マッピング データ フローでの並べ替え変換
適用対象: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
ヒント
企業向けのオールインワン分析ソリューション、Microsoft Fabric の Data Factory をお試しください。 Microsoft Fabric は、データ移動からデータ サイエンス、リアルタイム分析、ビジネス インテリジェンス、レポートまで、あらゆるものをカバーしています。 無料で新しい試用版を開始する方法について説明します。
データ フローは、Azure Data Factory および Azure Synapse Pipelines の両方で使用できます。 この記事は、マッピング データ フローに適用されます。 変換を初めて使用する場合は、概要の記事「マッピング データ フローを使用してデータを変換する」を参照してください。
並べ替え変換を使用すると、現在のデータ ストリームで受信した行を並べ替えることができます。 個々の列を選択し、昇順または降順に並べ替えることができます。
注意
マッピング データ フローは、複数のノードやパーティションにデータが分散される Spark クラスター上で実行されます。 後続の変換でデータのパーティションを再作成すると、データが再びシャッフルされるため、並べ替えた順序が失われる可能性があります。 データ フローで並べ替え順序を維持する最善の方法は、変換の [最適化] タブで単一のパーティションを設定し、並べ替え変換をできるだけシンクの近くに保持することです。
構成
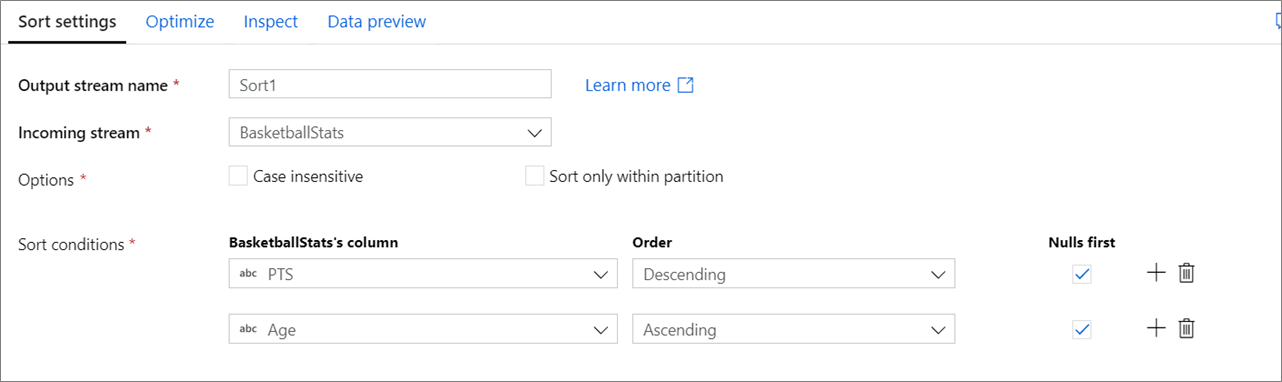
大文字と小文字の区別をしない: 文字列やテキスト フィールドを並べ替えるときに大文字と小文字を区別するかどうか
Sort Only Within Partitions (パーティション内でのみ並べ替え): データ フローは spark 上で実行されるため、各データ ストリームはパーティションに分割されます。 この設定では、データ ストリーム全体を並べ替えるのではなく、受信パーティション内でのみデータを並べ替えます。
並べ替え条件: 並べ替えの基準となる列と並べ替えの順序を選択します。 順序によって並べ替えの優先順位が決まります。 データ ストリームの先頭または末尾に null が出現するかどうかを選択します。
計算列
並べ替えを適用する前に列の値を変更または抽出するには、列の上にマウス ポインターを移動し、[計算列] を選択します。 これにより、式ビルダーが開き、列の値を使用する代わりに並べ替え操作用の式が作成されます。
データ フローのスクリプト
構文
<incomingStream>
sort(
desc(<sortColumn1>, { true | false }),
asc(<sortColumn2>, { true | false }),
...
) ~> <sortTransformationName<>
例
次のコード スニペットには、上記の並べ替え構成に対するデータ フロー スクリプトが含まれています。
BasketballStats sort(desc(PTS, true),
asc(Age, true)) ~> Sort1
関連するコンテンツ
並べ替え後に、集計変換を使用できます