は{"type":"TabularTranslator","mappings":[{"source":{"name":"Id"},"sink":{"name":"CustomerID"}},{"source":{"name":"Name"},"sink":{"name":"LastName"}},{"source":{"name":"LastModifiedDate"},"sink":{"name":"ModifiedDate"}}]}である必要があります。
データ型マッピング
コピー アクティビティでは、次のフローを使用してソースの型からシンクの型へのマッピングを実行します。
- ソース ネイティブ データ型を、Azure Data Factory パイプラインおよび Azure Synapse Analytics パイプラインで使用される中間データ型に変換します。
- 必要に応じて、中間データ型を自動的に変換して、対応するシンクの型に一致させます。既定のマッピングと明示的なマッピングの両方に適用できます。
- 中間データ型からシンクのネイティブなデータ型に変換します。
現在、コピー アクティビティによりサポートされている中間データ型は、Boolean、Byte、Byte 配列、Datetime、DatetimeOffset、Decimal、Double、GUID、Int16、Int32、Int64、SByte、Single、String、Timespan、UInt16、UInt32、UInt64 です。
次のデータ型変換は、ソースからシンクへの中間型の間でサポートされています。
| ソース \ シンク | Boolean | Byte array | 日付/時刻 | 10 進法 | 浮動小数点 | GUID | Integer | String | TimeSpan |
|---|---|---|---|---|---|---|---|---|---|
| Boolean | ✓ | ✓ | ✓ | ✓ | |||||
| Byte array | ✓ | ✓ | |||||||
| 日付/時刻 | ✓ | ✓ | |||||||
| Decimal | ✓ | ✓ | ✓ | ✓ | |||||
| 浮動小数点 | ✓ | ✓ | ✓ | ✓ | |||||
| GUID | ✓ | ✓ | |||||||
| Integer | ✓ | ✓ | ✓ | ✓ | |||||
| String | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | |
| TimeSpan | ✓ | ✓ |
(1) 日付/時刻には、DateTime と DateTimeOffset が含まれます。
(2) 浮動小数点には、Single と Double が含まれます。
(3) 整数には、SByte、Byte、Int16、UInt16、Int32、UInt32、Int64、UInt64 が含まれます。
注意
- 現在、このようなデータ型の変換は、表形式のデータ間でコピーするときにサポートされています。 階層構造のソースおよびシンクはサポートされていません。これは、システム定義されたデータ型が、ソースとシンクの中間型の間では変換されないことを意味します。
- この機能は、最新のデータセット モデルで動作します。 UI にこのオプションが表示されない場合は、新しいデータセットを作成してみてください。
データ型変換のコピー アクティビティでは、次のプロパティがサポートされています (プログラムの作成の translator セクションの下)。
| プロパティ | 内容 | 必須 |
|---|---|---|
| typeConversion | 新しいデータ型変換エクスペリエンスを有効にします。 下位互換性のため、既定値は false です。 2020 年 6 月下旬以降に Data Factory 作成 UI を使用して作成された新しいコピー アクティビティについては、このデータ型変換が、最善のエクスペリエンスを実現するために既定で有効になっています。また、該当するシナリオのコピー アクティビティ -> [マッピング] タブで次の型変換設定を確認できます。 プログラムを使ってパイプラインを作成するには、 typeConversion プロパティを明示的に true に設定して有効にする必要があります。この機能がリリースされる前に作成された既存のコピー アクティビティについては、下位互換性のため、型変換オプションが作成 UI に表示されません。 |
いいえ |
| typeConversionSettings | 型変換設定のグループ。 typeConversion が true に設定されている場合に適用します。 次のプロパティはすべてこのグループの下にあります。 |
いいえ |
typeConversionSettings の "下" |
||
| allowDataTruncation | コピー中に異なる型のシンクにソース データを変換するときのデータの切り捨てを許可します。たとえば、10 進から整数への変換では、DatetimeOffset から Datetime になります。 既定値は true です。 |
いいえ |
| treatBooleanAsNumber | ブール値を数値として扱います。たとえば、true は 1 として扱います。 既定値は false です。 |
いいえ |
| dateTimeFormat | 日付 (タイム ゾーン オフセットなし) と文字列の間で変換する場合の書式指定文字列 (yyyy-MM-dd HH:mm:ss.fff など)。 詳細については、カスタム日時書式指定文字列に関する記事を参照してください。 |
いいえ |
| dateTimeOffsetFormat | 日付 (タイム ゾーン オフセットあり) と文字列の間で変換する場合の書式指定文字列 (yyyy-MM-dd HH:mm:ss.fff zzz など)。 詳細については、カスタム日時書式指定文字列に関する記事を参照してください。 |
いいえ |
| timeSpanFormat | 時間間隔と文字列の間で変換する場合の書式指定文字列 (dd\.hh\:mm など)。 詳細については、カスタム TimeSpan 書式指定文字列に関する記事を参照してください。 |
いいえ |
| culture | en-us や fr-frなど、型を変換するときに使用されるカルチャ情報。 |
いいえ |
例:
{
"name": "CopyActivity",
"type": "Copy",
"typeProperties": {
"source": {
"type": "ParquetSource"
},
"sink": {
"type": "SqlSink"
},
"translator": {
"type": "TabularTranslator",
"typeConversion": true,
"typeConversionSettings": {
"allowDataTruncation": true,
"treatBooleanAsNumber": true,
"dateTimeFormat": "yyyy-MM-dd HH:mm:ss.fff",
"dateTimeOffsetFormat": "yyyy-MM-dd HH:mm:ss.fff zzz",
"timeSpanFormat": "dd\.hh\:mm",
"culture": "en-gb"
}
}
},
...
}
レガシ モデル
注意
ソース列とフィールドをシンクにマップする次のモデルは、下位互換性のために引き続きサポートされています。 「スキーマ マッピング」に記載されている新しいモデルを使用することをお勧めします。 作成 UI は、新しいモデルの生成に切り替えられました。
代替の列マッピング (レガシ モデル)
コピー アクティビティ ->translator ->columnMappings を指定して、表形式のデータ間をマップできます。 この場合、"structure" セクションは、入力と出力の両方のデータセットに必要です。 列マッピングでは、ソース データセットの "structure" 内のすべての列または列のサブセットのシンク データセットの "structure" 内のすべての列へのマッピングがサポートされます。 次のエラー状態では例外が発生します。
- ソース データ ストアのクエリの結果に、入力データセットの "構造" セクションで指定された列名は含まれません。
- シンク データ ストア (定義済みのスキーマを持つ場合) に、出力データセットの "structure" セクションで指定された列名は含まれません。
- シンク データセットの "structure" 内の列数が、マッピングで指定された数より少ないかまたは多い。
- 重複したマッピング。
次の例では、入力データセットには構造があり、オンプレミス Oracle データベース内のテーブルをポイントします。
{
"name": "OracleDataset",
"properties": {
"structure":
[
{ "name": "UserId"},
{ "name": "Name"},
{ "name": "Group"}
],
"type": "OracleTable",
"linkedServiceName": {
"referenceName": "OracleLinkedService",
"type": "LinkedServiceReference"
},
"typeProperties": {
"tableName": "SourceTable"
}
}
}
この例では、出力データセットには構造があり、Salesforce 内のテーブルをポイントします。
{
"name": "SalesforceDataset",
"properties": {
"structure":
[
{ "name": "MyUserId"},
{ "name": "MyName" },
{ "name": "MyGroup"}
],
"type": "SalesforceObject",
"linkedServiceName": {
"referenceName": "SalesforceLinkedService",
"type": "LinkedServiceReference"
},
"typeProperties": {
"tableName": "SinkTable"
}
}
}
次の JSON は、パイプラインのコピー アクティビティを定義します。 translator ->columnMappings プロパティを使用してシンク内の列にマップされるソースからの列。
{
"name": "CopyActivity",
"type": "Copy",
"inputs": [
{
"referenceName": "OracleDataset",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "SalesforceDataset",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": { "type": "OracleSource" },
"sink": { "type": "SalesforceSink" },
"translator":
{
"type": "TabularTranslator",
"columnMappings":
{
"UserId": "MyUserId",
"Group": "MyGroup",
"Name": "MyName"
}
}
}
}
列マッピングの指定に "columnMappings": "UserId: MyUserId, Group: MyGroup, Name: MyName" の構文を使用している場合は、引き続きそのままサポートされます。
代替のスキーマ マッピング (レガシ モデル)
コピー アクティビティ ->translator ->schemaMapping を指定して、階層構造のデータと表形式のデータの間をマップできます。たとえば MongoDB/REST からテキスト ファイルにコピーしたり、Oracle から Azure Cosmos DB for MongoDB にコピーしたりできます。 コピー アクティビティの translator セクションでは、次のプロパティがサポートされます。
| プロパティ | 内容 | 必須 |
|---|---|---|
| type | コピー アクティビティのトランスレーターの type プロパティはTabularTranslator に設定する必要があります。 | はい |
| schemaMapping | キーと値のペアのコレクション。ソース側からシンク側へのマッピングの関係を表します。 - Key: ソースを表します。 表形式のソースの場合、データセットの構造に定義された列名を指定します。階層構造のソースの場合、抽出とマッピングの対象となる各フィールドの JSON パス式を指定します。 - Value: シンクを表します。 表形式のシンクの場合、データセットの構造に定義された列名を指定します。階層構造のシンクの場合、抽出とマッピングの対象となる各フィールドの JSON パス式を指定します。 階層構造のデータで、ルート オブジェクトの直下のフィールドの場合、JSON パスはルートの $ から記述します。 collectionReference プロパティによって選択された配列内のフィールドの場合、JSON パスは配列要素から記述します。 |
はい |
| collectionReference | 同じパターンを持つ配列フィールド内のオブジェクトからのデータの反復処理と抽出を行って、オブジェクトごとの行ごとに変換する場合は、その配列の JSON のパスを指定してクロス適用を行います。 このプロパティは、階層形式のデータがソースであるときにのみサポートされます。 | いいえ |
例: MongoDB から Oracle へのコピー:
たとえば、次の内容が含まれる MongoDB ドキュメントがあるとします。
{
"id": {
"$oid": "592e07800000000000000000"
},
"number": "01",
"date": "20170122",
"orders": [
{
"prod": "p1",
"price": 23
},
{
"prod": "p2",
"price": 13
},
{
"prod": "p3",
"price": 231
}
],
"city": [ { "name": "Seattle" } ]
}
配列 (order_pd and order_price) 内のデータをフラット化し、共通のルート情報 (number, date, and city) とクロス結合させることで Azure SQL テーブルに次の形式でコピーする場合は、
| orderNumber | orderDate | order_pd | order_price | city |
|---|---|---|---|---|
| 01 | 20170122 | P1 | 23 | Seattle |
| 01 | 20170122 | P2 | 13 | Seattle |
| 01 | 20170122 | P3 | 231 | Seattle |
次のコピー アクティビティの JSON サンプルとしてスキーマ マッピング ルールを構成します。
{
"name": "CopyFromMongoDBToOracle",
"type": "Copy",
"typeProperties": {
"source": {
"type": "MongoDbV2Source"
},
"sink": {
"type": "OracleSink"
},
"translator": {
"type": "TabularTranslator",
"schemaMapping": {
"$.number": "orderNumber",
"$.date": "orderDate",
"prod": "order_pd",
"price": "order_price",
"$.city[0].name": "city"
},
"collectionReference": "$.orders"
}
}
}
関連するコンテンツ
コピー アクティビティの他の記事を参照してください。