ワークスペース モデル レジストリを使用してモデルのライフサイクルを管理する
重要
このドキュメントでは、ワークスペース モデル レジストリについて説明します。 ワークスペースで Unity Catalog が有効になっている場合は、このページの手順を使用しないでください。 代わりに、「Unity Catalog のモデル」を参照してください。
ワークスペース モデル レジストリは、今後非推奨となる予定です。 ワークスペース モデル レジストリから Unity Catalog にアップグレードする方法のガイダンスについては、「ワークフローおよびモデルの Unity Catalog への移行」を参照してください。
ワークスペースの既定のカタログが (hive_metastore ではなく) Unity Catalog 内にあり、Databricks Runtime 13.3 LTS 以降を使ってクラスターを実行している場合、モデルは自動的にワークスペースの既定のカタログ内に作成されて、そこから読み込まれます。構成は必要ありません。 この場合にワークスペース モデル レジストリを使用するには、ワークロードの開始時に import mlflow; mlflow.set_registry_uri("databricks") を実行することで、ワークスペース モデル レジストリを明示的にターゲットにする必要があります。 2024 年 1 月より前に既定のカタログが Unity Catalog 内のカタログに構成され、2024 年 1 月より前にワークスペース モデル レジストリが使われていた少数のワークスペースは、この動作から除外され、ワークスペース モデル レジストリが引き続き既定で使われます。
この記事では、機械学習ワークフローの一部としてワークスペース モデル レジストリを使用して ML モデルのライフサイクル全体を管理する方法について説明します。 ワークスペース モデル レジストリは、Databricks 提供のホステッド バージョンの MLflow モデル レジストリです。
ワークスペース モデル レジストリは、次の機能を備えています。
- 時系列モデル系列 (特定の時点でモデルを生成した MLflow 実験と実行)。
- モデル サービング。
- モデルのバージョン管理。
- ステージの切り替え (例: ステージングから運用またはアーカイブへ)。
- Webhooks。したがって、レジストリ イベントに基づいて自動的にアクションをトリガーできます。
- モデル イベントの電子メール通知。
モデルの説明を作成して表示し、コメントを残すこともできます。
この記事では、ワークスペース モデル レジストリ UI とワークスペース モデル レジストリ API の両方について説明します。
ワークスペース モデル レジストリの概念の概要については、「MLflow を使用した ML ライフサイクル管理」を参照してください。
モデルを作成または登録する
UI を使用してモデルを作成または登録することも、API を使用してモデルを登録することもできます。
UI を使用してモデルを作成または登録する
ワークスペース モデル レジストリにモデルを登録するには、2 つの方法があります。 MLflow にログ記録されている既存のモデルを登録するか、新しい空のモデルを作成して登録してから、以前にログに記録したモデルを割り当てることができます。
ノートブックから既存のログに記録されたモデルを登録する
ワークスペースで、登録するモデルを含む MLflow 実行を特定します。
ノートブックの右側のサイドバーの [実験] アイコン
 をクリックします。
をクリックします。
[実験実行] サイドバーで、実行日の横の
 アイコンをクリックします。 [MLflow Run]\(MLflow 実行\) ページが表示されます。 このページには、パラメーター、メトリック、タグ、および成果物の一覧を含む実行の詳細が表示されます。
アイコンをクリックします。 [MLflow Run]\(MLflow 実行\) ページが表示されます。 このページには、パラメーター、メトリック、タグ、および成果物の一覧を含む実行の詳細が表示されます。
[Artifacts]\(成果物\) セクションで、xxx-model という名前のディレクトリをクリックします。
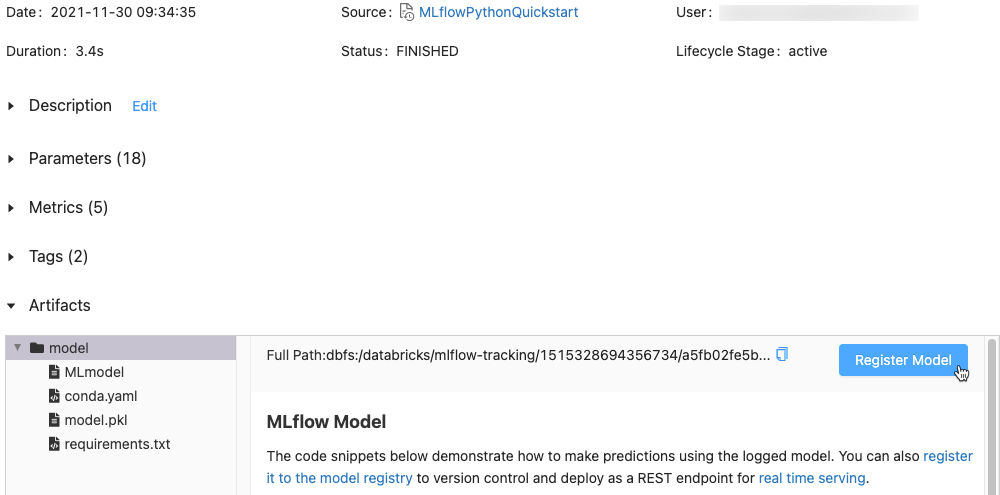
右端にある [モデルの登録] ボタンをクリックします。
ダイアログで、[モデル] ボックス内をクリックし、次のいずれかを実行します。
- ドロップダウン メニューから [新しいモデルの作成] を選択します。 [モデル名] フィールドが表示されます。 モデル名を入力します (例:
scikit-learn-power-forecasting)。 - ドロップダウン メニューから既存のモデルを選択します。
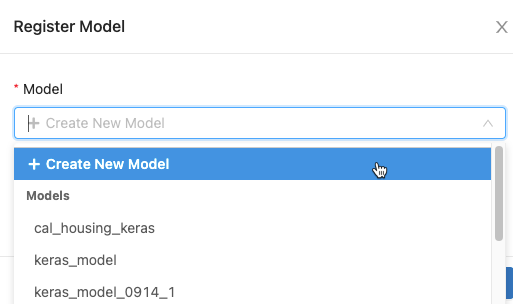
- ドロップダウン メニューから [新しいモデルの作成] を選択します。 [モデル名] フィールドが表示されます。 モデル名を入力します (例:
[登録] をクリックします。
- [新しいモデルの作成] を選択した場合は、
scikit-learn-power-forecastingという名前のモデルが登録され、ワークスペース モデル レジストリによって管理されている安全な場所にモデルがコピーされ、新しいバージョンのモデルが作成されます。 - 既存のモデルを選択した場合は、選択したモデルの新しいバージョンが登録されます。
しばらくすると、[モデルの登録] ボタンが登録済みの新しいモデル バージョンへのリンクに変わります。
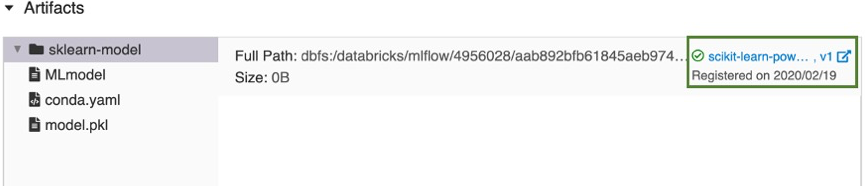
- [新しいモデルの作成] を選択した場合は、
リンクをクリックして、ワークスペース モデル レジストリ UI で新しいモデル バージョンを開きます。 ワークスペース モデル レジストリのモデルは、サイドバーの
 [モデル] をクリックして見つけることもできます。
[モデル] をクリックして見つけることもできます。
新しい登録済みモデルを作成し、ログに記録されたモデルを割り当てる
登録済みのモデルのページの [モデルの作成] ボタンを使用して、新しい空のモデルを作成してから、ログに記録されたモデルをそれに割り当てることができます。 次の手順のようにします。
登録済みのモデル ページで、[モデルの作成] をクリックします。 モデルの名前を入力し、[作成] をクリックします。
「ノートブックから既存のログに記録されたモデルをノートブックに登録する」の 1 から 3 の手順に従います。
[モデルの登録] ダイアログで、手順 1 で作成したモデルの名前を選択し、[登録] をクリック ます。 これにより、作成した名前でモデルが登録され、ワークスペース モデル レジストリによって管理されている安全な場所にモデルがコピーされ、モデル バージョン
Version 1が作成されます。しばらくすると、MLflow 実行 UI によって、[モデルの登録] ボタンが新しい登録済みのモデル バージョンへのリンクに置き換えられます。 これで、[Experiment Runs]\(実験実行\) ページの [モデルの登録] ダイアログの [モデル] ドロップダウン リストからモデルを選択できるようになりました。 また、Create ModelVersion などの API コマンドでその名前を指定して、新しいバージョンのモデルを登録することもできます。
API を使用してモデルを登録する
ワークスペース モデル レジストリにモデルを登録するには、プログラムによる 3 つの方法があります。 すべてのメソッドで、ワークスペース モデル レジストリによって管理されている安全な場所にモデルがコピーされます。
MLflow 実験中にモデルをログに記録し、指定した名前で登録するには、
mlflow.<model-flavor>.log_model(...)メソッドを使用します。 名前付きの登録済みのモデルが存在しない場合、メソッドにより新しいモデルが登録され、Version 1 が作成され、ModelVersionMLflow オブジェクトが返されます。 名前付きの登録済みのモデルが既にある場合は、メソッドにより新しいモデル バージョンが作成され、バージョン オブジェクトが返されます。with mlflow.start_run(run_name=<run-name>) as run: ... mlflow.<model-flavor>.log_model(<model-flavor>=<model>, artifact_path="<model-path>", registered_model_name="<model-name>" )すべての実験実行が完了し、レジストリに追加するのに最も適したモデルを決定した後、指定された名前を持つモデルを登録するには、
mlflow.register_model()メソッドを使用します。 この方法では、mlruns:URI引数の実行 ID が必要です。 名前付きの登録済みのモデルが存在しない場合、メソッドにより新しいモデルが登録され、Version 1 が作成され、ModelVersionMLflow オブジェクトが返されます。 名前付きの登録済みのモデルが既にある場合は、メソッドにより新しいモデル バージョンが作成され、バージョン オブジェクトが返されます。result=mlflow.register_model("runs:<model-path>", "<model-name>")指定された名前で新しい登録済みモデルを作成するには、MLflow Client API
create_registered_model()メソッドを使用します。 モデル名が存在する場合、このメソッドによりMLflowExceptionがスローされます。client = MlflowClient() result = client.create_registered_model("<model-name>")
Databricks Terraform プロバイダーと databricks_mlflow_model にモデルを登録することもできます。
UI でモデルを表示する
登録済みモデルのページ
サイドバーの![]() [モデル] をクリックすると、登録されているすべてのモデルが表示されます。 このページには、レジストリ内のすべてのモデルが表示されます。
[モデル] をクリックすると、登録されているすべてのモデルが表示されます。 このページには、レジストリ内のすべてのモデルが表示されます。
このページから新しいモデルを作成することができます。
このページでは、ワークスペース管理者がワークスペース モデル レジストリ内のすべてのモデルに対してアクセス許可を設定することもできます。

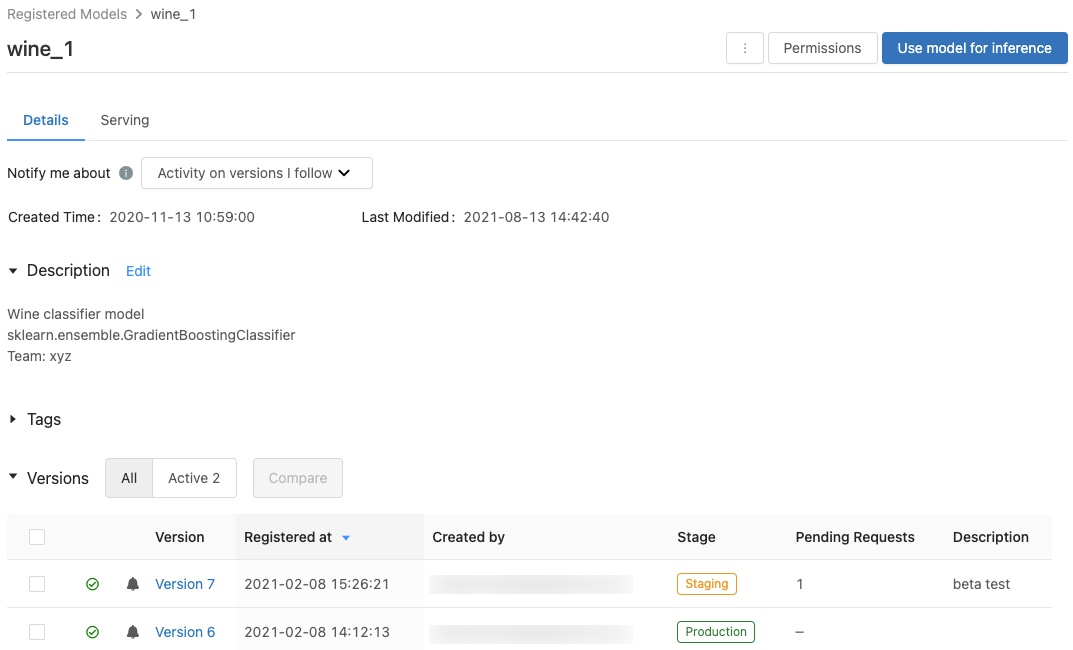
登録済みのモデルのページ
モデルの [登録済みのモデル] ページを表示するには、[登録済みのモデル] ページでモデル名をクリックします。 [登録済みのモデル] ページには、選択したモデルに関する情報と、モデルの各バージョンに関する情報を示すテーブルが表示されます。 このページからは、次のことも行うことができます。
- モデル サービングを設定します。
- モデルの推論に使用するノートブックを自動的に生成します。
- 電子メール通知を構成します。
- モデルのバージョンを比較します。
- モデルのアクセス許可を設定します。
- モデルを削除します。
モデル バージョンのページ
[モデルのバージョン] ページを表示するには、次のいずれかの操作を行います。
- [登録済みのモデル] ページで、[最新バージョン] 列のバージョン名をクリックします。
- [登録済みモデル] ページの [バージョン] 列でバージョン名をクリックします。
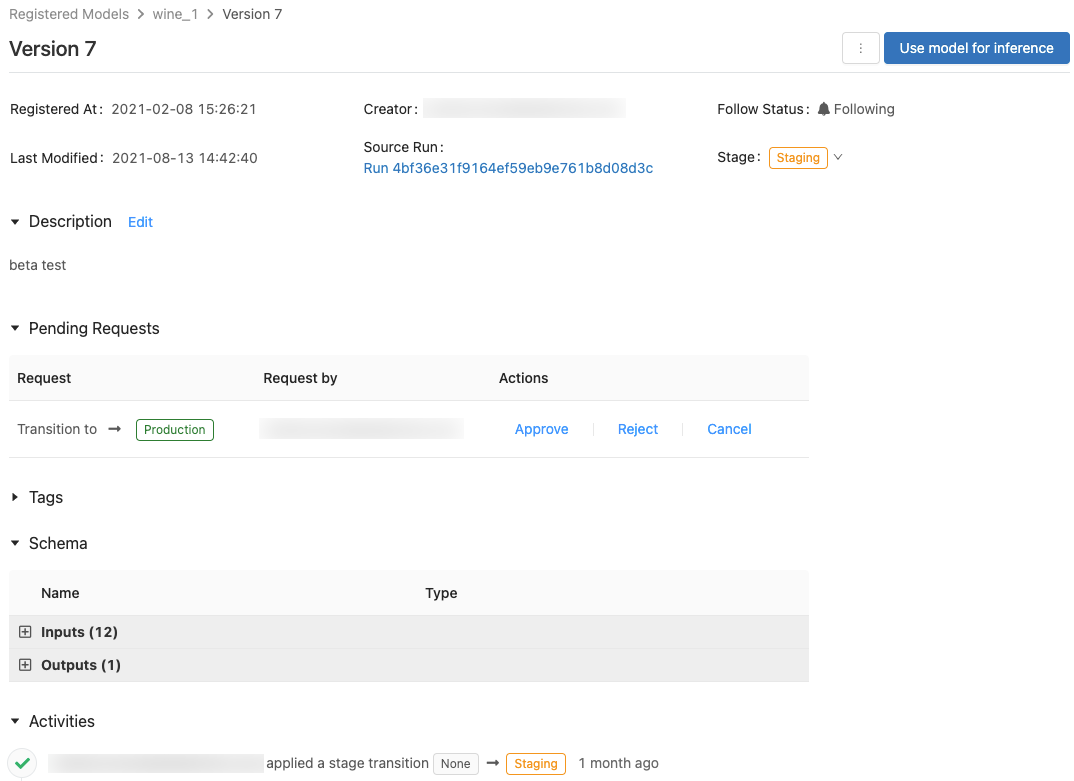
このページには、登録済みモデルの特定のバージョンに関する情報が表示されます。また、ソースの実行 (モデルを作成するために実行されたノートブックのバージョン) へのリンクも表示されます。 このページからは、次のことも行うことができます。
- モデルの推論に使用するノートブックを自動的に生成します。
- モデルを削除します。
モデルへのアクセスの制御
ワークスペース モデル レジストリに登録されているモデルへのアクセスを制御する方法については、「MLflow モデルを共有する」をご覧ください。
モデル ステージを切り替える
モデル バージョンには、なし、ステージング、運用、または アーカイブ済みのいずれかのステージがあります。 ステージング段階は、モデルのテストと検証を目的としています。一方、運用段階は、テストまたはレビューのプロセスを完了し、ライブ スコア付けのためにアプリケーションにデプロイされたモデル バージョンを対象としています。 アーカイブされたモデル バージョンは、非アクティブであると想定されます。その時点で、削除することを検討できます。 さまざまなモデル バージョンを、さまざまなステージに配置できます。
適切な権限を持つユーザーは、モデル バージョンのステージを切り替えることができます。 モデル バージョンを特定のステージに切り替える権限がある場合は、切り替えを直接行うことができます。 権限を持っていない場合は、ステージ切り替えを要求できます。また、モデル バージョンを切り替える権限を持つユーザーは、要求を承認、却下、またはキャンセルすることができます。
モデル ステージは、UI または API を使用して切り替えることができます。
UI を使用したモデル ステージの切り替え
モデルのステージを切り替えるには、次の手順に従います。
使用可能なモデル ステージと使用可能なオプションの一覧を表示するには、モデル バージョンのページで、[ステージ] の横にあるドロップ ダウンをクリックし、別のステージへの切り替えを要求または選択します。
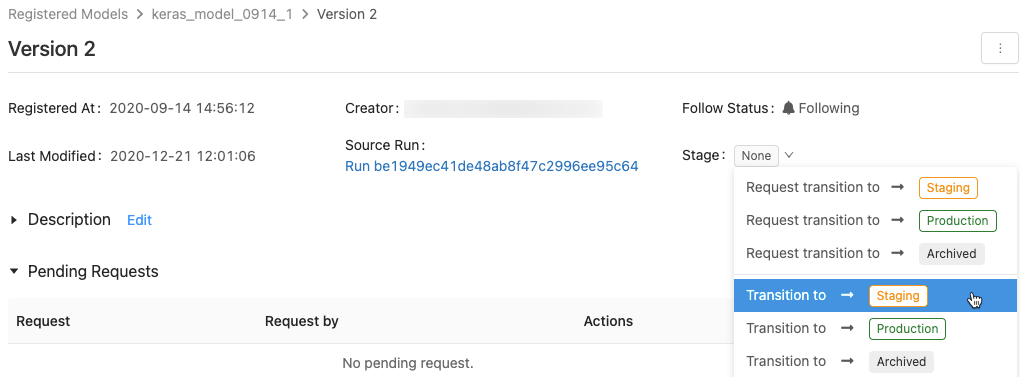
省略可能なコメントを入力し、[OK] をクリックします。
モデル バージョンを運用ステージに切り替える
テストと検証を行った後、運用ステージに移行または移行を要求できます。
ワークスペース モデル レジストリでは、登録されているモデルの複数のバージョンを各ステージで使用できます。 運用で 1 つのバージョンのみを使用する場合は、運用の既存のモデルのすべてのバージョンをアーカイブ済みに移行するには、[Transition existing Production model versions to Archived]\(既存の運用モデル バージョンをアーカイブ済みに移行\) をオンにします。
モデル バージョンのステージ切り替え要求の承認、拒否、または取り消し
ステージ切り替え権限のないユーザーは、ステージ切り替えを要求できます。 要求は、モデル バージョンのページの [保留中の要求] セクションに表示されます。

ステージ切り替えの要求を承認、拒否、またはキャンセルするには、[承認]、[拒否]、または [Cancel]\(取り消し\) リンクをクリックします。
切り替え要求の作成者は、要求をキャンセルすることもできます。
モデル バージョンのアクティビティを表示する
要求された、承認された、保留中、そしてモデル バージョンに適用されているすべての移行を表示するには、[アクティビティ] セクションに移動します。 このアクティビティのレコードにより、監査または検査のためのモデルのライフサイクルの系列が提供されます。
API を使用したモデル ステージの切り替え
適切な権限を持つユーザーは、モデル バージョンを新しいステージに切り替えることができます。
モデル バージョン ステージを新しいステージに更新するには、次のように MLflow Client API transition_model_version_stage() メソッドを使用します。
client = MlflowClient()
client.transition_model_version_stage(
name="<model-name>",
version=<model-version>,
stage="<stage>",
description="<description>"
)
<stage> に指定できる値は、"Staging"|"staging"、"Archived"|"archived"、"Production"|"production"、および "None"|"none" です。
推論にモデルを使用する
重要
この機能はパブリック プレビュー段階にあります。
ワークスペース モデル レジストリにモデルが登録されたら、バッチまたはストリーミング推論用のモデルを使用するためのノートブックを自動的に生成できます。 または、エンドポイントを作成して、モデル提供でのリアルタイムの提供にモデルを使用することもできます。
登録済みモデルのページまたはモデル バージョンのページの右上隅にある  をクリックします。 バッチ、ストリーミング、またはリアルタイムの推論を構成できる、[モデル推論の構成] ダイアログが表示されます。
をクリックします。 バッチ、ストリーミング、またはリアルタイムの推論を構成できる、[モデル推論の構成] ダイアログが表示されます。
重要
Anaconda Inc. は、anaconda.org チャネルのサービス利用規約を更新しました。 Anaconda のパッケージ化と配布に依存している場合は、新しいサービス利用規約に基づいて商用ライセンスが必要になることがあります。 詳細については、「Anaconda Commercial Edition の FAQ」を参照してください。 Anaconda チャネルの使用には、同社のサービス使用条件が適用されます。
v1.18 (Databricks Runtime 8.3 ML 以前) より前にログに記録された MLflow モデルは既定で、conda defaults チャネル (https://repo.anaconda.com/pkgs/) を依存関係としてログに記録されていました。 このライセンスの変更により、Databricks は MLflow v1.18 以降を使用してログに記録されたモデルの defaults チャネルの使用を停止しました。 ログに記録された既定のチャネルは現在、conda-forge であり、これはコミュニティで管理されている https://conda-forge.org/ を指しています。
モデルの conda 環境から defaults チャネルを除外 せずに MLflow v1.18 より前にモデルをログに記録した場合、そのモデルは意図していない defaults チャネルに依存している可能性があります。
モデルにこの依存関係があるかどうかを手動で確認するには、ログに記録されたモデルと共にパッケージ化された conda.yaml ファイル内での channel 値を調べることができます。 たとえば、defaults チャネルの依存関係を持つモデルの conda.yaml は次のようになります。
channels:
- defaults
dependencies:
- python=3.8.8
- pip
- pip:
- mlflow
- scikit-learn==0.23.2
- cloudpickle==1.6.0
name: mlflow-env
Databricks では、Anaconda リポジトリを使用してモデルを操作することが、Anaconda との関係の下で許可されているかどうか判断できないため、Databricks のお客様に変更を強制していません。 Databricks の使用を通じた Anaconda.com リポジトリの使用が、Anaconda の条件下で許可されている場合は、何も行う必要はありません。
モデルの環境で使用されているチャネルを変更する場合は、新しい conda.yaml でワークスペース モデル レジストリにモデルを再登録できます。 これを行うには、log_model() の conda_env パラメーターでチャネルを指定します。
log_model() API の詳細については、使用しているモデル フレーバー (scikit-learn の log_model など) の MLflow ドキュメントを参照してください。
conda.yaml ファイルの詳細については、MLflow のドキュメントを参照してください。
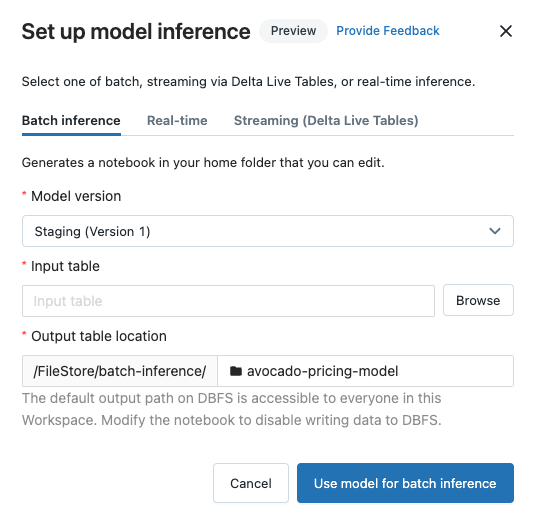
バッチ推論を構成する
これらの手順に従ってバッチ推論ノートブックを作成すると、ノートブックは、モデルの名前が付いたフォルダー内の Batch-Inference フォルダーの下のユーザー フォルダーに保存されます。 必要に応じてノートブックを編集できます。
[バッチ推論] タブをクリックします。
[モデル バージョン] ドロップダウンから、使用するモデル バージョンを選択します。 ドロップダウンの最初の 2 つの項目は、モデルの現在の運用バージョンとステージング バージョンです (存在する場合)。 これらのオプションのいずれかを選択すると、ノートブックの実行時に運用バージョンまたはステージング バージョンが自動的に使用されます。 モデルの開発を続けるときに、ノートブックを更新する必要はありません。
[入力テーブル] の横の [参照] ボタンをクリックします。 [Select input data] (入力データの選択) ダイアログが表示されます。 必要に応じて、[コンピューティング] ドロップダウンでクラスターを変更できます。
Note
Unity Catalog 対応ワークスペースの場合、[Select input data] (入力データの選択) ダイアログで、
<catalog-name>.<database-name>.<table-name>の 3 つのレベルから選択できます。モデルの入力データが含まれたテーブルを選択し、[選択] をクリックします。 生成されたノートブックにより、このデータが自動的にインポートされ、モデルに送信されます。 データをモデルに入力する前に変換が必要な場合は、生成されたノートブックを編集できます。
予測は、
dbfs:/FileStore/batch-inferenceディレクトリ内のフォルダーに保存されます。 既定では、予測はモデルと同じ名前のフォルダーに保存されます。 生成されたノートブックを実行するたびに、名前にタイムスタンプが追加された新しいファイルがこのディレクトリに書き込まれます。 タイムスタンプを含めないことや、ノートブックの以降の実行でファイルを上書きすることを選択することもできます。手順は生成されたノートブックに示されます。予測を保存するフォルダーを変更するには、[Output table location] (出力テーブルの場所) フィールドに新しいフォルダー名を入力するか、フォルダー アイコンをクリックしてディレクトリを参照し、別のフォルダーを選択します。
Unity カタログ内の場所に予測を保存するには、ノートブックを編集する必要があります。 Unity Catalog のデータを使う機械学習モデルをトレーニングし、結果を Unity Catalog に書き戻す方法を示すノートブックの例については、「Unity Catalog で機械学習モデルをトレーニングして登録する」をご覧ください。
Delta Live Tables を使用してストリーミング推論を構成する
これらの手順に従ってストリーミング推論ノートブックを作成すると、ノートブックは、モデルの名前が付いたフォルダー内の DLT-Inference フォルダーの下のユーザー フォルダーに保存されます。 必要に応じてノートブックを編集できます。
[Streaming (Delta Live Tables)] (ストリーミング (Delta Live Tables)) タブをクリックします。
[モデル バージョン] ドロップダウンから、使用するモデル バージョンを選択します。 ドロップダウンの最初の 2 つの項目は、モデルの現在の運用バージョンとステージング バージョンです (存在する場合)。 これらのオプションのいずれかを選択すると、ノートブックの実行時に運用バージョンまたはステージング バージョンが自動的に使用されます。 モデルの開発を続けるときに、ノートブックを更新する必要はありません。
[入力テーブル] の横の [参照] ボタンをクリックします。 [Select input data] (入力データの選択) ダイアログが表示されます。 必要に応じて、[コンピューティング] ドロップダウンでクラスターを変更できます。
Note
Unity Catalog 対応ワークスペースの場合、[Select input data] (入力データの選択) ダイアログで、
<catalog-name>.<database-name>.<table-name>の 3 つのレベルから選択できます。モデルの入力データが含まれたテーブルを選択し、[選択] をクリックします。 生成されたノートブックは、入力テーブルをソースとして使用するデータ変換を作成し、MLflow PySpark 推論 UDF を統合してモデルの予測を実行します。 モデルの適用前または適用後にデータに追加の変換が必要な場合は、生成されたノートブックを編集できます。
出力された Delta Live Table 名を指定します。 ノートブックは、指定された名前のライブ テーブルを作成し、それを使用してモデルの予測を格納します。 生成されたノートブックを変更して、必要に応じてターゲット データセットをカスタマイズできます。たとえば、ストリーミング ライブ テーブルを出力として定義したり、スキーマ情報やデータ品質制約を追加したりできます。
その後、このノートブックを使用して Delta Live Tables パイプラインを新規作成するか、追加のノートブック ライブラリとして既存のパイプラインに追加できます。
リアルタイム推論を構成する
モデル提供では、MLflow 機械学習モデルをスケーラブルな REST API エンドポイントとして公開します。 モデル提供エンドポイントを作成するには、「カスタム モデル提供エンドポイントを作成する」を参照してください。
フィードバックを提供する
この機能はプレビュー段階であるため、フィードバックをぜひお寄せください。 フィードバックを提供するには、[Configure model inference] (モデル推論の構成) ダイアログの [Provide Feedback] をクリックします。
モデル バージョンを比較する
ワークスペース モデル レジストリのモデル バージョンを比較できます。
- 登録済みモデルのページで、モデル バージョンの左側のチェック ボックスをオンにして、2 つ以上のモデル バージョンを選択します。
- [比較] をクリックします。
- [Comparing
<N>Versions] (個のバージョンの比較) 画面が表示され、選択したモデル バージョンのパラメーター、スキーマ、メトリックを比較するテーブルが表示されます。 画面の下部で、プロットの種類 (散布図、等高線、並列座標) と、プロットするパラメーターまたはメトリックを選択できます。
通知の設定を制御する
指定した登録済みのモデルとモデル バージョンでのアクティビティに関する通知をメールで受け取れるように、ワークスペース モデル レジストリを構成することができます。
登録済みモデルのページで、[Notify me about]\(以下の通知を受け取る\) メニューに次の 3 つのオプションが表示されます。
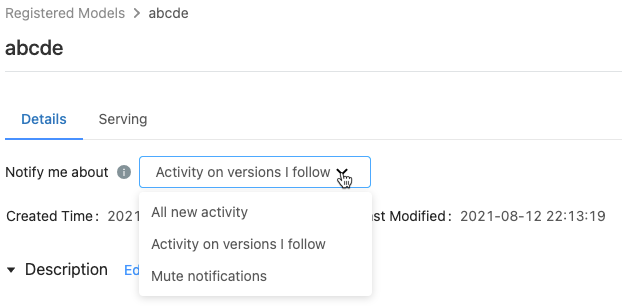
- All new activity (すべての新しいアクティビティ): このモデルのすべてのモデル バージョンのすべてのアクティビティに関する電子メール通知を送信します。 登録済みのモデルを作成した場合は、この設定が既定値になります。
- Activity on versions I follow (フォローしているバージョンのアクティビティ): フォローしているモデルのバージョンについてのみ、電子メール通知を送信します。 これを選択すると、フォローしているすべてのモデル バージョンの通知を受け取ることができます。特定のモデル バージョンの通知をオフにすることはできません。
- Mute notifications (通知のミュート): 登録されているこのモデルのアクティビティに関する電子メール通知を送信しません。
次のイベントにより、電子メール通知がトリガーされます。
- 新しいモデル バージョンの作成
- ステージの遷移の要求
- ステージの遷移
- 新しいコメント
次のいずれかの操作を行うと、モデル通知が自動的にサブスクライブされます。
- そのモデル バージョンに関するコメント
- モデル バージョンのステージを遷移させる
- モデルのステージに対して遷移を要求する
モデル バージョンをフォローしているかどうかを確認するには、モデル バージョン ページで [Follow Status]\(フォロー状態\) フィールドを確認するか、登録済みモデルのページでモデル バージョンのテーブルを参照してください。
すべての電子メール通知をオフにする
メール通知は、[ユーザー設定] メニューの [ワークスペース モデル レジストリ設定] タブでオフにすることができます。
- Azure Databricks ワークスペースの右上隅でユーザー名をクリックし、ドロップダウン メニューから [ユーザー設定] を選択します。
- [設定] サイドバーで、[通知] を選択します。
- [Model Registry email notifications]\(モデル レジストリの電子メール通知\) をオフにします。
アカウント管理者は、管理設定ページで組織全体の電子メール通知をオフにすることができます。
送信される電子メールの最大数
ワークスペース モデル レジストリを使うと、アクティビティごとに各ユーザーに送信される 1 日あたりのメール数が制限されます。 たとえば、登録済みのモデルに対して作成された新しいモデル バージョンについて 1 日に 20 通のメールを受信した場合、ワークスペース モデル レジストリから 1 日の上限に達したことを示すメールが送信されます。そのイベントに関する追加のメールは、次の日まで送信されません。
許可される電子メールの上限数を増やすには、Azure Databricks アカウント チームにお問い合わせください。
Webhooks
重要
この機能はパブリック プレビュー段階にあります。
Webhook を使うと、ワークスペース モデル レジストリ イベントをリッスンし、統合によってアクションが自動的にトリガーされるようにすることができます。 Webhook を使用して、機械学習パイプラインを自動化し、既存の CI/CD ツールおよびワークフローと統合できます。 たとえば、新しいモデル バージョンが作成されたら CI ビルドをトリガーしたり、モデルから運用への切り替えが要求されるたびに Slack を介してチーム メンバーに通知したりできます。
モデルまたはモデル バージョンに注釈を付ける
注釈を付けて、モデルまたはモデル バージョンに関する情報を提供できます。 たとえば、問題の概要や、使用される手法とアルゴリズムに関する情報を含めることができます。
UI を使用してモデルまたはモデル バージョンに注釈を付ける
Azure Databricks UI には、モデルとモデル バージョンに注釈を付ける方法がいくつか用意されています。 説明またはコメントを使用してテキスト情報を追加できます。また、検索可能なキー値タグを追加することもできます。 説明とタグはモデルとモデル バージョンに使用でき、コメントはモデル バージョンにのみ使用できます。
- 説明は、モデルに関する情報を提供することを目的としています。
- コメントは、モデル バージョンでのアクティビティに関するディスカッションを進行して、維持する手段を提供します。
- タグを使用すると、モデル メタデータをカスタマイズして、特定のモデルを見つけやすくすることができます。
モデルまたはモデル バージョンの説明を追加または更新する
登録済みモデルまたはモデル バージョンのページで、[説明] の横の [編集] をクリックします。 編集ウィンドウが表示されます。
編集ウィンドウで説明を入力または編集します。
[保存] をクリックして変更を保存するか、[キャンセル] をクリックしてウィンドウを閉じます。
モデル バージョンの説明を入力した場合、登録済みのモデルのページの表内の [説明] 列に説明が表示されます。 列には、最大で 32 文字または 1 行のテキスト (短い方) が表示されます。
モデル バージョンのコメントを追加する
- モデル バージョンのページにスクロール ダウンして、[アクティビティ] の横にある下矢印をクリックします。
- 編集ウィンドウでコメントを入力して、[コメントの追加] をクリックします。
モデルまたはモデル バージョンのタグを追加する
登録済みモデルまたはモデル バージョンのページで、
 をクリックします (まだ開いていない場合)。 タグ テーブルが表示されます。
をクリックします (まだ開いていない場合)。 タグ テーブルが表示されます。
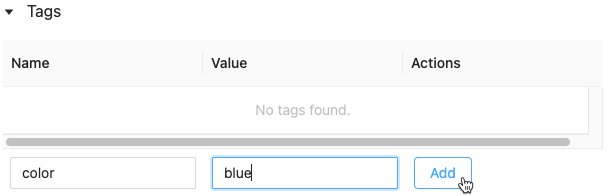
[名前] フィールドと [値] フィールド内をクリックし、タグのキーと値を入力します。
追加をクリックします。
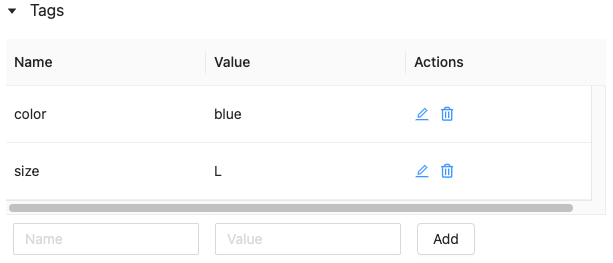
モデルまたはモデル バージョンのタグを編集または削除する
既存のタグを編集または削除するには、[アクション] 列のアイコンを使用します。
API を使用してモデル バージョンに注釈を付ける
モデル バージョンの説明を更新するには、MLflow Client API update_model_version() メソッドを使用します。
client = MlflowClient()
client.update_model_version(
name="<model-name>",
version=<model-version>,
description="<description>"
)
登録済みモデルまたはモデル バージョンのタグを設定または更新するには、MLflow Client API の set_registered_model_tag() または set_model_version_tag() メソッドを使用します。
client = MlflowClient()
client.set_registered_model_tag()(
name="<model-name>",
key="<key-value>",
tag="<tag-value>"
)
client = MlflowClient()
client.set_model_version_tag()(
name="<model-name>",
version=<model-version>,
key="<key-value>",
tag="<tag-value>"
)
モデル名を変更する (API のみ)
登録されているモデルの名前を変更するには、MLflow Client API rename_registered_model() メソッドを使用します。
client=MlflowClient()
client.rename_registered_model("<model-name>", "<new-model-name>")
Note
登録されているモデルの名前を変更できるのは、バージョンがない場合、またはすべてのバージョンが "なし" または "アーカイブ済み" ステージにある場合のみです。
モデルを検索する
UI または API を使ってワークスペース モデル レジストリ内のモデルを検索できます。
Note
モデルを検索すると、自分が読み取り可能アクセス許可以上のアクセス許可を持つモデルのみが返されます。
UI を使用してモデルを検索する
登録されているモデルを表示するには、サイドバーの ![]() [モデル] をクリックします。
[モデル] をクリックします。
特定のモデルを検索するには、検索ボックスにテキストを入力します。 モデルの名前または名前の任意の部分を入力できます。
タグでも検索できます。 タグは tags.<key>=<value> 形式で入力します。 複数のタグを検索するには、AND 演算子を使用します。
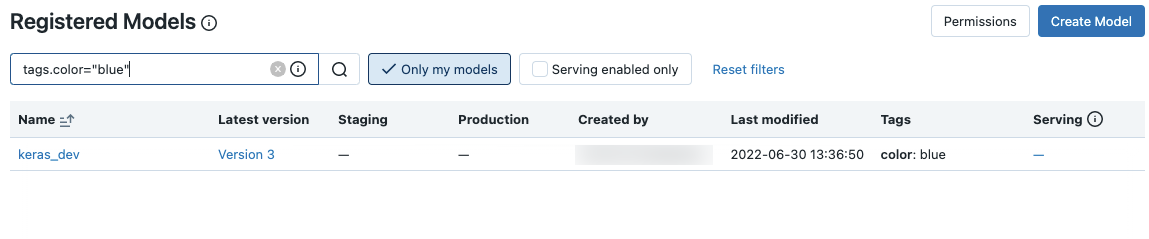
MLflow 検索構文を使用し、モデル名とタグの両方で検索できます。 次に例を示します。

API を使用してモデルを検索する
MLflow Client API メソッド search_registered_models() を使って、ワークスペース モデル レジストリで登録済みモデルを検索できます
モデルにタグを設定している場合は、search_registered_models()を使用してそれらのタグで検索することもできます。
print(f"Find registered models with a specific tag value")
for m in client.search_registered_models(f"tags.`<key-value>`='<tag-value>'"):
pprint(dict(m), indent=4)
また、MLflow Client API search_model_versions() メソッドを使用して、特定のモデル名を検索し、そのバージョンの詳細を一覧表示することもできます。
from pprint import pprint
client=MlflowClient()
[pprint(mv) for mv in client.search_model_versions("name='<model-name>'")]
これにより、以下が出力されます。
{ 'creation_timestamp': 1582671933246,
'current_stage': 'Production',
'description': 'A random forest model containing 100 decision trees '
'trained in scikit-learn',
'last_updated_timestamp': 1582671960712,
'name': 'sk-learn-random-forest-reg-model',
'run_id': 'ae2cc01346de45f79a44a320aab1797b',
'source': './mlruns/0/ae2cc01346de45f79a44a320aab1797b/artifacts/sklearn-model',
'status': 'READY',
'status_message': None,
'user_id': None,
'version': 1 }
{ 'creation_timestamp': 1582671960628,
'current_stage': 'None',
'description': None,
'last_updated_timestamp': 1582671960628,
'name': 'sk-learn-random-forest-reg-model',
'run_id': 'd994f18d09c64c148e62a785052e6723',
'source': './mlruns/0/d994f18d09c64c148e62a785052e6723/artifacts/sklearn-model',
'status': 'READY',
'status_message': None,
'user_id': None,
'version': 2 }
モデルまたはモデル バージョンを削除する
UI または API を使用してモデルを削除することができます。
UI を使用してモデル バージョンまたはモデルを削除する
警告
この操作を元に戻すことはできません。 モデル バージョンをレジストリから削除するのではなく、"アーカイブ済み" ステージにそれを移行することができます。 モデルを削除すると、ワークスペース モデル レジストリに格納されているすべてのモデル成果物と、登録済みモデルに関連付けられているすべてのメタデータが削除されます。
Note
モデルおよびモデル バージョンは、"なし" または "アーカイブ済み" ステージでのみ削除できます。 登録済みモデルのステージングまたは運用ステージにバージョンがある場合は、モデルを削除する前に、それらを "なし" または "アーカイブ済み" のいずれかのステージに移行する必要があります。
モデル バージョンを削除するには:
- サイドバーの [モデル] をクリックします。
- モデル名をクリックします。
- モデル バージョンをクリックします。
- 画面の右上隅にある
 をクリックし、ドロップダウン メニューから [削除] を選択します。
をクリックし、ドロップダウン メニューから [削除] を選択します。
モデルを削除するには:
- サイドバーの [モデル] をクリックします。
- モデル名をクリックします。
- 画面の右上隅にある をクリックし、ドロップダウン メニューから [削除] を選択します。
API を使用してモデル バージョンまたはモデルを削除する
警告
この操作を元に戻すことはできません。 モデル バージョンをレジストリから削除するのではなく、"アーカイブ済み" ステージにそれを移行することができます。 モデルを削除すると、ワークスペース モデル レジストリに格納されているすべてのモデル成果物と、登録済みモデルに関連付けられているすべてのメタデータが削除されます。
Note
モデルおよびモデル バージョンは、"なし" または "アーカイブ済み" ステージでのみ削除できます。 登録済みモデルのステージングまたは運用ステージにバージョンがある場合は、モデルを削除する前に、それらを "なし" または "アーカイブ済み" のいずれかのステージに移行する必要があります。
モデル バージョンを削除する
モデル バージョンを削除するには、MLflow Client API delete_model_version() メソッドを使用します。
# Delete versions 1,2, and 3 of the model
client = MlflowClient()
versions=[1, 2, 3]
for version in versions:
client.delete_model_version(name="<model-name>", version=version)
モデルを削除する
モデルを削除するには、MLflow Client API delete_registered_model() メソッドを使用します。
client = MlflowClient()
client.delete_registered_model(name="<model-name>")
ワークスペース間でモデルを共有する
Databricks では、Unity Catalog のモデルを使用して、ワークスペース間でモデルを共有することが推奨されています。 Unity Catalog は、ワークスペース間のモデル アクセス、ガバナンス、監査ログを追加設定なしでサポートしています。
ただし、ワークスペース モデル レジストリを使っている場合は、いくつかの設定を行うと複数のワークスペース間でモデルを共有することもできます。 たとえば、独自のワークスペースでモデルを開発してログに記録し、その後でリモート ワークスペース モデル レジストリを使って別のワークスペースからアクセスすることができます。 これは、複数のチームでモデルへのアクセスを共有する場合に便利です。 複数のワークスペースを作成し、これらの環境全体でモデルを使用および管理できます。
ワークスペース間で MLflow オブジェクトをコピーする
Azure Databricks ワークスペースとの間で MLflow オブジェクトをインポートまたはエクスポートするには、コミュニティ主導のオープンソース プロジェクト MLflow Export-Import を使用して、ワークスペース間で MLflow の実験、モデル、実行を移行します。
これらのツールを使用すると、次のことができます。
- 同じまたは別の追跡サーバー内の他のデータ サイエンティストと共有および共同作業を行う。 たとえば、別のユーザーの実験を自分のワークスペースに複製できます。
- あるワークスペースから別のワークスペースにモデルをコピーする (たとえば、開発から運用のワークスペースへ)。
- ローカル追跡サーバーから Databricks ワークスペースに MLflow の実験と実行をコピーする。
- ミッション クリティカルな実験とモデルを別の Databricks ワークスペースにバックアップする。
例
この例は、ワークスペース モデル レジストリを使って機械学習アプリケーションを構築する方法を示しています。